Ich betrachte mich selbst als einen kleinen Entdecker. In gewissen Dingen schon. Normalerweise bestelle ich immer das gleiche Essen in einem vertrauten Restaurant, weil die Angst vor Enttäuschungen meine Befürchtung überwiegt, etwas Neues auszuprobieren.
Und natürlich neigt ein hungriger Mensch dazu, einfach richtig zu essen?
Wenn es jedoch um Technologie geht, insbesondere um SQL (PostgreSQL), tendiere ich dazu, mit voller Geschwindigkeit (meine Definition von Erkunden) in oft unbekannte Bereiche zu stolpern, in der Hoffnung, etwas zu lernen. Wie kann man besser lernen als durch Erfahrung?
Was um alles in der Welt hat dieses Geschwätz mit der logischen und Streaming-Replikation in PostgreSQL zu tun?
Ich bin ein absoluter Neuling in diesen Bereichen mit null Kenntnissen. Ja, ich habe in diesem Bereich von Postgres ungefähr so viel Verständnis wie in der Astrophysik.
Habe ich erwähnt, dass ich kein Wissen hatte?
Daher werde ich in diesem Blogbeitrag versuchen, die Unterschiede bei diesen Replikationstypen zu verdauen. Ohne praktische Erfahrungen aus der realen Welt kann ich Ihnen nicht das 'Alles Ende versprechen ' Manuskript zur Vervielfältigung.
Wahrscheinlich würden andere, die sich in diesem speziellen Bereich weniger auskennen (wie ich selbst), von diesem Blogpost profitieren.
Erfahrene Benutzer und Entwickler, die mitfahren, ich hoffe, Sie in den Kommentaren unten zu sehen.
Ein paar grundlegende Definitionen
Was bedeutet Replikation im weitesten Sinne?
Replikation im Sinne von Wiktionary hat folgendes zu sagen:
"Vorgang, durch den ein Objekt, eine Person, ein Ort oder eine Idee kopiert, nachgeahmt oder reproduziert werden kann."
Der fünfte aufgeführte Punkt dort trifft jedoch eher auf diesen Blogpost zu, und ich denke, wir sollten ihn uns auch ansehen:
"(Computing) Der Vorgang des häufigen Kopierens elektronischer Daten von einer Datenbank auf einem Computer oder Server in eine Datenbank auf einem anderen, sodass alle Benutzer denselben Informationsstand haben. Wird verwendet, um die Fehlertoleranz des Systems zu verbessern."
Jetzt gibt es etwas, worauf wir uns einlassen können. Die Erwähnung des Kopierens von Daten von einem Server oder einer Datenbank auf einen anderen? Wir befinden uns jetzt auf vertrautem Terrain...
Wenn wir also hinzufügen, was wir aus dieser Definition wissen, was sind die Definitionen von Streaming-Replikation und logischer Replikation?
Mal sehen, was das PostgreSQL-Wiki zu bieten hat:
Streaming-Replikation:„bietet die Möglichkeit, die WAL XLOG-Einträge kontinuierlich zu versenden und auf eine Reihe von Standby-Servern anzuwenden, um sie auf dem neuesten Stand zu halten.
Und die PostgreSQL-Dokumentation hat diese Definition für die logische Replikation:
„Die logische Replikation ist eine Methode zum Replizieren von Datenobjekten und deren Änderungen, basierend auf ihrer Replikationsidentität (normalerweise ein Primärschlüssel). Wir verwenden den Begriff „logisch“ im Gegensatz zur physischen Replikation, die exakte Blockadressen und Byte-für-Byte-Replikation verwendet. "
Kapitel 19.6 Replikation aus der offiziellen Dokumentation ist auch vollgepackt mit Leckereien, also seien Sie sicher und besuchen Sie diese Quelle.
Im Folgenden werde ich versuchen, die Unterschiede in Laiensprache wiederzugeben. (Denken Sie daran, wenn ich stolpere, bin ich ein Neuling.) Dies ist ein extremer Überblick auf „hohem Niveau“.
Logische Replikation
Eine "Quellen"-Datenbank erstellt eine VERÖFFENTLICHUNG unter Verwendung des Befehls CREATE PUBLICATION. (Ich stelle mir das einfach als 'Absender' vor.)
Die Dokumentation bezeichnet ihn als Herausgeber.
Diese Publisher-Datenbank enthält die Daten, die wir replizieren möchten. Wir müssen jedoch etwas haben, auf das wir replizieren können, und hier kommen die Gegenstücke des Herausgebers ins Spiel. Der „Abonnent“. Beachten Sie, dass ich eine alternative Pluralform eingefügt habe, da es nach dem, was ich durch Online-Suchen gefunden habe, eine praktische Einrichtung ist, mehrere Abonnenten zu haben.
Ein „Abonnent“ (könnte auch als Replikatdatenbank betrachtet werden) erstellt ein Abonnement für eine „Quell“-Datenbank (Herausgeber), die Verbindungsinformationen und alle von ihm abonnierten Publikationen definiert.
Es ist möglich, dass ein Abonnent auch ein Herausgeber ist und seine eigene PUBLIKATION erstellt, die andere Abonnenten abonnieren können.
Was passiert jetzt?
Alle Datenänderungen, die auf dem Herausgeber stattfinden, werden an den Abonnenten gesendet. Was von Haus aus alles ist, aber konfiguriert oder auf bestimmte Operationen beschränkt werden kann (z. B. INSERT, UPDATE oder DELETE).
Beispiel auf hohem Niveau:
Angenommen, wir aktualisieren eine Zeile oder mehrere Zeilen in einer bestimmten Tabelle im Herausgeber, diese Aktualisierungen und Änderungen werden auf der Instanz des Abonnenten oder auf mehreren Abonnenten repliziert, wenn diese Art von Konfiguration implementiert ist.
Hier sind ein paar Dinge, an die ich mich erinnern sollte:
- Die wal_level-Konfiguration der Publisher-Datenbank muss auf logisch eingestellt sein.
- Die logische Replikation hat keine DDL-Befehle (Data Definition Language).
- Von der Seite „Konflikte“ in der Dokumentation:„Die logische Replikation verhält sich insofern ähnlich wie normale DML-Operationen, als dass die Daten aktualisiert werden, selbst wenn sie lokal auf dem Abonnentenknoten geändert wurden. Wenn eingehende Daten irgendwelche Beschränkungen verletzen, wird die Replikation beendet. Dies wird als Konflikt bezeichnet. Beim Replizieren von UPDATE- oder DELETE-Operationen führen fehlende Daten nicht zu einem Konflikt, und solche Operationen werden einfach übersprungen."
- Publisher-Tabellen müssen eine Möglichkeit haben, sich selbst zu identifizieren (als "Replikatidentität" bezeichnet), um DML-Operationen (UPDATE und DELETE) in allen Replikaten für diese betroffenen Zeilen ordnungsgemäß zu replizieren. Wenn die Tabelle einen Primärschlüssel hat, ist dies die Standardeinstellung (scheint mir die richtige Wahl zu sein), aber in Abwesenheit eines Primärschlüssels sind andere Konfigurationsoptionen verfügbar. Die gesamte Zeile könnte verwendet werden, wenn kein anderer Kandidatenschlüssel vorhanden ist (als "vollständig" bezeichnet), obwohl die Dokumentation erwähnt, dass dies normalerweise keine effiziente Lösung ist. (Siehe den Abschnitt REPLICA IDENTITY in der Dokumentation für eine Beschreibung auf niedrigerer Ebene, wie es festgelegt wird)
Einschränkungen
Die Dokumentation in Abschnitt 31.4. Einschränkungen enthält einige wichtige Erinnerungen an Einschränkungen, die ich beschönigen werde. Seien Sie sicher und überprüfen Sie die oben verlinkte Seite auf den genauen Wortlaut.
- Datenbankschema und DDL-Befehle werden bei der Replikation nicht unterstützt. Es wird vorgeschlagen, dass vielleicht pg_dump anfangs verwendet werden könnte, aber Sie müssten dennoch alle weiteren Änderungen und Fortschritte im Schema für alle Replikate selbst aktualisieren.
- Die Daten in Sequenzspalten werden repliziert. Die Sequenz selbst würde jedoch nur den Startwert widerspiegeln. Zum Lesen ist das okay. Wenn dies jedoch Ihre Anlaufstelle für ein Failover ist, müssen Sie selbst auf den aktuellen Wert AKTUALISIEREN. Die Dokumentation schlägt hier pg_dump vor.
- Truncate wird noch nicht unterstützt.
- Die Replikation großer Objekte wird nicht unterstützt.
- Ansichten, materialisierte Ansichten, Partitionsstammtabellen oder Fremdtabellen werden weder auf dem Herausgeber noch auf dem Abonnenten unterstützt.
Gemeldete häufige Anwendungsfälle
- Sie sind nur an bestimmten Daten und Datenänderungen interessiert, die Sie tatsächlich replizieren, anstatt nur die gesamte Datenbank zu replizieren.
- Wenn Sie Replikate für schreibgeschützte Vorgänge benötigen, z. B. in einem Analyseszenario.
