Die Verwaltung des Datenverkehrs zur Datenbank kann mit zunehmender Menge und der tatsächlichen Verteilung der Datenbank auf mehrere Server immer schwieriger werden. PostgreSQL-Clients kommunizieren normalerweise mit einem einzigen Endpunkt. Wenn ein primärer Knoten ausfällt, versuchen die Datenbankclients immer wieder dieselbe IP. Falls Sie ein Failover auf einen sekundären Knoten durchgeführt haben, muss die Anwendung mit dem neuen Endpunkt aktualisiert werden. An dieser Stelle möchten Sie einen Load Balancer zwischen den Anwendungen und den Datenbankinstanzen platzieren. Es kann Anwendungen an verfügbare/intakte Datenbankknoten leiten und bei Bedarf ein Failover durchführen. Ein weiterer Vorteil wäre die Steigerung der Leseleistung durch die effektive Verwendung von Repliken. Es ist möglich, einen schreibgeschützten Port zu erstellen, der Lesevorgänge über Replikate verteilt. In diesem Blog behandeln wir HAProxy. Wir werden sehen, was es ist, wie es funktioniert und wie es für PostgreSQL bereitgestellt wird.
Was ist HAProxy?
HAProxy ist ein Open-Source-Proxy, der zur Implementierung von Hochverfügbarkeit, Lastenausgleich und Proxying für TCP- und HTTP-basierte Anwendungen verwendet werden kann.
Als Load Balancer verteilt HAProxy den Datenverkehr von einem Ursprung zu einem oder mehreren Zielen und kann für diese Aufgabe spezifische Regeln und/oder Protokolle definieren. Wenn eines der Ziele nicht mehr reagiert, wird es als offline markiert und der Datenverkehr wird an die restlichen verfügbaren Ziele gesendet.
So installieren und konfigurieren Sie HAProxy manuell
Um HAProxy unter Linux zu installieren, können Sie die folgenden Befehle verwenden:
Unter Ubuntu/Debian OS:
$ apt-get install haproxy -yUnter CentOS/RedHat OS:
$ yum install haproxy -yUnd dann müssen wir die folgende Konfigurationsdatei bearbeiten, um unsere HAProxy-Konfiguration zu verwalten:
$ /etc/haproxy/haproxy.cfgDie Konfiguration unseres HAProxy ist nicht kompliziert, aber wir müssen wissen, was wir tun. Wir müssen mehrere Parameter konfigurieren, je nachdem, wie HAProxy funktionieren soll. Weitere Informationen finden Sie in der Dokumentation zur HAProxy-Konfiguration.
Sehen wir uns ein grundlegendes Konfigurationsbeispiel an. Angenommen, Sie haben die folgende Datenbanktopologie:
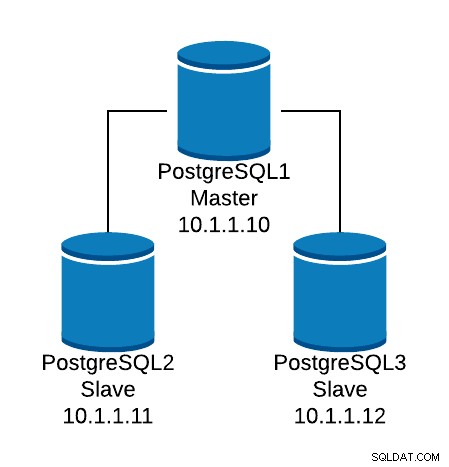 Beispiel einer Datenbanktopologie
Beispiel einer Datenbanktopologie Wir möchten einen HAProxy-Listener erstellen, um den Leseverkehr zwischen den drei Knoten auszugleichen.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkWie bereits erwähnt, müssen hier mehrere Parameter konfiguriert werden, und diese Konfiguration hängt davon ab, was wir tun möchten. Zum Beispiel:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkWie HAProxy auf ClusterControl funktioniert
Für PostgreSQL wird HAProxy von ClusterControl standardmäßig mit zwei verschiedenen Ports konfiguriert, einem mit Lese-/Schreibzugriff und einem mit Lesezugriff.
 ClusterControl-Load-Balancer-Bereitstellungsinformationen 1
ClusterControl-Load-Balancer-Bereitstellungsinformationen 1 In unserem Lese-Schreib-Port haben wir unseren Master-Server online und den Rest unserer Knoten offline, und in dem Nur-Lese-Port haben wir sowohl den Master als auch die Slaves online.
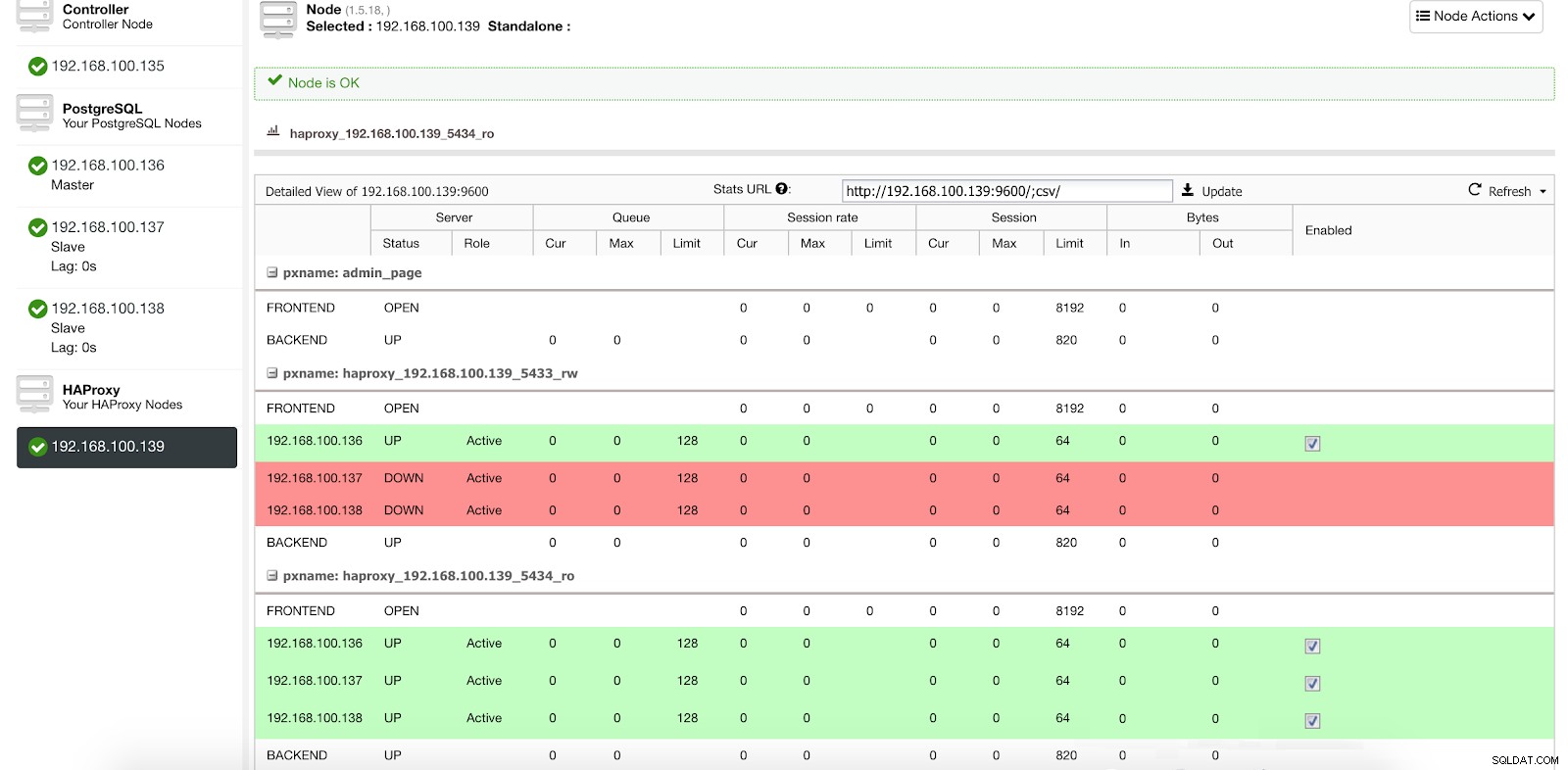 ClusterControl-Load-Balancer-Statistiken 1
ClusterControl-Load-Balancer-Statistiken 1 Wenn HAProxy erkennt, dass einer unserer Knoten, entweder Master oder Slave, nicht erreichbar ist, markiert es ihn automatisch als offline und berücksichtigt dies nicht beim Senden von Datenverkehr. Die Erkennung erfolgt durch Healthcheck-Skripte, die von ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert werden. Diese prüfen, ob die Instanzen aktiv sind, ob sie gerade wiederhergestellt werden oder schreibgeschützt sind.
Wenn ClusterControl einen Slave zum Master befördert, markiert unser HAProxy den alten Master als offline (für beide Ports) und stellt den beförderten Knoten online (im Lese-Schreib-Port).
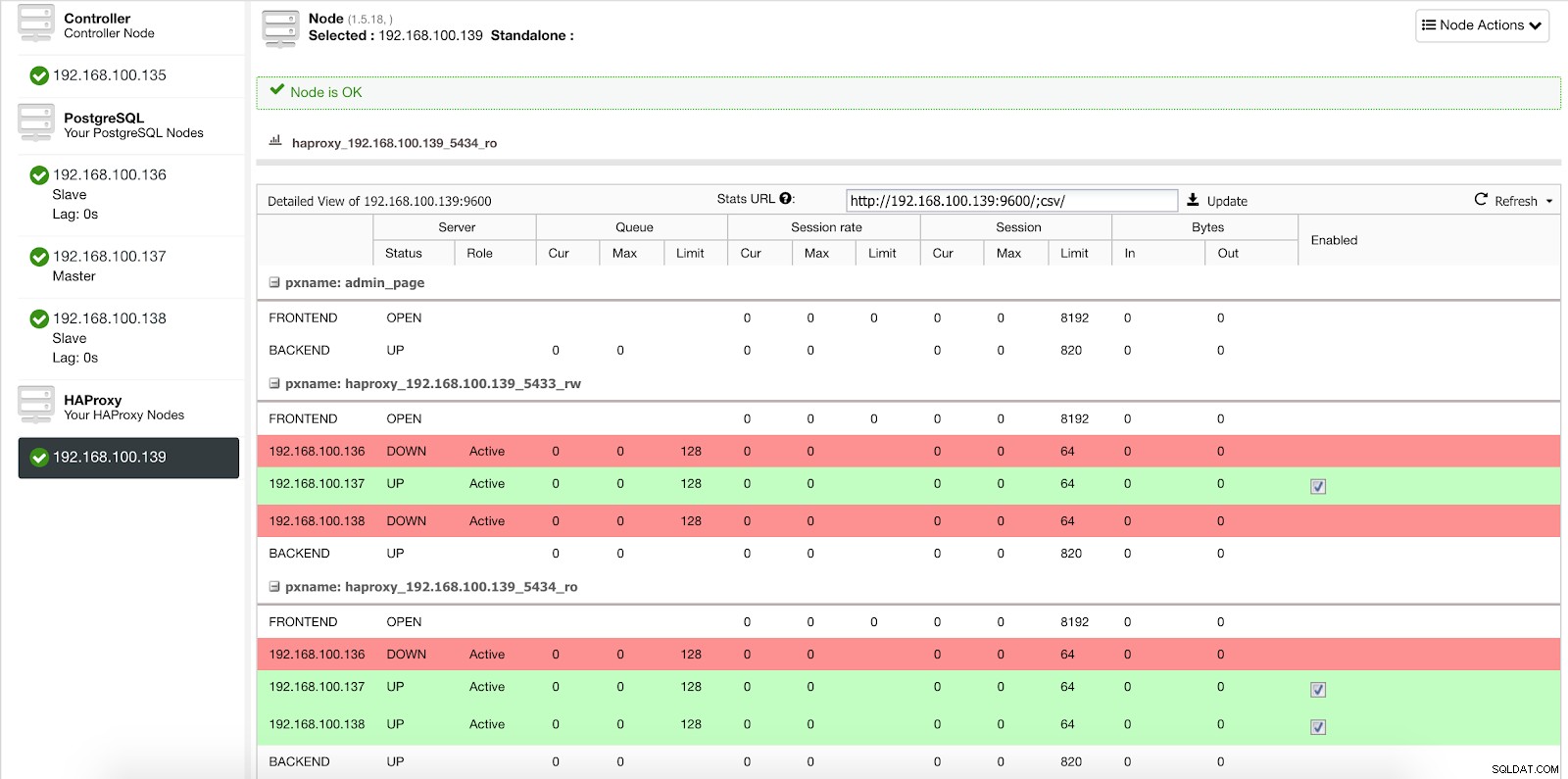 ClusterControl-Load-Balancer-Statistiken 2
ClusterControl-Load-Balancer-Statistiken 2 Auf diese Weise funktionieren unsere Systeme normal und ohne unser Eingreifen weiter.
So stellen Sie HAProxy mit ClusterControl bereit
In unserem Beispiel haben wir eine Umgebung mit 1 Master und 2 Slaves erstellt – siehe Screenshot der Topology View in ClusterControl. Wir fügen jetzt unseren HAProxy-Load-Balancer hinzu.
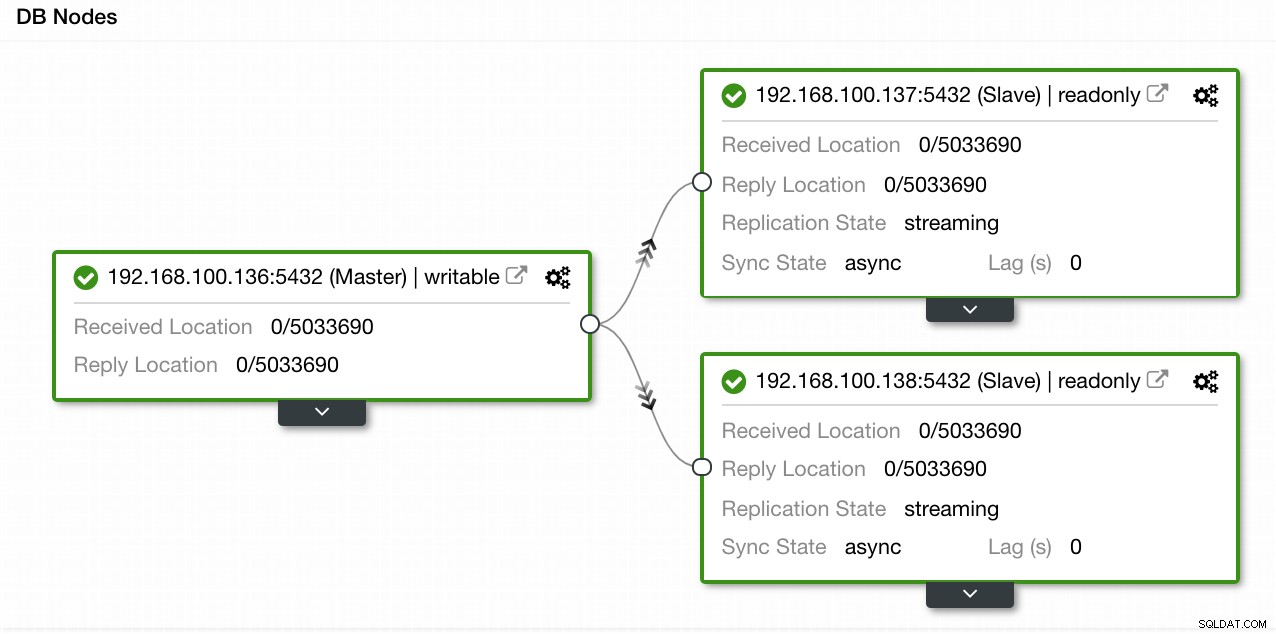 ClusterControl-Topologieansicht 1
ClusterControl-Topologieansicht 1 Für diese Aufgabe müssen wir zu ClusterControl -> PostgreSQL Cluster Actions -> Load Balancer hinzufügen
gehen ClusterControl-Cluster-Aktionsmenü
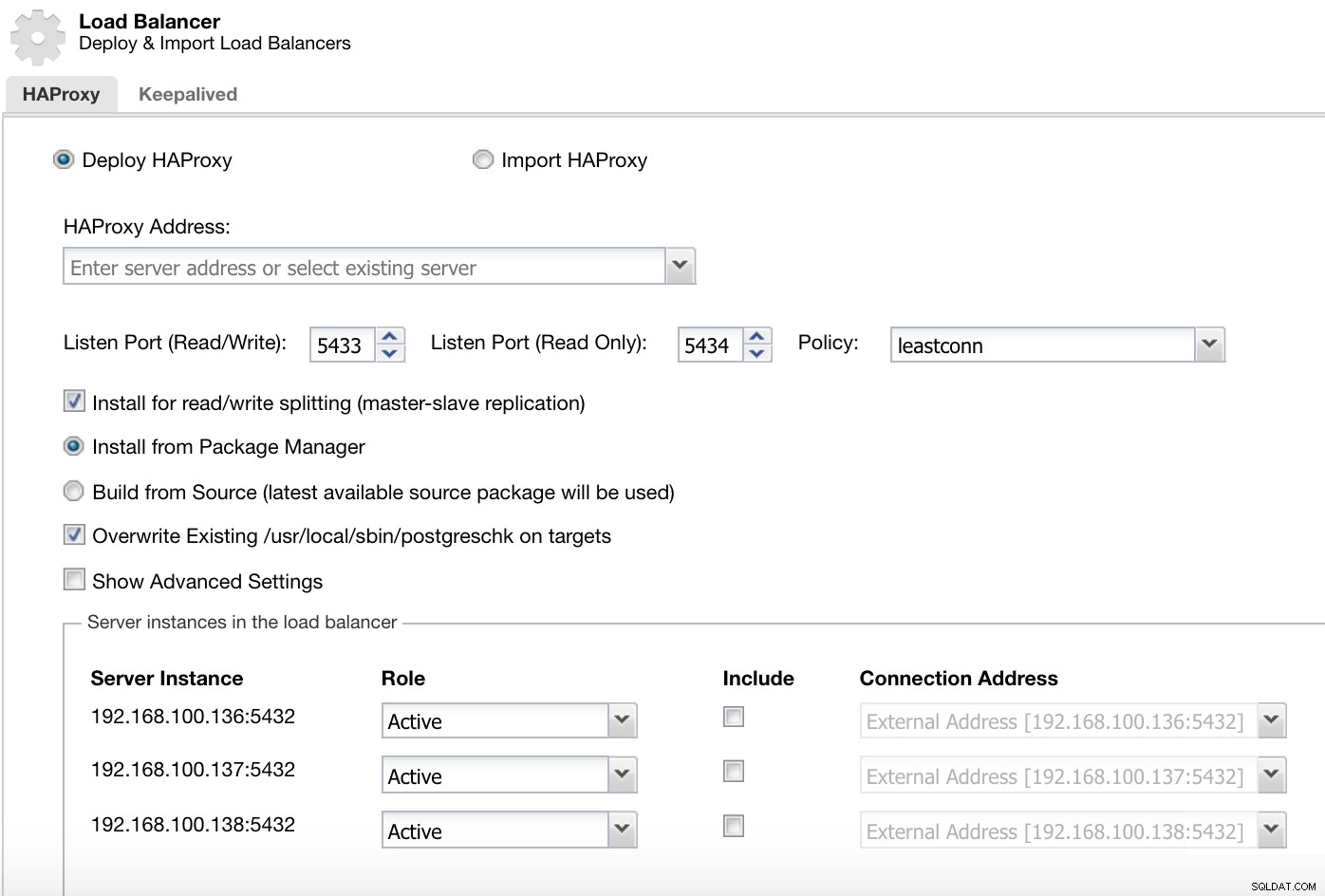
ClusterControl-Cluster-Aktionsmenü Hier müssen wir die Informationen hinzufügen, die ClusterControl zum Installieren und Konfigurieren unseres HAProxy-Load-Balancers verwenden wird.
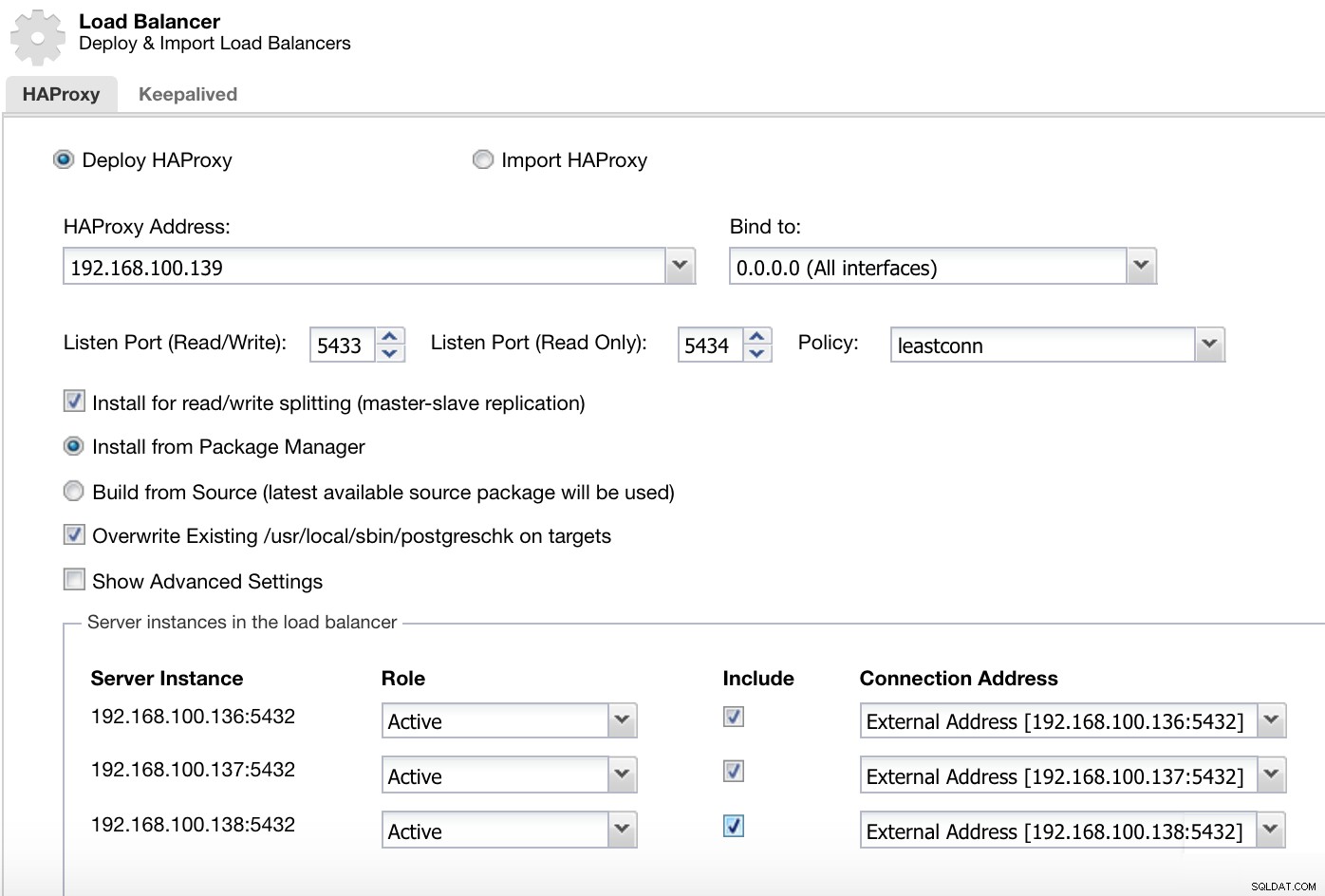 ClusterControl-Load-Balancer-Bereitstellungsinformationen 2
ClusterControl-Load-Balancer-Bereitstellungsinformationen 2 Die Informationen, die wir einführen müssen, sind:
Aktion:Bereitstellen oder Importieren.
HAProxy-Adresse:IP-Adresse für unseren HAProxy-Server.
Binden an:Schnittstelle oder IP-Adresse, an der HAProxy lauscht.
Listen Port (Read/Write):Port für Lese-/Schreibmodus.
Listen Port (Read Only):Port für Nur-Lesen-Modus.
Richtlinie:Dies kann sein:
- leastconn:Der Server mit der geringsten Anzahl an Verbindungen erhält die Verbindung.
- Roundrobin:Jeder Server wird abwechselnd entsprechend seiner Gewichtung verwendet.
- Quelle:Die Quell-IP-Adresse wird gehasht und durch die Gesamtgewichtung der laufenden Server geteilt, um anzugeben, welcher Server die Anfrage erhält.
Für Lese-/Schreibaufteilung installieren:Für Master-Slave-Replikation.
Source:Wir können Install from a package manager oder build from source wählen.
Vorhandenes postgreschk auf Zielen überschreiben.
Und wir müssen auswählen, welche Server Sie zur HAProxy-Konfiguration hinzufügen möchten, sowie einige zusätzliche Informationen wie:
Rolle:Kann Aktiv oder Backup sein.
Einschließlich:Ja oder Nein.
Informationen zur Verbindungsadresse.
Außerdem können wir erweiterte Einstellungen wie Admin-Benutzer, Backend-Name, Zeitüberschreitungen und mehr konfigurieren.
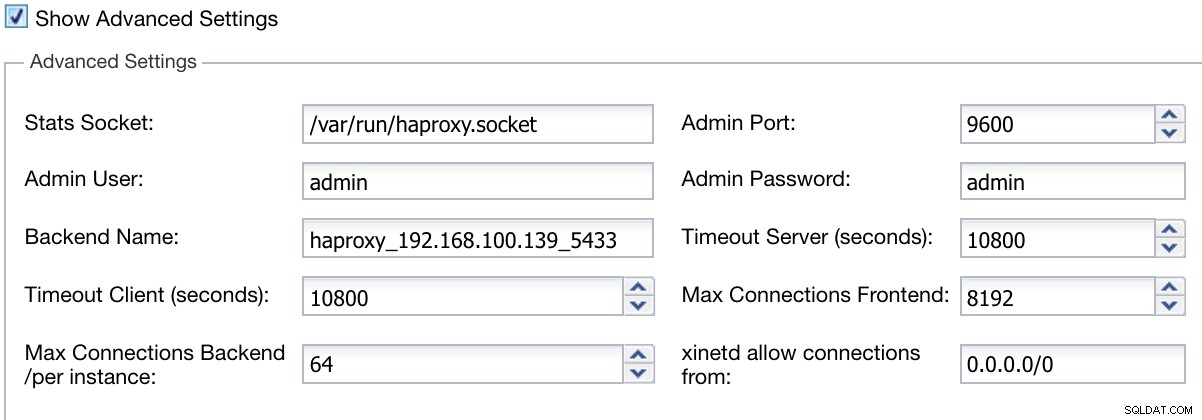 ClusterControl Load Balancer Bereitstellungsinformationen erweitert
ClusterControl Load Balancer Bereitstellungsinformationen erweitert Wenn Sie die Konfiguration abgeschlossen und die Bereitstellung bestätigt haben, können wir den Fortschritt im Aktivitätsbereich auf der ClusterControl-Benutzeroberfläche verfolgen.
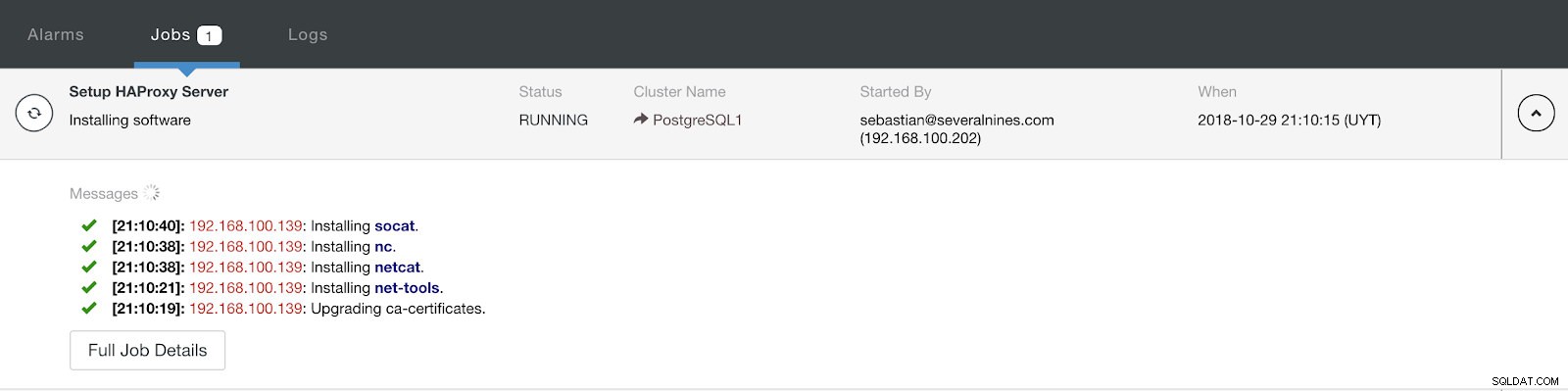 ClusterControl-Aktivitätsabschnitt
ClusterControl-Aktivitätsabschnitt Wenn es fertig ist, sollten wir die folgende Topologie haben:
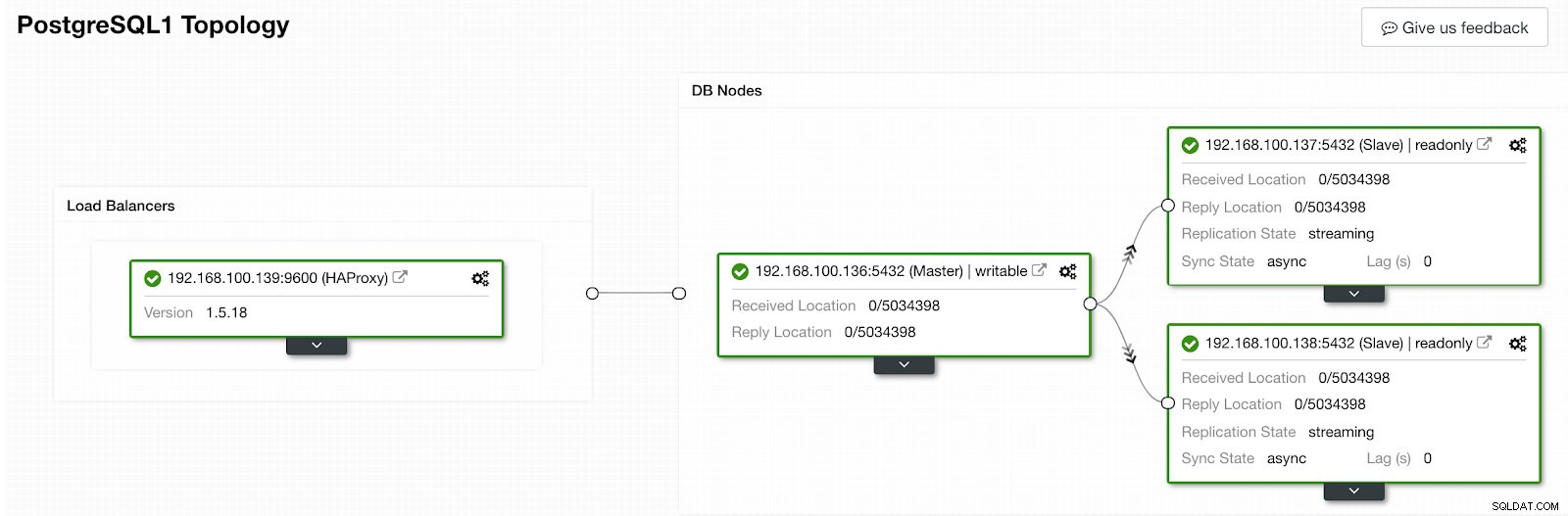 ClusterControl-Topologieansicht 2
ClusterControl-Topologieansicht 2 Wir können unser HA-Design verbessern, indem wir einen neuen HAProxy-Knoten hinzufügen und den Keepalived-Dienst zwischen ihnen konfigurieren. All dies kann von ClusterControl durchgeführt werden. Weitere Informationen finden Sie in unserem vorherigen Blog über PostgreSQL und HA.
Verwenden der ClusterControl CLI zum Hinzufügen eines HAProxy Load Balancer
Dieses optionale Paket, auch bekannt als s9s-tools, wurde in ClusterControl Version 1.4.1 eingeführt, die eine Binärdatei namens s9s enthält. Es ist ein Befehlszeilentool zur Interaktion, Steuerung und Verwaltung Ihrer Datenbankinfrastruktur mit ClusterControl. Das s9s-Befehlszeilenprojekt ist Open Source und kann auf GitHub gefunden werden.
Ab Version 1.4.1 installiert das Installationsskript automatisch das Paket (s9s-tools) auf dem ClusterControl-Knoten.
ClusterControl CLI öffnet eine neue Tür für die Cluster-Automatisierung, wo Sie es einfach in vorhandene Tools zur Bereitstellungsautomatisierung wie Ansible, Puppet, Chef oder Salt integrieren können.
Sehen wir uns ein Beispiel an, wie ein HAProxy-Load-Balancer mit der IP-Adresse 192.168.100.142 auf Cluster-ID 1 erstellt wird:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.Und dann können wir alle unsere Knoten von der Befehlszeile aus überprüfen:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Weitere Informationen zu s9s und seiner Verwendung finden Sie in der offiziellen Dokumentation oder in diesem How-to-Blog zu diesem Thema.
Schlussfolgerung
In diesem Blog haben wir uns angesehen, wie HAProxy uns dabei helfen kann, den Datenverkehr von der Anwendung in unsere PostgreSQL-Datenbank zu verwalten. Wir haben geprüft, wie es manuell bereitgestellt und konfiguriert werden kann, und dann gesehen, wie es mit ClusterControl automatisiert werden kann. Um zu vermeiden, dass HAProxy zu einem Single Point of Failure (SPOF) wird, stellen Sie sicher, dass Sie mindestens zwei HAProxy-Instanzen bereitstellen und darüber etwas wie Keepalived und Virtual IP implementieren.