PostgreSQL ist eine der fortschrittlichsten Open-Source-Datenbanken der Welt mit vielen großartigen Funktionen. Eine davon ist die Streaming-Replikation (Physische Replikation), die in PostgreSQL 9.0 eingeführt wurde. Es basiert auf XLOG-Einträgen, die an den Zielserver übertragen und dort angewendet werden. Es ist jedoch Cluster-basiert und wir können keine Replikation einer einzelnen Datenbank oder eines einzelnen Objekts (selektive Replikation) durchführen. Im Laufe der Jahre waren wir für die selektive oder teilweise Replikation auf externe Tools wie Slony, Bucardo, BDR usw. angewiesen, da es bis PostgreSQL 9.6 keine Funktion auf Kernebene gab. PostgreSQL 10 hat jedoch eine Funktion namens Logische Replikation entwickelt, mit der wir eine Replikation auf Datenbank-/Objektebene durchführen können.
Die logische Replikation repliziert Änderungen an Objekten basierend auf ihrer Replikationsidentität, die normalerweise ein Primärschlüssel ist. Es unterscheidet sich von der physischen Replikation, bei der die Replikation auf Blöcken und einer Byte-für-Byte-Replikation basiert. Die logische Replikation benötigt keine exakte Binärkopie auf der Seite des Zielservers, und wir haben die Möglichkeit, im Gegensatz zur physischen Replikation auf den Zielserver zu schreiben. Diese Funktion stammt aus dem pglogical-Modul.
In diesem Blogbeitrag werden wir Folgendes besprechen:
- Wie es funktioniert - Architektur
- Funktionen
- Anwendungsfälle - wenn es nützlich ist
- Einschränkungen
- So erreichen Sie es
So funktioniert es – Logische Replikationsarchitektur
Logical Replication implementiert ein Publish-and-Subscribe-Konzept (Publication &Subscription). Nachfolgend finden Sie ein Architekturdiagramm auf höherer Ebene, das zeigt, wie es funktioniert.
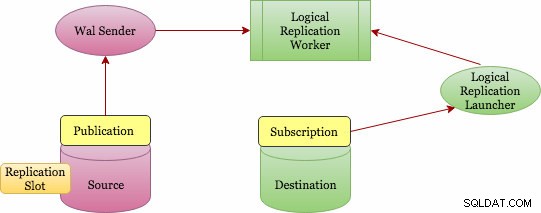
Grundlegende logische Replikationsarchitektur
Die Veröffentlichung kann auf dem Master-Server definiert werden, und der Knoten, auf dem sie definiert wird, wird als "Publisher" bezeichnet. Veröffentlichung ist eine Reihe von Änderungen aus einer einzelnen Tabelle oder einer Gruppe von Tabellen. Es befindet sich auf Datenbankebene und jede Veröffentlichung existiert in einer Datenbank. Einer einzelnen Veröffentlichung können mehrere Tabellen hinzugefügt werden, und eine Tabelle kann sich in mehreren Veröffentlichungen befinden. Sie sollten Objekte explizit zu einer Veröffentlichung hinzufügen, es sei denn, Sie wählen die Option "ALLE TABELLEN", die ein Superuser-Privileg erfordert.
Sie können die zu replizierenden Änderungen von Objekten (INSERT, UPDATE und DELETE) einschränken. Standardmäßig werden alle Operationstypen repliziert. Für das Objekt, das Sie einer Veröffentlichung hinzufügen möchten, muss eine Replikationsidentität konfiguriert sein. Dies geschieht, um UPDATE- und DELETE-Operationen zu replizieren. Die Replikationsidentität kann ein Primärschlüssel oder ein eindeutiger Index sein. Wenn die Tabelle keinen Primärschlüssel oder eindeutigen Index hat, kann sie auf die Replica Identity "full" gesetzt werden, bei der alle Spalten als Schlüssel verwendet werden (die gesamte Zeile wird zum Schlüssel).
Sie können eine Veröffentlichung mit CREATE PUBLICATION erstellen. Einige praktische Befehle werden im Abschnitt "So erreichen Sie es" behandelt.
Das Abonnement kann auf dem Zielserver definiert werden, und der Knoten, auf dem es definiert ist, wird als "Abonnent" bezeichnet. Die Verbindung zur Quelldatenbank wird im Abonnement definiert. Der Abonnentenknoten ist derselbe wie jede andere eigenständige Postgres-Datenbank, und Sie können ihn auch als Veröffentlichung für weitere Abonnements verwenden.
