Alle modernen Datenbanksysteme unterstützen ein Abfrageoptimierungsmodul, um automatisch die effizienteste Strategie zur Ausführung der SQL-Abfragen zu identifizieren. Die effiziente Strategie heißt „Plan“ und wird anhand der Kosten gemessen, die direkt proportional zur „Query Execution/Response Time“ sind. Der Plan wird in Form einer Baumausgabe des Abfrageoptimierers dargestellt. Die Planbaumknoten können hauptsächlich in die folgenden 3 Kategorien unterteilt werden:
- Knoten scannen :Wie in meinem vorherigen Blog „Ein Überblick über die verschiedenen Scan-Methoden in PostgreSQL“ erklärt, gibt es an, wie die Daten einer Basistabelle abgerufen werden müssen.
- Knoten beitreten :Wie in meinem vorherigen Blog „An Overview of the JOIN Methods in PostgreSQL“ erklärt, gibt es an, wie zwei Tabellen miteinander verbunden werden müssen, um das Ergebnis von zwei Tabellen zu erhalten.
- Materialisierungsknoten :Auch Hilfsknoten genannt. Die beiden vorherigen Arten von Knoten betrafen das Abrufen von Daten aus einer Basistabelle und das Verbinden von Daten, die aus zwei Tabellen abgerufen wurden. Die Knoten in dieser Kategorie werden auf die abgerufenen Daten angewendet, um weitere Analysen oder Berichte usw. vorzubereiten, z. Sortieren der Daten, Aggregation von Daten usw.
Betrachten Sie ein einfaches Abfragebeispiel wie...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Nehmen Sie an, dass ein Plan generiert wird, der der folgenden Abfrage entspricht:
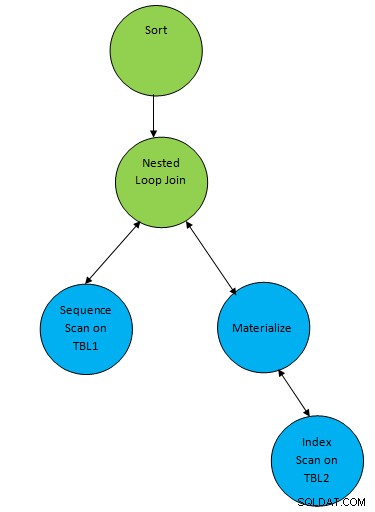
Hier wird dem Ergebnis also ein Hilfsknoten „Sortieren“ hinzugefügt von join, um die Daten in der gewünschten Reihenfolge zu sortieren.
Einige der vom PostgreSQL-Abfrageoptimierer generierten Hilfsknoten lauten wie folgt:
- Sortieren
- Aggregat
- Gruppieren nach Aggregat
- Beschränkung
- Einzigartig
- LockRows
- SetOp
Lassen Sie uns jeden dieser Knoten verstehen.
Sortieren
Wie der Name schon sagt, wird dieser Knoten als Teil eines Planbaums hinzugefügt, wenn sortierte Daten benötigt werden. Sortierte Daten können explizit oder implizit wie in den folgenden zwei Fällen erforderlich sein:
Das Benutzerszenario erfordert sortierte Daten als Ausgabe. In diesem Fall kann der Sortierknoten über dem gesamten Datenabruf liegen, einschließlich aller anderen Verarbeitungen.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Hinweis: Obwohl der Benutzer die endgültige Ausgabe in sortierter Reihenfolge benötigt, wird der Sortierknoten möglicherweise nicht im endgültigen Plan hinzugefügt, wenn es einen Index für die entsprechende Tabelle und Sortierspalte gibt. In diesem Fall kann es einen Index-Scan wählen, der zu einer implizit sortierten Reihenfolge der Daten führt. Lassen Sie uns beispielsweise einen Index für das obige Beispiel erstellen und das Ergebnis anzeigen:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Wie in meinem vorherigen Blog Überblick über die JOIN-Methoden in PostgreSQL erläutert, erfordert Merge Join, dass beide Tabellendaten vor dem Verbinden sortiert werden. So kann es vorkommen, dass sich Merge Join als billiger herausstellt als jede andere Join-Methode, sogar mit zusätzlichen Kosten für das Sortieren. In diesem Fall wird also zwischen Join- und Scan-Methode der Tabelle ein Sort-Knoten eingefügt, damit sortierte Datensätze an die Join-Methode übergeben werden können.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Aggregat
Aggregatknoten werden als Teil einer Planstruktur hinzugefügt, wenn eine Aggregatfunktion zur Berechnung einzelner Ergebnisse aus mehreren Eingabezeilen verwendet wird. Einige der verwendeten Aggregatfunktionen sind COUNT, SUM, AVG (AVERAGE), MAX (MAXIMUM) und MIN (MINIMUM).
