Im vorigen Blogbeitrag habe ich kurz erklärt, wie wir zu den in der pglogical-Ankündigung veröffentlichten Leistungszahlen gekommen sind. In diesem Blogbeitrag möchte ich die Leistungsgrenzen logischer Replikationslösungen im Allgemeinen erörtern und auch, wie sie sich auf pglogical beziehen.
Physische Replikation
Sehen wir uns zunächst an, wie die physische Replikation (seit Version 9.0 in PostgreSQL integriert) funktioniert. Eine etwas vereinfachte Abbildung des mit zwei nur zwei Knoten sieht so aus:
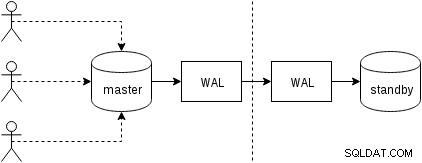
Clients führen Abfragen auf dem Master-Knoten aus, die Änderungen werden in ein Transaktionsprotokoll (WAL) geschrieben und über das Netzwerk in WAL auf dem Standby-Knoten kopiert. Die Wiederherstellung auf dem Standby-Prozess auf dem Standby liest dann die Änderungen von WAL und wendet sie auf die Datendateien an, genau wie während der Wiederherstellung. Wenn sich der Standby im „hot_standby“-Modus befindet, können Clients währenddessen schreibgeschützte Abfragen auf dem Knoten ausgeben.
Dies ist sehr effizient, da nur sehr wenig zusätzliche Verarbeitung erforderlich ist – Änderungen werden übertragen und als undurchsichtiger binärer Blob in den Standby geschrieben. Natürlich ist die Wiederherstellung nicht kostenlos (sowohl in Bezug auf CPU als auch E/A), aber es ist schwierig, effizienter zu werden.
Die offensichtlichen potenziellen Engpässe bei der physischen Replikation sind die Netzwerkbandbreite (Übertragung der WAL vom Master zum Standby) und auch die I/O auf dem Standby, die durch den Wiederherstellungsprozess gesättigt sein können, der oft viele zufällige I/O-Anforderungen ausgibt ( in manchen Fällen mehr als der Meister, aber darauf gehen wir nicht ein).
logische Replikation
Die logische Replikation ist etwas komplizierter, da es sich nicht um einen undurchsichtigen binären WAL-Stream handelt, sondern um einen Stream „logischer“ Änderungen (stellen Sie sich INSERT-, UPDATE- oder DELETE-Anweisungen vor, obwohl das nicht ganz korrekt ist, da wir es mit einer strukturierten Darstellung von zu tun haben die Daten). Durch die logischen Änderungen können interessante Dinge wie Konfliktlösung, Replikation nur ausgewählter Tabellen, in ein anderes Schema oder zwischen verschiedenen Versionen (oder sogar verschiedenen Datenbanken) durchgeführt werden.
Es gibt verschiedene Möglichkeiten, die Änderungen abzurufen – der traditionelle Ansatz besteht darin, Trigger zu verwenden, die die Änderungen in einer Tabelle aufzeichnen, und einen benutzerdefinierten Prozess diese Änderungen kontinuierlich lesen und sie durch Ausführen von SQL-Abfragen auf den Standby-Server anwenden zu lassen. Und all dies wird von einem externen Daemon-Prozess (oder möglicherweise mehreren Prozessen, die auf beiden Knoten laufen) gesteuert, wie in der nächsten Abbildung dargestellt

Das ist es, was slony oder londiste tun, und obwohl es ziemlich gut funktioniert hat, bedeutet es viel Overhead – zum Beispiel müssen die Datenänderungen erfasst und die Daten mehrmals geschrieben werden (in die ursprüngliche Tabelle und in eine „Protokoll“-Tabelle und auch an WAL für diese beiden Tabellen). Wir werden später auf andere Quellen von Overhead eingehen. Während pglogical die gleichen Ziele erreichen muss, erreicht es sie anders, dank mehrerer Funktionen, die den neueren PostgreSQL-Versionen hinzugefügt wurden (daher nicht verfügbar, als die anderen Tools implementiert wurden):

Das heißt, anstatt ein separates Änderungsprotokoll zu führen, verlässt sich pglogical auf WAL – dies ist dank einer in PostgreSQL 9.4 verfügbaren logischen Dekodierung möglich, die es ermöglicht, logische Änderungen aus dem WAL-Protokoll zu extrahieren. Dank dessen benötigt pglogical keine teuren Trigger und kann in der Regel vermeiden, die Daten zweimal auf den Master zu schreiben (außer bei großen Transaktionen, die möglicherweise auf die Festplatte überlaufen).
