In der Frage sind nicht viele Informationen enthalten. Wir wissen nur:
- Spalte verwendet Sortierung von
Thai_CI_AS(Zumindest klingt es so, als würde die Frage sagen) - Thailändische Zeichen werden übergeben
- Was in der Spalte gespeichert ist, ist:
???
Allein daraus können wir jedoch zwei Dinge ableiten:
-
Der eingehende String ist weder ein
NVARCHARParameter / Variable, noch ist es ein String-Literal, dem ein großes "N" vorangestellt ist,und
-
Die Standardsortierung für die DB, in der die Abfrage ausgeführt wird (nicht unbedingt die DB, in der die Tabelle vorhanden ist), ist nicht eine thailändische Sortierung.
Wir wissen nicht, ob die Zielspalte VARCHAR ist oder NVARCHAR , aber das spielt keine Rolle, wenn die Sortierung der Spalte eine thailändische Sortierung ist (da dies VARCHAR zulässt Daten für thailändische Zeichen und NVARCHAR würde trotzdem funktionieren).
Wenn entweder :
-
die eingehende Zeichenfolge verwendet ein
NVARCHARParameter (oder wenn String-Literal, dann Präfix mit einem großen "N"),oder
-
Die Abfrage wurde in einer Datenbank ausgeführt, die eine thailändische Standardsortierung hat
dann würden die thailändischen Zeichen wie erwartet gespeichert.
Das folgende Beispiel demonstriert dieses Verhalten. Ich verwende ein thailändisches Schriftzeichen Khomut U+0E5B
auf einer Instanz mit einem Korean_100_CS_AS_KS_WS_SC Standardsortierung auf Instanzebene. Die Zielspalte hat eine Sortierung von Thai_CI_AS . Erstens, während die "aktuelle" DB nicht ist Wenn ich eine thailändische Standardsortierung habe, füge ich das Zeichen zweimal hinzu:einmal mit vorangestelltem "N" und einmal ohne Präfix auf dem Zeichenfolgenliteral:
USE [tempdb];
-- DROP TABLE #Thai;
CREATE TABLE #Thai (ID INT IDENTITY(1, 1), Col1 VARCHAR(50) COLLATE Thai_CI_AS);
-- In a DB with a non-Thai default Collation:
INSERT INTO #Thai (Col1) VALUES ('๛');
INSERT INTO #Thai (Col1) VALUES (N'๛');
Als nächstes wechsle ich zu einer DB, die macht haben eine thailändische Standardsortierung und fügen nur die Zeichenfolge ohne Präfix ein (keine wirkliche Notwendigkeit, die Zeichenfolge mit dem Präfix „N“ erneut zu testen):
USE [other_db];
-- In a DB with a Thai default Collation:
INSERT INTO #Thai (Col1) VALUES ('๛');
SELECT * FROM #Thai;
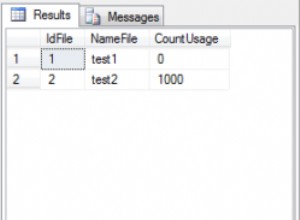
Das Ergebnis ist:
ID Col1
1 ?
2 ๛
3 ๛
Wie Sie sehen können (Punkt # unten bezieht sich auf ID # in den Ergebnissen oben):
- Die Zeichenfolge ohne „N“-Präfix, die in einer Datenbank verwendet wird, die eine nicht-thailändische Standardsortierung verwendet, wurde in
?übersetzt - Die Zeichenfolge mit dem Präfix "N", die auch in einer DB mit einer nicht-thailändischen Standardsortierung verwendet wird, speicherte den Wert korrekt
- Die Zeichenfolge ohne "N"-Präfix, die in einer Datenbank verwendet wird, die eine thailändische Standardsortierung hat, speicherte den Wert korrekt