Ein aggregierter Knoten kann über einem Basisbeziehungs-Scan oder (und) einer Verknüpfung von Beziehungen liegen. Beispiel:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)HashAggregate / GroupAggregate
Diese Arten von Knoten sind Erweiterungen des „Aggregate“-Knotens. Wenn Aggregatfunktionen verwendet werden, um mehrere Eingabezeilen gemäß ihrer Gruppe zu kombinieren, werden diese Arten von Knoten einem Planbaum hinzugefügt. Wenn also für die Abfrage eine Aggregatfunktion verwendet wird und zusammen mit dieser eine GROUP BY-Klausel in der Abfrage vorhanden ist, wird der Planstruktur entweder ein HashAggregate- oder ein GroupAggregate-Knoten hinzugefügt.
Da PostgreSQL den Cost Based Optimizer verwendet, um einen optimalen Planbaum zu generieren, ist es fast unmöglich zu erraten, welcher dieser Knoten verwendet wird. Aber lassen Sie uns verstehen, wann und wie es verwendet wird.
Hashaggregat
HashAggregate baut die Hash-Tabelle der Daten auf, um sie zu gruppieren. Daher kann HashAggregate vom Aggregat auf Gruppenebene verwendet werden, wenn das Aggregat auf einem unsortierten Datensatz erfolgt.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Hier entsprechen die Schemadaten der Tabelle demo1 dem im vorherigen Abschnitt gezeigten Beispiel. Da nur 1000 Zeilen zu gruppieren sind, ist die zum Erstellen einer Hash-Tabelle erforderliche Ressource geringer als die Kosten für das Sortieren. Der Abfrageplaner entscheidet sich für HashAggregate.
Gruppenaggregat
GroupAggregate arbeitet mit sortierten Daten, sodass keine zusätzliche Datenstruktur erforderlich ist. GroupAggregate kann von einem Aggregat auf Gruppenebene verwendet werden, wenn sich die Aggregation auf einem sortierten Datensatz befindet. Um nach sortierten Daten zu gruppieren, kann es entweder explizit sortieren (durch Hinzufügen des Sort-Knotens) oder es kann mit Daten arbeiten, die vom Index abgerufen werden. In diesem Fall werden sie implizit sortiert.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Hier sind die Schemadaten der demo2-Tabelle wie in dem im vorherigen Abschnitt gezeigten Beispiel. Da hier 100.000 Zeilen zu gruppieren sind, kann die zum Erstellen der Hash-Tabelle erforderliche Ressource teurer sein als die Kosten für das Sortieren. Der Abfrageplaner entscheidet sich also für GroupAggregate. Beachten Sie hier, dass die aus der Tabelle „demo2“ ausgewählten Datensätze explizit sortiert sind und für die ein Knoten in der Planstruktur hinzugefügt wurde.
Siehe unten ein weiteres Beispiel, wo bereits Daten aufgrund des Index-Scans sortiert abgerufen werden:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Siehe unten ein weiteres Beispiel, das zwar einen Index-Scan hat, aber dennoch explizit sortieren muss, da die Spalte, in der der Index dort und die Gruppierungsspalte nicht identisch sind. Es muss also immer noch nach der Gruppierungsspalte sortiert werden.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Hinweis: GroupAggregate/HashAggregate kann für viele andere indirekte Abfragen verwendet werden, obwohl die Aggregation mit group by in der Abfrage nicht vorhanden ist. Es hängt davon ab, wie der Planer die Abfrage interpretiert. Z.B. Angenommen, wir müssen einen eindeutigen Wert aus der Tabelle erhalten, dann kann sie von der entsprechenden Spalte als Gruppe gesehen werden und dann einen Wert aus jeder Gruppe nehmen.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Hier wird also HashAggregate verwendet, obwohl es keine Aggregation und Gruppierung gibt.
