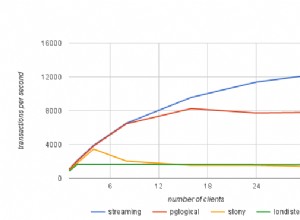
Was sind Replikationsslots?
Als "Replication Slots" noch nicht eingeführt wurden, war die Verwaltung der WAL-Segmente eine Herausforderung. Bei der Standard-Streaming-Replikation hat der Master keine Kenntnis vom Slave-Status. Nehmen Sie das Beispiel eines Masters, der eine große Transaktion ausführt, während sich ein Standby-Knoten für einige Stunden im Wartungsmodus befindet (z. B. Upgrade der Systempakete, Anpassung der Netzwerksicherheit, Hardware-Upgrade usw.). Irgendwann entfernt der Master sein Transaktionsprotokoll (WAL-Segmente), wenn der Checkpoint passiert wird. Sobald der Slave aus der Wartung ist, hat er möglicherweise einen großen Slave-Lag und muss den Master einholen. Schließlich wird der Slave ein schwerwiegendes Problem wie das folgende bekommen:
LOG: started streaming WAL from primary at 0/73000000 on timeline 1
FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000000000073 has already been removedDer typische Ansatz besteht darin, in Ihrer postgresql.conf ein WAL-Archivierungsskript anzugeben, das WAL-Dateien an einen oder mehrere Langzeitarchivierungsorte kopiert. Wenn Sie keine Standbys oder andere Streaming-Replikationsclients haben, kann der Server die WAL-Datei im Grunde verwerfen, sobald das Archivskript fertig ist oder OK antwortet. Sie benötigen jedoch immer noch einige aktuelle WAL-Dateien für die Wiederherstellung nach einem Absturz (Daten aus aktuellen WAL-Dateien werden während der Wiederherstellung nach einem Absturz wiedergegeben. In unserem Beispiel eines Standby-Knotens, der für einen langen Wartungszeitraum platziert wird, treten Probleme auf, wenn er wieder online geht und fragt die primäre für eine WAL-Datei, die die primäre nicht mehr hat, dann schlägt die Replikation fehl.
Dieses Problem wurde in PostgreSQL 9.4 über "Replication Slots" behoben.
Wenn Sie keine Replikationsslots verwenden, besteht eine gängige Methode zur Verringerung des Risikos einer fehlgeschlagenen Replikation darin, wal_keep_segments hoch genug zu setzen, damit WAL-Dateien, die möglicherweise benötigt werden, nicht rotiert oder recycelt werden. Der Nachteil dieses Ansatzes besteht darin, dass es schwierig ist festzustellen, welcher Wert für Ihr Setup am besten geeignet ist. Sie müssen nicht täglich gewartet werden oder Sie müssen keinen großen Stapel von WAL-Dateien aufbewahren, der Ihren Festplattenspeicher verschlingt. Obwohl dies funktioniert, ist es keine ideale Lösung, da das Risiko von Speicherplatz auf dem Master dazu führen kann, dass eingehende Transaktionen fehlschlagen.
Alternative Ansätze zur Nichtverwendung von Replikationsslots bestehen darin, PostgreSQL mit kontinuierlicher Archivierung zu konfigurieren und einen restore_command bereitzustellen, um der Replik Zugriff auf das Archiv zu gewähren. Um eine WAL-Anhäufung auf dem Primärserver zu vermeiden, können Sie ein separates Volume oder Speichergerät für die WAL-Dateien verwenden, z. B. SAN oder NFS. Eine andere Sache ist die synchrone Replikation, da sie erfordert, dass der Primärknoten darauf warten muss, dass Standby-Knoten Transaktionen festschreiben. Das heißt, es stellt sicher, dass WAL-Dateien auf die Standby-Knoten angewendet wurden. Dennoch ist es am besten, wenn Sie Archivierungsbefehle von der Primärdatenbank bereitstellen, damit Sie nach dem Recycling der WALs in der Primärdatenbank sicher sein können, dass Sie WAL-Sicherungen für den Fall einer Wiederherstellung haben. In einigen Situationen ist die synchrone Replikation jedoch keine ideale Lösung, da sie im Vergleich zur asynchronen Replikation mit einem gewissen Leistungsmehraufwand verbunden ist.
