PostgreSQL ist ein großartiges Projekt und entwickelt sich mit erstaunlicher Geschwindigkeit. Wir werden uns mit einer Reihe von Blogbeiträgen auf die Entwicklung der Fehlertoleranzfunktionen in PostgreSQL in allen Versionen konzentrieren. Dies ist der zweite Beitrag der Serie und wir werden über die Replikation und ihre Bedeutung für die Fehlertoleranz und Zuverlässigkeit von PostgreSQL sprechen.
Wenn Sie den Evolutionsfortschritt von Anfang an miterleben möchten, lesen Sie bitte den ersten Blogbeitrag der Serie:Evolution of Fault Tolerance in PostgreSQL
PostgreSQL-Replikation
Datenbankreplikation ist der Begriff, den wir verwenden, um die Technologie zu beschreiben, die zum Aufbewahren einer Kopie verwendet wird eines Datensatzes auf einer Fernbedienung System. Das Aufbewahren einer zuverlässigen Kopie eines laufenden Systems ist eines der größten Anliegen der Redundanz, und wir alle mögen wartbare, benutzerfreundliche und stabile Kopien unserer Daten.
Schauen wir uns die grundlegende Architektur an. Typischerweise werden einzelne Datenbankserver als Knoten bezeichnet . Die gesamte Gruppe von Datenbankservern, die an der Replikation beteiligt sind, wird als Cluster bezeichnet . Ein Datenbankserver, der es einem Benutzer ermöglicht, Änderungen vorzunehmen, wird als Master bezeichnet oder primär , oder kann als Quelle von Veränderungen beschrieben werden. Ein Datenbankserver, der nur Lesezugriff zulässt, wird als Hot Standby bezeichnet . (Hot-Standby-Begriff wird ausführlich unter dem Titel „Standby-Modi“ erklärt. )
Der Schlüsselaspekt der Replikation besteht darin, dass Datenänderungen auf einem Master erfasst und dann an andere Knoten übertragen werden. In einigen Fällen kann ein Knoten Datenänderungen an andere Knoten senden, was ein Prozess ist, der als Kaskadierung bezeichnet wird oder Relais . Somit ist der Master ein sendender Knoten, aber nicht alle sendenden Knoten müssen Master sein. Die Replikation wird oft danach kategorisiert, ob mehr als ein Master-Knoten erlaubt ist, in diesem Fall wird sie als Multimaster-Replikation bezeichnet .
Sehen wir uns an, wie PostgreSQL die Replikation im Laufe der Zeit handhabt und was der Stand der Technik für die Fehlertoleranz bei den Replikationsbedingungen ist.
PostgreSQL-Replikationsverlauf
In der Vergangenheit (um die Jahre 2000-2005) konzentrierte sich Postgres nur auf die Fehlertoleranz/Wiederherstellung einzelner Knoten, was hauptsächlich durch das Transaktionsprotokoll WAL erreicht wird. Die Fehlertoleranz wird teilweise von MVCC (Multi-Version Concurrency System) gehandhabt, aber es handelt sich hauptsächlich um eine Optimierung.
Write-Ahead-Protokollierung war und ist die größte Fehlertoleranzmethode in PostgreSQL. Im Grunde genommen haben Sie nur WAL-Dateien, in die Sie alles schreiben, und können Fehler durch erneutes Abspielen wiederherstellen. Dies war für Einzelknotenarchitekturen ausreichend und die Replikation gilt als die beste Lösung zum Erreichen von Fehlertoleranz mit mehreren Knoten.
Die Postgres-Community glaubte lange Zeit, dass Replikation etwas ist, das Postgres nicht bieten sollte und von externen Tools gehandhabt werden sollte, weshalb Tools wie Slony und Londiste existierten. (Wir werden Trigger-basierte Replikationslösungen in den nächsten Blogbeiträgen der Serie behandeln.)
Schließlich wurde klar, dass eine Server-Toleranz nicht ausreicht, und mehr Leute forderten eine angemessene Fehlertoleranz der Hardware und eine ordnungsgemäße Art des Umschaltens, etwas, das in Postgres integriert ist. Dies war der Zeitpunkt, an dem die physische (damals physische Streaming-) Replikation zum Leben erweckt wurde.