Grenze
Limit-Knoten werden der Planstruktur hinzugefügt, wenn die „limit/offset“-Klausel in der SELECT-Abfrage verwendet wird. Diese Klausel wird verwendet, um die Anzahl der Zeilen zu begrenzen und optional einen Offset bereitzustellen, um mit dem Lesen von Daten zu beginnen. Beispiel unten:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Einzigartig
Dieser Knoten wird ausgewählt, um einen eindeutigen Wert aus dem zugrunde liegenden Ergebnis zu erhalten. Beachten Sie, dass je nach Abfrage, Selektivität und anderen Ressourceninformationen der eindeutige Wert mit HashAggregate/GroupAggregate auch ohne Verwendung des Unique-Knotens abgerufen werden kann. Beispiel:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)LockRows
PostgreSQL bietet Funktionen zum Sperren aller ausgewählten Zeilen. Zeilen können je nach „FOR SHARE“- bzw. „FOR UPDATE“-Klausel in einem „Shared“- oder „Exclusive“-Modus ausgewählt werden. Ein neuer Knoten „LockRows“ wird zum Planbaum hinzugefügt, um diese Operation auszuführen.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)SetOp
PostgreSQL bietet Funktionen zum Kombinieren der Ergebnisse von zwei oder mehr Abfragen. Wenn also der Typ des Join-Knotens ausgewählt wird, um zwei Tabellen zu verknüpfen, wird ein ähnlicher Typ des SetOp-Knotens ausgewählt, um die Ergebnisse von zwei oder mehr Abfragen zu kombinieren. Betrachten Sie beispielsweise eine Tabelle mit Mitarbeitern mit ihrer ID, ihrem Namen, ihrem Alter und ihrem Gehalt wie unten:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Nun nehmen wir Mitarbeiter mit einem Alter von mehr als 25 Jahren:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Lassen Sie uns jetzt Mitarbeiter mit einem Gehalt von mehr als 95 Millionen bekommen:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Um nun Mitarbeiter mit einem Alter von mehr als 25 Jahren und einem Gehalt von mehr als 95 Mio. zu bekommen, können wir unten eine Schnittabfrage schreiben:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Hier wird also eine neue Art von Knoten HashSetOp hinzugefügt, um die Schnittmenge dieser beiden einzelnen Abfragen auszuwerten.
Beachten Sie, dass hier zwei weitere Arten von neuen Knoten hinzugefügt wurden:
Anhängen
Dieser Knoten wird hinzugefügt, um mehrere Ergebnismengen zu einer zu kombinieren.
Unterabfrage-Scan
Dieser Knoten wird hinzugefügt, um jede Unterabfrage auszuwerten. Im obigen Plan wird die Unterabfrage hinzugefügt, um einen zusätzlichen konstanten Spaltenwert auszuwerten, der angibt, welcher Eingabesatz zu einer bestimmten Zeile beigetragen hat.
HashedSetop arbeitet mit dem Hash des zugrunde liegenden Ergebnisses, aber es ist möglich, eine auf Sortierung basierende SetOp-Operation durch den Abfrageoptimierer zu generieren. Sortierbasierte Setop-Knoten werden als „Setop“ bezeichnet.
Hinweis:Es ist möglich, das gleiche Ergebnis wie im obigen Ergebnis mit einer einzigen Abfrage zu erzielen, aber hier wird es nur zur einfachen Demonstration mit intersect gezeigt.
Fazit
Alle Knoten von PostgreSQL sind nützlich und werden basierend auf der Art der Abfrage, der Daten usw. ausgewählt. Viele der Klauseln werden eins zu eins mit Knoten abgebildet. Für einige Klauseln gibt es mehrere Optionen für Knoten, die basierend auf den zugrunde liegenden Datenkostenberechnungen entschieden werden.