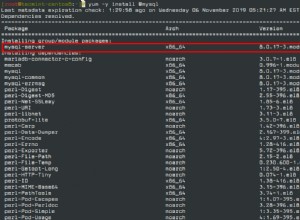
Sie sollten diese Seite aus den offiziellen Dokumenten zu Ergebnissätzen lesen . Es heißt
Standardmäßig werden ResultSets vollständig abgerufen und im Arbeitsspeicher gespeichert. In den meisten Fällen ist dies die effizienteste Arbeitsweise und aufgrund des Designs des MySQL-Netzwerkprotokolls einfacher zu implementieren. Wenn Sie mit ResultSets arbeiten, die eine große Anzahl von Zeilen oder großen Werten enthalten, und keinen Heap-Speicherplatz in Ihrer JVM für den erforderlichen Speicher zuweisen können, können Sie den Treiber anweisen, die Ergebnisse Zeile für Zeile zurück zu streamen.
stmt = conn.createStatement(java.sql.ResultSet.TYPE_FORWARD_ONLY,
java.sql.ResultSet.CONCUR_READ_ONLY);
stmt.setFetchSize(Integer.MIN_VALUE);
Die Kombination einer vorwärtsgerichteten, schreibgeschützten Ergebnismenge mit einer Abrufgröße von Integer.MIN_VALUE dient als Signal an den Treiber, Ergebnismengen Zeile für Zeile zu streamen. Danach werden alle mit der Anweisung erstellten Ergebnismengen Zeile für Zeile abgerufen.
Tatsächlich hat das Festlegen von nur fetchSize keine Auswirkung auf die Connector-j-Implementierung.