Dieser Artikel ist der fünfte Teil einer Reihe über Tabellenausdrücke. In Teil 1 habe ich den Hintergrund zu Tabellenausdrücken bereitgestellt. In Teil 2, Teil 3 und Teil 4 habe ich sowohl die logischen als auch die Optimierungsaspekte von abgeleiteten Tabellen behandelt. Diesen Monat beginne ich mit der Behandlung von Common Table Expressions (CTEs). Wie bei abgeleiteten Tabellen werde ich zunächst auf die logische Behandlung von CTEs eingehen und in Zukunft auf Optimierungsüberlegungen eingehen.
In meinen Beispielen verwende ich eine Beispieldatenbank namens TSQLV5. Sie finden das Skript, das es erstellt und füllt, hier und sein ER-Diagramm hier.
CTEs
Beginnen wir mit dem Begriff allgemeiner Tabellenausdruck . Weder dieser Begriff noch sein Akronym CTE erscheinen in den ISO/IEC-SQL-Standardspezifikationen. Es könnte also sein, dass der Begriff aus einem der Datenbankprodukte stammt und später von einigen anderen Datenbankanbietern übernommen wurde. Sie finden es in der Dokumentation von Microsoft SQL Server und Azure SQL Database. T-SQL unterstützt dies ab SQL Server 2005. Der Standard verwendet den Begriff Abfrageausdruck um einen Ausdruck darzustellen, der einen oder mehrere CTEs definiert, einschließlich der äußeren Abfrage. Es verwendet den Begriff mit Listenelement um darzustellen, was T-SQL einen CTE nennt. Ich werde in Kürze die Syntax für einen Abfrageausdruck bereitstellen.
Die Quelle des Begriffs beiseite, allgemeiner Tabellenausdruck , oder CTE , ist der von T-SQL-Experten häufig verwendete Begriff für die Struktur, die im Mittelpunkt dieses Artikels steht. Lassen Sie uns also zuerst ansprechen, ob es sich um einen angemessenen Begriff handelt. Wir haben bereits festgestellt, dass der Begriff Tabellenausdruck ist für einen Ausdruck geeignet, der konzeptionell eine Tabelle zurückgibt. Abgeleitete Tabellen, CTEs, Ansichten und Inline-Tabellenwertfunktionen sind alle Arten von benannten Tabellenausdrücken die T-SQL unterstützt. Also der Tabellenausdruck Teil des allgemeinen Tabellenausdrucks scheint auf jeden Fall angemessen. Wie für das Gemeinsame Teil des Begriffs, hat es wahrscheinlich mit einem der Designvorteile von CTEs gegenüber abgeleiteten Tabellen zu tun. Denken Sie daran, dass Sie den Namen der abgeleiteten Tabelle (oder genauer gesagt den Namen der Bereichsvariablen) nicht mehr als einmal in der äußeren Abfrage wiederverwenden können. Umgekehrt kann der CTE-Name mehrfach in der äußeren Abfrage verwendet werden. Mit anderen Worten, der CTE-Name ist allgemein zur äußeren Abfrage. Natürlich werde ich diesen Designaspekt in diesem Artikel demonstrieren.
CTEs bieten Ihnen ähnliche Vorteile wie abgeleitete Tabellen, einschließlich der Ermöglichung der Entwicklung modularer Lösungen, der Wiederverwendung von Spaltenaliasen, der indirekten Interaktion mit Fensterfunktionen in Klauseln, die dies normalerweise nicht zulassen, der Unterstützung von Modifikationen, die sich indirekt auf TOP oder OFFSET FETCH mit der Auftragsspezifikation stützen. und andere. Aber es gibt bestimmte Designvorteile im Vergleich zu abgeleiteten Tabellen, auf die ich ausführlich eingehen werde, nachdem ich die Syntax für die Struktur bereitgestellt habe.
Syntax
Hier ist die Syntax des Standards für einen Abfrageausdruck:
7.17
Funktion
Geben Sie eine Tabelle an.
Formatieren
[
[
AS
|
[
|
[
|
[
|
[
CORRESPONDING [ BY
FETCH { FIRST | WEITER } [
|
7.18
Funktion
Geben Sie die Generierung von Sortier- und Zykluserkennungsinformationen im Ergebnis rekursiver Abfrageausdrücke an.
Formatieren
SEARCH
DEPTH FIRST BY
CYCLE
DEFAULT
7.3
Funktion
Geben Sie einen Satz von
Der Standardbegriff Abfrageausdruck stellt einen Ausdruck dar, der eine WITH-Klausel beinhaltet, eine with list , die aus einem oder mehreren mit Listenelementen besteht , und eine äußere Abfrage. T-SQL bezieht sich auf den Standard mit Listenelement als CTE.
T-SQL unterstützt nicht alle Standard-Syntaxelemente. Beispielsweise werden einige der fortgeschritteneren rekursiven Abfrageelemente nicht unterstützt, mit denen Sie die Suchrichtung steuern und Zyklen in einer Diagrammstruktur behandeln können. Rekursive Abfragen stehen im Mittelpunkt des Artikels im nächsten Monat.
Hier ist die T-SQL-Syntax für eine vereinfachte Abfrage eines CTE:
Hier ist ein Beispiel für eine einfache Abfrage eines CTE, der Kunden in den USA repräsentiert:
In einer Anweisung gegen einen CTE finden Sie die gleichen drei Teile wie bei einer Anweisung gegen eine abgeleitete Tabelle:
Was das Design von CTEs im Vergleich zu abgeleiteten Tabellen unterscheidet, ist, wo sich diese drei Elemente im Code befinden. Bei abgeleiteten Tabellen ist die innere Abfrage in der FROM-Klausel der äußeren Abfrage verschachtelt, und der Name des Tabellenausdrucks wird nach dem Tabellenausdruck selbst zugewiesen. Die Elemente sind irgendwie miteinander verflochten. Umgekehrt trennt der Code bei CTEs die drei Elemente:Zuerst weisen Sie den Namen des Tabellenausdrucks zu; zweitens spezifizieren Sie den Tabellenausdruck – von Anfang bis Ende ohne Unterbrechungen; Drittens spezifizieren Sie die äußere Abfrage – von Anfang bis Ende ohne Unterbrechungen. Später, unter „Überlegungen zum Design“, werde ich die Auswirkungen dieser Designunterschiede erläutern.
Ein Wort zu CTEs und der Verwendung eines Semikolons als Abschlusszeichen für Anweisungen. Im Gegensatz zu Standard-SQL zwingt Sie T-SQL leider nicht dazu, alle Anweisungen mit einem Semikolon abzuschließen. Es gibt jedoch nur sehr wenige Fälle in T-SQL, in denen der Code ohne Abschlusszeichen mehrdeutig ist. In diesen Fällen ist die Kündigung zwingend. Ein solcher Fall betrifft die Tatsache, dass die WITH-Klausel für mehrere Zwecke verwendet wird. Eine besteht darin, einen CTE zu definieren, eine andere darin, einen Tabellenhinweis für eine Abfrage zu definieren, und es gibt einige zusätzliche Anwendungsfälle. Als Beispiel wird in der folgenden Anweisung die WITH-Klausel verwendet, um die serialisierbare Isolationsstufe mit einem Tabellenhinweis zu erzwingen:
Das Potenzial für Mehrdeutigkeiten besteht, wenn Sie eine nicht abgeschlossene Anweisung vor einer CTE-Definition haben, in diesem Fall kann der Parser möglicherweise nicht erkennen, ob die WITH-Klausel zur ersten oder zur zweiten Anweisung gehört. Hier ist ein Beispiel, das dies demonstriert:
Hier kann der Parser nicht erkennen, ob die WITH-Klausel verwendet werden soll, um einen Tabellenhinweis für die Customers-Tabelle in der ersten Anweisung zu definieren, oder eine CTE-Definition zu starten. Sie erhalten die folgende Fehlermeldung:
Die Lösung besteht natürlich darin, die Anweisung vor der CTE-Definition zu beenden, aber als Best Practice sollten Sie wirklich alle Ihre Anweisungen beenden:
Sie haben vielleicht bemerkt, dass einige Leute ihre CTE-Definitionen aus Gewohnheit mit einem Semikolon beginnen, etwa so:
Bei dieser Vorgehensweise geht es darum, das Potenzial für zukünftige Fehler zu reduzieren. Was ist, wenn jemand zu einem späteren Zeitpunkt direkt vor Ihrer CTE-Definition im Skript eine nicht abgeschlossene Anweisung hinzufügt und sich nicht die Mühe macht, das vollständige Skript zu überprüfen, sondern nur seine Anweisung? Ihr Semikolon direkt vor der WITH-Klausel wird effektiv zu ihrem Abschlusszeichen. Sie können sicherlich die Praktikabilität dieser Praxis erkennen, aber sie ist ein bisschen unnatürlich. Was empfohlen wird, auch wenn es schwieriger zu erreichen ist, ist die Einführung guter Programmierpraktiken in der Organisation, einschließlich der Beendigung aller Anweisungen.
Hinsichtlich der Syntaxregeln, die für den Tabellenausdruck gelten, der als innere Abfrage in der CTE-Definition verwendet wird, sind sie die gleichen wie diejenigen, die für den Tabellenausdruck gelten, der als innere Abfrage in einer abgeleiteten Tabellendefinition verwendet wird. Das sind:
Einzelheiten finden Sie im Abschnitt „Ein Tabellenausdruck ist eine Tabelle“ in Teil 2 der Serie.
Wenn Sie erfahrene T-SQL-Entwickler befragen, ob sie abgeleitete Tabellen oder CTEs bevorzugen, werden sich nicht alle darüber einig sein, was besser ist. Natürlich haben verschiedene Menschen unterschiedliche Styling-Vorlieben. Ich verwende manchmal abgeleitete Tabellen und manchmal CTEs. Es ist gut, die spezifischen Sprachdesign-Unterschiede zwischen den beiden Tools bewusst identifizieren und basierend auf Ihren Prioritäten in einer bestimmten Lösung auswählen zu können. Mit der Zeit und Erfahrung treffen Sie Ihre Entscheidungen intuitiver.
Darüber hinaus ist es wichtig, die Verwendung von Tabellenausdrücken und temporären Tabellen nicht zu verwechseln, aber das ist eine leistungsbezogene Diskussion, die ich in einem zukünftigen Artikel ansprechen werde.
CTEs haben rekursive Abfragefunktionen und abgeleitete Tabellen nicht. Wenn Sie sich also auf diese verlassen müssen, würden Sie sich natürlich für CTEs entscheiden. Rekursive Abfragen stehen im Mittelpunkt des Artikels im nächsten Monat.
In Teil 2 habe ich erklärt, dass ich das Verschachteln von abgeleiteten Tabellen als zusätzliche Komplexität des Codes betrachte, da es es schwierig macht, der Logik zu folgen. Ich habe das folgende Beispiel bereitgestellt, das Bestelljahre identifiziert, in denen mehr als 70 Kunden Bestellungen aufgegeben haben:
CTEs unterstützen keine Verschachtelung. Wenn Sie also eine auf CTEs basierende Lösung überprüfen oder Fehler beheben, verlieren Sie sich nicht in der verschachtelten Logik. Anstatt zu verschachteln, erstellen Sie modularere Lösungen, indem Sie mehrere CTEs unter derselben WITH-Anweisung definieren, die durch Kommas getrennt sind. Jeder der CTEs basiert auf einer Abfrage, die von Anfang bis Ende ohne Unterbrechungen geschrieben wird. Ich sehe es aus Sicht der Code-Klarheit und Wartbarkeit als eine gute Sache.
Hier ist eine Lösung für die oben genannte Aufgabe mit CTEs:
Mir gefällt die CTE-basierte Lösung besser. Aber fragen Sie erfahrene Entwickler, welche der beiden oben genannten Lösungen sie bevorzugen, und sie werden nicht alle zustimmen. Einige bevorzugen tatsächlich die verschachtelte Logik und die Möglichkeit, alles an einem Ort zu sehen.