- Benutzern oder verschiedenen Untergruppen von Benutzern eingeschränkten oder überwachten Zugriff auf Daten gewähren.
- Daten verteilen.
- Kompatibilität mit anderen PostgreSQL-Versionen.
Streaming-Replikation
Aus der Recherche, dem Lesen und dem Studium der Streaming-Replikation ist eine Sache, die ich gleich zu Beginn entnehme, die Wahl, entweder die asynchrone (Standardeinstellung) oder die synchrone Replikation einzurichten.
Ah, noch mehr unbekannte Begriffe, oder?
Hier ist meine "hochrangige" Definition von beiden:
Bei der asynchronen Replikation kommt es nach dem Festschreiben einer Transaktion auf dem Primärknoten zu einer leichten Verzögerung, wenn dieselbe Transaktion festgeschrieben und auf das Replikat geschrieben wird. Bei dieser Art von Konfiguration besteht die Möglichkeit eines Datenverlusts.
- Angenommen, der Master stürzt ab.
- Zweitens, die Replik(en) sind so weit hinter dem Master zurück, dass benötigte Daten und Informationen für die Replik(en) verworfen wurden, um überhaupt „aktuell“ zu sein.
Bei der synchronen Replikation gilt jedoch keine Transaktion als abgeschlossen, bis sie sowohl vom Master- als auch vom Replikatserver bestätigt wird. Welches wird ein Commit in die WAL beider Server geschrieben haben.
Soweit ich weiß, bedeutet dies, dass Schreibvorgänge auf dem Master auch bestätigt und auf die Replik geschrieben wurden.
Hier ist die offizielle Erklärung aus Abschnitt 26.2.8. Synchrone Replikation in der offiziellen Dokumentation:
„Beim Anfordern einer synchronen Replikation wartet jeder Commit einer Schreibtransaktion, bis eine Bestätigung empfangen wird, dass der Commit auf die Write-Ahead-Log-On-Festplatte sowohl des Primär- als auch des Standby-Servers geschrieben wurde. „
Eine andere Passage aus der Dokumentation hat einen netten Überblick darüber, was (meiner Meinung nach) ein großer Vorteil sein muss:"Die einzige Möglichkeit, dass Daten verloren gehen können, ist, wenn sowohl der Primär- als auch der Standby-Server gleichzeitig abstürzen."
Obwohl nichts unmöglich ist, ist dies dennoch eine ziemlich gute Garantie dafür, dass Sie nicht ohne Kopie Ihrer Daten dastehen.
Okay, wir wissen, dass wir eine dieser Setup-Konfigurationen wählen müssen, aber was ist das Wesentliche?
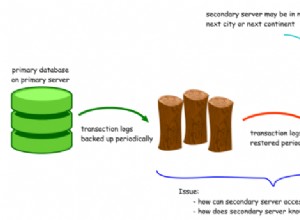
Kurz gesagt, die Streaming-Replikation sendet und wendet WAL-Dateien (Write Ahead Log) von einem Datenbankserver (dem Master- oder Primärserver) an ein „Replikat“ (Empfangsdatenbank) an.
Aber hier gibt es eine Einschränkung zu beachten. Möglicherweise können die WAL-Dateien vom Master wiederverwendet werden, bevor der Standy sie erhalten hat. Eine Möglichkeit, dies abzumildern, besteht darin, die Einstellung wal_keep_segments auf einen höheren Wert zu erhöhen.
Punkte zur Streaming-Replikation
Zugehörige Ressourcen ClusterControl for PostgreSQL PostgreSQL Streaming Replication - a Deep Dive An Expert’s Guide to Slony Replication for PostgreSQL- Standardmäßig ist die Streaming-Replikation asynchron, was bedeutet, dass es eine (möglicherweise kleine) Verzögerung zwischen den festgeschriebenen Transaktionen auf dem Master und ihrer Sichtbarkeit auf dem Replikat gibt.
- Replica(s) verbinden sich über eine Netzwerkverbindung mit dem Master.
- Achten Sie auf die Authentifizierung. Siehe hier aus der Dokumentation:"Es ist sehr wichtig, dass die Zugriffsrechte für die Replikation so eingerichtet werden, dass nur vertrauenswürdige Benutzer den WAL-Stream lesen können, weil es einfach ist, privilegierte Informationen daraus zu extrahieren"
Wann Streaming-Replikation verwendet werden sollte
- Eine häufige Verwendung (insbesondere in der Analytik) stellt eine „schreibgeschützte“ Kopie bereit, um den primären Server zu entlasten.
- Sie benötigen eine Hochverfügbarkeitsumgebung.
- Nützliche Einrichtung für Failover auf Hot-Standby-Server, falls der Primärserver ausfällt.