Typen von Replikationsslots
Es gibt zwei Arten von Replikationsslots. Diese sind:
Physische Replikationsslots
Kann für Standard-Streaming-Replikation verwendet werden. Sie stellen sicher, dass Daten nicht zu früh recycelt werden.
Logische Replikationsslots
Die logische Replikation macht dasselbe wie physische Replikationsslots und wird für die logische Replikation verwendet. Sie werden jedoch zur logischen Dekodierung verwendet. Die Idee hinter der logischen Dekodierung besteht darin, Benutzern die Möglichkeit zu geben, an das Transaktionsprotokoll anzuhängen und es mit einem Plugin zu dekodieren. Es erlaubt, Änderungen an der Datenbank und damit am Transaktionslog in jedem Format und für jeden Zweck zu extrahieren.
In diesem Blog verwenden wir physische Replikationsslots und wie man dies mit ClusterControl erreicht.
Vor- und Nachteile der Verwendung von Replikations-Slots
Replikationsslots sind definitiv von Vorteil, sobald sie aktiviert sind. Standardmäßig sind "Replikationsslots" nicht aktiviert und müssen manuell festgelegt werden. Zu den Vorteilen der Verwendung von Replikationsslots gehören
- Stellt sicher, dass der Master genügend WAL-Segmente behält, damit alle Replikate sie empfangen können
- Verhindert, dass der Master Zeilen entfernt, die Wiederherstellungskonflikte auf den Replikaten verursachen könnten
- Ein Master kann das Transaktionsprotokoll erst wiederverwenden, wenn es von allen Replikaten verbraucht wurde. Der Vorteil dabei ist, dass ein Slave nie so stark ins Hintertreffen geraten kann, dass ein Re-Sync nötig wäre.
Replikationsslots haben auch einige Einschränkungen.
- Ein verwaister Replikationsslot kann aufgrund von gestapelten WAL-Dateien vom Master zu einem unbegrenzten Festplattenwachstum führen
- Slave-Knoten, die einer langen Wartung unterzogen werden (z. B. Tage oder Wochen) und die an einen Replikationsslot gebunden sind, haben ein unbegrenztes Festplattenwachstum aufgrund von aufgehäuften WAL-Dateien vom Master
Sie können dies überwachen, indem Sie pg_replication_slots abfragen, um die nicht verwendeten Slots zu ermitteln. Wir werden dies etwas später noch einmal überprüfen.
Replikationsslots verwenden
Wie bereits erwähnt, gibt es zwei Arten von Replikationsslots. Für diesen Blog verwenden wir physische Replikationsslots für die Streaming-Replikation.
Erstellen eines Replikations-Slots
Das Erstellen einer Replikation ist einfach. Dazu müssen Sie die vorhandene Funktion pg_create_physical_replication_slot aufrufen, die im Master-Knoten ausgeführt und erstellt werden muss. Die Funktion ist einfach,
maximus_db=# \df pg_create_physical_replication_slot
Schema | pg_catalog
Name | pg_create_physical_replication_slot
Result data type | record
Argument data types | slot_name name, immediately_reserve boolean DEFAULT false, OUT slot_name name, OUT xlog_position pg_lsn
Type | normalz.B. Erstellen eines Replikationsslots mit dem Namen slot1,
postgres=# SELECT pg_create_physical_replication_slot('slot1');
-[ RECORD 1 ]-----------------------+---------
pg_create_physical_replication_slot | (slot1,)Die Replikations-Slot-Namen und die zugrunde liegende Konfiguration sind nur systemweit und nicht clusterweit. Wenn Sie beispielsweise Knoten A (aktueller Master) und die Standby-Knoten Knoten B und Knoten C haben und den Steckplatz auf einem Master-Knoten A namens „Steckplatz 1“ erstellen, stehen Knoten B und Knoten C keine Daten zur Verfügung. Daher müssen Sie die von Ihnen erstellten Slots neu erstellen, wenn ein Failover/Switchover stattfinden soll.