Das Abonnement wird mit CREATE SUBSCRIPTION hinzugefügt und kann jederzeit mit dem Befehl ALTER SUBSCRIPTION gestoppt/fortgesetzt und mit DROP SUBSCRIPTION entfernt werden.
Nachdem ein Abonnement erstellt wurde, kopiert die logische Replikation einen Snapshot der Daten in der Herausgeberdatenbank. Sobald dies erledigt ist, wartet es auf Delta-Änderungen und sendet sie an den Abonnementknoten, sobald sie auftreten.
Doch wie werden die Änderungen erfasst? Wer schickt sie zum Ziel? Und wer bringt sie am Ziel an? Die logische Replikation basiert ebenfalls auf derselben Architektur wie die physische Replikation. Es wird durch die Prozesse „walsender“ und „apply“ umgesetzt. Da es auf WAL-Decodierung basiert, wer beginnt mit der Dekodierung? Der walsender-Prozess ist dafür verantwortlich, die logische Decodierung der WAL zu starten, und lädt das standardmäßige Plug-in für die logische Decodierung (pgoutput). Das Plugin wandelt die von WAL gelesenen Änderungen in das logische Replikationsprotokoll um und filtert die Daten gemäß der Veröffentlichungsspezifikation. Die Daten werden dann kontinuierlich unter Verwendung des Streaming-Replikationsprotokolls an den Apply-Worker übertragen, der die Daten lokalen Tabellen zuordnet und die einzelnen Änderungen in der korrekten Transaktionsreihenfolge anwendet, sobald sie empfangen werden.
Es protokolliert alle diese Schritte in Protokolldateien, während es eingerichtet wird. Wir können die Nachrichten im Abschnitt "So erreichen Sie es" später im Beitrag sehen.
Merkmale der logischen Replikation
- Die logische Replikation repliziert Datenobjekte basierend auf ihrer Replikationsidentität (im Allgemeinen ein
- Primärschlüssel oder eindeutiger Index).
- Zielserver kann für Schreibvorgänge verwendet werden. Sie können unterschiedliche Indizes und Sicherheitsdefinitionen haben.
- Die logische Replikation unterstützt verschiedene Versionen. Im Gegensatz zur Streaming-Replikation kann die logische Replikation zwischen verschiedenen Versionen von PostgreSQL (aber> 9.4) eingestellt werden
- Die logische Replikation führt eine ereignisbasierte Filterung durch
- Im Vergleich dazu hat die logische Replikation eine geringere Schreibverstärkung als die Streaming-Replikation
- Publikationen können mehrere Abonnements haben
- Die logische Replikation bietet Speicherflexibilität durch die Replikation kleinerer Sätze (sogar partitionierter Tabellen)
- Minimale Serverlast im Vergleich zu Trigger-basierten Lösungen
- Ermöglicht paralleles Streaming über Publisher hinweg
- Die logische Replikation kann für Migrationen und Upgrades verwendet werden
- Datentransformation kann während der Einrichtung durchgeführt werden.
Anwendungsfälle – Wann ist die logische Replikation sinnvoll?
Es ist sehr wichtig zu wissen, wann die logische Replikation verwendet werden soll. Andernfalls haben Sie keinen großen Nutzen, wenn Ihr Anwendungsfall nicht passt. Hier sind also einige Anwendungsfälle, wann die logische Replikation verwendet werden sollte:
- Wenn Sie mehrere Datenbanken zu Analysezwecken in einer einzigen Datenbank konsolidieren möchten.
- Wenn Sie Daten zwischen verschiedenen Hauptversionen von PostgreSQL replizieren möchten.
- Wenn Sie inkrementelle Änderungen in einer einzelnen Datenbank oder einer Teilmenge einer Datenbank an andere Datenbanken senden möchten.
- Wenn verschiedenen Benutzergruppen Zugriff auf replizierte Daten gewährt wird.
- Wenn eine Teilmenge der Datenbank von mehreren Datenbanken gemeinsam genutzt wird.
Einschränkungen der logischen Replikation
Die logische Replikation hat einige Einschränkungen, an deren Überwindung die Community kontinuierlich arbeitet:
- Tabellen müssen zwischen Veröffentlichung und Abonnement denselben vollständig qualifizierten Namen haben.
