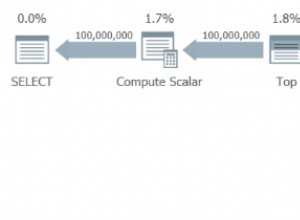
Kodierung von fünf Sonderzeichen mit rekursivem CTE:
DECLARE
@unsafe NVARCHAR(MAX),
@safe NVARCHAR(MAX)
--
-- Create the unsafe html string
--
SET @unsafe = N'html''s encoding "method" is <= or >= & 1234 ' + NCHAR(129)
--
-- Use a recursive CTE to iterate through each character in the string
--
;WITH cte AS
(
--
-- The first row will contain the original
-- string, an empty string to be used to
-- build the "safe" string, and a position
-- column to mark the character position
-- of the loop
--
SELECT
@unsafe AS unsafe_html,
CONVERT(NVARCHAR(MAX), '') AS safe_html,
1 AS pos
WHERE @unsafe IS NOT NULL AND LEN(@unsafe) > 0
UNION ALL
--
-- Create a loop:
-- The anchor row starts at position one.
-- Increment the position by one for each pass.
-- Stop when the position value is equal to the string lenth.
-- Evaluate the character in each string
-- If the ASCII value > 128, use the &# format.
-- Otherwise, check for 5 special characters: " & ' < >
-- Use the encoding reference or just the original character
--
SELECT
@unsafe AS unsafe_html,
CONVERT(NVARCHAR(MAX), safe_html +
CASE WHEN UNICODE(SUBSTRING(unsafe_html, pos, 1)) > 128
THEN '&#' + CONVERT(NVARCHAR(10), UNICODE(SUBSTRING(unsafe_html, pos, 1)))
ELSE CASE SUBSTRING(unsafe_html, pos, 1)
WHEN '"' THEN '"'
WHEN '&' THEN '&'
WHEN '''' THEN '&apos'
WHEN '<' THEN '<'
WHEN '>' THEN '>'
ELSE SUBSTRING(unsafe_html, pos, 1)
END
END ) AS safe_html,
pos + 1 AS pos
FROM cte
WHERE pos <= LEN(@unsafe)
)
--
-- Each pass through the string creates a row in the CTE
-- The last row will have the position value of the string length + 1
-- Use that row as the safe html string
-- SQL Server allows a max recursion of 32767
--
SELECT @safe = (
SELECT safe_html
FROM cte
WHERE pos = LEN(@unsafe) + 1
)
OPTION (MAXRECURSION 32767)
SELECT @safe
-- html&aposs encoding "method" is <= or >= & 1234 
Erste Version:
DECLARE @s NVARCHAR(100)
SET @s = '<html>unsafe & safe<html>'
SELECT @s
SELECT (SELECT @s FOR XML PATH(''))
---------------------------------------
<html>unsafe & safe<html>
-----------------------------------------
<html>unsafe & safe<html>
Vollständige Codierung mit allen offiziellen Referenzen:
DECLARE
@unsafe NVARCHAR(MAX),
@safe NVARCHAR(MAX)
-- Build string with first 10,000 unicode chars
SELECT @unsafe = COALESCE(@unsafe, '') + NCHAR(number) + ' '
FROM (
SELECT TOP 10000 ROW_NUMBER() OVER (ORDER BY (SELECT 0)) AS number
FROM sys.all_objects s1 CROSS JOIN sys.all_objects s2
) t
-- Build table variable with character entity references defined in HTML 4.0
-- Reference: https://www.htmlcodetutorial.com/characterentities_famsupp_69.html