Verwerfen eines Replikations-Slots
Nicht verwendete Replikationsslots müssen entfernt oder gelöscht werden. Wie bereits erwähnt, können verwaiste Replikationsslots oder Slots, die keinem Client- oder Standby-Knoten zugewiesen wurden, zu grenzenlosen Speicherplatzproblemen führen, wenn sie nicht gelöscht werden. Daher ist es sehr wichtig, dass diese fallen gelassen werden, wenn sie nicht mehr verwendet werden. Um es zu löschen, rufen Sie einfach pg_drop_replication_slot auf. Diese Funktion hat die folgende Definition:
maximus_db=# \df pg_drop_replication_slot
Schema | pg_catalog
Name | pg_drop_replication_slot
Result data type | void
Argument data types | name
Type | normalDas Löschen ist einfach:
maximus_db=# select pg_drop_replication_slot('slot2');
-[ RECORD 1 ]------------+-
pg_drop_replication_slot |Überwachung Ihrer PostgreSQL-Replikationsslots
Die Überwachung Ihrer Replikationsslots ist etwas, das Sie nicht missen möchten. Sammeln Sie einfach die Informationen aus der Ansicht pg_replication_slots im primären/Master-Knoten, genau wie unten:
postgres=# select * from pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | main_slot
plugin |
slot_type | physical
datoid |
database |
active | t
active_pid | 16297
xmin |
catalog_xmin |
restart_lsn | 2/F4000108
confirmed_flush_lsn |
-[ RECORD 2 ]-------+-----------
slot_name | main_slot2
plugin |
slot_type | physical
datoid |
database |
active | f
active_pid |
xmin |
catalog_xmin |
restart_lsn |
confirmed_flush_lsn |Das obige Ergebnis zeigt, dass main_slot belegt ist, aber nicht main_slot2.
Eine andere Sache, die Sie tun können, ist zu überwachen, wie viel Verzögerung Sie hinter Ihren Slots haben. Um dies zu erreichen, können Sie einfach die Abfrage basierend auf dem folgenden Beispielergebnis verwenden:
postgres=# SELECT redo_lsn, slot_name,restart_lsn,
round((redo_lsn-restart_lsn) / 1024 / 1024 / 1024, 2) AS GB_behind
FROM pg_control_checkpoint(), pg_replication_slots;
redo_lsn | slot_name | restart_lsn | gb_behind
------------+-----------+-------------+-----------
1/8D400238 | slot1 | 0/9A000000 | 3.80Aber redo_lsn ist in 9.6 nicht vorhanden, soll redo_location verwenden, also in 9.6,
imbd=# SELECT redo_location, slot_name,restart_lsn,
round((redo_location-restart_lsn) / 1024 / 1024 / 1024, 2) AS GB_behind
FROM pg_control_checkpoint(), pg_replication_slots;
-[ RECORD 1 ]-+-----------
redo_location | 2/F6008BE0
slot_name | main_slot
restart_lsn | 2/F6008CC0
gb_behind | 0.00
-[ RECORD 2 ]-+-----------
redo_location | 2/F6008BE0
slot_name | main_slot2
restart_lsn | 2/F6008CC0
gb_behind | 0.00Anforderungen an Systemvariablen
Das Implementieren von Replikationsslots erfordert eine manuelle Einstellung. Es gibt Variablen, die Sie im Auge behalten müssen, die geändert werden müssen und in Ihrer postgresql.conf angegeben werden müssen. Siehe unten:
- max_replication_slots – Wenn auf 0 gesetzt, bedeutet dies, dass Replikationsslots vollständig deaktiviert sind. Wenn Sie PostgreSQL-Versionen <10 verwenden, muss dieser Slot anders als 0 (Standard) angegeben werden. Seit PostgreSQL 10 ist der Standardwert 10. Diese Variable gibt die maximale Anzahl von Replikationsslots an. Wenn Sie ihn auf einen niedrigeren Wert als die Anzahl der derzeit vorhandenen Replikationsslots setzen, wird der Server am Starten gehindert.
- wal_level – muss mindestens replik oder höher sein (replik ist Standard). Das Setzen von hot_standby oder archive wird dem Replikat zugeordnet. Für einen physischen Replikationsslot ist die Replikation ausreichend. Für logische Replikationsslots wird logisch bevorzugt.
- max_wal_senders – standardmäßig auf 10 gesetzt, 0 in Version 9.6, was bedeutet, dass die Replikation deaktiviert ist. Wir empfehlen Ihnen, dies mindestens auf 16 zu setzen, insbesondere wenn Sie mit ClusterControl laufen.
- hot_standby – in Versionen <10 müssen Sie dies auf on setzen, was standardmäßig ausgeschaltet ist. Dies ist wichtig für Standby-Knoten, dh wenn Sie eingeschaltet sind, können Sie während der Wiederherstellung oder im Standby-Modus eine Verbindung herstellen und Abfragen ausführen.
- primary_slot_name – Diese Variable wird über recovery.conf auf dem Standby-Knoten festgelegt. Dies ist der Steckplatz, der vom Empfänger oder Standby-Knoten verwendet wird, wenn er sich mit dem Sender (oder Primär/Master) verbindet.
Beachten Sie, dass diese Variablen meistens einen Neustart des Datenbankdienstes erfordern, um neue Werte nachzuladen.
Verwenden von Replikationsslots in einer ClusterControl-PostgreSQL-Umgebung
Sehen wir uns nun an, wie wir physische Replikationsslots verwenden und sie in einem von ClusterControl verwalteten Postgres-Setup implementieren können.
Bereitstellen von PostgreSQL-Datenbankknoten
Beginnen wir mit der Bereitstellung eines 3-Knoten-PostgreSQL-Clusters mit ClusterControl, diesmal mit PostgreSQL 9.6-Version.

ClusterControl stellt Knoten mit den folgenden entsprechend definierten Systemvariablen basierend auf ihren Standardwerten bereit oder hochgestimmte Werte. In:
postgres=# select name, setting from pg_settings where name in ('max_replication_slots', 'wal_level', 'max_wal_senders', 'hot_standby');
name | setting
-----------------------+---------
hot_standby | on
max_replication_slots | 0
max_wal_senders | 16
wal_level | replica
(4 rows)In den Versionen PostgreSQL> 9.6 ist der Standardwert von max_replication_slots 10, was standardmäßig aktiviert ist, aber nicht in 9.6 oder niedrigeren Versionen, die standardmäßig deaktiviert sind. Sie müssen max_replication_slots höher als 0 zuweisen. In diesem Beispiel setze ich max_replication_slots auf 5.
example@sqldat.com:~# grep 'max_replication_slots' /etc/postgresql/9.6/main/postgresql.conf
# max_replication_slots = 0 # max number of replication slots
max_replication_slots = 5und den Dienst neu gestartet,
example@sqldat.com:~# pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
9.6 main 5432 online postgres /var/lib/postgresql/9.6/main pg_log/postgresql-%Y-%m-%d_%H%M%S.log
example@sqldat.com:~# pg_ctlcluster 9.6 main restartFestlegen der Replikations-Slots für Primär- und Standby-Knoten
Dazu gibt es in ClusterControl keine Option, also müssen Sie Ihre Slots manuell erstellen. In diesem Beispiel habe ich die Slots im primären Host 192.168.30.100 erstellt:
192.168.10.100:5432 example@sqldat.com_db=# SELECT pg_create_physical_replication_slot('slot1'), pg_create_physical_replication_slot('slot2');
pg_create_physical_replication_slot | pg_create_physical_replication_slot
-------------------------------------+-------------------------------------
(slot1,) | (slot2,)
(1 row)Überprüfen, was wir gerade erstellt haben, zeigt,
192.168.10.100:5432 example@sqldat.com_db=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
-----------+--------+-----------+--------+----------+--------+------------+------+--------------+-------------+---------------------
slot1 | | physical | | | f | | | | |
slot2 | | physical | | | f | | | | |
(2 rows)Jetzt müssen wir in den Standby-Knoten die recovery.conf aktualisieren und die Variable primary_slot_name hinzufügen und den Anwendungsnamen ändern, damit es einfacher ist, den Knoten zu identifizieren. So sieht es in Host 192.168.30.110 recovery.conf aus:
example@sqldat.com:/var/lib/postgresql/9.6/main/pg_log# cat ../recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=node11 host=192.168.30.100 port=5432 user=cmon_replication password=m8rLmZxyn23Lc2Rk'
recovery_target_timeline = 'latest'
primary_slot_name = 'slot1'
trigger_file = '/tmp/failover_5432.trigger'Machen Sie dasselbe auch in Host 192.168.30.120, aber ändern Sie den Anwendungsnamen und setzen Sie den primären_Slot_Name ='slot2'.
Zustand des Replikations-Slots prüfen:
192.168.10.100:5432 example@sqldat.com_db=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
-----------+--------+-----------+--------+----------+--------+------------+------+--------------+-------------+---------------------
slot1 | | physical | | | t | 24252 | | | 0/CF0A4218 |
slot2 | | physical | | | t | 11635 | | | 0/CF0A4218 |
(2 rows)Was brauchen Sie noch?
Da ClusterControl derzeit keine Replikationsslots unterstützt, gibt es Dinge, die Sie berücksichtigen müssen. Was ist das? Lassen Sie uns ins Detail gehen.
Failover-/Switchover-Prozess
Wenn ein Auto-Failover oder Switchover über ClusterControl versucht wurde, werden Slots von den primären und den Standby-Knoten nicht beibehalten. Sie müssen dies manuell neu erstellen, die Variablen überprüfen, ob sie richtig gesetzt sind, und die recovery.conf entsprechend ändern.
Wiederaufbau eines Slaves von einem Master
Beim Neuaufbau eines Slaves wird die recovery.conf nicht beibehalten. Das bedeutet, dass Ihre recovery.conf-Einstellungen mit dem primary_slot_name gelöscht werden. Sie müssen dies erneut manuell angeben und die pg_replication_slots-Ansicht überprüfen, um festzustellen, ob Slots richtig verwendet werden oder verwaist sind.
Wenn Sie den Slave-/Standby-Knoten von einem Master neu erstellen möchten, müssen Sie möglicherweise die PGAPPNAME-Umgebungsvariable genau wie den folgenden Befehl angeben:
$ export PGAPPNAME="app_repl_testnode15"; /usr/pgsql-9.6/bin/pg_basebackup -h 192.168.10.190 -U cmon_replication -D /var/lib/pgsql/9.6/data -p5434 -W -S main_slot -X s -R -PDas Angeben des Parameters -R ist sehr wichtig, damit die recovery.conf neu erstellt wird, während -S angeben soll, welcher Slot-Name verwendet werden soll, wenn der Standby-Knoten neu erstellt wird.
Fazit
Die Implementierung der Replikations-Slots in PostgreSQL ist einfach, aber es gibt bestimmte Einschränkungen, die Sie beachten müssen. Bei der Bereitstellung mit ClusterControl müssen Sie einige Einstellungen während eines Failovers oder Slave-Neuaufbaus aktualisieren.