Ein klarer Vorteil von CTEs gegenüber abgeleiteten Tabellen besteht darin, dass Sie mit mehreren Instanzen desselben Tabellenausdrucks in Ihrer Lösung interagieren müssen. Erinnern Sie sich an das folgende Beispiel basierend auf abgeleiteten Tabellen aus Teil 2 der Serie:
Diese Lösung gibt Bestelljahre, Bestellzahlen pro Jahr und die Differenz zwischen den Zahlen des aktuellen Jahres und des Vorjahres zurück. Ja, Sie könnten es mit der LAG-Funktion einfacher machen, aber mein Fokus liegt hier nicht darauf, den besten Weg zu finden, um diese sehr spezielle Aufgabe zu lösen. Ich verwende dieses Beispiel, um bestimmte Aspekte des Sprachdesigns benannter Tabellenausdrücke zu veranschaulichen.
Das Problem bei dieser Lösung besteht darin, dass Sie einem Tabellenausdruck keinen Namen zuweisen und ihn im selben logischen Abfrageverarbeitungsschritt wiederverwenden können. Sie benennen eine abgeleitete Tabelle nach dem Tabellenausdruck selbst in der FROM-Klausel. Wenn Sie eine abgeleitete Tabelle als erste Eingabe eines Joins definieren und benennen, können Sie diesen abgeleiteten Tabellennamen nicht auch als zweite Eingabe desselben Joins wiederverwenden. Wenn Sie zwei Instanzen desselben Tabellenausdrucks selbst verknüpfen müssen, haben Sie bei abgeleiteten Tabellen keine andere Wahl, als den Code zu duplizieren. Das haben Sie im obigen Beispiel getan. Umgekehrt wird der CTE-Name als erstes Element des Codes unter den oben genannten drei (CTE-Name, innere Abfrage, äußere Abfrage) zugewiesen. In Bezug auf die logische Abfrageverarbeitung ist der CTE-Name bereits definiert und verfügbar, wenn Sie zur äußeren Abfrage gelangen. Das bedeutet, dass Sie mit mehreren Instanzen des CTE-Namens in der äußeren Abfrage wie folgt interagieren können:
Diese Lösung hat einen klaren Programmierbarkeitsvorteil gegenüber der auf abgeleiteten Tabellen basierenden Lösung, da Sie nicht zwei Kopien desselben Tabellenausdrucks verwalten müssen. Aus Sicht der physischen Verarbeitung gibt es noch mehr darüber zu sagen und es mit der Verwendung temporärer Tabellen zu vergleichen, aber ich werde dies in einem zukünftigen Artikel tun, der sich auf die Leistung konzentriert.
Ein Vorteil, den Code, der auf abgeleiteten Tabellen basiert, im Vergleich zu Code, der auf CTEs basiert, hat, hat mit der Abschlusseigenschaft zu tun, die ein Tabellenausdruck besitzen soll. Denken Sie daran, dass die Abschlusseigenschaft eines relationalen Ausdrucks besagt, dass sowohl die Eingaben als auch die Ausgabe Relationen sind und dass ein relationaler Ausdruck daher dort verwendet werden kann, wo eine Relation erwartet wird, als Eingabe für einen weiteren relationalen Ausdruck. Ebenso gibt ein Tabellenausdruck eine Tabelle zurück und soll als Eingabetabelle für einen anderen Tabellenausdruck zur Verfügung stehen. Dies gilt für eine Abfrage, die auf abgeleiteten Tabellen basiert – Sie können sie dort verwenden, wo eine Tabelle erwartet wird. Beispielsweise können Sie eine Abfrage, die auf abgeleiteten Tabellen basiert, als innere Abfrage einer CTE-Definition verwenden, wie im folgenden Beispiel:
Dasselbe gilt jedoch nicht für eine Abfrage, die auf CTEs basiert. Obwohl es konzeptionell als Tabellenausdruck betrachtet werden sollte, können Sie es nicht als innere Abfrage in abgeleiteten Tabellendefinitionen, Unterabfragen und CTEs selbst verwenden. Beispielsweise ist der folgende Code in T-SQL nicht gültig:
Die gute Nachricht ist, dass Sie eine auf CTEs basierende Abfrage als innere Abfrage in Ansichten und Inline-Tabellenwertfunktionen verwenden können, die ich in zukünftigen Artikeln behandeln werde.