DECLARE @t TABLE (
name NVARCHAR(25) NOT NULL,
unicode_val INT NOT NULL PRIMARY KEY
)
INSERT @t
VALUES
('"', 34),
('&', 38),
('&apos', 39),
('<', 60),
('>', 62),
(' ', 160),
('¡', 161),
('¢', 162),
('£', 163),
('¤', 164),
('¥', 165),
('¦', 166),
('§', 167),
('¨', 168),
('©', 169),
('ª', 170),
('«', 171),
('¬', 172),
('­', 173),
('®', 174),
('¯', 175),
('°', 176),
('±', 177),
('²', 178),
('³', 179),
('´', 180),
('µ', 181),
('¶', 182),
('·', 183),
('¸', 184),
('¹', 185),
('º', 186),
('»', 187),
('¼', 188),
('½', 189),
('¾', 190),
('¿', 191),
('À', 192),
('Á', 193),
('Â', 194),
('Ã', 195),
('Ä', 196),
('Å', 197),
('Æ', 198),
('Ç', 199),
('È', 200),
('É', 201),
('Ê', 202),
('Ë', 203),
('Ì', 204),
('Í', 205),
('Î', 206),
('Ï', 207),
('Ð', 208),
('Ñ', 209),
('Ò', 210),
('Ó', 211),
('Ô', 212),
('Õ', 213),
('Ö', 214),
('×', 215),
('Ø', 216),
('Ù', 217),
('Ú', 218),
('Û', 219),
('Ü', 220),
('Ý', 221),
('Þ', 222),
('ß', 223),
('à', 224),
('á', 225),
('â', 226),
('ã', 227),
('ä', 228),
('å', 229),
('æ', 230),
('ç', 231),
('è', 232),
('é', 233),
('ê', 234),
('ë', 235),
('ì', 236),
('í', 237),
('î', 238),
('ï', 239),
('ð', 240),
('ñ', 241),
('ò', 242),
('ó', 243),
('ô', 244),
('õ', 245),
('ö', 246),
('÷', 247),
('ø', 248),
('ù', 249),
('ú', 250),
('û', 251),
('ü', 252),
('ý', 253),
('þ', 254),
('ÿ', 255),
('&OElig', 338),
('&oelig', 339),
('&Scaron', 352),
('&scaron', 353),
('&Yuml', 376),
('&fnof', 402),
('&circ', 710),
('&tilde', 732),
('&Alpha', 913),
('&Beta', 914),
('&Gamma', 915),
('&Delta', 916),
('&Epsilon', 917),
('&Zeta', 918),
('&Eta', 919),
('&Theta', 920),
('&Iota', 921),
('&Kappa', 922),
('&Lambda', 923),
('&Mu', 924),
('&Nu', 925),
('&Xi', 926),
('&Omicron', 927),
('&Pi', 928),
('&Rho', 929),
('&Sigma', 931),
('&Tau', 932),
('&Upsilon', 933),
('&Phi', 934),
('&Chi', 935),
('&Psi', 936),
('&Omega', 937),
('&alpha', 945),
('&beta', 946),
('&gamma', 947),
('&delta', 948),
('&epsilon', 949),
('&zeta', 950),
('&eta', 951),
('&theta', 952),
('&iota', 953),
('&kappa', 954),
('&lambda', 955),
('&mu', 956),
('&nu', 957),
('&xi', 958),
('&omicron', 959),
('&pi', 960),
('&rho', 961),
('&sigmaf', 962),
('&sigma', 963),
('&tau', 964),
('&upsilon', 965),
('&phi', 966),
('&chi', 967),
('&psi', 968),
('&omega', 969),
('&thetasym', 977),
('&upsih', 978),
('&piv', 982),
('&ensp', 8194),
('&emsp', 8195),
('&thinsp', 8201),
('&zwnj', 8204),
('&zwj', 8205),
('&lrm', 8206),
('&rlm', 8207),
('&ndash', 8211),
('&mdash', 8212),
('&lsquo', 8216),
('&rsquo', 8217),
('&sbquo', 8218),
('&ldquo', 8220),
('&rdquo', 8221),
('&bdquo', 8222),
('&dagger', 8224),
('&Dagger', 8225),
('&bull', 8226),
('&hellip', 8230),
('&permil', 8240),
('&prime', 8242),
('&Prime', 8243),
('&lsaquo', 8249),
('&rsaquo', 8250),
('&oline', 8254),
('&frasl', 8260),
('&euro', 8364),
('&image', 8465),
('&weierp', 8472),
('&real', 8476),
('&trade', 8482),
('&alefsym', 8501),
('&larr', 8592),
('&uarr', 8593),
('&rarr', 8594),
('&darr', 8595),
('&harr', 8596),
('&crarr', 8629),
('&lArr', 8656),
('&uArr', 8657),
('&rArr', 8658),
('&dArr', 8659),
('&hArr', 8660),
('&forall', 8704),
('&part', 8706),
('&exist', 8707),
('&empty', 8709),
('&nabla', 8711),
('&isin', 8712),
('¬in', 8713),
('&ni', 8715),
('&prod', 8719),
('&sum', 8721),
('&minus', 8722),
('&lowast', 8727),
('&radic', 8730),
('&prop', 8733),
('&infin', 8734),
('&ang', 8736),
('&and', 8743),
('&or', 8744),
('&cap', 8745),
('&cup', 8746),
('&int', 8747),
('&there4', 8756),
('&sim', 8764),
('&cong', 8773),
('&asymp', 8776),
('&ne', 8800),
('&equiv', 8801),
('&le', 8804),
('&ge', 8805),
('&sub', 8834),
('&sup', 8835),
('&nsub', 8836),
('&sube', 8838),
('&supe', 8839),
('&oplus', 8853),
('&otimes', 8855),
('&perp', 8869),
('&sdot', 8901),
('&lceil', 8968),
('&rceil', 8969),
('&lfloor', 8970),
('&rfloor', 8971),
('&lang', 9001),
('&rang', 9002),
('&loz', 9674),
('&spades', 9824),
('&clubs', 9827),
('&hearts', 9829),
('&diams', 9830)
-- Build numbers table to parse the string
DECLARE @numbers TABLE (number INT NOT NULL PRIMARY KEY)
INSERT @numbers
SELECT TOP (LEN(@unsafe)) ROW_NUMBER() OVER (ORDER BY (SELECT 0)) AS number
FROM sys.all_objects s1 CROSS JOIN sys.all_objects s2
-- Use numbers table to parse each character.
-- If a match is found in character entity reference table,
-- then use the safe substitute. Otherwise, if the unicode
-- value is greater than 128, use &#<unicode char value>.
-- Finally, use the original character if nothing else
-- is a match
SELECT @safe = COALESCE(@safe,'')
+ COALESCE(name,
CASE WHEN UNICODE(SUBSTRING(@unsafe, number, 1)) > 128 THEN '&#'
+ CONVERT(NVARCHAR(10), UNICODE(SUBSTRING(@unsafe, number, 1)))
ELSE SUBSTRING(@unsafe, number, 1) END)
FROM @numbers
LEFT OUTER JOIN @t
ON UNICODE(SUBSTRING(@unsafe, number, 1)) = unicode_val
SELECT @safe AS [safe]
Results:
! " # $ % & &apos ( ) * + , - . / 0 1 2 3 4 5 6 7 8 9 : ;
< = > ? @ A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
[ \ ] ^ _ ` a b c d e f g h i j k l m n o p q r s t u v w x y z {
| } ~  ‚ ƒ „ … † ‡ ˆ ‰ Š
‹ Œ  Ž   ‘ ’ “ ” •
– — ˜ ™ š › œ  ž Ÿ  
¡ ¢ £ ¤ ¥ ¦ § ¨ © ª
« ¬ ­ ® ¯ ° ± ² ³ ´ µ
¶ · ¸ ¹ º » ¼ ½ ¾
¿ À Á Â Ã Ä Å Æ Ç
È É Ê Ë Ì Í Î Ï Ð Ñ
Ò Ó Ô Õ Ö × Ø Ù Ú
Û Ü Ý Þ ß à á â ã ä
å æ ç è é ê ë ì í î
ï ð ñ ò ó ô õ ö ÷ ø
ù ú û ü ý þ ÿ Ā ā Ă ă
Ą ą Ć ć Ĉ ĉ Ċ...