Wie wir kürzlich angekündigt haben, hat ClusterControl 1.7.4 eine neue Funktion namens Cluster-zu-Cluster-Replikation. Es ermöglicht Ihnen, eine Replikation zwischen zwei autonomen Clustern auszuführen. Nähere Informationen entnehmen Sie bitte der oben genannten Ankündigung.
Wir sehen uns an, wie Sie diese neue Funktion für einen bestehenden PostgreSQL-Cluster verwenden können. Für diese Aufgabe gehen wir davon aus, dass Sie ClusterControl installiert haben und der Master-Cluster damit bereitgestellt wurde.
Anforderungen für das Mastercluster
Der Master-Cluster muss einige Anforderungen erfüllen, damit er funktioniert:
- PostgreSQL 9.6 oder höher.
- Es muss ein PostgreSQL-Server mit der ClusterControl-Rolle 'Master' vorhanden sein.
- Beim Einrichten des Slave-Clusters müssen die Admin-Anmeldedaten mit denen des Master-Clusters identisch sein.
Master-Cluster vorbereiten
Der Mastercluster muss die oben genannten Anforderungen erfüllen.
Über die erste Anforderung stellen Sie sicher, dass Sie die richtige PostgreSQL-Version im Master-Cluster verwenden und dieselbe für den Slave-Cluster auswählen.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitWenn Sie die Master-Rolle einem bestimmten Knoten zuweisen müssen, können Sie dies über die ClusterControl-Benutzeroberfläche tun. Gehen Sie zu ClusterControl -> Select Master Cluster -> Nodes -> Select the Node -> Node Actions -> Promote Slave.
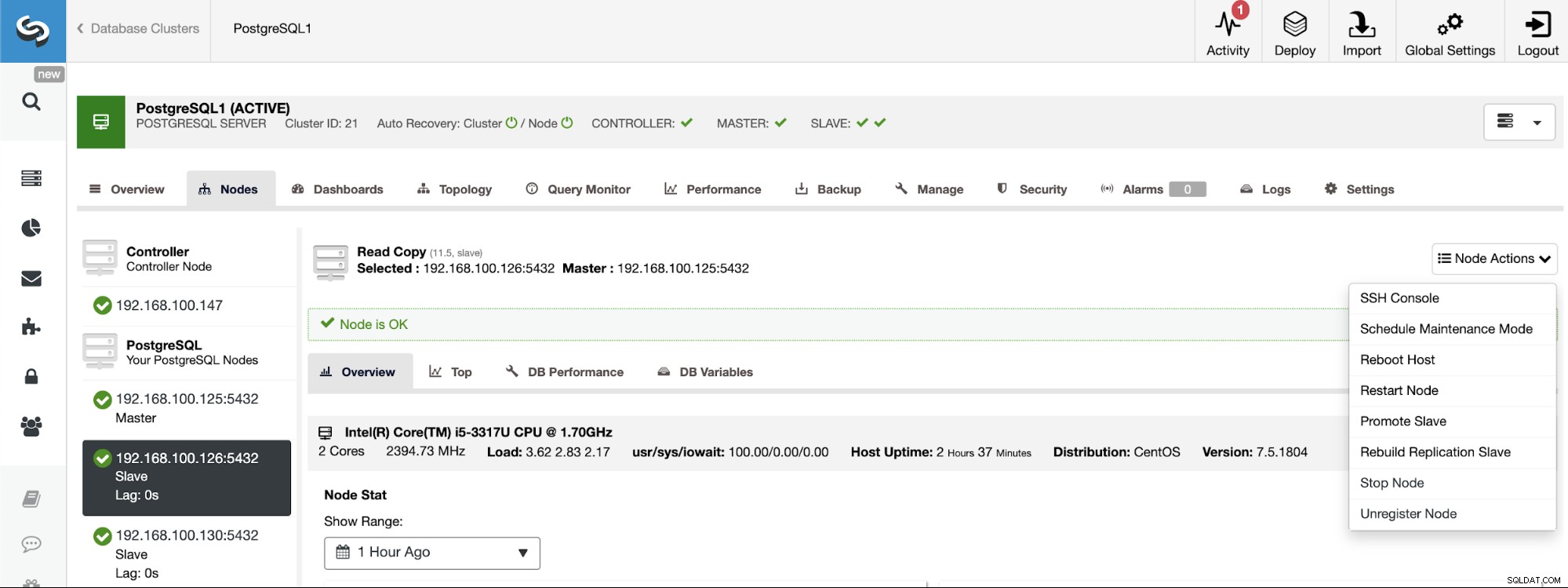
Und schließlich müssen Sie während der Erstellung des Slave-Clusters denselben Administrator verwenden Anmeldeinformationen, die Sie derzeit im Master-Cluster verwenden. Im folgenden Abschnitt erfahren Sie, wo Sie es hinzufügen müssen.
Erstellen des Slave-Clusters über die ClusterControl-Benutzeroberfläche
Um einen neuen Slave-Cluster zu erstellen, gehen Sie zu ClusterControl -> Cluster auswählen -> Cluster-Aktionen -> Slave-Cluster erstellen.
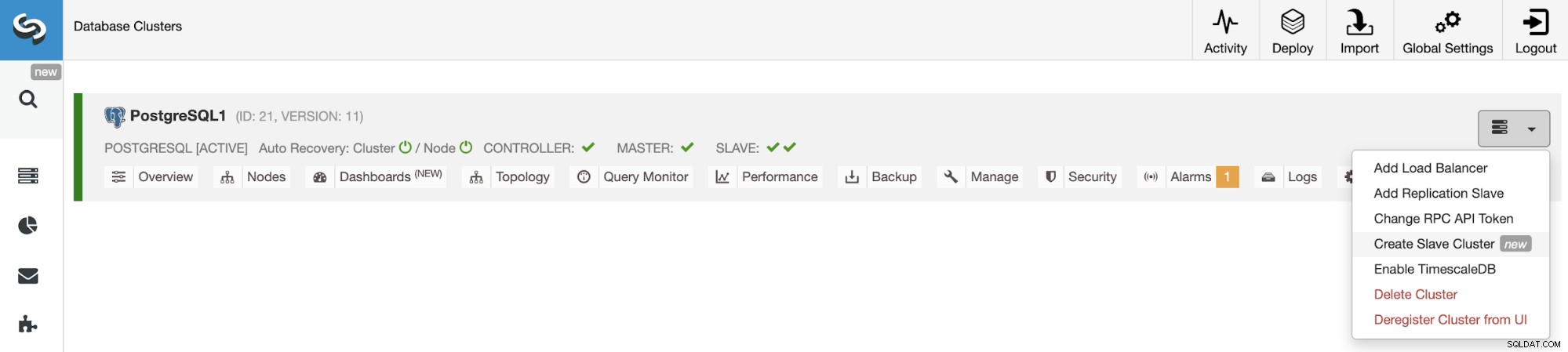
Der Slave-Cluster wird durch Streaming von Daten aus dem aktuellen Master-Cluster erstellt.
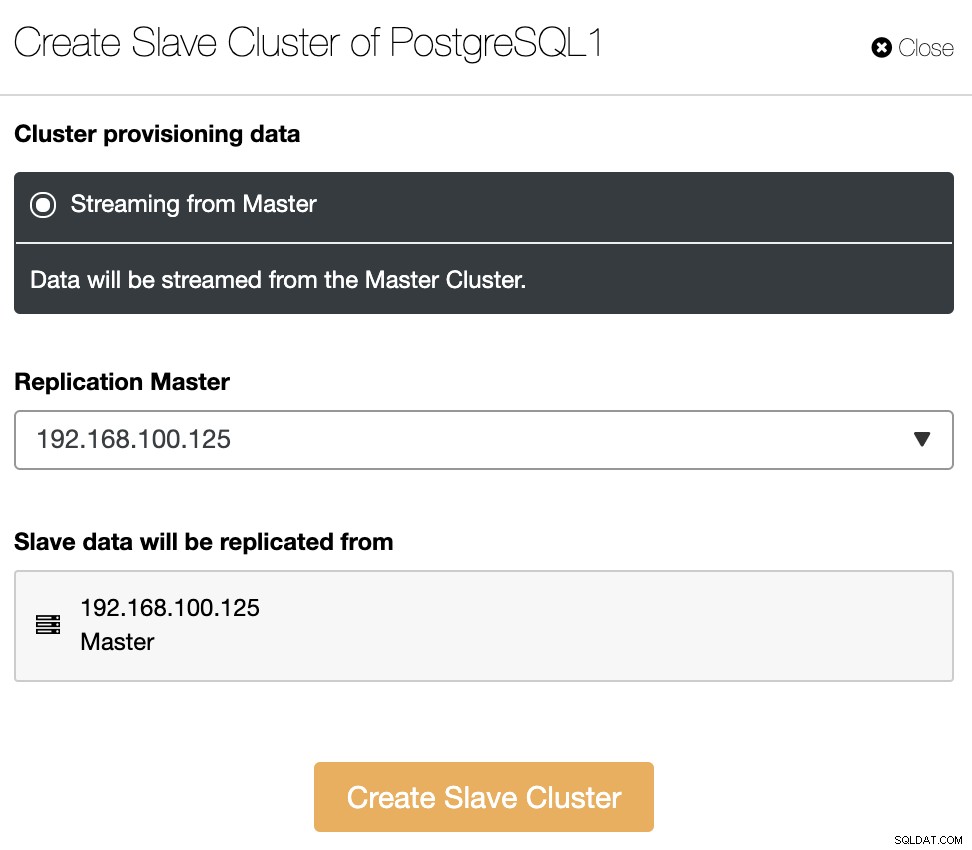
In diesem Abschnitt müssen Sie auch den Master-Knoten des aktuellen Clusters auswählen aus der die Daten repliziert werden.
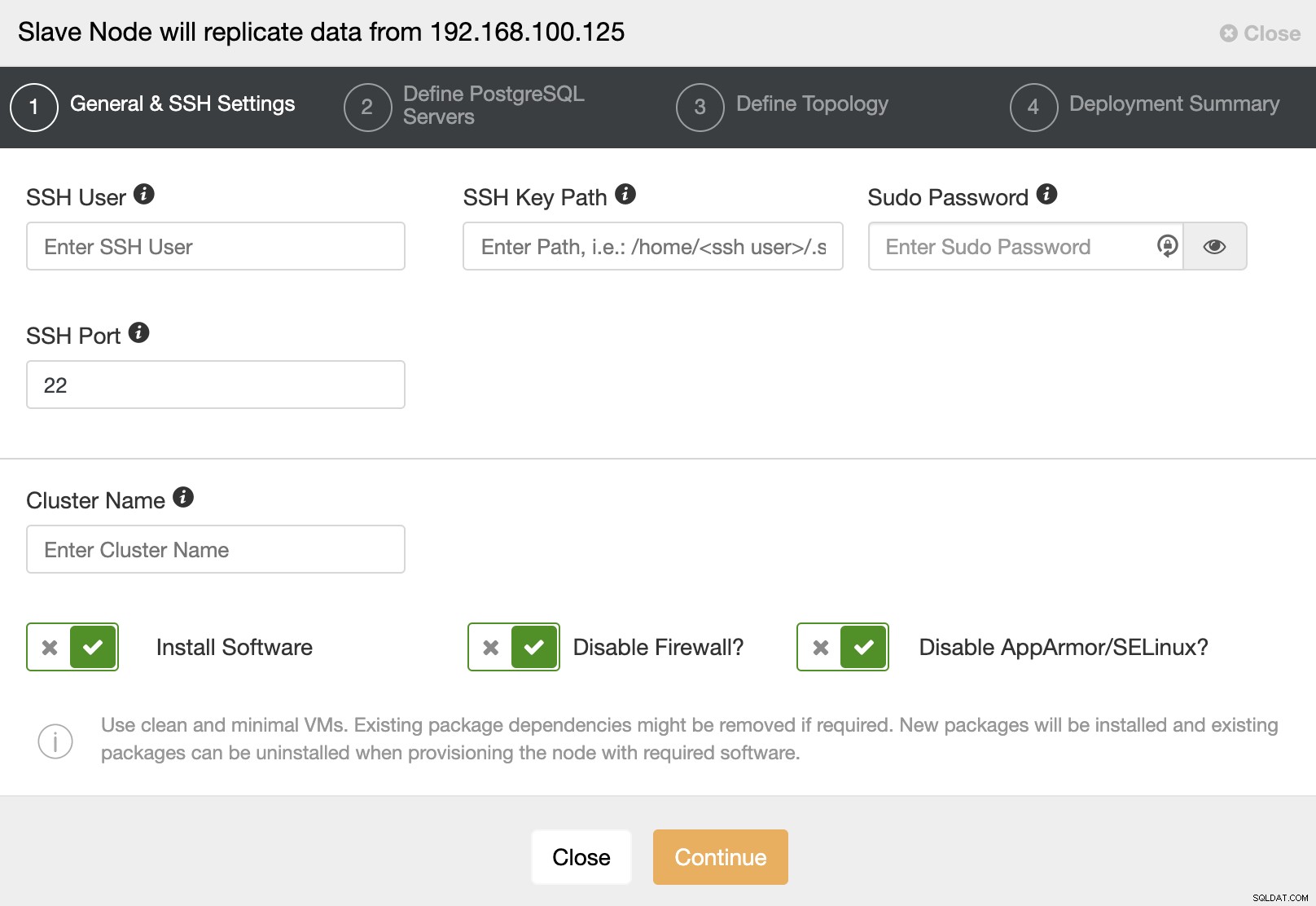
Wenn Sie zum nächsten Schritt gehen, müssen Sie User, Key or angeben Passwort und Port, um sich per SSH mit Ihren Servern zu verbinden. Außerdem benötigen Sie einen Namen für Ihr Slave-Cluster und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
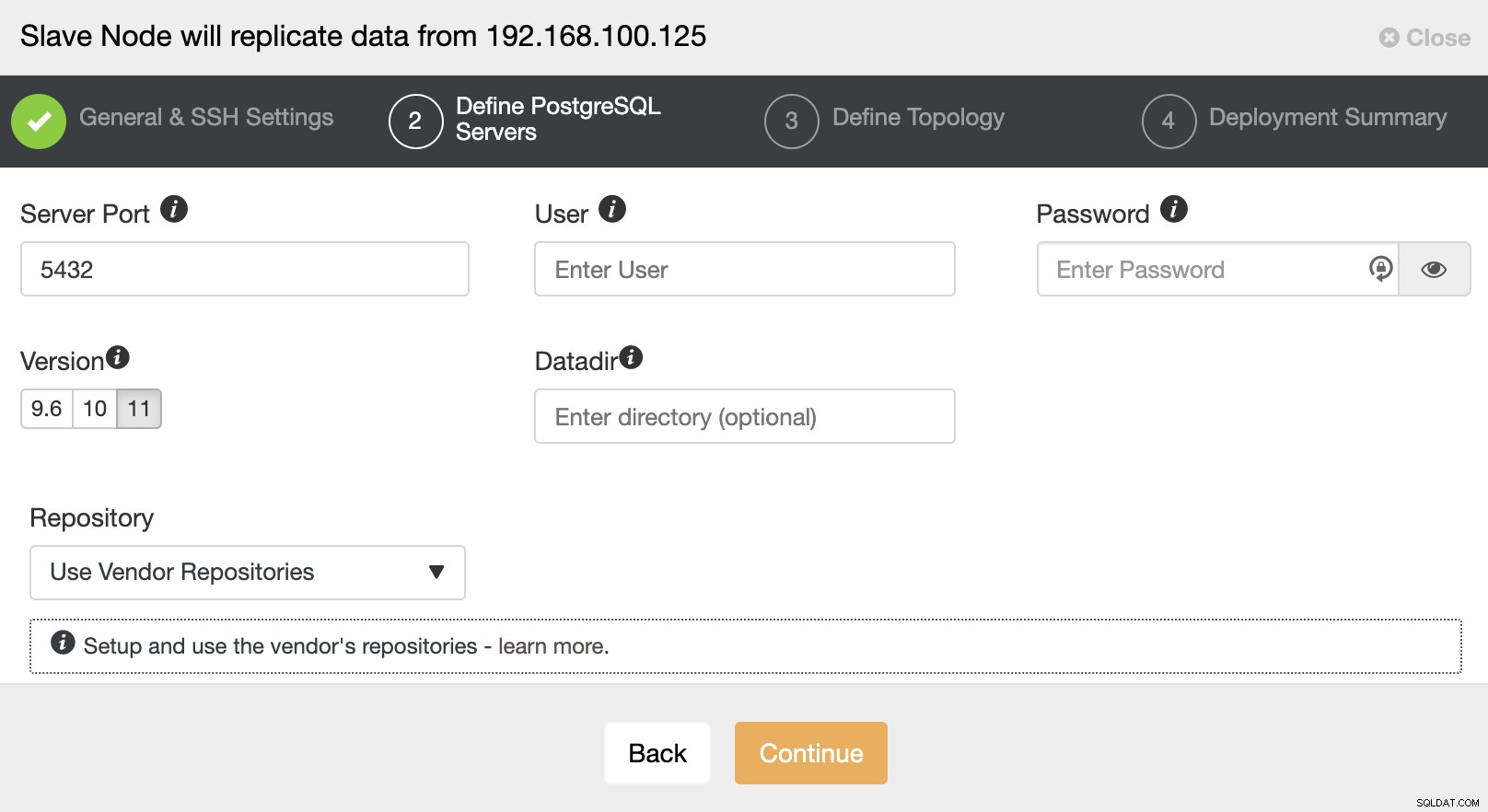
Nachdem Sie die SSH-Zugangsdaten eingerichtet haben, müssen Sie die Datenbankversion definieren, datadir, Port und Admin-Anmeldeinformationen. Da die Streaming-Replikation verwendet wird, stellen Sie sicher, dass Sie dieselbe Datenbankversion verwenden, und wie bereits erwähnt, müssen die Anmeldeinformationen dieselben sein, die vom Master-Cluster verwendet werden. Sie können auch angeben, welches Repository verwendet werden soll.
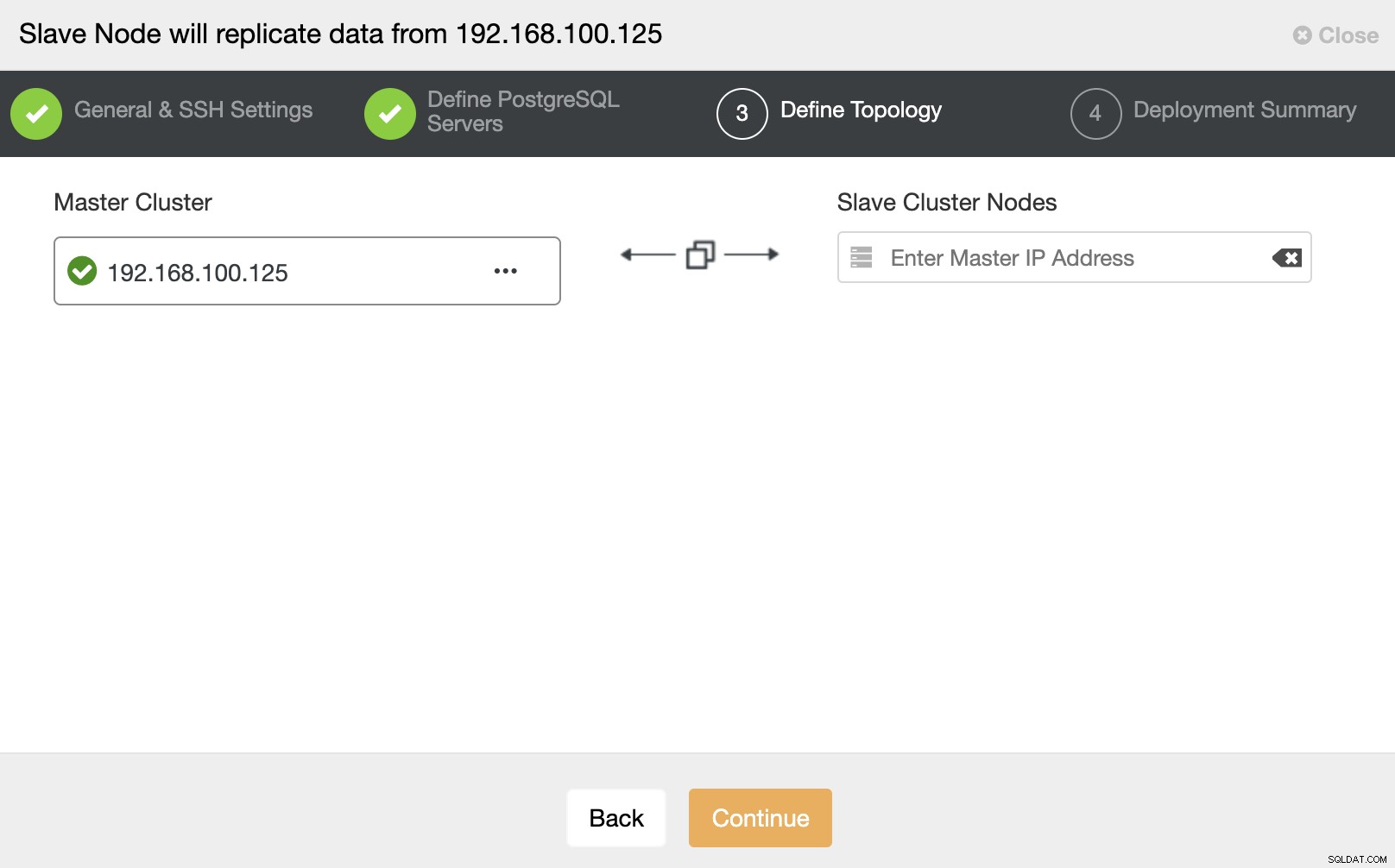
In diesem Schritt müssen Sie den Server zum neuen Slave-Cluster hinzufügen . Für diese Aufgabe können Sie sowohl die IP-Adresse als auch den Hostnamen des Datenbankknotens eingeben.
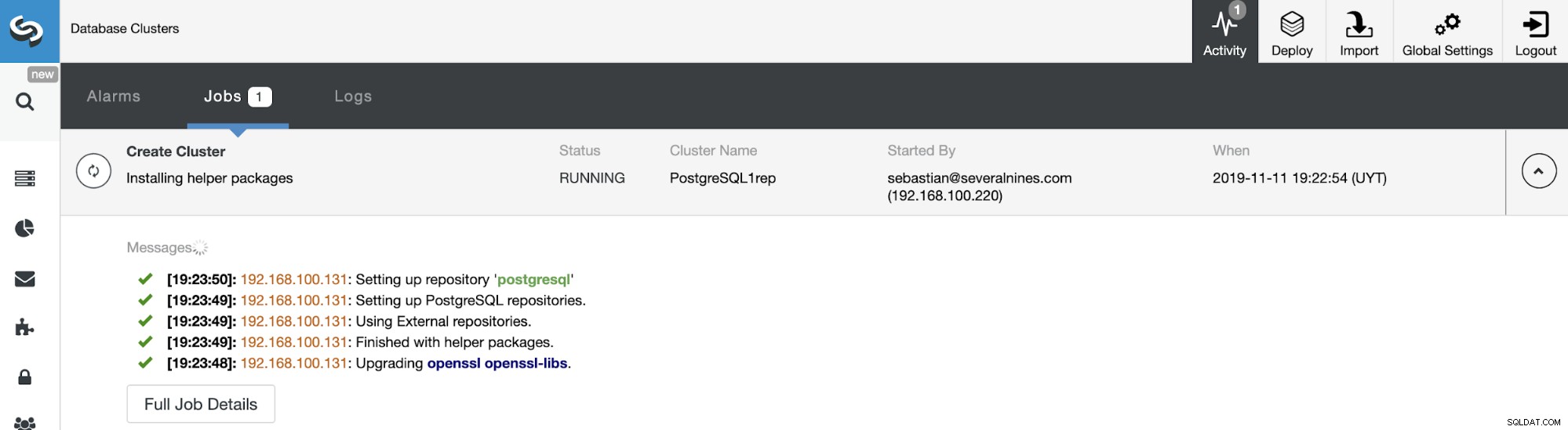
Sie können den Status der Erstellung Ihres neuen Slave-Clusters von überwachen ClusterControl-Aktivitätsmonitor. Sobald die Aufgabe abgeschlossen ist, können Sie den Cluster auf dem Hauptbildschirm von ClusterControl sehen.
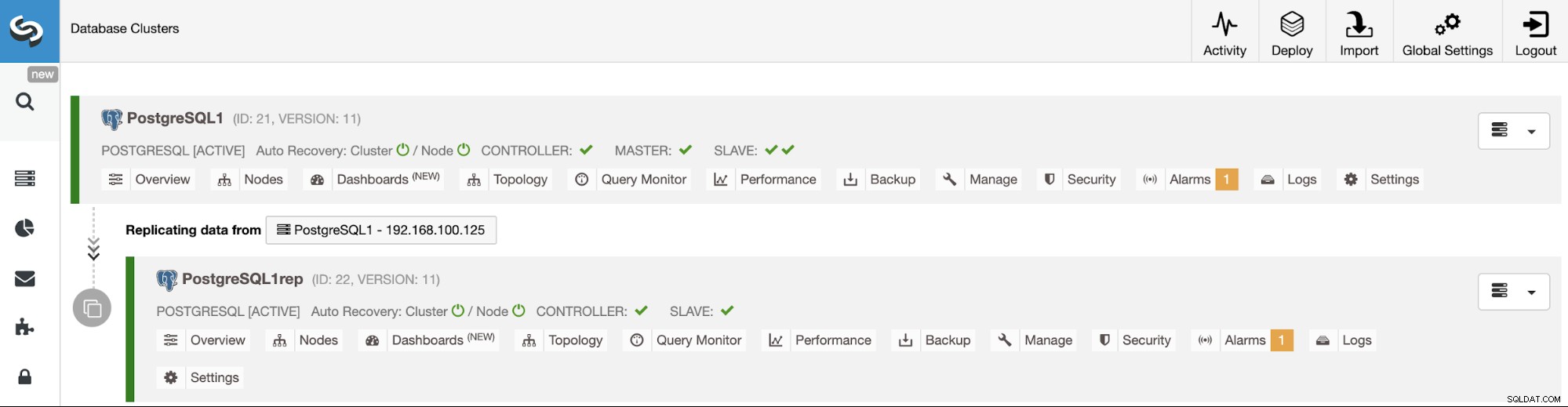
Verwalten der Cluster-zu-Cluster-Replikation mithilfe der ClusterControl-Benutzeroberfläche
Jetzt haben Sie Ihre Cluster-zu-Cluster-Replikation eingerichtet und ausgeführt, es gibt verschiedene Aktionen, die Sie mit ClusterControl für diese Topologie ausführen können.