Wir werden später in diesem Beitrag alle Replikationsmethoden durchgehen, aber sehen wir uns die chronologischen Ereignisse des PostgreSQL-Replikationsverlaufs nach Hauptversionen an:
- PostgreSQL 7.x (~2000)
- Die Replikation sollte kein Teil von Core Postgres sein
- Londiste – Slony (triggerbasierte logische Replikation)
- PostgreSQL 8.0 (2005)
- Point-in-Time-Recovery (WAL)
- PostgreSQL 9.0 (2010)
- Streaming-Replikation (physisch)
- PostgreSQL 9.4 (2014)
- Logische Dekodierung (Änderungssatzextraktion)
Physische Replikation
PostgreSQL löste den Kernreplikationsbedarf mit dem, was die meisten relationalen Datenbanken tun; nahm die WAL und ermöglichte es, sie über das Netzwerk zu senden. Dann werden diese WAL-Dateien in eine separate Postgres-Instanz übernommen, die schreibgeschützt ausgeführt wird.
Die schreibgeschützte Standby-Instanz wendet nur die Änderungen (durch WAL) und die einzigen Schreibvorgänge an kommen wieder aus dem gleichen WAL-Log. So funktioniert im Grunde die Streaming-Replikation Mechanismus funktioniert. Am Anfang verschickte die Replikation ursprünglich alle Dateien –Protokollversand- , aber später entwickelte es sich zum Streaming.
Beim Protokollversand haben wir ganze Dateien über den archive_command gesendet . Die Logik ist dort ziemlich einfach:Sie senden einfach das Archiv und Log es irgendwohin – wie die ganze 16 MB große WAL-Datei – und dann bewerben Sie sich es irgendwohin, und dann holen Sie es das nächste und bewerben das und es geht so. Später wurde es durch Verwendung des libpq-Protokolls in PostgreSQL Version 9.0 zum Streaming über das Netzwerk.
Die vorhandene Replikation wird besser als Physische Streaming-Replikation bezeichnet da wir eine Reihe physischer Änderungen von einem Knoten zum anderen streamen. Das heißt, wenn wir einfügen eine Zeile in eine Tabelle generieren wir Änderungsdatensätze für dieEinfügung plus alle Indexeinträge .
Wenn wir VACUUM einer Tabelle erzeugen wir auch Änderungssätze.
Außerdem zeichnet die physische Streaming-Replikation alle Änderungen auf Byte-/Blockebene auf , was es sehr schwierig macht, etwas anderes zu tun, als einfach alles wiederzugeben
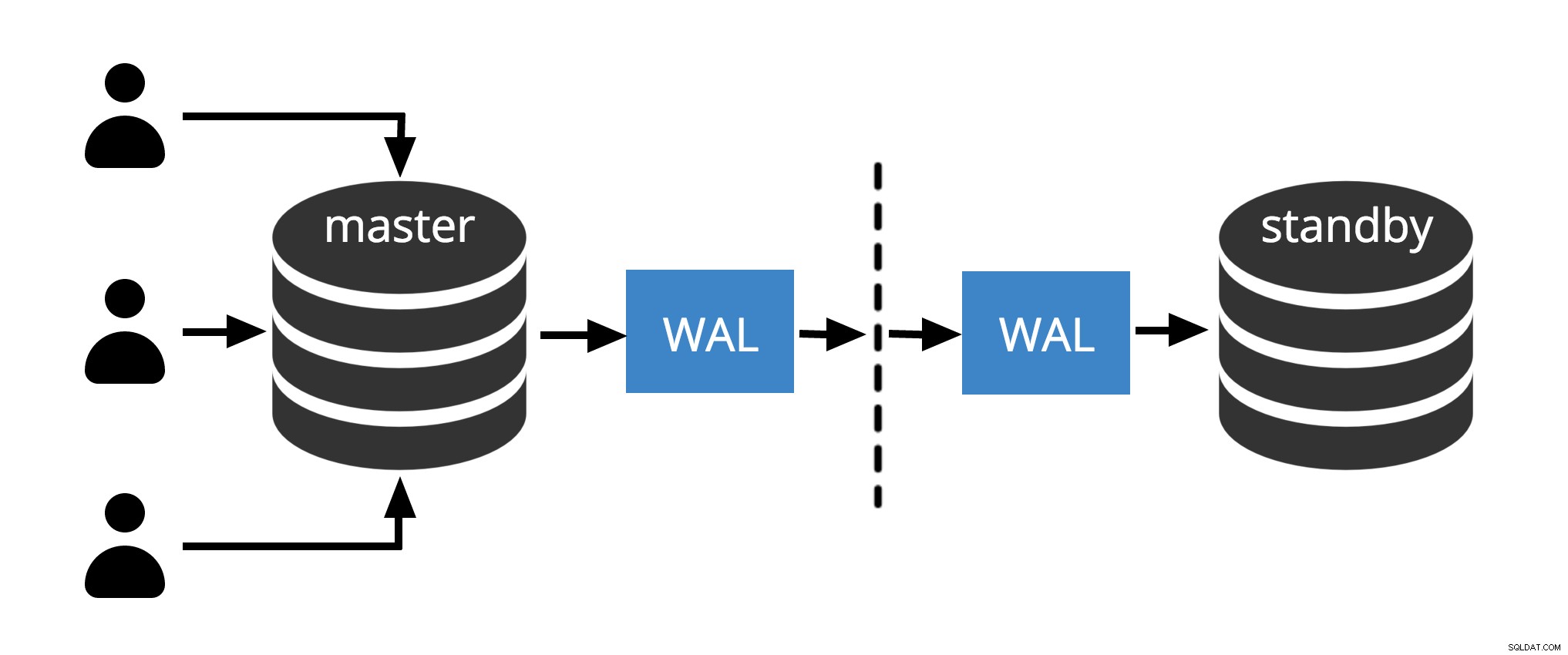
Abb.1 Physische Replikation
Abb. 1 zeigt, wie die physische Replikation mit nur zwei Knoten funktioniert. Der Client führt Abfragen auf dem Master-Knoten aus, die Änderungen werden in ein Transaktionsprotokoll (WAL) geschrieben und über das Netzwerk in WAL auf dem Standby-Knoten kopiert. Der Wiederherstellungsprozess auf dem Standby-Knoten liest dann die Änderungen aus WAL und wendet sie auf die Datendateien an, genau wie bei der Wiederherstellung nach einem Absturz. Wenn sich der Standby im Hot-Standby befindet Modus können Clients schreibgeschützte Abfragen auf dem Knoten ausgeben, während dies geschieht.
Hinweis: Die physische Replikation bezieht sich einfach auf das Senden von WAL-Dateien über das Netzwerk vom Master- zum Standby-Knoten. Dateien können über verschiedene Protokolle wie scp, rsync, ftp… gesendet werden. Der Unterschied zwischen Physischer Replikation und Physische Streaming-Replikation Die Streaming-Replikation verwendet ein internes Protokoll zum Senden von WAL-Dateien (sender und Empfängerprozesse )
Standby-Modi
Mehrere Knoten bieten Hochverfügbarkeit. Aus diesem Grund haben moderne Architekturen normalerweise Standby-Knoten. Es gibt verschiedene Modi für Standby-Knoten (Warm- und Hot-Standby). Die folgende Liste erläutert die grundlegenden Unterschiede zwischen verschiedenen Standby-Modi und zeigt auch den Fall einer Multi-Master-Architektur.
Warm-Standby
Kann sofort aktiviert werden, kann aber bis zur Aktivierung keine nützliche Arbeit leisten. Wenn wir die Reihe von WAL-Dateien kontinuierlich an eine andere Maschine weitergeben, die mit derselben Basis-Sicherungsdatei geladen wurde, haben wir ein Warm-Standby-System:Wir können die zweite Maschine jederzeit hochfahren und sie wird eine fast aktuelle Kopie davon haben die Datenbank. Warm-Standby erlaubt keine Nur-Lese-Anfragen, Abb.2 stellt diese Tatsache einfach dar.
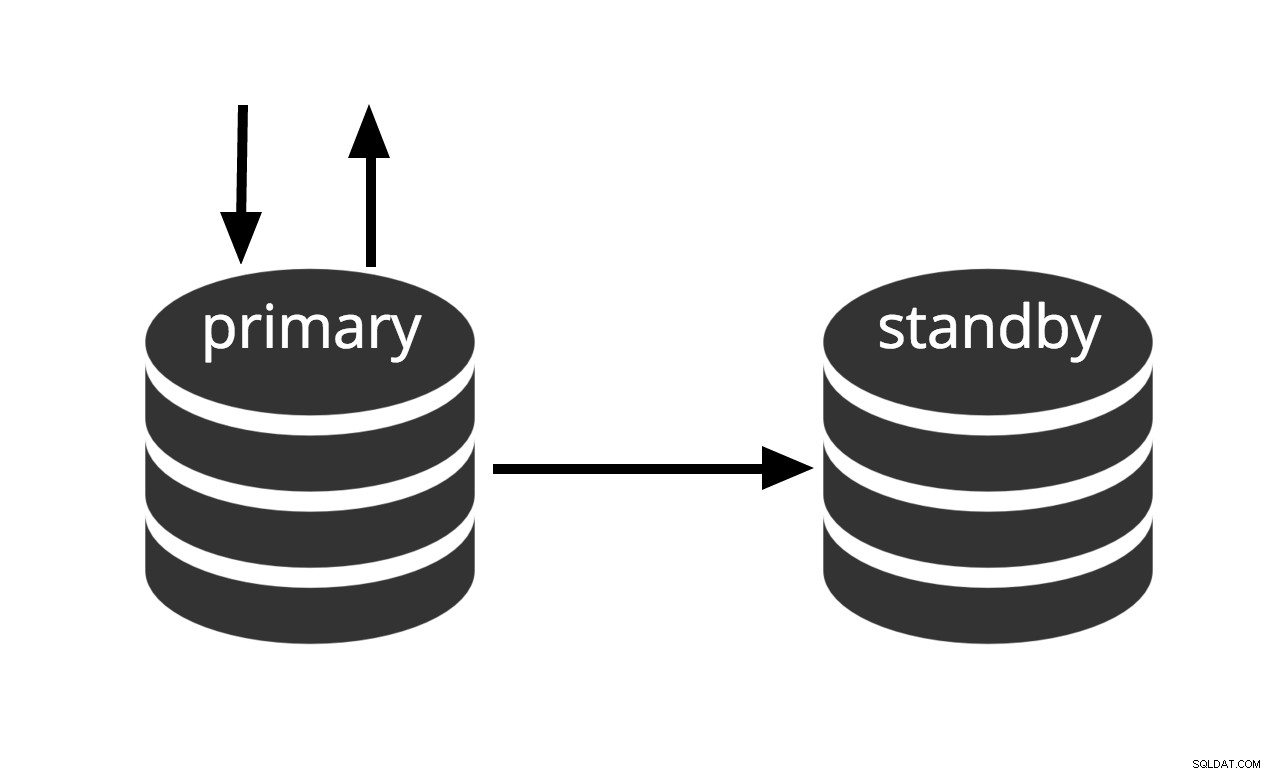
Abb.2 Warm Standby
Die Wiederherstellungsleistung eines Warm-Standby ist ausreichend gut, sodass das Standby normalerweise nur wenige Augenblicke von der vollen Verfügbarkeit entfernt ist, sobald es aktiviert wurde. Daher wird dies als Warm-Standby-Konfiguration bezeichnet, die eine hohe Verfügbarkeit bietet.
Hot-Standby
Hot Standby ist der Begriff, der verwendet wird, um die Möglichkeit zu beschreiben, eine Verbindung zum Server herzustellen und schreibgeschützte Abfragen auszuführen, während sich der Server im Archivwiederherstellungs- oder Standby-Modus befindet. Dies ist sowohl für Replikationszwecke als auch für die präzise Wiederherstellung eines gewünschten Zustands eines Backups nützlich.
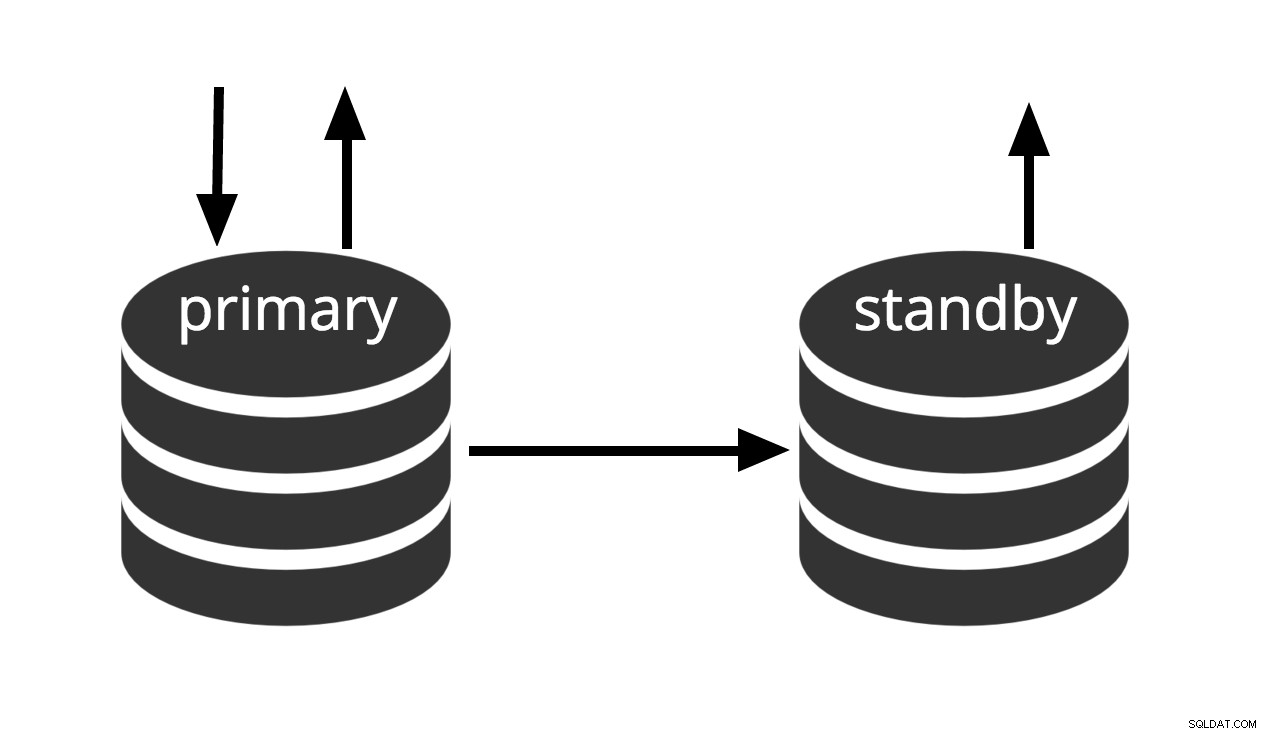 Abb. 3 Hot Standby
Abb. 3 Hot Standby
Der Begriff Hot-Standby bezieht sich auch auf die Fähigkeit des Servers, von der Wiederherstellung in den Normalbetrieb überzugehen, während Benutzer weiterhin Abfragen ausführen und/oder ihre Verbindungen offen halten. Abb. 3 zeigt, dass der Standby-Modus schreibgeschützte Abfragen zulässt.
Multi-Master
Alle Knoten können Lese-/Schreibvorgänge ausführen. (Wir behandeln Multi-Master-Architekturen in den nächsten Blogbeiträgen der Serie.)
WAL-Level-Parameter
Es besteht eine Beziehung zwischen dem Einrichten von wal_level Parameter in der Datei postgresql.conf und wofür ist diese Einstellung geeignet. Ich habe eine Tabelle erstellt, um die Beziehung für PostgreSQL Version 9.6 anzuzeigen.

Failover und Switchover
Wenn bei der Single-Master-Replikation der Master stirbt, muss einer der Standbys seinen Platz einnehmen (Beförderung ). Andernfalls können wir keine neuen Schreibtransaktionen akzeptieren. Daher sind die Begriffsbezeichnungen Master und Standby nur Rollen, die jeder Knoten irgendwann einnehmen kann. Um die Master-Rolle auf einen anderen Knoten zu verschieben, führen wir ein Verfahren namens Switchover durch .
Wenn der Master stirbt und sich nicht erholt, wird die schwerwiegendere Rollenänderung als Failover bezeichnet . In vielerlei Hinsicht können diese ähnlich sein, aber es ist hilfreich, für jedes Ereignis unterschiedliche Begriffe zu verwenden. (Die Kenntnis der Bedingungen für Failover und Switchover hilft uns beim Verständnis der Zeitachsenprobleme im nächsten Blogbeitrag.)
Schlussfolgerung
In diesem Blogbeitrag haben wir die PostgreSQL-Replikation und ihre Bedeutung für die Bereitstellung von Fehlertoleranz und Zuverlässigkeit besprochen. Wir haben die physische Streaming-Replikation behandelt und über Standby-Modi für PostgreSQL gesprochen. Wir haben Failover und Switchover erwähnt. Wir werden mit den PostgreSQL-Zeitleisten im nächsten Blogbeitrag fortfahren.
Referenzen
PostgreSQL-Dokumentation
Logical Replication in PostgreSQL 5432…MeetUs-Präsentation von Petr Jelinek
PostgreSQL 9 Administration Cookbook – Zweite Ausgabe



