Warum dauert es so lange, eine Abfrage auszuführen? Warum gibt es keine Indizes? Wahrscheinlich haben Sie schon von EXPLAIN in PostgreSQL gehört. Es gibt jedoch immer noch viele Menschen, die keine Ahnung haben, wie man es benutzt. Ich hoffe, dass dieser Artikel Benutzern hilft, mit diesem großartigen Tool umzugehen.
Dieser Artikel ist die Autorenrevision von Understanding EXPLAIN von Guillaume Lelarge. Da ich einige Informationen verpasst habe, empfehle ich Ihnen dringend, sich mit dem Original vertraut zu machen.
Der Teufel ist nicht so schwarz, wie er gemalt wird
Es ist wichtig, die Logik des PostgreSQL-Kernels zu verstehen, um Abfragen zu optimieren. Ich versuche es zu erklären. Es ist wirklich nicht so kompliziert.
EXPLAIN zeigt die notwendigen Informationen an, die erklären, was der Kernel für jede spezifische Abfrage macht.
Lassen Sie uns einen Blick darauf werfen, was der EXPLAIN-Befehl anzeigt, und verstehen, was genau in PostgreSQL passiert. Sie können diese Informationen auf PostgreSQL 9.2 und höhere Versionen anwenden.
Unsere Aufgaben:
- Lernen Sie, wie Sie die Ausgabe des EXPLAIN-Befehls lesen und verstehen
- Verstehen, was in PostgreSQL passiert, wenn eine Abfrage ausgeführt wird
Erste Schritte
Wir werden an einer Testtabelle mit einer Million Zeilen üben.
CREATE TABLE foo (c1 integer, c2 text); INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 1000000) AS i;
Versuchen Sie, die Daten zu lesen
EXPLAIN SELECT * FROM foo;
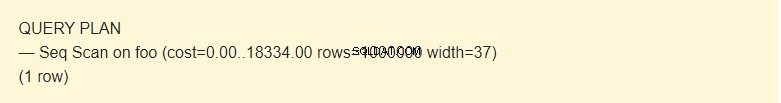
Es gibt mehrere Möglichkeiten, Daten aus einer Tabelle zu lesen. In unserem Fall teilt EXPLAIN mit, dass ein Seq-Scan verwendet wird – sequentielle, Block für Block gelesene Foo-Tabellendaten.
Was sind Kosten ?
Nun, es ist keine Zeit, sondern ein Konzept, mit dem die Kosten einer Operation geschätzt werden können. Der erste Wert 0,00 sind die Kosten für das Abrufen der ersten Zeile. Der zweite Wert 18334,00 sind die Kosten für das Abrufen aller Zeilen.
Zeilen sind die ungefähre Anzahl der Zeilen, die zurückgegeben werden, wenn eine Seq-Scan-Operation ausgeführt wird. Der Scheduler gibt diesen Wert zurück. In meinem Fall stimmt es mit der tatsächlichen Anzahl der Zeilen in der Tabelle überein.
Breite ist eine durchschnittliche Größe einer Zeile in Bytes.
Versuchen wir, 10 Zeilen hinzuzufügen.
INSERT INTO foo SELECT i, md5(random()::text) FROM generate_series(1, 10) AS i; EXPLAIN SELECT * FROM foo;

Der Wert der Zeilen wurde nicht geändert. Die Statistik der Tabelle ist alt. Um die Statistiken zu aktualisieren, rufen Sie den Befehl ANALYZE auf.
Jetzt Zeilen zeigt die richtige Anzahl von Zeilen an.
Was passiert beim Ausführen von ANALYZE?
- Zufällig werden einige Zeilen ausgewählt und aus der Tabelle gelesen.
- Die Statistik der Werte von jeder Spalte wird gesammelt.
Die Anzahl der von ANALYZE gelesenen Zeilen hängt vom Parameter default_statistics_target ab.
Aktuelle Daten
Alles, was wir oben in der Ausgabe des EXPLAIN-Befehls gesehen haben, ist das, was der Planer erwartet. Versuchen wir, sie mit den Ergebnissen der tatsächlichen Daten zu vergleichen. Verwenden Sie dazu EXPLAIN (ANALYZE).
EXPLAIN (ANALYZE) SELECT * FROM foo;

Eine solche Abfrage wird tatsächlich durchgeführt. Wenn Sie also EXPLAIN (ANALYZE) für die INSERT-, DELETE- oder UPDATE-Anweisungen ausführen, werden Ihre Daten geändert. Vorsichtig sein! Verwenden Sie in diesen Fällen den ROLLBACK-Befehl.
Der Befehl zeigt die folgenden zusätzlichen Parameter an:
- tatsächliche Zeit ist die tatsächliche Zeit in Millisekunden, die aufgewendet wird, um die erste Zeile bzw. alle Zeilen abzurufen.
- rows ist die tatsächliche Anzahl der mit Seq Scan empfangenen Zeilen.
- loops ist die Anzahl der Male, die der Seq-Scan-Vorgang durchgeführt werden musste.
- Gesamtlaufzeit ist die Gesamtzeit der Abfrageausführung.
Weiterführende Literatur:
Abfrageoptimierung in PostgreSQL. ERKLÄREN Grundlagen – Teil 2
Abfrageoptimierung in PostgreSQL. ERKLÄREN Grundlagen – Teil 3