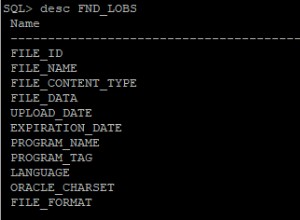
Unterbaumkosten sollten mit Vorsicht betrachtet werden (insbesondere, wenn Sie große Kardinalitätsfehler haben). SET STATISTICS IO ON; SET STATISTICS TIME ON; Output ist ein besserer Indikator für die tatsächliche Leistung.
Die Nullzeilensortierung beansprucht nicht 87 % der Ressourcen. Dieses Problem in Ihrem Plan ist eines der statistischen Schätzung. Die in der Ist-Planung ausgewiesenen Kosten sind noch geschätzte Kosten. Es passt sie nicht an, um zu berücksichtigen, was tatsächlich passiert ist.
Es gibt einen Punkt im Plan, an dem ein Filter 1.911.721 Zeilen auf 0 reduziert, aber die geschätzten Zeilen für die Zukunft sind 1.860.310. Danach sind alle Kosten falsch und gipfeln in den geschätzten 87 % der Kosten für die Sortierung von 3.348.560 Zeilen.
Der Kardinalitätsschätzungsfehler kann außerhalb des Merge reproduziert werden Anweisung, indem Sie sich den geschätzten Plan für den Full Outer Join ansehen mit äquivalenten Prädikaten (ergibt dieselbe Schätzung von 1.860.310 Zeilen).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Allerdings sieht der Plan bis zum Filter selbst ziemlich suboptimal aus. Es führt einen vollständigen Clustered-Index-Scan durch, wenn Sie vielleicht einen Plan mit 2 Clustered-Index-Bereichssuchen wünschen. Einer zum Abrufen der einzelnen Zeile, die mit dem Primärschlüssel aus dem Join auf der Quelle übereinstimmt, und der andere zum Abrufen von T.Key1 = @id Bereich (obwohl dies vielleicht der Fall ist, um die Notwendigkeit zu vermeiden, später in die gruppierte Schlüsselreihenfolge zu sortieren?)
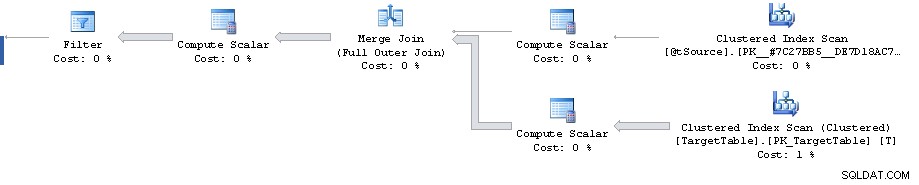
Vielleicht könnten Sie diese Umschreibung ausprobieren und sehen, ob sie besser oder schlechter funktioniert
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;