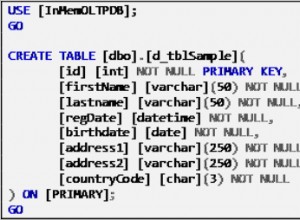
Read Committed ist die zweitschwächste der vier vom SQL-Standard definierten Isolationsstufen. Dennoch ist dies die Standardisolationsstufe für viele Datenbank-Engines, einschließlich SQL Server. Dieser Beitrag in einer Reihe über Isolationsstufen und die ACID-Eigenschaften von Transaktionen befasst sich mit den logischen und physischen Garantien, die tatsächlich durch Read Committed Isolation bereitgestellt werden.
Logische Garantien
Der SQL-Standard erfordert, dass eine Transaktion, die unter Lese-Committed-Isolation ausgeführt wird, nur committed liest Daten. Es drückt diese Anforderung aus, indem es das als Dirty Read bekannte Nebenläufigkeitsphänomen verbietet. Ein Dirty Read tritt auf, wenn eine Transaktion Daten liest, die von einer anderen Transaktion geschrieben wurden, bevor diese zweite Transaktion abgeschlossen ist. Eine andere Möglichkeit, dies auszudrücken, ist zu sagen, dass ein Dirty Read auftritt, wenn eine Transaktion nicht festgeschriebene Daten liest.
Der Standard erwähnt auch, dass eine Transaktion, die mit Read-Commited-Isolation ausgeführt wird, auf Parallelitätsphänomene stoßen kann, die als nicht wiederholbare Lesevorgänge bekannt sind und Phantome . Obwohl viele Bücher diese Phänomene dahingehend erklären, dass eine Transaktion geänderte oder neue Datenelemente sehen kann, wenn die Daten anschließend erneut gelesen werden, kann diese Erklärung das Missverständnis verstärken dass Nebenläufigkeitsphänomene nur innerhalb einer expliziten Transaktion auftreten können, die mehrere Anweisungen enthält. Das ist nicht so. Eine einzelne Anweisung ohne explizite Transaktion ist genauso anfällig für nicht wiederholbare Lese- und Phantomphänomene, wie wir gleich sehen werden.
Das ist so ziemlich alles, was der Standard zum Thema Read Committed Isolation zu sagen hat. Auf den ersten Blick scheint das Lesen nur von Committed-Daten eine ziemlich gute Garantie für vernünftiges Verhalten zu sein, aber wie immer steckt der Teufel im Detail. Sobald Sie beginnen, nach potenziellen Schlupflöchern zu suchen In dieser Definition wird es nur zu einfach, Fälle zu finden, in denen unsere gelesenen festgeschriebenen Transaktionen möglicherweise nicht die erwarteten Ergebnisse liefern. Auch diese werden wir in ein oder zwei Momenten ausführlicher besprechen.
Unterschiedliche physische Implementierungen
Es gibt mindestens zwei Dinge, die bedeuten, dass das beobachtete Verhalten der Read Committed-Isolationsstufe auf verschiedenen Datenbank-Engines sehr unterschiedlich sein kann. Erstens gilt die Anforderung des SQL-Standards, nur festgeschriebene Daten zu lesen, nicht bedeutet zwangsläufig, dass die von einer Transaktion gelesenen festgeschriebenen Daten die neuesten sind festgeschriebene Daten.
Eine Datenbank-Engine darf eine festgeschriebene Version einer Zeile von jedem Zeitpunkt in der Vergangenheit lesen , und entsprechen dennoch der SQL-Standarddefinition. Mehrere gängige Datenbankprodukte implementieren auf diese Weise Read-Committed-Isolation. Abfrageergebnisse, die mit dieser Implementierung der Read-Committed-Isolation erzielt wurden, können willkürlich veraltet sein , verglichen mit dem aktuellen festgeschriebenen Zustand der Datenbank. Wir werden dieses Thema in Bezug auf SQL Server im nächsten Beitrag dieser Serie behandeln.
Zweitens möchte ich Ihre Aufmerksamkeit darauf lenken, dass die SQL-Standarddefinition dies nicht tut verhindern, dass eine bestimmte Implementierung über das Verhindern von dirty reads hinaus zusätzlichen Schutz vor Nebenläufigkeitseffekten bietet . Der Standard spezifiziert nur, dass Dirty Reads nicht erlaubt sind, er verlangt nicht, dass andere Nebenläufigkeitsphänomene erlaubt werden müssen bei jeder gegebenen Isolationsstufe.
Um diesen zweiten Punkt klarzustellen, könnte eine standardkonforme Datenbank-Engine alle Isolationsstufen mit serialisierbar implementieren Verhalten, wenn es so wollte. Einige große kommerzielle Datenbank-Engines bieten auch eine Implementierung von Read Committed, die weit über das bloße Verhindern von Dirty Reads hinausgeht (obwohl keine so weit geht, eine vollständige Isolierung in der ACID bereitzustellen Sinn des Wortes).
Darüber hinaus sollten Sie für mehrere beliebte Produkte bestätigt lesen Isolation ist die niedrigste Isolationsstufe verfügbar; ihre Implementierungen von read uncommitted Isolation sind genau die gleichen wie Read Committed. Der Standard erlaubt dies, aber diese Art von Unterschieden erhöht die Komplexität der ohnehin schon schwierigen Aufgabe, Code von einer Plattform auf eine andere zu migrieren. Wenn es um das Verhalten einer Isolationsstufe geht, ist es normalerweise wichtig, auch die jeweilige Plattform anzugeben.
Soweit ich weiß, ist SQL Server unter den großen kommerziellen Datenbank-Engines einzigartig, da es zwei bereitstellt Implementierungen der Isolationsstufe „Read Committed“ mit jeweils sehr unterschiedlichen physikalischen Verhaltensweisen. Dieser Beitrag befasst sich mit dem ersten davon, dem Sperren read commited.
SQL Server Locking Read Committed
Wenn die Datenbankoption READ_COMMITTED_SNAPSHOT ist OFF verwendet SQL Server eine Sperre Implementierung der Read-Commited-Isolationsstufe, bei der gemeinsam genutzte Sperren verwendet werden, um zu verhindern, dass eine gleichzeitige Transaktion gleichzeitig die Daten ändert, da die Änderung eine exklusive Sperre erfordern würde, die nicht mit der gemeinsam genutzten Sperre kompatibel ist.
Der Hauptunterschied zwischen dem Sperren von Read Committed in SQL Server und dem Sperren von wiederholbarem Lesen (das beim Lesen von Daten auch gemeinsame Sperren verwendet) besteht darin, dass Read Committed die gemeinsame Sperre so schnell wie möglich freigibt , während wiederholbares Lesen diese Sperren bis zum Ende der einschließenden Transaktion aufrechterhält.
Wenn das Sperren von Read Committed Sperren mit Zeilengranularität erwirbt, wird die gemeinsame Sperre, die für eine Zeile genommen wurde, freigegeben wenn eine gemeinsame Sperre auf die nächste Zeile gesetzt wird . Bei Seitengranularität wird die gemeinsam genutzte Seitensperre aufgehoben, wenn die erste Zeile auf der nächsten Seite gelesen wird, und so weiter. Sofern mit der Abfrage kein Sperrgranularitätshinweis bereitgestellt wird, entscheidet die Datenbank-Engine, mit welcher Granularitätsebene begonnen wird. Beachten Sie, dass Hinweise zur Granularität von der Engine nur als Vorschläge behandelt werden, eine weniger granulare Sperre als angefordert könnte anfangs dennoch verwendet werden. Abhängig von der Systemkonfiguration können Sperren auch während der Ausführung von Zeilen- oder Seitenebene auf Partitions- oder Tabellenebene eskaliert werden.
Der wichtige Punkt hier ist, dass gemeinsame Sperren normalerweise nur für eine sehr kurze Zeit gehalten werden während die Anweisung ausgeführt wird. Um ein weit verbreitetes Missverständnis explizit anzusprechen:Das Sperren von Read Committed ist nicht gemeinsam genutzte Sperren bis zum Ende der Anweisung halten.
Sperren von Committed-Leseverhalten
Die kurzfristigen freigegebenen Sperren, die von der SQL Server-Sperr-Read-Committed-Implementierung verwendet werden, bieten nur sehr wenige der Garantien, die üblicherweise von T-SQL-Programmierern von einer Datenbanktransaktion erwartet werden. Insbesondere eine Anweisung, die unter Sperren läuft read commit Isolierung:
- Kann mehrmals auf dieselbe Zeile stoßen;
- Kann einige Zeilen komplett übersehen; und
- Tut nicht bieten eine zeitpunktbezogene Ansicht der Daten
Diese Liste scheint eher wie eine Beschreibung der seltsamen Verhaltensweisen zu sein, die Sie möglicherweise eher mit der Verwendung von NOLOCK in Verbindung bringen Hinweise, aber all diese Dinge können wirklich passieren und passieren, wenn Sie die gesperrte Read-Commited-Isolation verwenden.
Beispiel
Betrachten Sie die einfache Aufgabe, die Zeilen in einer Tabelle zu zählen, indem Sie die offensichtliche Abfrage mit einer einzigen Anweisung verwenden. Beim Locking Read Committed Isolation mit Row-Locking-Granularität nimmt unsere Abfrage eine gemeinsame Sperre für die erste Zeile, liest sie, hebt die gemeinsame Sperre auf, fährt mit der nächsten Zeile fort und so weiter, bis sie das Ende der Struktur it erreicht liest. Nehmen wir für dieses Beispiel an, dass unsere Abfrage einen Index-B-Baum in aufsteigender Schlüsselreihenfolge liest (obwohl sie genauso gut eine absteigende Reihenfolge oder eine andere Strategie verwenden könnte).
Da nur eine einzige Zeile zu jedem Zeitpunkt geteilt gesperrt ist, ist es für gleichzeitige Transaktionen eindeutig möglich, die entsperrten Zeilen in dem Index zu ändern, den unsere Abfrage durchläuft. Wenn diese gleichzeitigen Änderungen Indexschlüsselwerte ändern, bewirken sie, dass Zeilen innerhalb der Indexstruktur verschoben werden. Unter Berücksichtigung dieser Möglichkeit veranschaulicht das folgende Diagramm zwei problematische Szenarien, die auftreten können:
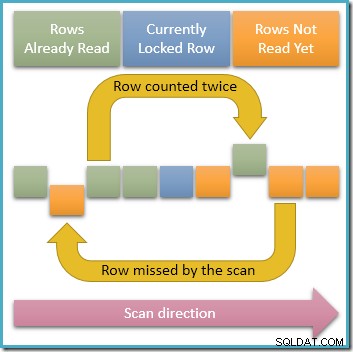
Der oberste Pfeil zeigt eine Zeile, die wir bereits gezählt haben, deren Indexschlüssel gleichzeitig geändert wird, sodass die Zeile vor die aktuelle Scan-Position im Index verschoben wird, was bedeutet, dass die Zeile zweimal gezählt wird . Der zweite Pfeil zeigt eine Reihe, die unser Scan noch nicht angetroffen hat, die sich jedoch hinter die Scanposition bewegt, was bedeutet, dass die Reihe nicht gezählt wird überhaupt.
Keine Point-in-Time-Ansicht
Der vorherige Abschnitt hat gezeigt, wie das Sperren von festgeschriebenen Lesevorgängen Daten vollständig übersehen oder dasselbe Element mehrmals zählen kann (mehr als zweimal, wenn wir Pech haben). Der dritte Aufzählungspunkt in der Liste der unerwarteten Verhaltensweisen besagt, dass das Sperren von Read Committed auch keine Point-in-Time-Ansicht der Daten bietet.
Die Argumentation hinter dieser Aussage sollte jetzt leicht zu erkennen sein. Unsere Zählabfrage könnte beispielsweise problemlos Daten lesen, die durch gleichzeitige Transaktionen eingefügt wurden, nachdem unsere Abfrage mit der Ausführung begonnen hatte. Ebenso können Daten, die unsere Abfrage sieht, durch gleichzeitige Aktivitäten geändert werden, nachdem unsere Abfrage gestartet und bevor sie abgeschlossen wurde. Schließlich können Daten, die wir gelesen und gezählt haben, durch eine gleichzeitige Transaktion gelöscht werden, bevor unsere Abfrage abgeschlossen ist.
Die Daten, die von einer Anweisung oder Transaktion gesehen werden, die unter Locking-Read-Committed-Isolation ausgeführt werden, entsprechen eindeutig kein einzelnem Zustand der Datenbank zu einem bestimmten Zeitpunkt . Die Daten, auf die wir stoßen, können sehr wohl von verschiedenen Zeitpunkten stammen, wobei der einzige gemeinsame Faktor darin besteht, dass jedes Element den letzten festgeschriebenen Wert dieser Daten zum Zeitpunkt des Lesens darstellt (obwohl es sich seitdem geändert oder verschwunden sein könnte).
Wie ernst sind diese Probleme?
Dies alles mag wie ein ziemlich schwammiger Sachverhalt erscheinen, wenn Sie daran gewöhnt sind, Ihre Einzelanweisungsabfragen und expliziten Transaktionen als logisch sofort ausgeführt zu betrachten oder bei Verwendung von gegen einen einzigen festgeschriebenen Point-in-Time-Zustand der Datenbank zu laufen standardmäßige SQL Server-Isolationsstufe. Es passt sicherlich nicht gut zum Konzept der Isolation im ACID-Sinne.
Angesichts der offensichtlichen Schwäche der Garantien, die durch das Sperren der Read-Committed-Isolation bereitgestellt werden, fragen Sie sich vielleicht, wie irgendwelche Ihres Produktions-T-SQL-Codes hat jemals richtig funktioniert! Natürlich können wir akzeptieren, dass die Verwendung einer Isolationsstufe unterhalb der Serialisierbarkeit bedeutet, dass wir die vollständige ACID-Transaktionsisolation im Gegenzug für andere potenzielle Vorteile aufgeben, aber wie ernst können wir diese Probleme in der Praxis erwarten?
Fehlende und doppelt gezählte Zeilen
Diese ersten beiden Probleme beruhen im Wesentlichen auf gleichzeitiger Aktivität, die Schlüssel ändert in einer Indexstruktur, die wir gerade scannen. Beachten Sie, dass Scannen enthält hier den partiellen Bereichsscan-Teil einer Index-Suche , sowie der bekannte uneingeschränkte Index- oder Tabellenscan.
Wenn wir eine Indexstruktur (Bereichs-)scannen, deren Schlüssel normalerweise nicht durch gleichzeitige Aktivitäten geändert werden, sollten diese ersten beiden Probleme kein großes praktisches Problem darstellen. Es ist jedoch schwierig, sich darüber sicher zu sein, da Abfragepläne geändert werden können, um eine andere Zugriffsmethode zu verwenden, und der neue Suchindex möglicherweise flüchtige Schlüssel enthält.
Wir müssen auch bedenken, dass viele Produktionsabfragen nur einen ungefähren Wert benötigen oder sowieso die bestmögliche Antwort auf einige Arten von Fragen. Die Tatsache, dass einige Zeilen fehlen oder doppelt gezählt werden, spielt im weiteren Sinne möglicherweise keine Rolle. Auf einem System mit vielen gleichzeitigen Änderungen kann es sogar schwierig sein, sicher zu sein, dass das Ergebnis war ungenau, da sich die Daten so häufig ändern. In einer solchen Situation könnte eine ungefähr richtige Antwort für die Zwecke des Datenverbrauchers ausreichen.
Keine Point-in-Time-Ansicht
Auch der dritte Punkt (die Frage einer sogenannten „konsistenten“ zeitpunktbezogenen Betrachtung der Daten) läuft auf die gleiche Art von Überlegungen hinaus. Für Berichterstellungszwecke, wo Inkonsistenzen dazu neigen, unangenehme Fragen von den Datennutzern nach sich zu ziehen, ist eine Momentaufnahme häufig vorzuziehen. In anderen Fällen kann die Art von Inkonsistenzen, die sich aus der fehlenden Point-in-Time-Ansicht der Daten ergeben, durchaus tolerierbar sein.
Problemszenarien
Es gibt auch viele Fälle, in denen die aufgeführten Bedenken werden wichtig sein. Zum Beispiel, wenn Sie Code schreiben, der Geschäftsregeln erzwingt In T-SQL müssen Sie darauf achten, eine Isolationsstufe auszuwählen (oder andere geeignete Maßnahmen zu ergreifen), um die Korrektheit zu gewährleisten. Viele Geschäftsregeln können mithilfe von Fremdschlüsseln oder Einschränkungen erzwungen werden, wobei die Feinheiten der Auswahl der Isolationsstufe automatisch von der Datenbank-Engine für Sie gehandhabt werden. Als allgemeine Faustregel gilt:Verwenden Sie den integrierten Satz der deklarativen Integrität Funktionen ist dem Erstellen eigener Regeln in T-SQL vorzuziehen.
Es gibt eine weitere breite Klasse von Abfragen, die eine Geschäftsregel per se nicht ganz durchsetzen , was aber dennoch unglückliche Folgen haben könnte, wenn es auf der standardmäßigen Isolationsstufe zum Sperren von Lesebestätigungen ausgeführt wird. Diese Szenarien sind nicht immer so offensichtlich wie die oft zitierten Beispiele für die Überweisung von Geld zwischen Bankkonten oder die Sicherstellung, dass der Kontostand mehrerer verknüpfter Konten niemals unter Null fällt. Betrachten Sie beispielsweise die folgende Abfrage, die überfällige Rechnungen als Eingabe für einen Prozess identifiziert, der streng formulierte Mahnschreiben versendet:
INSERT dbo.OverdueInvoices
SELECT I.InvoiceNumber
FROM dbo.Invoices AS INV
WHERE INV.TotalDue >
(
SELECT SUM(P.Amount)
FROM dbo.Payments AS P
WHERE P.InvoiceNumber = I.InvoiceNumber
); Natürlich möchten wir niemandem einen Brief schicken, der seine Rechnung vollständig in Raten bezahlt hat, nur weil gleichzeitige Datenbankaktivitäten zum Zeitpunkt unserer Abfrage dazu geführt haben, dass wir eine falsche Summe berechnet haben der erhaltenen Zahlungen. Reale Abfragen auf realen Produktionssystemen sind natürlich häufig viel komplexer als das obige einfache Beispiel.
Werfen Sie zum Abschluss für heute einen Blick auf die folgende Abfrage und prüfen Sie, ob Sie erkennen können, wie viele Gelegenheiten für unbeabsichtigte Ereignisse bestehen, wenn mehrere solcher Abfragen gleichzeitig auf der Isolationsstufe Locking Read Committed ausgeführt werden (möglicherweise während andere nicht verwandte Transaktionen ändern auch die Cases-Tabelle):
-- Allocate the oldest unallocated case ID to
-- the current case worker, while ensuring
-- the worker never has more than three
-- active cases at once.
UPDATE dbo.Cases
SET WorkerID = @WorkerID
WHERE
CaseID =
(
-- Find the oldest unallocated case ID
SELECT TOP (1)
C2.CaseID
FROM dbo.Cases AS C2
WHERE
C2.WorkerID IS NULL
ORDER BY
C2.DateCreated DESC
)
AND
(
SELECT COUNT_BIG(*)
FROM dbo.Cases AS C3
WHERE C3.WorkerID = @WorkerID
) < 3; Sobald Sie anfangen, nach all den kleinen Möglichkeiten zu suchen, wie eine Abfrage auf dieser Isolationsstufe schief gehen kann, kann es schwierig sein, sie zu stoppen. Beachten Sie die zuvor erwähnten Vorbehalte in Bezug auf die tatsächliche Notwendigkeit vollständig isolierter und zeitpunktgenauer Ergebnisse. Es ist völlig in Ordnung, Abfragen zu haben, die ausreichend gute Ergebnisse liefern, solange Sie sich der Kompromisse bewusst sind, die Sie durch die Verwendung von Read Committed eingehen.
Nächstes Mal
Der nächste Teil dieser Reihe befasst sich mit der zweiten physischen Implementierung der Read-Committed-Isolation, die in SQL Server verfügbar ist, der Read-Committed-Snapshot-Isolation.
[Siehe den Index für die gesamte Serie]