Nach dem Decodieren jeder Transaktion wird sie an die Standby-Datenbank übertragen, und der Apply-Prozess wendet ihre Änderungen auf die Standby-Datenbank an. pglogical wendet die Änderungen nicht an, indem es reguläre SQL-Abfragen ausführt, sondern auf einer niedrigeren Ebene und umgeht den Overhead, der mit dem Analysieren und Planen von SQL-Abfragen verbunden ist. Dies verschafft pglogical einen erheblichen Vorteil gegenüber den bestehenden Lösungen, die alle durch die SQL-Schicht gehen (wodurch das Parsing und die Planung bezahlt werden).
potenzielle Engpässe
Natürlich ist die logische Replikation anfällig für die gleichen Engpässe wie die physische Replikation, d. h. es ist möglich, das Netzwerk zu sättigen, wenn die Änderungen übertragen werden, und E/A auf dem Standby, wenn sie auf das Standby angewendet werden. Es gibt auch eine Menge Overhead aufgrund zusätzlicher Schritte, die bei einer physischen Replikation nicht vorhanden sind.
Wir müssen die logischen Änderungen irgendwie erfassen, während die physische Replikation die WAL einfach als Bytestrom weiterleitet. Wie bereits erwähnt, verlassen sich bestehende Lösungen in der Regel darauf, dass Trigger die Änderungen in eine „Log“-Tabelle schreiben. pglogical stützt sich stattdessen auf das Write-Ahead-Protokoll (WAL) und die logische Dekodierung, um dasselbe zu erreichen, was billiger als Trigger ist und die Daten in den meisten Fällen auch nicht zweimal schreiben muss (mit dem zusätzlichen Bonus, dass wir die Änderungen automatisch anwenden). in Commit-Reihenfolge).
Das heißt nicht, dass es keine Möglichkeiten für zusätzliche Verbesserungen gibt – zum Beispiel erfolgt die Dekodierung derzeit nur, wenn die Transaktion festgeschrieben wird, sodass dies bei großen Transaktionen die Replikationsverzögerung erhöhen kann. Die physische Replikation streamt einfach die WAL-Änderungen an den anderen Knoten und hat daher diese Einschränkung nicht. Große Transaktionen können auch auf die Festplatte überlaufen und doppelte Schreibvorgänge verursachen, da der Upstream sie speichern muss, bis sie festgeschrieben werden und sie an den Downstream gesendet werden können.
Zukünftige Arbeiten sind geplant, um es pglogical zu ermöglichen, große Transaktionen zu streamen, während sie noch im Upstream ausgeführt werden, wodurch die Latenz zwischen Upstream-Commit und Downstream-Commit und die Upstream-Write-Amplifikation reduziert werden.
Nachdem die Änderungen in den Standby-Modus übertragen wurden, muss der Apply-Prozess sie tatsächlich irgendwie anwenden. Wie im vorherigen Abschnitt erwähnt, haben die bestehenden Lösungen dies getan, indem sie SQL-Befehle konstruiert und ausgeführt haben, während pglogical die SQL-Schicht und den damit verbundenen Overhead vollständig umgeht.
Dies macht die Anwendung jedoch nicht völlig kostenlos, da sie immer noch Dinge wie Primärschlüsselsuchen, Aktualisieren von Indizes, Ausführen von Triggern und verschiedene andere Überprüfungen durchführen muss. Aber es ist deutlich billiger als der SQL-basierte Ansatz. In gewisser Weise funktioniert es ähnlich wie COPY und ist besonders schnell auf einfachen Tabellen ohne Trigger, Fremdschlüssel usw.
Bei allen logischen Replikationslösungen findet jeder dieser Schritte (Decodieren und Anwenden) in einem einzigen Prozess statt, sodass die CPU-Zeit ziemlich begrenzt ist. Dies ist wahrscheinlich der dringendste Engpass bei allen vorhandenen Lösungen, da Sie möglicherweise eine ziemlich kräftige Maschine mit Dutzenden oder sogar Hunderten von Clients haben, die parallel Abfragen ausführen, aber all dies muss einen einzigen Prozess durchlaufen, der diese Änderungen dekodiert (auf der master) und einen Prozess, der diese Änderungen anwendet (im Standby).
Die Beschränkung auf einen "einzelnen Prozess" kann etwas gelockert werden, indem separate Datenbanken verwendet werden, da jede Datenbank von einem separaten Prozess behandelt wird. Wenn es um eine einzelne Datenbank geht, ist geplant, die Anwendung in Zukunft über einen Pool von Hintergrundarbeitern zu parallelisieren, um diesen Engpass zu beseitigen.