Denken Sie auch daran, dass Sie immer einen anderen CTE basierend auf der letzten Abfrage definieren können und dann die äußerste Abfrage mit diesem CTE interagieren lassen:
Vom Standpunkt der Fehlerbehebung aus finde ich es, wie erwähnt, normalerweise einfacher, der Logik von Code zu folgen, der auf CTEs basiert, im Vergleich zu Code, der auf abgeleiteten Tabellen basiert. Lösungen, die auf abgeleiteten Tabellen basieren, haben jedoch den Vorteil, dass Sie jede Verschachtelungsebene hervorheben und unabhängig ausführen können, wie in Abbildung 1 gezeigt.
Bei CTEs sind die Dinge schwieriger. Damit Code mit CTEs ausgeführt werden kann, muss er mit einer WITH-Klausel beginnen, gefolgt von einem oder mehreren benannten Tabellenausdrücken in Klammern, die durch Kommas getrennt sind, gefolgt von einer Abfrage ohne Klammern ohne vorangestelltes Komma. Sie können jede der inneren Abfragen hervorheben und ausführen, die wirklich eigenständig sind, sowie den Code der vollständigen Lösung; Sie können jedoch keinen anderen Zwischenteil der Lösung hervorheben und erfolgreich ausführen. Abbildung 2 zeigt beispielsweise einen erfolglosen Versuch, den Code auszuführen, der C2 repräsentiert.
Bei CTEs muss man also zu etwas umständlichen Mitteln greifen, um einen Zwischenschritt der Lösung beheben zu können. Eine gängige Lösung besteht beispielsweise darin, vorübergehend eine SELECT * FROM your_cte-Abfrage direkt unter dem relevanten CTE einzufügen. Sie markieren dann den Code und führen ihn aus, einschließlich der eingefügten Abfrage, und wenn Sie fertig sind, löschen Sie die eingefügte Abfrage. Abbildung 3 demonstriert diese Technik.
Das Problem besteht darin, dass jedes Mal, wenn Sie Änderungen am Code vornehmen – selbst geringfügige vorübergehende wie die oben genannten – die Möglichkeit besteht, dass Sie beim Versuch, zum ursprünglichen Code zurückzukehren, am Ende einen neuen Fehler einführen.
Eine andere Möglichkeit besteht darin, Ihren Code etwas anders zu gestalten, so dass jede nichterste CTE-Definition mit einer separaten Codezeile beginnt, die so aussieht:
Wenn Sie dann einen Zwischenteil des Codes bis zu einem bestimmten CTE ausführen möchten, können Sie dies mit minimalen Änderungen an Ihrem Code tun. Mit einem Zeilenkommentar kommentieren Sie nur die Codezeile aus, die diesem CTE entspricht. Dann heben Sie den Code hervor und führen ihn bis einschließlich der inneren Abfrage dieses CTE aus, die jetzt als die äußerste Abfrage betrachtet wird, wie in Abbildung 4 dargestellt.
Wenn Sie mit diesem Stil nicht zufrieden sind, haben Sie noch eine andere Option. Sie können einen Blockkommentar verwenden, der direkt vor dem Komma vor dem interessierenden CTE beginnt und nach der offenen Klammer endet, wie in Abbildung 5 dargestellt.
Es läuft auf persönliche Vorlieben hinaus. Ich verwende normalerweise die temporär injizierte SELECT *-Abfragetechnik.
Es gibt eine gewisse Einschränkung bei der Unterstützung von Tabellenwertkonstruktoren durch T-SQL im Vergleich zum Standard. Wenn Sie mit dem Konstrukt nicht vertraut sind, schauen Sie sich zuerst Teil 2 der Serie an, in dem ich es ausführlich beschreibe. Während Sie mit T-SQL eine abgeleitete Tabelle basierend auf einem Tabellenwertkonstruktor definieren können, können Sie keinen CTE basierend auf einem Tabellenwertkonstruktor definieren.
Hier ist ein unterstütztes Beispiel, das eine abgeleitete Tabelle verwendet:
Leider wird ähnlicher Code, der einen CTE verwendet, nicht unterstützt:
Dieser Code generiert den folgenden Fehler:
Es gibt jedoch ein paar Problemumgehungen. Eine besteht darin, eine Abfrage für eine abgeleitete Tabelle zu verwenden, die wiederum auf einem Tabellenwertkonstruktor basiert, als innere Abfrage des CTE, etwa so:
Eine andere besteht darin, auf die Technik zurückzugreifen, die vor der Einführung von Tabellenwertkonstruktoren in T-SQL verwendet wurde – mit einer Reihe von Abfragen ohne FROM, die durch UNION ALL-Operatoren getrennt sind, etwa so:
Beachten Sie, dass die Spaltenaliasnamen direkt nach dem CTE-Namen zugewiesen werden.
Die beiden Methoden werden gleich algebriert und optimiert, also verwenden Sie die Methode, mit der Sie sich wohler fühlen.
Ein Hilfsmittel, das ich in meinen Lösungen oft verwende, ist eine Hilfstabelle mit Zahlen. Eine Möglichkeit besteht darin, eine tatsächliche Zahlentabelle in Ihrer Datenbank zu erstellen und sie mit einer angemessen großen Sequenz zu füllen. Eine andere besteht darin, eine Lösung zu entwickeln, die spontan eine Zahlenfolge erzeugt. Für die letztere Option möchten Sie, dass die Eingaben die Trennzeichen des gewünschten Bereichs sind (wir nennen sie
Dieser Code generiert die folgende Ausgabe:
Der erste CTE namens L0 basiert auf einem Tabellenwertkonstruktor mit zwei Zeilen. Die tatsächlichen Werte dort sind unbedeutend; Wichtig ist, dass es zwei Reihen hat. Dann gibt es eine Folge von fünf zusätzlichen CTEs mit den Namen L1 bis L5, die jeweils einen Cross Join zwischen zwei Instanzen des vorhergehenden CTE anwenden. Der folgende Code berechnet die Anzahl der Zeilen, die möglicherweise von jedem der CTEs generiert werden, wobei @L die Nummer der CTE-Ebene ist:
Hier sind die Zahlen, die Sie für jeden CTE erhalten:
Wenn Sie zu Level 5 aufsteigen, erhalten Sie über vier Milliarden Zeilen. Dies sollte für jeden praktischen Anwendungsfall ausreichen, den ich mir vorstellen kann. Der nächste Schritt findet im CTE namens Nums statt. Sie verwenden eine ROW_NUMBER-Funktion, um eine Folge von ganzen Zahlen zu generieren, die mit 1 beginnen, basierend auf keiner definierten Reihenfolge (ORDER BY (SELECT NULL)), und benennen die Ergebnisspalte rownum. Schließlich verwendet die äußere Abfrage einen TOP-Filter, der auf der Rownum-Reihenfolge basiert, um so viele Zahlen wie die gewünschte Sequenzkardinalität (@high – @low + 1) zu filtern, und berechnet die Ergebniszahl n als @low + rownum – 1.
Hier können Sie die Schönheit des CTE-Designs und die Einsparungen, die es ermöglicht, wenn Sie Lösungen modular aufbauen, wirklich schätzen. Letztendlich entpackt der Entschachtelungsprozess 32 Tabellen, die jeweils aus zwei Zeilen bestehen, die auf Konstanten basieren. Dies ist deutlich im Ausführungsplan für diesen Code zu sehen, wie in Abbildung 6 mit SentryOne Plan Explorer gezeigt.
Jeder Constant-Scan-Operator repräsentiert eine Tabelle mit Konstanten mit zwei Zeilen. Die Sache ist die, dass der Top-Operator derjenige ist, der diese Zeilen anfordert, und er schließt kurz, nachdem er die gewünschte Nummer erhalten hat. Beachten Sie die 10 Zeilen, die über dem Pfeil angezeigt werden, der in den Top-Operator fließt.
Ich weiß, dass der Schwerpunkt dieses Artikels auf der konzeptionellen Behandlung von CTEs und nicht auf physischen/leistungsbezogenen Erwägungen liegt, aber wenn Sie sich den Plan ansehen, können Sie die Kürze des Codes im Vergleich zu der Langatmigkeit dessen, was er hinter den Kulissen bedeutet, wirklich schätzen.
Mit abgeleiteten Tabellen können Sie tatsächlich eine Lösung schreiben, die jede CTE-Referenz durch die zugrunde liegende Abfrage ersetzt, die sie darstellt. Was Sie bekommen, ist ziemlich beängstigend:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Formatieren
VALUES
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Falsche Syntax in der Nähe von 'UC'. Soll dies ein allgemeiner Tabellenausdruck sein, müssen Sie die vorherige Anweisung explizit mit einem Semikolon abschließen. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Überlegungen zum Design
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Abbildung 1:Kann einen Teil des Codes mit abgeleiteten Tabellen hervorheben und ausführen
Abbildung 1:Kann einen Teil des Codes mit abgeleiteten Tabellen hervorheben und ausführen  Abbildung 2:Ein Teil des Codes kann nicht mit CTEs hervorgehoben und ausgeführt werden
Abbildung 2:Ein Teil des Codes kann nicht mit CTEs hervorgehoben und ausgeführt werden  Abbildung 3:Fügen Sie SELECT * unter dem relevanten CTE ein
Abbildung 3:Fügen Sie SELECT * unter dem relevanten CTE ein , cte_name AS (
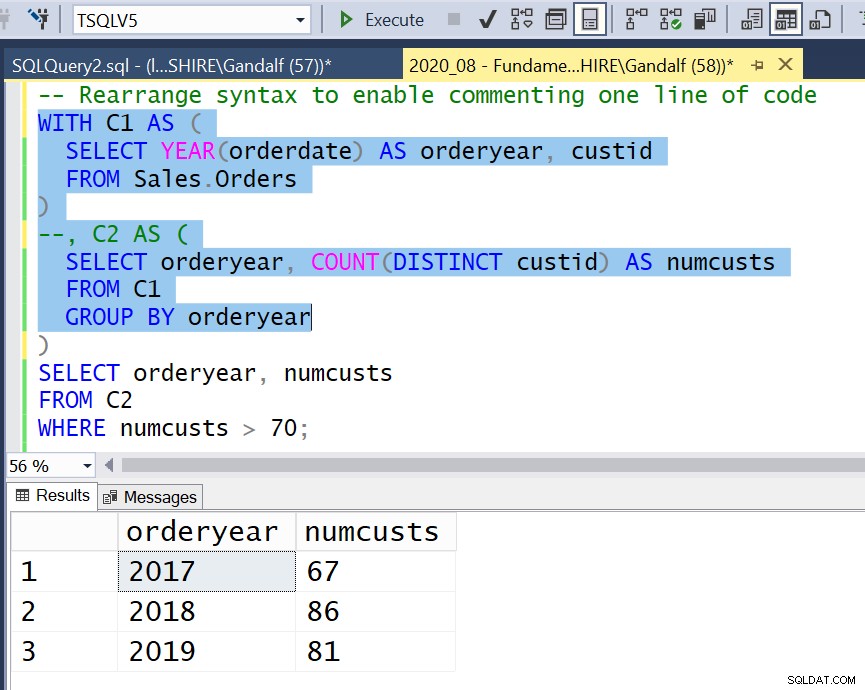 Abbildung 4:Syntax neu anordnen, um das Kommentieren einer Codezeile zu ermöglichen
Abbildung 4:Syntax neu anordnen, um das Kommentieren einer Codezeile zu ermöglichen  Abbildung 5:Blockkommentar verwenden
Abbildung 5:Blockkommentar verwenden Tabellenwertkonstruktor
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Falsche Syntax in der Nähe des Schlüsselworts „VALUES“. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Eine Zahlenfolge erzeugen
@low und @high ). Sie möchten, dass Ihre Lösung potenziell große Bereiche unterstützt. Hier ist meine Lösung für diesen Zweck unter Verwendung von CTEs mit einer Anfrage für den Bereich 1001 bis 1010 in diesem speziellen Beispiel:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Kardinalität L0 2 L1 4 L2 16 L3 256 L4 65.536 L5 4.294.967.296  Abbildung 6:Plan für die Generierung einer Zahlenfolge für Abfragen
Abbildung 6:Plan für die Generierung einer Zahlenfolge für Abfragen DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Zusammenfassung
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes