Ich habe mehrere Benchmarks veröffentlicht, die verschiedene PostgreSQL-Versionen vergleichen, wie zum Beispiel den Performance Archaeology Talk (Evaluierung von PostgreSQL 7.4 bis 9.4), und alle diese Benchmarks gehen von einer festen Umgebung (Hardware, Kernel, …) aus. Was in vielen Fällen in Ordnung ist (z. B. wenn die Auswirkungen eines Patches auf die Leistung bewertet werden), aber in der Produktion ändern sich diese Dinge im Laufe der Zeit – Sie erhalten Hardware-Upgrades und von Zeit zu Zeit erhalten Sie ein Update mit einer neuen Kernel-Version.
Bei Hardware-Upgrades (besserer Speicher, mehr RAM, schnellere CPUs usw.) sind die Auswirkungen normalerweise ziemlich einfach vorherzusagen, und außerdem ist den Menschen im Allgemeinen klar, dass sie die Auswirkungen abschätzen müssen, indem sie die Engpässe auf die Produktion analysieren und vielleicht sogar zuerst die neue Hardware testen .
Aber wozu Kernel-Updates? Leider führen wir in diesem Bereich normalerweise nicht viel Benchmarking durch. Die Annahme ist meistens, dass neue Kernel besser sind als ältere (schneller, effizienter, auf mehr CPU-Kerne skalieren). Aber ist es wirklich wahr? Und wie groß ist der Unterschied? Was ist zum Beispiel, wenn Sie einen Kernel von 3.0 auf 4.7 aktualisieren – wirkt sich das auf die Leistung aus, und wenn ja, wird sich die Leistung verbessern oder nicht?
Von Zeit zu Zeit erhalten wir Berichte über schwerwiegende Rückschritte bei einer bestimmten Kernelversion oder plötzliche Verbesserungen zwischen Kernelversionen. Kernel-Versionen können also eindeutig die Leistung beeinträchtigen.
Mir ist ein einzelner PostgreSQL-Benchmark bekannt, der verschiedene Kernel-Versionen vergleicht, der 2014 von Sergey Konoplev als Reaktion auf Empfehlungen zur Vermeidung von 3.0-3.8-Kerneln erstellt wurde. Aber dieser Benchmark ist ziemlich alt (die letzte verfügbare Kernel-Version vor ~18 Monaten war 3.13, während wir heute 3.19 und 4.6 haben), also habe ich mich entschieden, einige Benchmarks mit aktuellen Kerneln (und PostgreSQL 9.6beta1) auszuführen.
PostgreSQL vs. Kernel-Versionen
Aber lassen Sie mich zunächst einige signifikante Unterschiede zwischen den Richtlinien diskutieren, die Commits in den beiden Projekten regeln. In PostgreSQL haben wir das Konzept von Haupt- und Nebenversionen – Hauptversionen (z. B. 9.5) werden ungefähr einmal im Jahr veröffentlicht und enthalten verschiedene neue Funktionen. Nebenversionen (z. B. 9.5.2) enthalten nur Fehlerbehebungen und werden etwa alle drei Monate veröffentlicht (oder häufiger, wenn ein schwerwiegender Fehler entdeckt wird). Daher sollte es keine größeren Leistungs- oder Verhaltensänderungen zwischen Nebenversionen geben, wodurch es ziemlich sicher ist, Nebenversionen ohne umfangreiche Tests bereitzustellen.
Bei Kernel-Versionen ist die Situation viel weniger klar. Der Linux-Kernel hat auch Zweige (z. B. 2.6, 3.0 oder 4.7), die sind keineswegs gleichbedeutend mit „Hauptversionen“ von PostgreSQL, da sie weiterhin neue Funktionen und nicht nur Bugfixes erhalten. Ich behaupte nicht, dass die PostgreSQL-Versionierungsrichtlinie irgendwie automatisch überlegen ist, aber die Konsequenz ist, dass die Aktualisierung zwischen kleineren Kernelversionen die Leistung leicht erheblich beeinträchtigen oder sogar Fehler einführen kann (z. B. leidet 3.18.37 unter OOM-Problemen aufgrund eines solchen Nicht-Bugfixes verpflichten).
Natürlich erkennen Distributionen diese Risiken und sperren häufig die Kernel-Version und führen weitere Tests durch, um neue Fehler auszusortieren. Dieser Beitrag verwendet jedoch Vanilla-Longterm-Kernel, wie sie auf www.kernel.org verfügbar sind.
Benchmark
Es gibt viele Benchmarks, die wir verwenden könnten – dieser Beitrag stellt eine Reihe von pgbench-Tests vor, d. h. einen ziemlich einfachen OLTP-Benchmark (TPC-B-ähnlich). Ich plane zusätzliche Tests mit anderen Benchmark-Typen (insbesondere DWH/DSS-orientiert) und werde sie in Zukunft in diesem Blog präsentieren.
Nun zurück zur pgbench – wenn ich „Sammlung von Tests“ sage, meine ich Kombinationen von
- Nur-Lesen vs. Lesen-Schreiben
- Datensatzgröße – aktiver Satz passt (nicht) in gemeinsam genutzte Puffer / RAM
- Client-Anzahl – einzelner Client vs. viele Clients (Sperren/Scheduling)
Die Werte hängen natürlich von der verwendeten Hardware ab, sehen wir uns also an, auf welcher Hardware diese Benchmark-Runde lief:
- CPU:Intel i5-2500k @ 3,3 GHz (3,7 GHz Turbo)
- RAM:8 GB (DDR3 bei 1333 MHz)
- Speicher:6x Intel SSD DC S3700 in RAID-10 (Linux sw raid)
- Dateisystem:ext4 mit Standard-I/O-Scheduler (cfq)
Es ist also dieselbe Maschine, die ich für eine Reihe früherer Benchmarks verwendet habe – eine ziemlich kleine Maschine, nicht gerade die neueste CPU usw., aber ich glaube, es ist immer noch ein vernünftiges „kleines“ System.
Die Benchmark-Parameter sind:
- Datenmengenskalen:30, 300 und 1500 (also etwa 450 MB, 4,5 GB und 22,5 GB)
- Client-Anzahl:1, 4, 16 (die Maschine hat 4 Kerne)
Für jede Kombination gab es 3 Nur-Lese-Läufe (jeweils 15 Minuten) und 3 Lese-Schreib-Läufe (jeweils 30 Minuten). Das eigentliche Skript, das den Benchmark antreibt, ist hier verfügbar (zusammen mit Ergebnissen und anderen nützlichen Daten).
Hinweis :Wenn Sie erheblich unterschiedliche Hardware haben (z. B. Rotationslaufwerke), sehen Sie möglicherweise sehr unterschiedliche Ergebnisse. Wenn Sie ein System haben, das Sie testen möchten, lassen Sie es mich wissen und ich helfe Ihnen dabei (vorausgesetzt, ich darf die Ergebnisse veröffentlichen).
Kernel-Versionen
Bezüglich der Kernel-Versionen habe ich die neusten Versionen in allen Longterm-Zweigen seit 2.6.x getestet (2.6.39, 3.0.101, 3.2.81, 3.4.112, 3.10.102, 3.12.61, 3.14.73, 3.16. 36, 3.18.38, 4.1.29, 4.4.16, 4.6.5 und 4.7). Es gibt immer noch viele Systeme, die auf 2.6.x-Kernel laufen, daher ist es nützlich zu wissen, wie viel Leistung Sie durch ein Upgrade auf einen neueren Kernel gewinnen (oder verlieren) können. Aber ich habe alle Kernel selbst kompiliert (d. h. unter Verwendung von Vanilla-Kerneln, keine verteilungsspezifischen Patches), und die Konfigurationsdateien befinden sich im Git-Repository.
Ergebnisse
Wie üblich sind alle Daten auf Bitbucket verfügbar, einschließlich
- Kernel-.config-Datei
- Benchmark-Skript (run-pgbench.sh)
- PostgreSQL-Konfiguration (mit einigen grundlegenden Einstellungen für die Hardware)
- PostgreSQL-Protokolle
- verschiedene Systemprotokolle (dmesg, sysctl, mount, …)
Die folgenden Diagramme zeigen die durchschnittlichen tps für jeden Benchmark-Fall – die Ergebnisse für die drei Läufe sind ziemlich konsistent, in den meisten Fällen mit ~2 % Unterschied zwischen Minimum und Maximum.
schreibgeschützt
Für den kleinsten Datensatz gibt es einen deutlichen Leistungsabfall zwischen 3,4 und 3,10 für alle Clientzahlen. Die Ergebnisse für 16 Clients (4x die Anzahl der Kerne) werden jedoch in 3.12 mehr als wiederhergestellt.
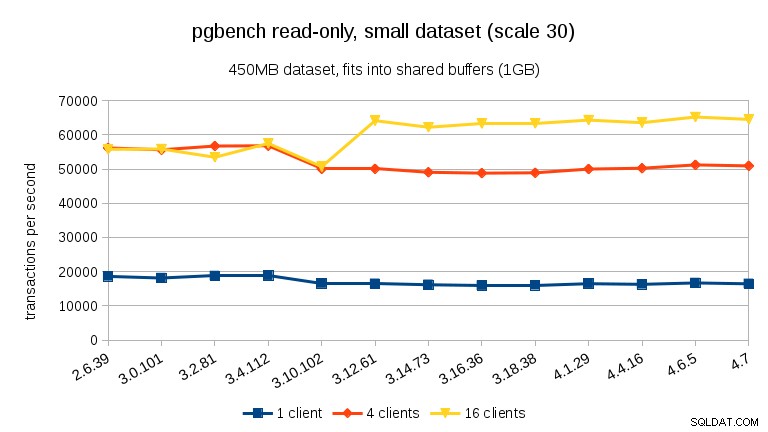
Für den mittleren Datensatz (passt in RAM, aber nicht in gemeinsam genutzte Puffer) können wir den gleichen Abfall zwischen 3.4 und 3.10 sehen, aber nicht die Wiederherstellung in 3.12.
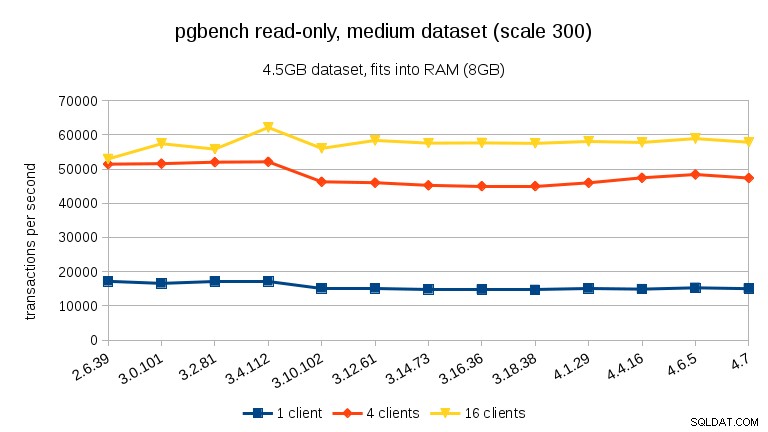
Bei großen Datensätzen (über RAM hinaus, so stark I/O-gebunden) sind die Ergebnisse sehr unterschiedlich – ich bin mir nicht sicher, was zwischen 3.10 und 3.12 passiert ist, aber die Leistungsverbesserung (insbesondere bei höheren Client-Anzahlen) ist ziemlich erstaunlich.
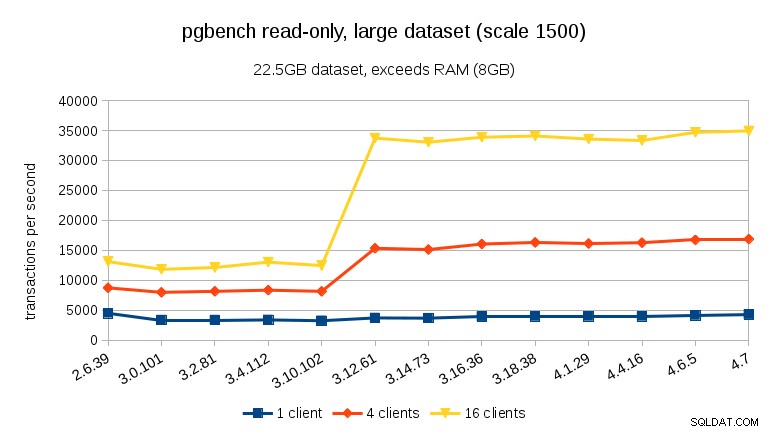
Lesen-Schreiben
Für die Lese-Schreib-Workload sind die Ergebnisse ziemlich ähnlich. Bei den kleinen und mittleren Datensätzen können wir zwischen 3.4 und 3.10 den gleichen Rückgang von ~10 % beobachten, aber leider keine Erholung in 3.12.
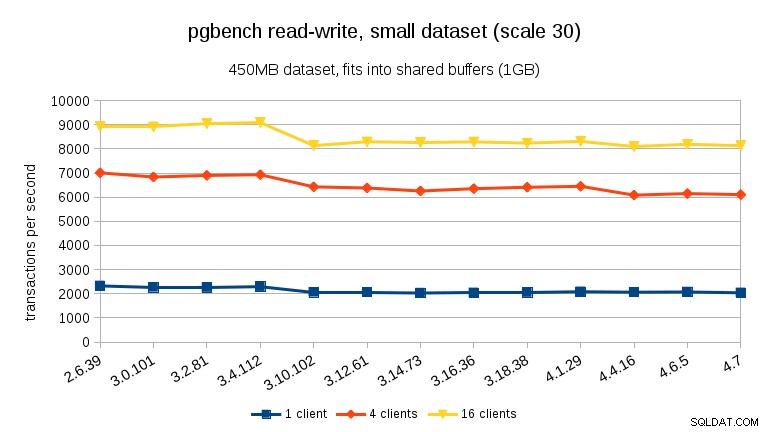
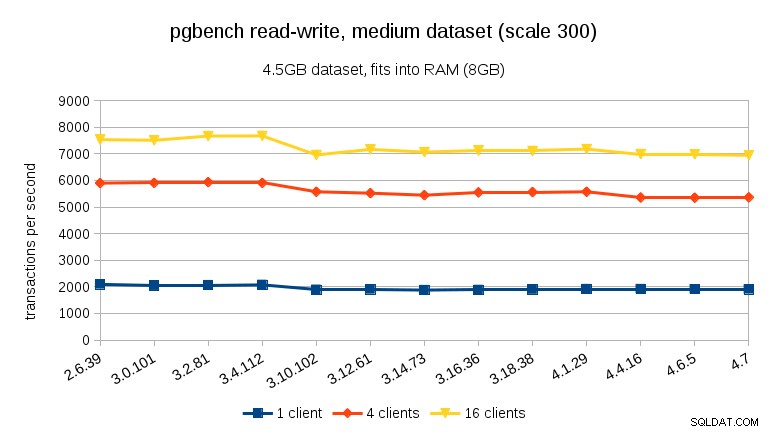
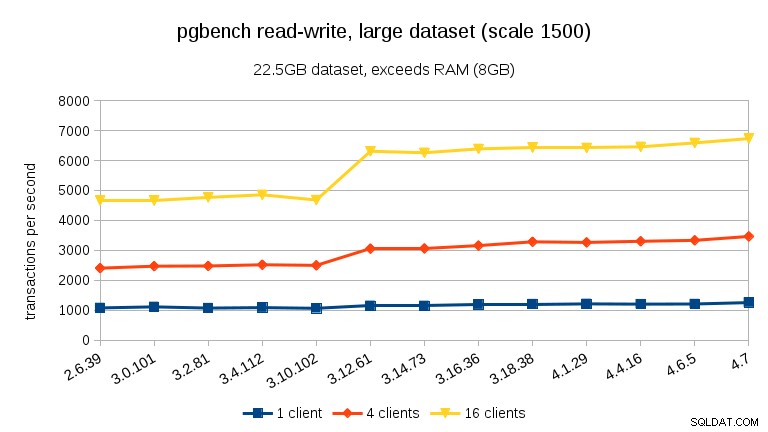
Für den großen Datensatz (wieder deutlich I/O-gebunden) können wir eine ähnliche Verbesserung in 3.12 sehen (nicht so signifikant wie für die schreibgeschützte Arbeitslast, aber immer noch signifikant):
Zusammenfassung
Ich wage nicht, Schlussfolgerungen aus einem einzelnen Benchmark auf einer einzelnen Maschine zu ziehen, aber ich denke, es ist sicher zu sagen:
- Die Gesamtleistung ist ziemlich stabil, aber wir können einige signifikante Leistungsänderungen feststellen (in beide Richtungen).
- Bei Datensätzen, die in den Speicher passen (entweder in shared_buffers oder zumindest in RAM), sehen wir einen messbaren Leistungsabfall zwischen 3,4 und 3,10. Beim Nur-Lesen-Test wird dies in 3.12 teilweise wiederhergestellt (aber nur für viele Clients).
- Bei Datensätzen, die den Arbeitsspeicher überschreiten und daher hauptsächlich I/O-gebunden sind, sehen wir keine solchen Leistungseinbußen, sondern eine deutliche Verbesserung in 3.12.
Was die Gründe für diese plötzlichen Veränderungen betrifft, bin ich mir nicht ganz sicher. Es gibt viele möglicherweise relevante Commits zwischen den Versionen, aber ich bin mir nicht sicher, wie ich den richtigen ohne umfangreiche (und zeitaufwändige) Tests identifizieren soll. Wenn Sie andere Ideen haben (z. B. solche Commits kennen), lassen Sie es mich wissen.