- Tabellen müssen einen Primärschlüssel oder einen eindeutigen Schlüssel haben
- Gegenseitige (bidirektionale) Replikation wird nicht unterstützt
- Repliziert Schema/DDL nicht
- Repliziert keine Sequenzen
- Repliziert TRUNCATE nicht
- Repliziert keine großen Objekte
- Abonnements können mehr Spalten oder eine andere Spaltenreihenfolge haben, aber die Typen und Spaltennamen müssen zwischen Veröffentlichung und Abonnement übereinstimmen.
- Superuser-Rechte zum Hinzufügen aller Tabellen
- Sie können nicht auf denselben Host streamen (das Abonnement wird gesperrt).
So erreichen Sie eine logische Replikation
Hier sind die Schritte zum Erreichen einer grundlegenden logischen Replikation. Wir können später über komplexere Szenarien diskutieren.
-
Zwei verschiedene Instanzen für Veröffentlichung und Abonnement initialisieren und starten.
C1MQV0FZDTY3:bin bajishaik$ export PATH=$PWD:$PATH C1MQV0FZDTY3:bin bajishaik$ which psql /Users/bajishaik/pg_software/10.2/bin/psql C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/publication_db C1MQV0FZDTY3:bin bajishaik$ ./initdb -D /tmp/subscription_db -
Parameter, die geändert werden müssen, bevor Sie die Instanzen starten (sowohl für Veröffentlichungs- als auch für Abonnementinstanzen).
C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/publication_db/postgresql.conf listen_addresses='*' port = 5555 wal_level= logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/publication_db/ start waiting for server to start....2018-03-21 16:03:30.394 IST [24344] LOG: listening on IPv4 address "0.0.0.0", port 5555 2018-03-21 16:03:30.395 IST [24344] LOG: listening on IPv6 address "::", port 5555 2018-03-21 16:03:30.544 IST [24344] LOG: listening on Unix socket "/tmp/.s.PGSQL.5555" 2018-03-21 16:03:30.662 IST [24345] LOG: database system was shut down at 2018-03-21 16:03:27 IST 2018-03-21 16:03:30.677 IST [24344] LOG: database system is ready to accept connections done server started C1MQV0FZDTY3:bin bajishaik$ tail -3 /tmp/subscription_db/postgresql.conf listen_addresses='*' port=5556 wal_level=logical C1MQV0FZDTY3:bin bajishaik$ pg_ctl -D /tmp/subscription_db/ start waiting for server to start....2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv4 address "0.0.0.0", port 5556 2018-03-21 16:05:28.408 IST [24387] LOG: listening on IPv6 address "::", port 5556 2018-03-21 16:05:28.410 IST [24387] LOG: listening on Unix socket "/tmp/.s.PGSQL.5556" 2018-03-21 16:05:28.460 IST [24388] LOG: database system was shut down at 2018-03-21 15:59:32 IST 2018-03-21 16:05:28.512 IST [24387] LOG: database system is ready to accept connections done server startedAndere Parameter können für die Grundeinstellung voreingestellt sein.
-
Ändern Sie die Datei pg_hba.conf, um die Replikation zuzulassen. Beachten Sie, dass diese Werte von Ihrer Umgebung abhängen, dies ist jedoch nur ein einfaches Beispiel (sowohl für Veröffentlichungs- als auch für Abonnementinstanzen).
C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/publication_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ tail -1 /tmp/subscription_db/pg_hba.conf host all repuser 0.0.0.0/0 md5 C1MQV0FZDTY3:bin bajishaik$ psql -p 5555 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:19.271 IST [24344] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 16.103 ms C1MQV0FZDTY3:bin bajishaik$ psql -p 5556 -U bajishaik -c "select pg_reload_conf()" Timing is on. Pager usage is off. 2018-03-21 16:08:29.929 IST [24387] LOG: received SIGHUP, reloading configuration files pg_reload_conf ---------------- t (1 row) Time: 53.542 ms C1MQV0FZDTY3:bin bajishaik$ -
Erstellen Sie ein paar Testtabellen zum Replizieren und fügen Sie einige Daten in die Veröffentlichungsinstanz ein.
postgres=# create database source_rep; CREATE DATABASE Time: 662.342 ms postgres=# \c source_rep You are now connected to database "source_rep" as user "bajishaik". source_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 63.706 ms source_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 65.187 ms source_rep=# insert into test_rep values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 2.679 ms source_rep=# insert into test_rep_other values(generate_series(1,100),'data'||generate_series(1,100)); INSERT 0 100 Time: 1.848 ms source_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.513 ms source_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.488 ms source_rep=# -
Erstellen Sie eine Struktur der Tabellen in der Abonnementinstanz, da die logische Replikation die Struktur nicht repliziert.
postgres=# create database target_rep; CREATE DATABASE Time: 514.308 ms postgres=# \c target_rep You are now connected to database "target_rep" as user "bajishaik". target_rep=# create table test_rep_other(id int primary key, name varchar); CREATE TABLE Time: 9.684 ms target_rep=# create table test_rep(id int primary key, name varchar); CREATE TABLE Time: 5.374 ms target_rep=# -
Veröffentlichung auf Veröffentlichungsinstanz erstellen (Port 5555).
source_rep=# CREATE PUBLICATION mypub FOR TABLE test_rep, test_rep_other; CREATE PUBLICATION Time: 3.840 ms source_rep=# -
Erstellen Sie ein Abonnement für die Abonnementinstanz (Port 5556) für die in Schritt 6 erstellte Veröffentlichung.
target_rep=# CREATE SUBSCRIPTION mysub CONNECTION 'dbname=source_rep host=localhost user=bajishaik port=5555' PUBLICATION mypub; NOTICE: created replication slot "mysub" on publisher CREATE SUBSCRIPTION Time: 81.729 msAus Protokoll:
2018-03-21 16:16:42.200 IST [24617] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.200 IST [24617] DETAIL: There are no running transactions. target_rep=# 2018-03-21 16:16:42.207 IST [24618] LOG: logical replication apply worker for subscription "mysub" has started 2018-03-21 16:16:42.217 IST [24619] LOG: starting logical decoding for slot "mysub" 2018-03-21 16:16:42.217 IST [24619] DETAIL: streaming transactions committing after 0/1616DB8, reading WAL from 0/1616D80 2018-03-21 16:16:42.217 IST [24619] LOG: logical decoding found consistent point at 0/1616D80 2018-03-21 16:16:42.217 IST [24619] DETAIL: There are no running transactions. 2018-03-21 16:16:42.219 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has started 2018-03-21 16:16:42.231 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has started 2018-03-21 16:16:42.260 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.260 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.267 IST [24623] LOG: logical decoding found consistent point at 0/1616DF0 2018-03-21 16:16:42.267 IST [24623] DETAIL: There are no running transactions. 2018-03-21 16:16:42.304 IST [24621] LOG: starting logical decoding for slot "mysub_16403_sync_16393" 2018-03-21 16:16:42.304 IST [24621] DETAIL: streaming transactions committing after 0/1616DF0, reading WAL from 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] LOG: logical decoding found consistent point at 0/1616DB8 2018-03-21 16:16:42.304 IST [24621] DETAIL: There are no running transactions. 2018-03-21 16:16:42.306 IST [24620] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep" has finished 2018-03-21 16:16:42.308 IST [24622] LOG: logical replication table synchronization worker for subscription "mysub", table "test_rep_other" has finishedWie Sie in der NOTICE-Nachricht sehen können, wurde ein Replikationsslot erstellt, der sicherstellt, dass die WAL-Bereinigung nicht durchgeführt werden sollte, bis erste Snapshot- oder Delta-Änderungen an die Zieldatenbank übertragen wurden. Dann begann der WAL-Sender mit der Dekodierung der Änderungen, und die Anwendung der logischen Replikation funktionierte, als Pub und Sub gestartet wurden. Dann startet es die Tabellensynchronisation.
-
Überprüfen Sie die Daten in der Abonnementinstanz.
target_rep=# select count(1) from test_rep; count ------- 100 (1 row) Time: 0.927 ms target_rep=# select count(1) from test_rep_other ; count ------- 100 (1 row) Time: 0.767 ms target_rep=#Wie Sie sehen, wurden die Daten durch den anfänglichen Snapshot repliziert.
-
Delta-Änderungen überprüfen.
C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.869 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5555 -d source_rep -c "insert into test_rep_other values(generate_series(101,200), 'data'||generate_series(101,200))" INSERT 0 100 Time: 3.211 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep" count ------- 200 (1 row) Time: 1.742 ms C1MQV0FZDTY3:bin bajishaik$ psql -d postgres -p 5556 -d target_rep -c "select count(1) from test_rep_other" count ------- 200 (1 row) Time: 1.480 ms C1MQV0FZDTY3:bin bajishaik$
Dies sind die Schritte für eine grundlegende Einrichtung der logischen Replikation.