Im Gegensatz zu anderen Datenbankverwaltungssystemen, die ihren eigenen integrierten Scheduler haben (wie Oracle, MSSQL oder MySQL), hat PostgreSQL diese Art von Funktion immer noch nicht.
Um Planungsfunktionen in PostgreSQL bereitzustellen, müssen Sie ein externes Tool wie ... verwenden
- Linux-Crontab
- Agent pgAgent
- Erweiterung pg_cron
In diesem Blog werden wir diese Tools untersuchen und ihre Bedienung und ihre Hauptfunktionen hervorheben.
Linux-Crontab
Es ist das älteste, jedoch ein effizienter und nützlicher Weg, um Planungsaufgaben auszuführen. Dieses Programm basiert auf einem Daemon (cron), der es ermöglicht, dass Aufgaben regelmäßig automatisch im Hintergrund ausgeführt werden, und überprüft regelmäßig die Konfigurationsdateien (Crontab-Dateien genannt), in denen das auszuführende Skript/der Befehl und seine Zeitplanung definiert sind.
Jeder Benutzer kann seine eigene crontab-Datei haben und die neuesten Ubuntu-Versionen befinden sich in:
/var/spool/cron/crontabs (for other linux distributions the location could be different):
example@sqldat.com:/var/spool/cron/crontabs# ls -ltr
total 12
-rw------- 1 dbmaster crontab 1128 Jan 12 12:18 dbmaster
-rw------- 1 slonik crontab 1126 Jan 12 12:22 slonik
-rw------- 1 nines crontab 1125 Jan 12 12:23 ninesDie Syntax der Konfigurationsdatei ist folgende:
mm hh dd mm day <<command or script to execute>>
mm: Minute(0-59)
hh: Hour(0-23)
dd: Day(1-31)
mm: Month(1-12)
day: Day of the week(0-7 [7 or 0 == Sunday])Einige Operatoren könnten mit dieser Syntax verwendet werden, um die Planungsdefinition zu rationalisieren, und diese Symbole ermöglichen die Angabe mehrerer Werte in einem Feld:
Sternchen (*) - bedeutet alle möglichen Werte für ein Feld
Das Komma (,) - wird verwendet, um eine Werteliste zu definieren
Bindestrich (-) - wird verwendet, um einen Wertebereich zu definieren
Trennzeichen (/) - gibt einen Schrittwert an
Das Skript all_db_backup.sh wird entsprechend jedem Scheduling-Ausdruck ausgeführt:
| 0 6 * * * /home/backup/all_db_backup.sh | Jeden Tag um 6 Uhr |
| 20 22 * * Mo, Di, Mi, Do, Fr /home/backup/all_db_backup.sh | Um 22:20 Uhr, jeden Wochentag |
| 0 23 * * 1-5 /home/backup/all_db_backup.sh | Unter der Woche um 23 Uhr |
| 0 0/5 14 * * /home/backup/all_db_backup.sh | Alle fünf Stunden ab 14:00 Uhr und endet jeden Tag um 14:55 Uhr |
Wenn die crontab-Datei für einen Benutzer nicht existiert, kann sie mit dem folgenden Befehl erstellt werden:
example@sqldat.com:~$ crontab -eoder mit dem Parameter -l präsentiert:
example@sqldat.com:~$ crontab -lWenn es notwendig ist, diese Datei zu entfernen, ist der entsprechende Parameter -r:
example@sqldat.com:~$ crontab -rDer Cron-Daemon-Status wird durch die Ausführung des folgenden Befehls angezeigt:
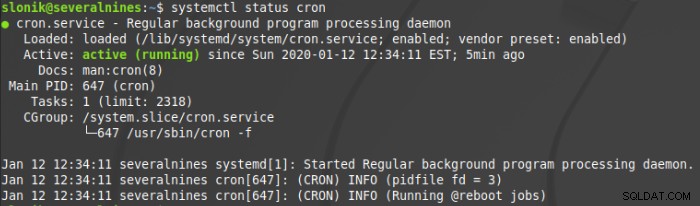
Agent pgAgent
Der pgAgent ist ein für PostgreSQL verfügbarer Job-Scheduling-Agent, der die Ausführung von gespeicherten Prozeduren, SQL-Anweisungen und Shell-Skripten ermöglicht. Seine Konfiguration wird in der Postgres-Datenbank im Cluster gespeichert.
Der Zweck besteht darin, dass dieser Agent als Daemon auf Linux-Systemen läuft und regelmäßig eine Verbindung zur Datenbank herstellt, um zu prüfen, ob Jobs ausgeführt werden müssen.
Diese Planung wird einfach von PgAdmin 4 verwaltet, aber sie wird nicht standardmäßig installiert, sobald pgAdmin installiert ist, es ist notwendig, sie selbst herunterzuladen und zu installieren.