Neuaufbau eines Slave-Clusters
Um einen Slave-Cluster neu aufzubauen, gehen Sie zu ClusterControl -> Select Slave Cluster -> Nodes -> Choose the Node connected to the Master Cluster -> Node Actions -> Rebuild Replication Slave.
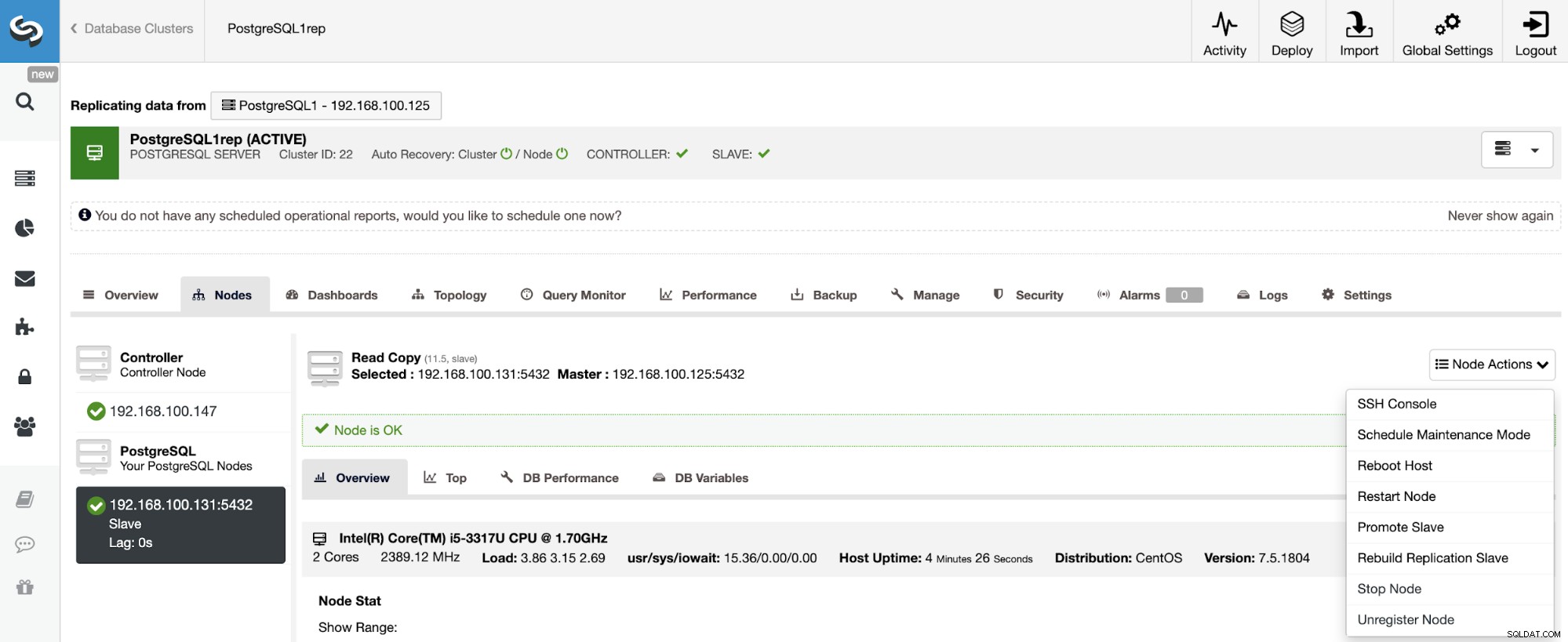
ClusterControl führt die folgenden Schritte aus:
- PostgreSQL-Server stoppen
- Inhalte aus seinem Datenverzeichnis entfernen
- Streamen Sie mit pg_basebackup ein Backup vom Master zum Slave
- Starte den Slave
Replikations-Slave stoppen/starten
Das Anhalten und Starten der Replikation in PostgreSQL bedeutet Anhalten und Fortsetzen, aber wir verwenden diese Begriffe, um mit anderen von uns unterstützten Datenbanktechnologien konsistent zu sein.
Diese Funktion wird in Kürze über die ClusterControl-Benutzeroberfläche verfügbar sein. Diese Aktion verwendet die PostgreSQL-Funktionen pg_wal_replay_pause und pg_wal_replay_resume, um diese Aufgabe auszuführen.
In der Zwischenzeit können Sie einen Workaround verwenden, um den Replikations-Slave zu stoppen und zu starten, indem Sie den Datenbankknoten auf einfache Weise mit ClusterControl stoppen und starten.
Gehe zu ClusterControl -> Select Slave Cluster -> Nodes -> Choose the Knoten -> Knotenaktionen -> Knoten stoppen/Knoten starten. Diese Aktion stoppt/startet den Datenbankdienst direkt.
Cluster-zu-Cluster-Replikation mit der ClusterControl-CLI verwalten
Im vorherigen Abschnitt konnten Sie sehen, wie Sie eine Cluster-zu-Cluster-Replikation mithilfe der ClusterControl-Benutzeroberfläche verwalten. Sehen wir uns nun an, wie Sie dies über die Befehlszeile tun.
Hinweis:Wie bereits zu Beginn dieses Blogs erwähnt, gehen wir davon aus, dass Sie ClusterControl installiert haben und der Master-Cluster damit bereitgestellt wurde.
Erstelle den Slave-Cluster
Sehen wir uns zunächst einen Beispielbefehl zum Erstellen eines Slave-Clusters mithilfe der ClusterControl-CLI an:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logNun haben Sie Ihren Prozess zum Erstellen von Slaves ausgeführt, sehen wir uns jeden verwendeten Parameter an:
- Cluster:Zum Auflisten und Bearbeiten von Clustern.
- Erstellen:Erstellen und installieren Sie einen neuen Cluster.
- Cluster-Name:Der Name des neuen Slave-Clusters.
- Clustertyp:Der Typ des zu installierenden Clusters.
- Provider-Version:Die Software-Version.
- Nodes:Liste der neuen Nodes im Slave-Cluster.
- Os-user:Der Benutzername für die SSH-Befehle.
- Os-key-file:Die Schlüsseldatei, die für die SSH-Verbindung verwendet werden soll.
- Db-admin:Der Benutzername des Datenbankadministrators.
- Db-admin-passwd:Das Passwort für den Datenbankadministrator.
- Remote-cluster-id:Master-Cluster-ID für die Cluster-zu-Cluster-Replikation.
- Log:Jobmeldungen abwarten und überwachen.
Mit dem Flag --log können Sie die Protokolle in Echtzeit sehen:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Neuaufbau eines Slave-Clusters
Sie können einen Slave-Cluster mit dem folgenden Befehl neu aufbauen:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logDie Parameter sind:
- Replikation:Zur Überwachung und Steuerung der Datenreplikation.
- Stufe:Stufe/Wiederaufbau eines Replikations-Slaves.
- Master:Der Replikations-Master im Master-Cluster.
- Slave:Der Replikations-Slave im Slave-Cluster.
- Cluster-id:Die Slave-Cluster-ID.
- Remote-cluster-id:Die Master-Cluster-ID.
- Log:Jobmeldungen abwarten und überwachen.
Das Auftragsprotokoll sollte diesem ähneln:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Replikations-Slave stoppen/starten
Wie wir im Abschnitt zur Benutzeroberfläche erwähnt haben, bedeutet das Stoppen und Starten der Replikation in PostgreSQL, sie anzuhalten und fortzusetzen, aber wir verwenden diese Begriffe, um die Parallelität mit anderen Technologien aufrechtzuerhalten.
Sie können die Replikation der Daten vom Master-Cluster auf diese Weise stoppen:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logSie werden Folgendes sehen:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().Und jetzt können Sie es erneut starten:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logSie werden also sehen:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Nun überprüfen wir die verwendeten Parameter.
- Replikation:Zur Überwachung und Steuerung der Datenreplikation.
- Stop/Start:Damit der Slave die Replikation stoppt/startet.
- Slave:Der Replikations-Slave-Knoten.
- Cluster-id:Die ID des Clusters, in dem sich der Slave-Knoten befindet.
- Log:Jobmeldungen abwarten und überwachen.
Fazit
Mit dieser neuen ClusterControl-Funktion können Sie die Replikation zwischen verschiedenen PostgreSQL-Clustern schnell einrichten und die Einrichtung auf einfache und benutzerfreundliche Weise verwalten. Das Entwicklerteam von Multiplenines arbeitet an der Verbesserung dieser Funktion, daher sind Ideen oder Vorschläge sehr willkommen.