Kenntnisse der Replikation sind ein Muss für jeden, der Datenbanken verwaltet. Es ist ein Thema, das Sie wahrscheinlich immer wieder gesehen haben, aber nie alt werden. In diesem Blog gehen wir ein wenig auf die Geschichte der integrierten Replikationsfunktionen von PostgreSQL ein und tauchen tief in die Funktionsweise der Streaming-Replikation ein.
Wenn wir über Replikation sprechen, werden wir viel über WALs sprechen. Lassen Sie uns also schnell ein wenig über Write-Ahead-Protokolle sprechen.
Write-Ahead-Protokoll (WAL)
Ein Write-Ahead-Protokoll ist eine Standardmethode zur Sicherstellung der Datenintegrität und wird standardmäßig automatisch aktiviert.
Die WALs sind die REDO-Protokolle in PostgreSQL. Aber was genau sind REDO-Logs?
REDO-Protokolle enthalten alle in der Datenbank vorgenommenen Änderungen und werden für die Replikation, Wiederherstellung, Online-Sicherung und Point-in-Time-Recovery (PITR) verwendet. Alle Änderungen, die nicht auf die Datenseiten angewendet wurden, können aus den REDO-Protokollen wiederhergestellt werden.
Die Verwendung von WAL führt zu einer erheblich geringeren Anzahl von Schreibvorgängen auf der Festplatte, da nur die Protokolldatei auf die Festplatte geleert werden muss, um sicherzustellen, dass eine Transaktion festgeschrieben wird, und nicht jede Datendatei, die durch die Transaktion geändert wird.
P>Ein WAL-Datensatz gibt die an den Daten vorgenommenen Änderungen Stück für Stück an. Jeder WAL-Datensatz wird an eine WAL-Datei angehängt. Die Einfügeposition ist eine Log Sequence Number (LSN), ein Byte-Offset in den Logs, der mit jedem neuen Datensatz ansteigt.
Die WALs werden im Verzeichnis pg_wal (oder pg_xlog in PostgreSQL-Versionen <10) unter dem Datenverzeichnis gespeichert. Diese Dateien haben eine Standardgröße von 16 MB (Sie können die Größe ändern, indem Sie beim Erstellen des Servers die Konfigurationsoption --with-wal-segsize ändern). Sie haben einen eindeutigen inkrementellen Namen im folgenden Format:"00000001 00000000 00000000".
Die Anzahl der in pg_wal enthaltenen WAL-Dateien hängt von dem Wert ab, der dem Parameter checkpoint_segments (oder min_wal_size und max_wal_size, je nach Version) in der Konfigurationsdatei postgresql.conf zugewiesen wurde.
Ein Parameter, den Sie einrichten müssen, wenn Sie alle Ihre PostgreSQL-Installationen konfigurieren, ist wal_level. Der wal_level bestimmt, wie viele Informationen in die WAL geschrieben werden. Der Standardwert ist minimal, wodurch nur die Informationen geschrieben werden, die zur Wiederherstellung nach einem Absturz oder sofortigen Herunterfahren erforderlich sind. Archive fügt die für die WAL-Archivierung erforderliche Protokollierung hinzu; hot_standby fügt weitere Informationen hinzu, die benötigt werden, um schreibgeschützte Abfragen auf einem Standby-Server auszuführen; logical fügt Informationen hinzu, die zur Unterstützung der logischen Dekodierung erforderlich sind. Dieser Parameter erfordert einen Neustart, daher kann es schwierig sein, ihn in laufenden Produktionsdatenbanken zu ändern, wenn Sie das vergessen haben.
Weitere Informationen finden Sie in der offiziellen Dokumentation hier oder hier. Nachdem wir nun die WAL behandelt haben, sehen wir uns den Verlauf der Replikation in PostgreSQL an.
Replikationsverlauf in PostgreSQL
Die erste von PostgreSQL implementierte Replikationsmethode (Warm-Standby) (Version 8.2, damals 2006) basierte auf der Protokollversandmethode.
Das bedeutet, dass die WAL-Einträge direkt von einem Datenbankserver auf einen anderen verschoben werden, um angewendet zu werden. Wir können sagen, dass es sich um ein kontinuierliches PITR handelt.
PostgreSQL implementiert den dateibasierten Protokollversand, indem WAL-Datensätze jeweils nur eine Datei (WAL-Segment) übertragen werden.
Diese Replikationsimplementierung hat die Kehrseite:Bei einem größeren Ausfall auf den Primärservern gehen noch nicht versendete Transaktionen verloren. Es gibt also ein Fenster für Datenverlust (Sie können dies mit dem Parameter archive_timeout einstellen, der auf wenige Sekunden eingestellt werden kann. Eine so niedrige Einstellung erhöht jedoch die für den Dateiversand erforderliche Bandbreite erheblich).
Wir können diese dateibasierte Protokollversandmethode mit dem folgenden Bild darstellen:
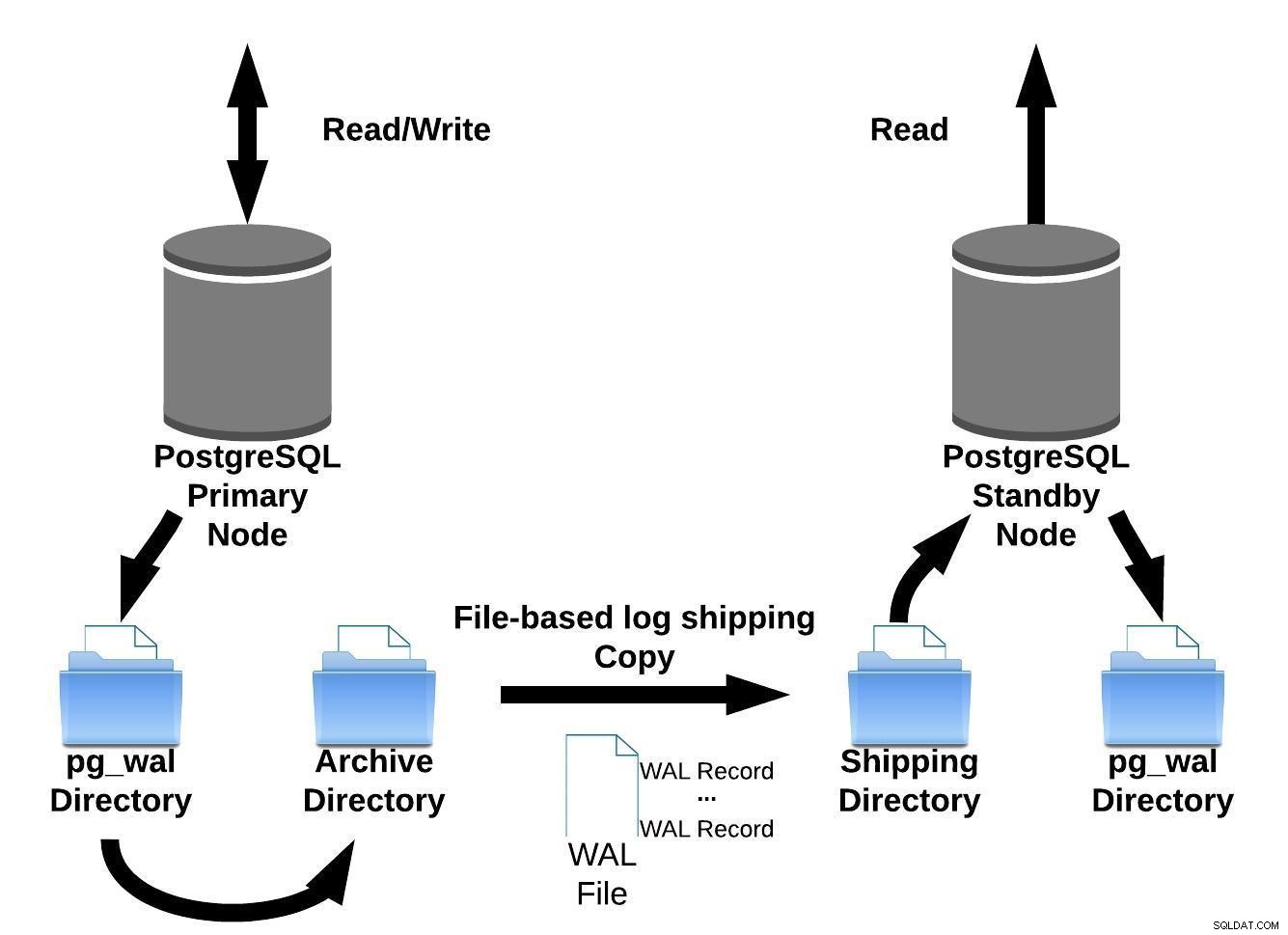 Dateibasierter PostgreSQL-Protokollversand
Dateibasierter PostgreSQL-ProtokollversandIn Version 9.0 (damals im Jahr 2010 ) wurde die Streaming-Replikation eingeführt.
Streaming-Replikation ermöglicht es Ihnen, aktueller zu bleiben, als dies mit dateibasiertem Protokollversand möglich ist. Dies funktioniert durch die Übertragung von WAL-Datensätzen (eine WAL-Datei besteht aus WAL-Datensätzen) im laufenden Betrieb (datensatzbasierter Protokollversand) zwischen einem primären Server und einem oder mehreren Standby-Servern, ohne darauf zu warten, dass die WAL-Datei gefüllt wird.
In der Praxis verbindet sich ein Prozess namens WAL-Empfänger, der auf dem Standby-Server läuft, über eine TCP/IP-Verbindung mit dem Primärserver. Auf dem primären Server existiert ein weiterer Prozess namens WAL-Sender, der für das Senden der WAL-Registrierungen an den Standby-Server zuständig ist, während sie auftreten.
Das folgende Diagramm stellt die Streaming-Replikation dar:
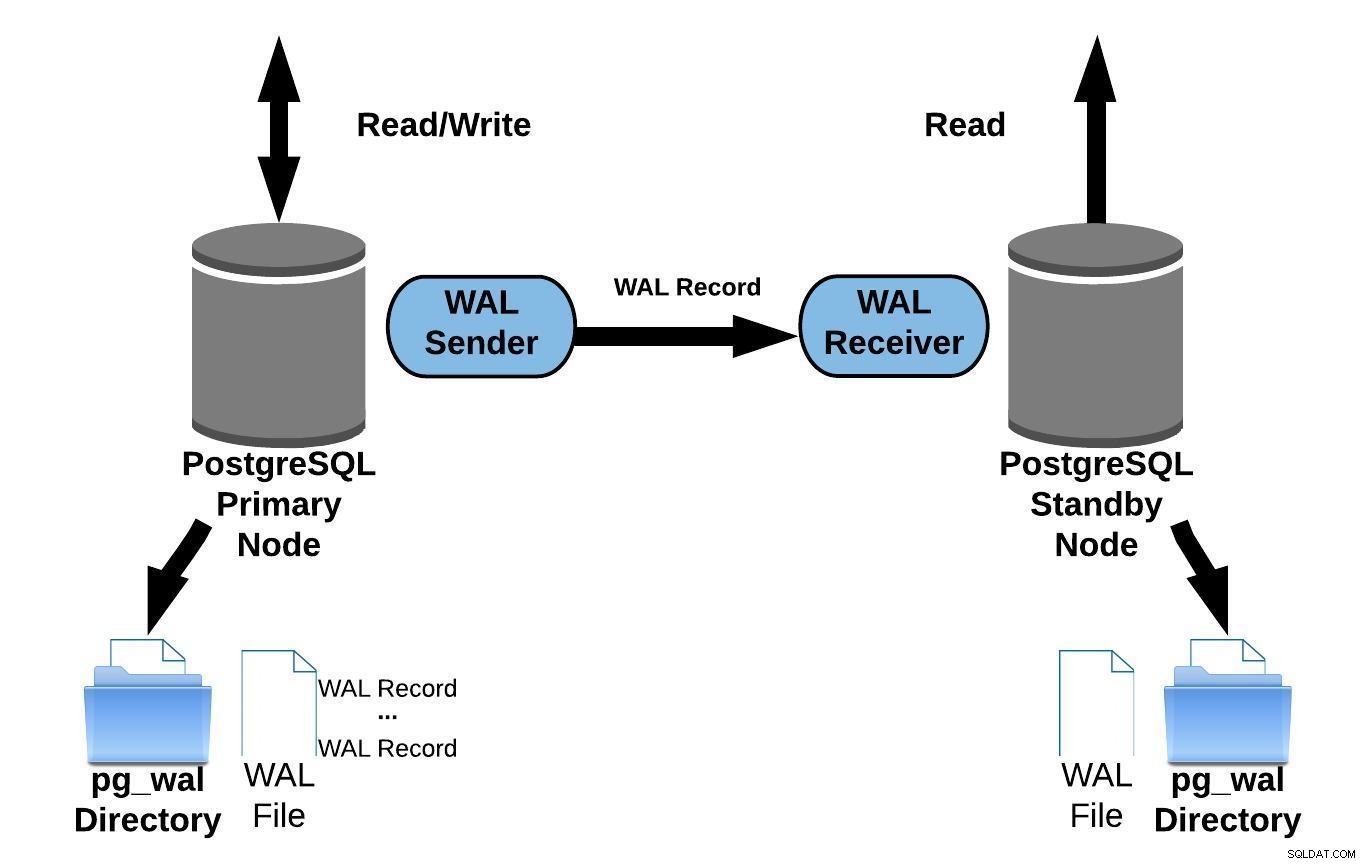 PostgreSQL-Streaming-Replikation
PostgreSQL-Streaming-ReplikationWenn Sie sich das obige Diagramm ansehen, fragen Sie sich vielleicht, was passiert wenn die Kommunikation zwischen dem WAL-Sender und dem WAL-Empfänger fehlschlägt?
Bei der Konfiguration der Streaming-Replikation haben Sie die Möglichkeit, die WAL-Archivierung zu aktivieren.
Dieser Schritt ist nicht obligatorisch, aber äußerst wichtig für eine robuste Replikationskonfiguration. Es muss verhindert werden, dass der Hauptserver alte WAL-Dateien recycelt, die noch nicht auf den Standby-Server angewendet wurden. In diesem Fall müssen Sie das Replikat von Grund auf neu erstellen.
Wenn Sie die Replikation mit kontinuierlicher Archivierung konfigurieren, beginnt sie mit einem Backup. Um den synchronen Zustand mit dem primären zu erreichen, muss es alle Änderungen anwenden, die in der WAL gehostet werden, die nach der Sicherung vorgenommen wurden. Während dieses Vorgangs stellt der Standby-Modus zunächst alle am Archivspeicherort verfügbaren WAL wieder her (durch Aufrufen von restore_command). Der restore_command schlägt fehl, wenn er den letzten archivierten WAL-Eintrag erreicht, also wird der Standby im pg_wal-Verzeichnis nachsehen, ob die Änderung dort vorhanden ist (dies funktioniert, um Datenverlust zu vermeiden, wenn die primären Server abstürzen und einige Änderungen daran wurden bereits verschoben und auf das Replikat angewendet wurden noch nicht archiviert).
Wenn dies fehlschlägt und der angeforderte Datensatz dort nicht existiert, beginnt er mit der Kommunikation mit dem primären Server durch Streaming-Replikation.
Wenn die Streaming-Replikation fehlschlägt, kehrt sie zu Schritt 1 zurück und stellt die Datensätze erneut aus dem Archiv wieder her. Diese Wiederholungsschleife aus dem Archiv, pg_wal und über die Streaming-Replikation wird fortgesetzt, bis der Server stoppt oder ein Failover durch eine Triggerdatei ausgelöst wird.
Das folgende Diagramm stellt eine Streaming-Replikationskonfiguration mit kontinuierlicher Archivierung dar:
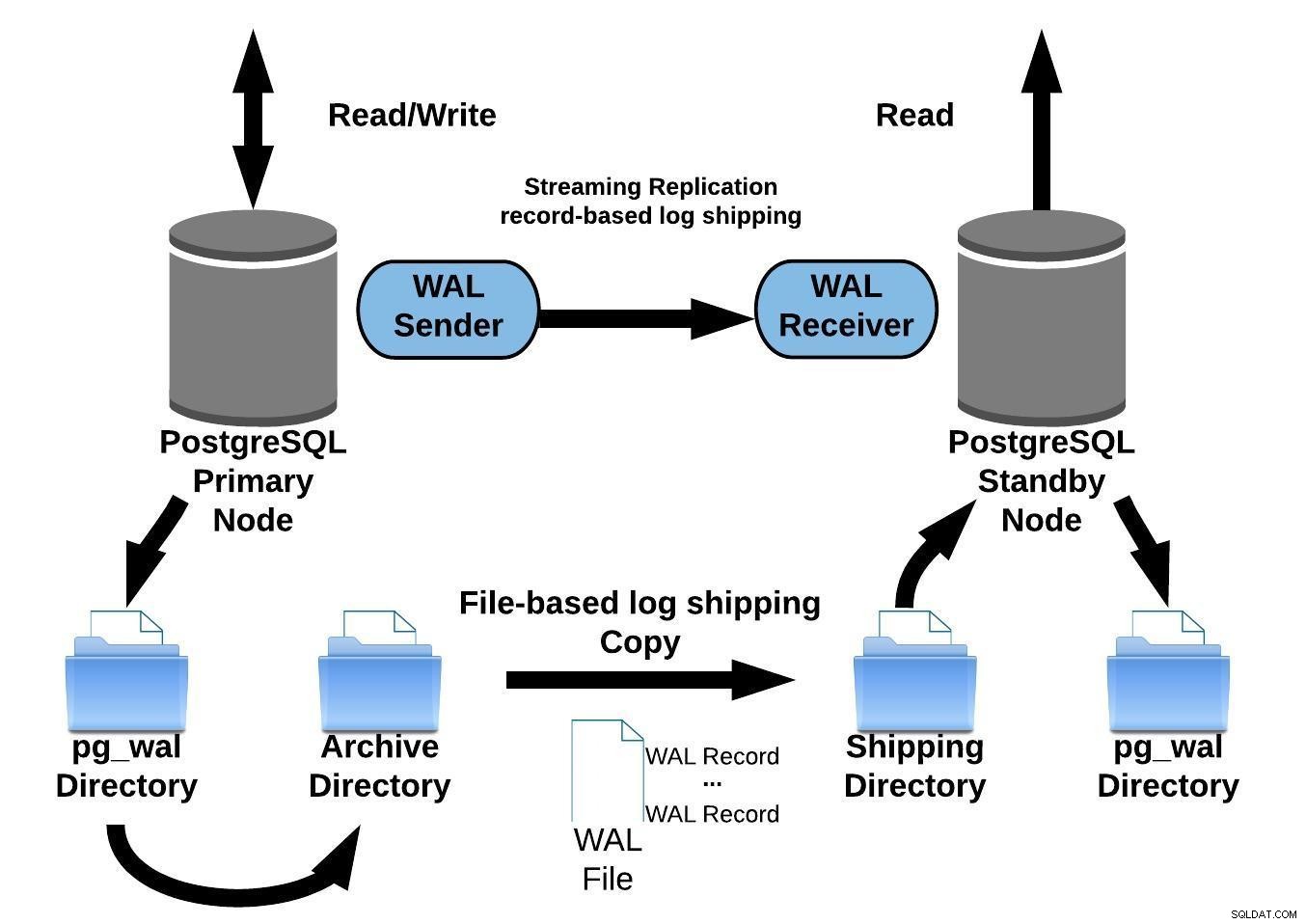 PostgreSQL-Streaming-Replikation mit kontinuierlicher Archivierung
PostgreSQL-Streaming-Replikation mit kontinuierlicher ArchivierungStreaming-Replikation ist standardmäßig asynchron, so weiter Zu jedem beliebigen Zeitpunkt können Sie einige Transaktionen haben, die auf dem primären Server festgeschrieben und noch nicht auf den Standby-Server repliziert werden können. Dies impliziert einen potenziellen Datenverlust.
Diese Verzögerung zwischen dem Commit und der Auswirkung der Änderungen in der Replik soll jedoch sehr gering sein (einige Millisekunden), vorausgesetzt natürlich, dass der Replikationsserver leistungsfähig genug ist, um damit Schritt zu halten die Ladung.
Für Fälle, in denen selbst das Risiko eines geringfügigen Datenverlusts nicht akzeptabel ist, wurde in Version 9.1 die synchrone Replikationsfunktion eingeführt.
Bei der synchronen Replikation wartet jeder Commit einer Schreibtransaktion, bis eine Bestätigung empfangen wird, dass der Commit auf die Write-Ahead-Log-On-Festplatte sowohl des Primär- als auch des Standby-Servers geschrieben wird.
Diese Methode minimiert die Möglichkeit eines Datenverlusts; Dazu müssen sowohl der Primär- als auch der Standby-Server gleichzeitig ausfallen.
Der offensichtliche Nachteil dieser Konfiguration ist, dass die Antwortzeit für jede Schreibtransaktion länger wird, da gewartet werden muss, bis alle Parteien geantwortet haben. Die Zeit für einen Commit ist also mindestens der Hin- und Rückweg zwischen dem primären und dem Replikat. Schreibgeschützte Transaktionen sind davon nicht betroffen.
Um die synchrone Replikation einzurichten, müssen Sie einen Anwendungsnamen in der primary_conninfo der Wiederherstellung für jede Standby-server.conf-Datei angeben:primary_conninfo ='...aplication_name=standbyX' .
Außerdem müssen Sie die Liste der Standby-Server angeben, die an der synchronen Replikation teilnehmen:synchroner_standby_name ='standbyX,standbyY'.
Sie können einen oder mehrere synchrone Server einrichten, und dieser Parameter gibt auch an, welche Methode (FIRST und ANY) aus den aufgelisteten synchronen Standbys ausgewählt werden soll. Weitere Informationen zum Einrichten des synchronen Replikationsmodus finden Sie in diesem Blog. Es ist auch möglich, eine synchrone Replikation beim Deployment über ClusterControl einzurichten.
Nachdem Sie Ihre Replikation konfiguriert haben und sie ausgeführt wird, müssen Sie die Überwachung implementieren
PostgreSQL-Replikation überwachen
Die pg_stat_replication-Ansicht auf dem Master-Server enthält viele relevante Informationen:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Sehen wir uns das im Detail an:
-
pid:Prozess-ID des Walsender-Prozesses.
-
usesysid:OID des Benutzers, der für die Streaming-Replikation verwendet wird.
-
usename:Name des Benutzers, der für die Streaming-Replikation verwendet wird.
-
application_name:Name der Anwendung, die mit dem Master verbunden ist.
-
client_addr:Adresse der Standby-/Streaming-Replikation.
-
client_hostname:Hostname des Standby.
-
client_port:TCP-Portnummer, auf der Standby mit dem WAL-Sender kommuniziert.
-
backend_start:Startzeit, wenn SR mit Primary verbunden ist.
-
state:Aktueller WAL-Senderstatus, d. h. Streaming.
-
sent_lsn:Letzter Transaktionsstandort an Standby gesendet.
-
write_lsn:Letzte Transaktion, die im Standby auf die Festplatte geschrieben wurde.
-
flush_lsn:Letzter Transaktions-Flush auf der Festplatte im Standby.
-
replay_lsn:Letzte Transaktionslöschung auf der Festplatte im Standby.
-
sync_priority:Priorität des Standby-Servers, der als synchroner Standby ausgewählt wurde.
-
sync_state:Sync-Status des Standby (ist es asynchron oder synchron).
Sie können auch die WAL-Sender/Empfänger-Prozesse sehen, die auf den Servern laufen.
Absender (primärer Knoten):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Empfänger (Standby-Knoten):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Eine Möglichkeit, die Aktualität Ihrer Replikation zu überprüfen, besteht darin, die Anzahl der WAL-Einträge zu überprüfen, die auf dem primären Server generiert, aber noch nicht auf den Standby-Server angewendet wurden.
Primär:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Standby:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Sie können die folgende Abfrage im Standby-Knoten verwenden, um die Verzögerung in Sekunden zu erhalten:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)Und Sie können auch die letzte empfangene Nachricht sehen:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Überwachung der PostgreSQL-Replikation mit ClusterControl
Um Ihren PostgreSQL-Cluster zu überwachen, können Sie ClusterControl verwenden, mit dem Sie mehrere zusätzliche Verwaltungsaufgaben wie Bereitstellung, Backups, Skalierung und mehr überwachen und ausführen können.
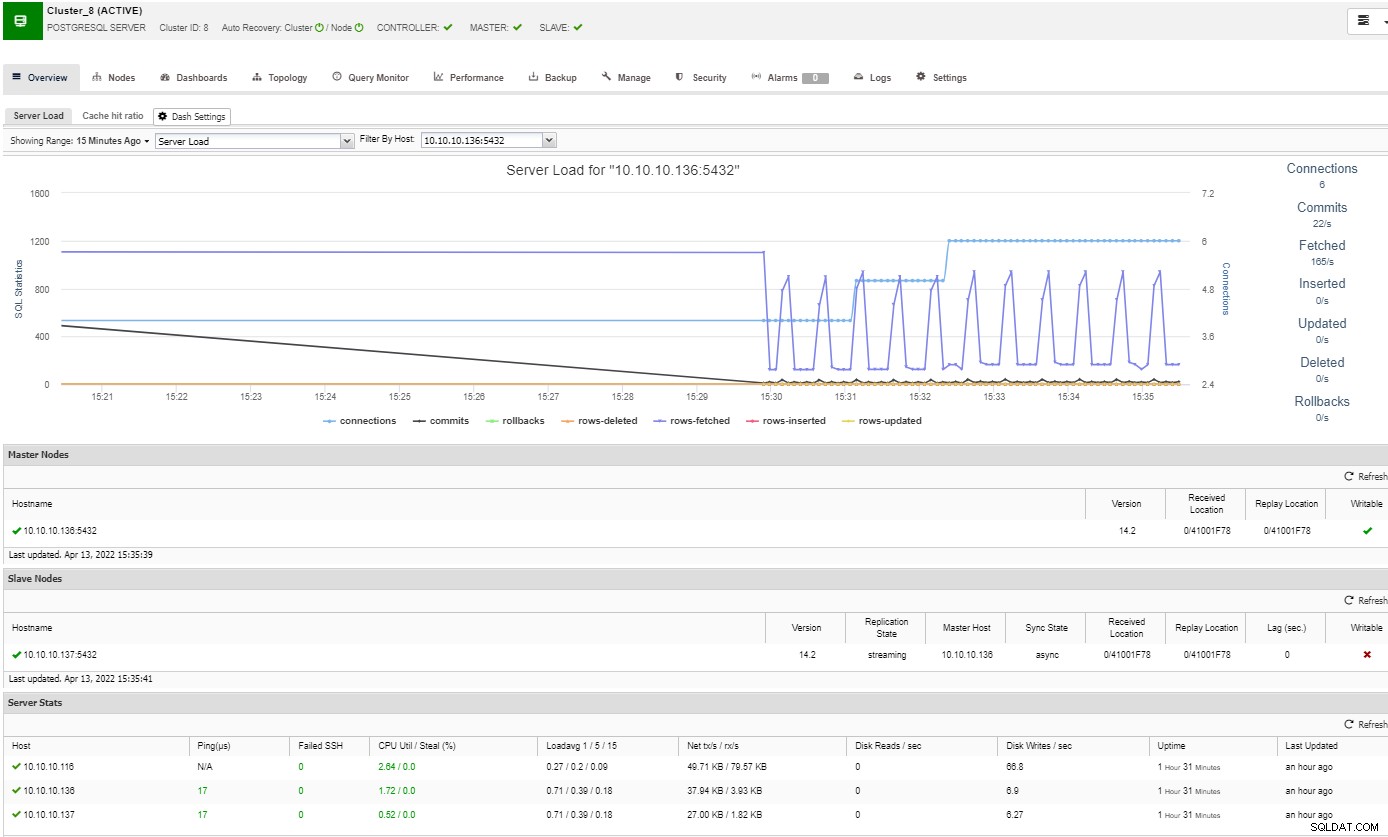
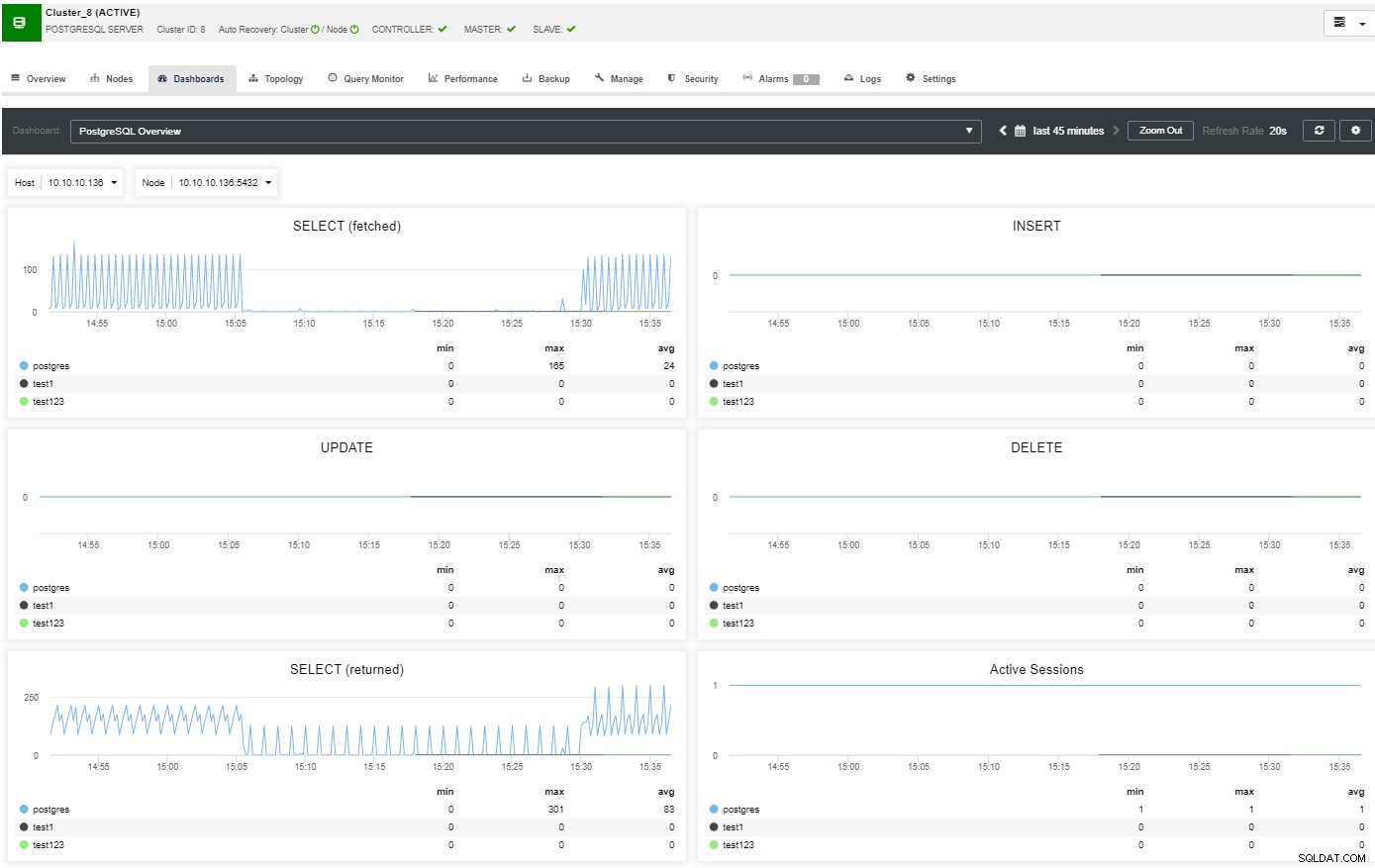
Im Übersichtsabschnitt erhalten Sie ein vollständiges Bild Ihrer Datenbank-Cluster aktueller Status. Um weitere Details anzuzeigen, können Sie auf den Dashboard-Bereich zugreifen, in dem Sie viele hilfreiche Informationen sehen, die in verschiedene Grafiken unterteilt sind.
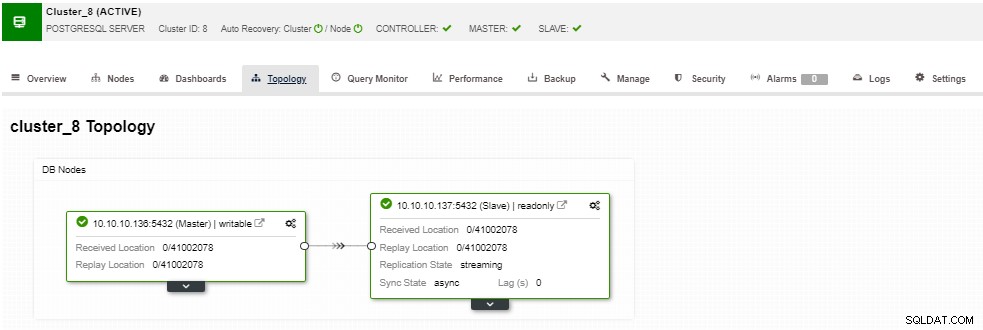
Im Topologieabschnitt können Sie Ihre aktuelle Topologie in einem Benutzer- freundliche Weise, und Sie können auch verschiedene Aufgaben über die Knoten ausführen, indem Sie die Schaltfläche "Knotenaktion" verwenden.
Die Streaming-Replikation basiert auf dem Versand der WAL-Einträge und deren Anwendung auf die Standby-Instanz Server bestimmt, welche Bytes in welcher Datei hinzugefügt oder geändert werden sollen. Folglich ist der Standby-Server tatsächlich eine Bit-für-Bit-Kopie des primären Servers. Hier gibt es jedoch einige bekannte Einschränkungen:
-
Sie können nicht in eine andere Version oder Architektur replizieren.
-
Auf dem Standby-Server können Sie nichts ändern.
-
Sie haben nicht viel Genauigkeit bei dem, was Sie replizieren.
Um diese Einschränkungen zu überwinden, hat PostgreSQL 10 Unterstützung für die logische Replikation hinzugefügt
Logische Replikation
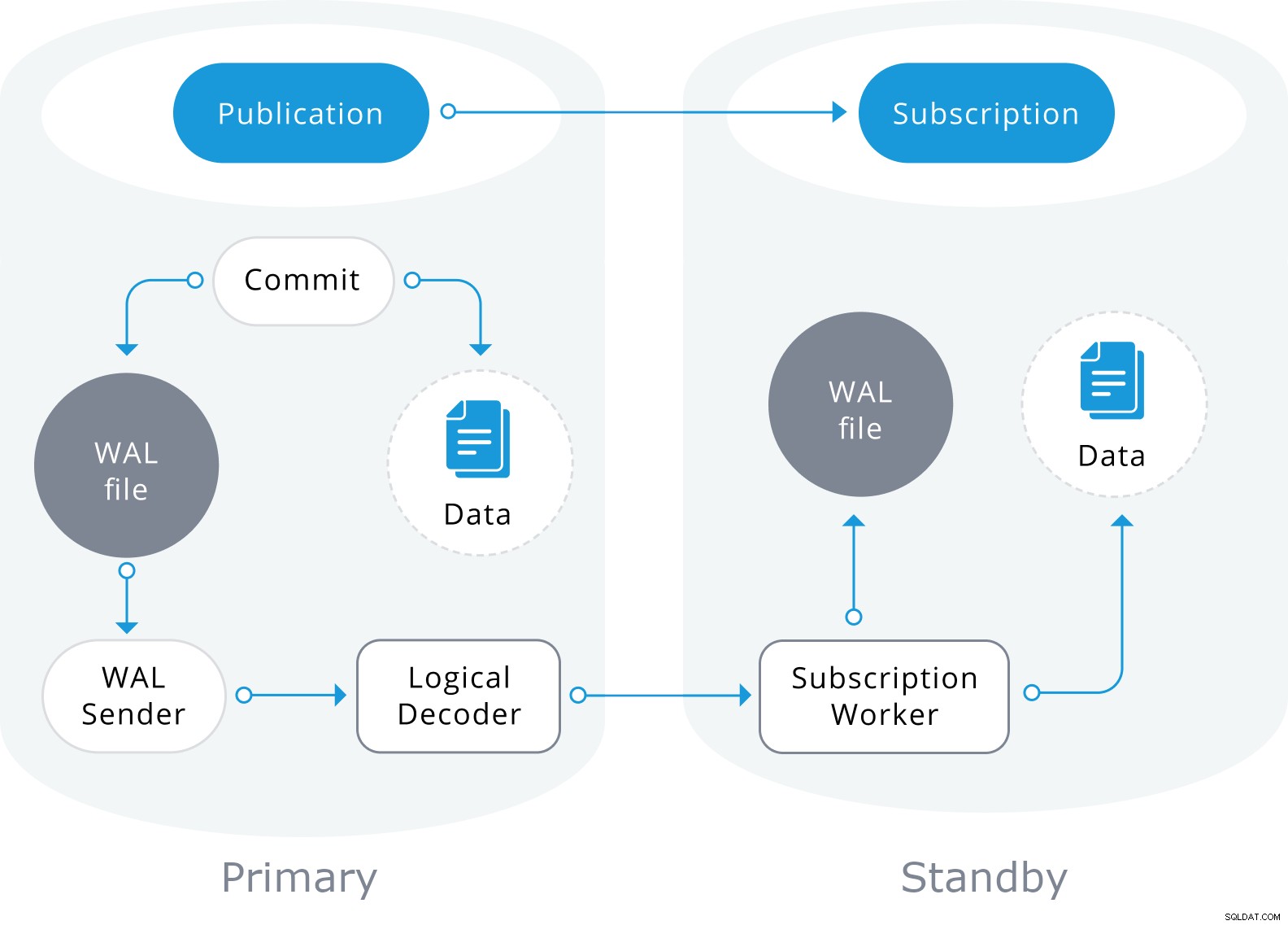
Die logische Replikation verwendet ebenfalls die Informationen in der WAL-Datei, dekodiert sie jedoch in logische Änderungen. Anstatt zu wissen, welches Byte sich geändert hat, weiß es genau, welche Daten in welche Tabelle eingefügt wurden.
Es basiert auf einem „Veröffentlichen“- und „Abonnieren“-Modell, bei dem ein oder mehrere Abonnenten eine oder mehrere Veröffentlichungen auf einem Herausgeberknoten abonnieren, der wie folgt aussieht:
Abschluss
Mit der Streaming-Replikation können Sie WAL-Einträge kontinuierlich an Ihre Standby-Server senden und anwenden und sicherstellen, dass auf dem primären Server aktualisierte Informationen in Echtzeit an den Standby-Server übertragen werden, sodass beide synchron bleiben .
ClusterControl vereinfacht die Einrichtung der Streaming-Replikation und Sie können es 30 Tage lang kostenlos testen.
Wenn Sie mehr über die logische Replikation in PostgreSQL erfahren möchten, lesen Sie unbedingt diese Übersicht über die logische Replikation und diesen Beitrag zu Best Practices für die PostgreSQL-Replikation.
Folgen Sie uns für weitere Tipps und Best Practices zur Verwaltung Ihrer Open-Source-basierten Datenbank auf Twitter und LinkedIn und abonnieren Sie unseren Newsletter für regelmäßige Updates.