Im Folgenden werden alle notwendigen Schritte beschrieben, damit der pgAgent ordnungsgemäß funktioniert:
Schritt Eins
Installation von pgAdmin 4
$ sudo apt install pgadmin4 pgadmin4-apacheSchritt Zwei
Erstellung der prozeduralen Sprache plpgsql, falls nicht definiert
CREATE TRUSTED PROCEDURAL LANGUAGE ‘plpgsql’
HANDLER plpgsql_call_handler
HANDLER plpgsql_validator;Schritt Drei
Installation von pgAgent
$ sudo apt-get install pgagentSchritt Vier
Erstellung der pgagent-Erweiterung
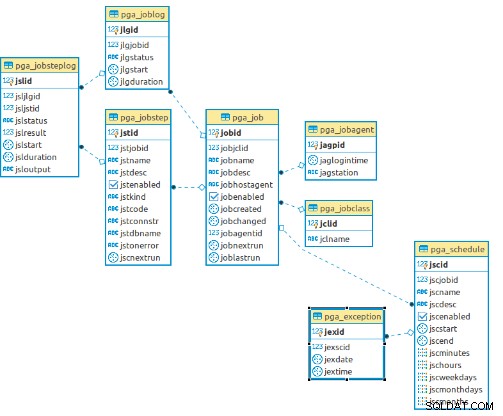
CREATE EXTENSION pageant Diese Erweiterung erstellt alle Tabellen und Funktionen für die pgAgent-Operation und im Folgenden wird das von dieser Erweiterung verwendete Datenmodell gezeigt:
Nun verfügt die pgAdmin-Oberfläche bereits über die Option „pgAgent Jobs“, um dies zu tun pgAgent verwalten:

Um einen neuen Job zu definieren, müssen Sie nur "Erstellen" auswählen Verwenden Sie die rechte Schaltfläche auf „pgAgent Jobs“, und es fügt eine Bezeichnung für diesen Job ein und definiert die Schritte zu seiner Ausführung:
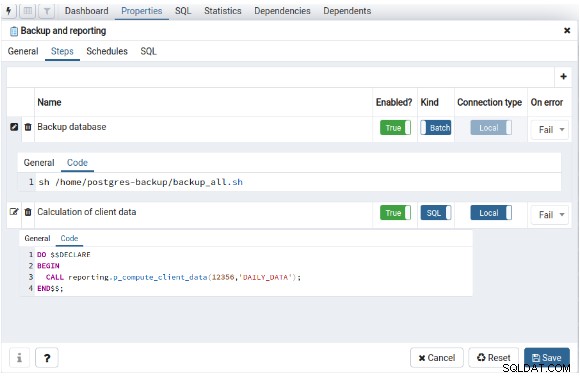
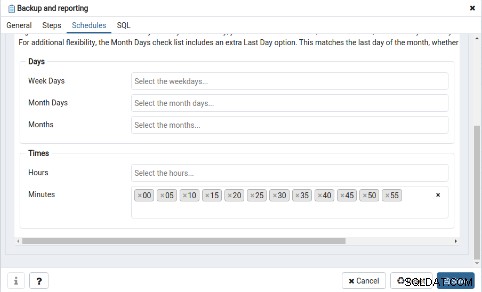
Im Reiter „Zeitpläne“ muss die Zeitplanung für diesen neuen Job definiert werden :
Um den Agenten schließlich im Hintergrund laufen zu lassen, muss die folgenden Prozess manuell:
/usr/bin/pgagent host=localhost dbname=postgres user=postgres port=5432 -l 1Dennoch ist die beste Option für diesen Agenten, einen Daemon mit dem vorherigen Befehl zu erstellen.
Erweiterung pg_cron
Der pg_cron ist ein Cron-basierter Job-Scheduler für PostgreSQL, der innerhalb der Datenbank als Erweiterung läuft (ähnlich dem DBMS_SCHEDULER in Oracle) und die Ausführung von Datenbankaufgaben direkt aus der Datenbank ermöglicht, aufgrund a Hintergrundarbeiter.
Die auszuführenden Aufgaben können eine der folgenden sein:
- gespeicherte Prozeduren
- SQL-Anweisungen
- PostgreSQL-Befehle (als VACUUM oder VACUUM ANALYZE)
pg_cron kann mehrere Jobs parallel ausführen, aber es kann immer nur eine Instanz eines Programms gleichzeitig laufen.
Wenn ein zweiter Lauf gestartet werden soll, bevor der erste beendet ist, wird er in die Warteschlange gestellt und gestartet, sobald der erste Lauf beendet ist.
Diese Erweiterung wurde für die Version 9.5 oder höher von PostgreSQL definiert.
Installation von pg_cron
Die Installation dieser Erweiterung erfordert nur den folgenden Befehl:
example@sqldat.com:~$ sudo apt-get -y install postgresql-10-cronAktualisierung von Konfigurationsdateien
Um den Hintergrund-Worker pg_cron nach dem Start des PostgreSQL-Servers zu starten, muss der Parameter pg_cron in postgresql.conf auf den Parameter shared_preload_libraries gesetzt werden:
shared_preload_libraries = ‘pg_cron’Es ist auch notwendig, in dieser Datei die Datenbank zu definieren, auf der die pg_cron-Erweiterung erstellt wird, indem Sie den folgenden Parameter hinzufügen:
cron.database_name= ‘postgres’Andererseits muss in der pg_hba.conf-Datei, die die Authentifizierung verwaltet, das postgres-Login als vertrauenswürdig für die IPv4-Verbindungen definiert werden, da pg_cron diesen Benutzer benötigt, um sich mit der Datenbank verbinden zu können ohne Angabe eines Passworts, daher muss dieser Datei die folgende Zeile hinzugefügt werden:
host postgres postgres 192.168.100.53/32 trustDie vertrauenswürdige Authentifizierungsmethode erlaubt es jedem, sich mit der/den in der Datei pg_hba.conf angegebenen Datenbank(en) zu verbinden, in diesem Fall mit der Postgres-Datenbank. Es handelt sich um eine Methode, die häufig verwendet wird, um eine Verbindung über einen Unix-Domain-Socket auf einem einzelnen Benutzercomputer für den Zugriff auf die Datenbank zu ermöglichen, und sollte nur verwendet werden, wenn ein angemessener Schutz auf Betriebssystemebene für Verbindungen zum Server vorhanden ist.
Beide Änderungen erfordern einen Neustart des PostgreSQL-Dienstes:
example@sqldat.com:~$ sudo system restart postgresql.serviceEs ist wichtig zu berücksichtigen, dass pg_cron keine Jobs ausführt, solange sich der Server im Hot-Standby-Modus befindet, sondern automatisch startet, wenn der Server hochgestuft wird.
Erstellung der Erweiterung pg_cron
Diese Erweiterung erstellt die Metadaten und die Verfahren zu ihrer Verwaltung, daher sollte der folgende Befehl auf psql ausgeführt werden:
postgres=#CREATE EXTENSION pg_cron;
CREATE EXTENSION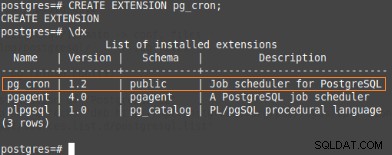
Jetzt sind die erforderlichen Objekte zum Planen von Jobs bereits im Cron-Schema definiert :
Diese Erweiterung ist sehr einfach, nur die Jobtabelle reicht aus, um alles zu verwalten diese Funktionalität:
Definition neuer Jobs
Die Scheduling-Syntax zum Definieren von Jobs auf pg_cron ist die gleiche wie beim Cron-Tool, und die Definition neuer Jobs ist sehr einfach, es ist nur notwendig, die Funktion cron.schedule aufzurufen:
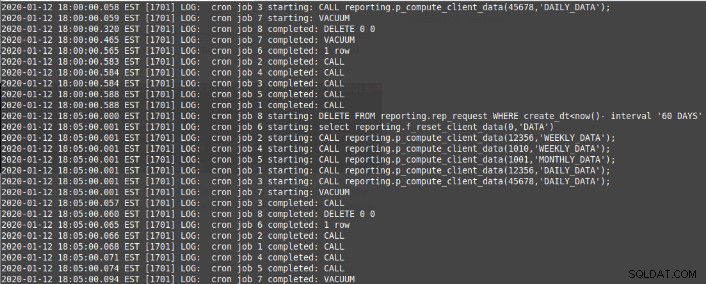
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(12356,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(998934,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(45678,''DAILY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1010,''WEEKLY_DATA'');')
select cron.schedule('*/5 * * * *','CALL reporting.p_compute_client_data(1001,''MONTHLY_DATA'');')
select cron.schedule('*/5 * * * *','select reporting.f_reset_client_data(0,''DATA'')')
select cron.schedule('*/5 * * * *','VACUUM')
select cron.schedule('*/5 * * * *','$$DELETE FROM reporting.rep_request WHERE create_dt<now()- interval '60 DAYS'$$)Das Job-Setup wird in der Job-Tabelle gespeichert:
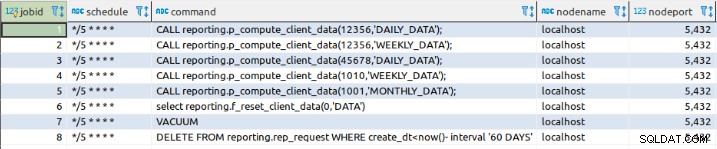
Eine andere Möglichkeit, einen Job zu definieren, besteht darin, die Daten direkt in den Cron einzufügen .job-Tabelle:
INSERT INTO cron.job (schedule, command, nodename, nodeport, database, username)
VALUES ('0 11 * * *','call loader.load_data();','postgresql-pgcron',5442,'staging', 'loader');und benutzerdefinierte Werte für Knotenname und Knotenport verwenden, um sich mit einem anderen Rechner (sowie anderen Datenbanken) zu verbinden.
Deaktivierung eines Jobs
Um einen Job zu deaktivieren, ist es dagegen nur notwendig, die folgende Funktion auszuführen:
select cron.schedule(8)Auftragsprotokollierung
Die Protokollierung dieser Jobs finden Sie in der PostgreSQL-Protokolldatei /var/log/postgresql/postgresql-12-main.log: