Eine Multi-Cloud-Umgebung ist eine gute Option für einen Notfallwiederherstellungsplan (DRP), aber es kann eine zeitaufwändige Aufgabe sein, da Sie die Konnektivität zwischen den verschiedenen Cloud-Anbietern konfigurieren müssen und werden dann müssen Sie Ihren Datenbank-Cluster an zwei verschiedenen Orten bereitstellen und verwalten.
In diesem Blog zeigen wir, wie man eine Multi-Cloud-Bereitstellung für PostgreSQL in zwei der derzeit beliebtesten Cloud-Anbieter, AWS und Google Cloud, durchführt. Für diese Aufgabe werden wir einige der Funktionen verwenden, die ClusterControl Ihnen bieten kann, wie z. B. Skalierung und Cluster-zu-Cluster-Replikation.
Wir gehen davon aus, dass Sie eine ClusterControl-Installation ausführen und bereits zwei verschiedene Cloud-Provider-Konten erstellt haben.
Vorbereiten Ihrer Cloud-Umgebung
Zunächst müssen Sie Ihre Umgebung bei Ihrem Haupt-Cloud-Anbieter erstellen. In diesem Fall verwenden wir AWS mit 2 PostgreSQL-Knoten:

Stellen Sie sicher, dass Sie den SSH- und PostgreSQL-Datenverkehr von Ihrem ClusterControl-Server zugelassen haben Bearbeiten Ihrer Sicherheitsgruppe:

Wechseln Sie dann zum sekundären Cloud-Anbieter und erstellen Sie mindestens eine virtuelle Maschine das wird der Slave-Knoten sein. Wir verwenden die Google Cloud Platform mit 1 PostgreSQL-Knoten.

Und stellen Sie erneut sicher, dass Sie SSH- und PostgreSQL-Datenverkehr von Ihrem ClusterControl zulassen Server:

In diesem Fall lassen wir den Datenverkehr ohne Einschränkung der Quelle zu , aber es ist nur ein Beispiel und wird im wirklichen Leben nicht empfohlen.
Stellen Sie einen PostgreSQL-Cluster in der Cloud bereit
Wir werden ClusterControl für diese Aufgabe verwenden, also gehen wir davon aus, dass Sie es installiert haben.
Gehen Sie zu Ihrem ClusterControl-Server und wählen Sie die Option „Bereitstellen“. Wenn Sie bereits eine PostgreSQL-Instanz ausführen, müssen Sie stattdessen „Vorhandenen Server/Datenbank importieren“ auswählen.
Bei der Auswahl von PostgreSQL müssen Sie Benutzer, Schlüssel oder Passwort und Port angeben um sich per SSH mit Ihren PostgreSQL-Knoten zu verbinden. Außerdem benötigen Sie den Namen für Ihren neuen Cluster und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
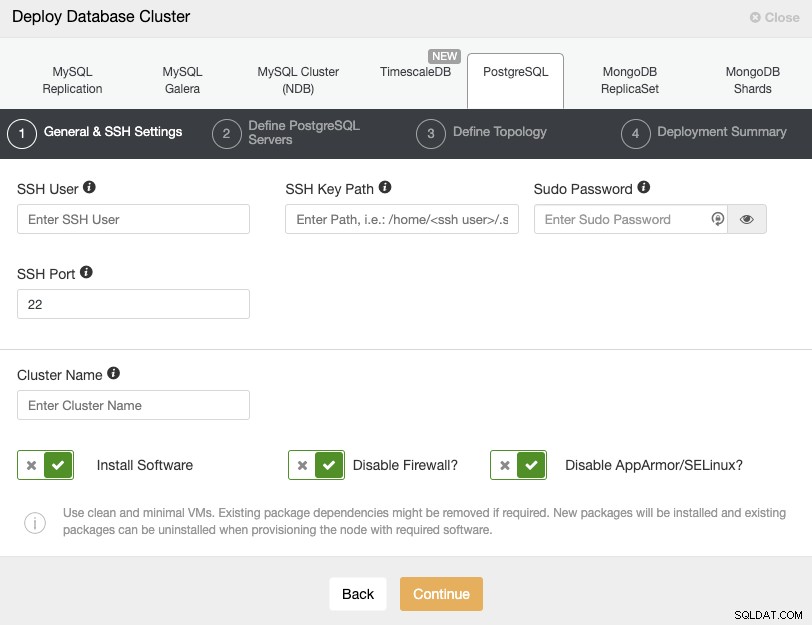
Weitere Informationen zu diesem Schritt finden Sie in den Benutzeranforderungen von ClusterControl.
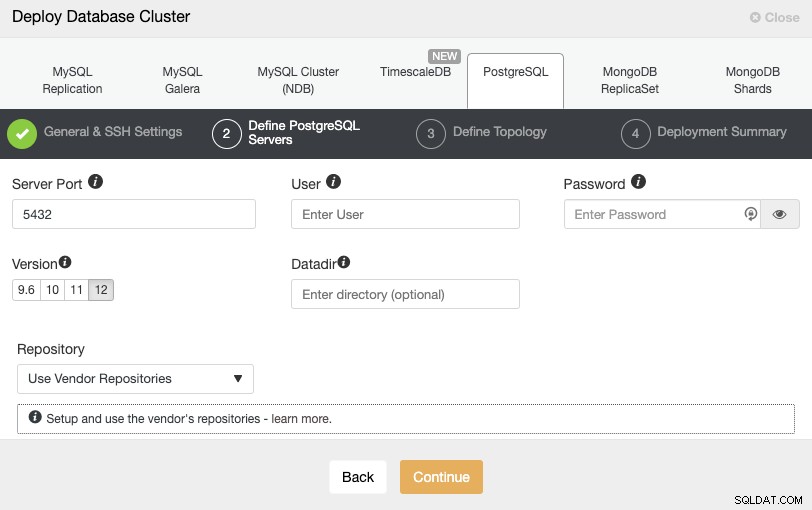
Nachdem Sie die SSH-Zugangsdaten eingerichtet haben, müssen Sie den Datenbankbenutzer definieren, version und datadir (optional). Sie können auch angeben, welches Repository verwendet werden soll. Im nächsten Schritt müssen Sie Ihre Server zu dem Cluster hinzufügen, den Sie erstellen werden.
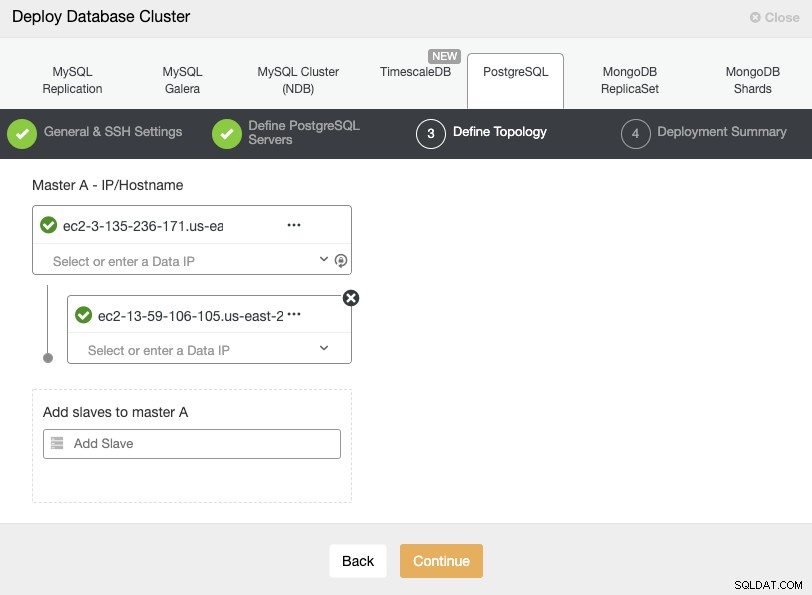
Wenn Sie Ihre Server hinzufügen, können Sie die IP oder den Hostnamen eingeben. In diesem Schritt könnten Sie auch den im sekundären Cloud-Anbieter platzierten Knoten hinzufügen, da ClusterControl keine Einschränkungen hinsichtlich des zu verwendenden Netzwerks hat, aber um es klarer zu machen, werden wir ihn im nächsten Abschnitt hinzufügen. Die einzige Voraussetzung hier ist, SSH-Zugriff auf den Knoten zu haben.
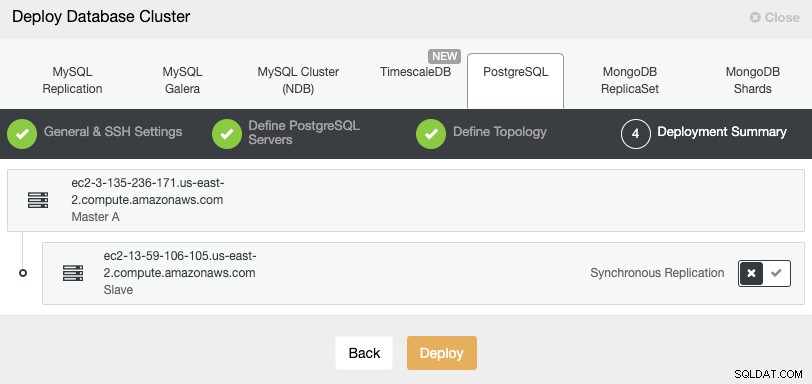
Im letzten Schritt können Sie wählen, ob Ihre Replikation synchron oder Asynchron.
Falls Sie Ihren Remote-Knoten hier hinzufügen, ist es wichtig, die asynchrone Replikation zu verwenden, andernfalls könnte Ihr Cluster von Latenz- oder Netzwerkproblemen betroffen sein.
Sie können den Erstellungsstatus im Aktivitätsmonitor von ClusterControl überwachen.
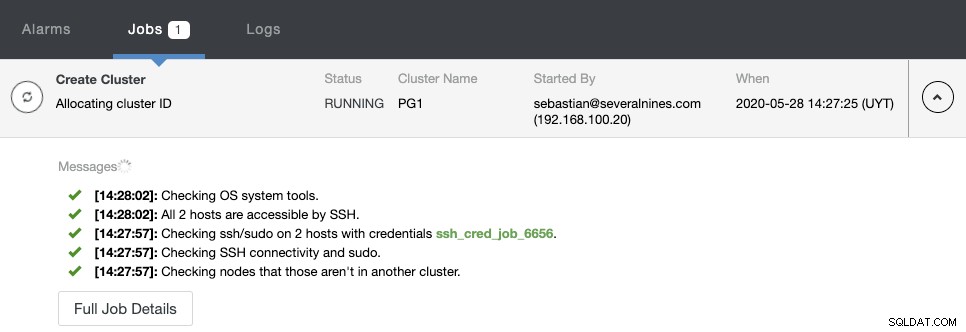
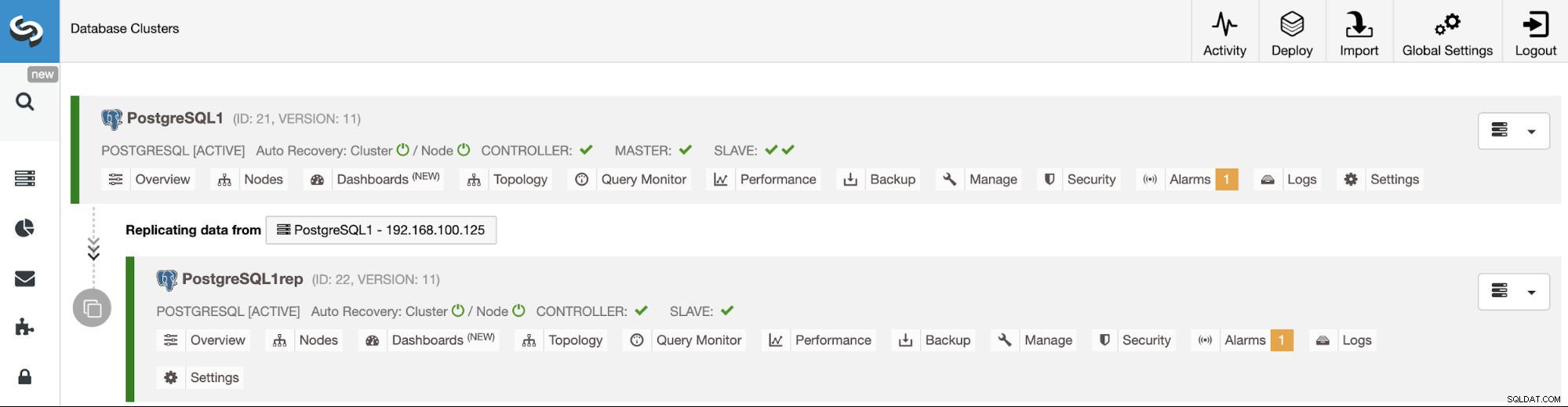
Sobald die Aufgabe abgeschlossen ist, können Sie Ihren neuen PostgreSQL-Cluster im sehen Hauptbildschirm von ClusterControl.

Hinzufügen eines Remote-Slave-Knotens in der Cloud
Sobald Sie Ihren Cluster erstellt haben, können Sie mehrere Aufgaben darauf ausführen, wie z. B. einen Load Balancer oder einen Replikations-Slave-Knoten bereitstellen/importieren.
Gehen Sie zu Cluster-Aktionen und wählen Sie „Replikations-Slave hinzufügen“:
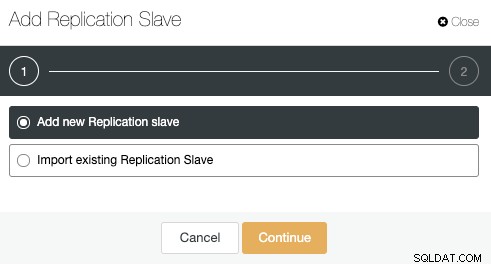
Lassen Sie uns die Option „Neuen Replikations-Slave hinzufügen“ verwenden, da wir davon ausgehen der Remote-Knoten ist eine Neuinstallation, wenn nicht, können Sie stattdessen die Option „Vorhandenen Replikations-Slave importieren“ verwenden.
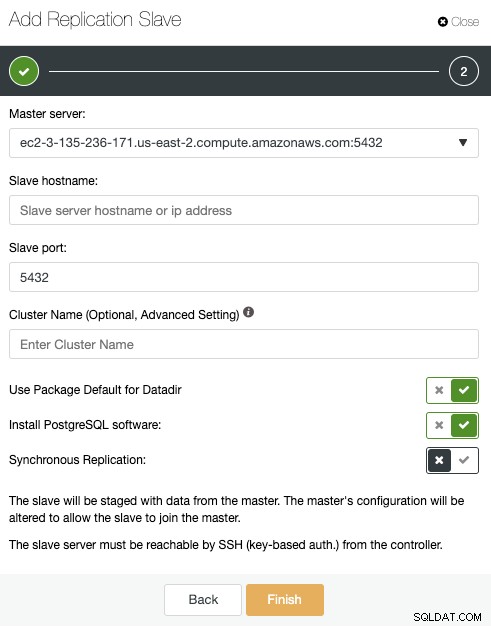
Hier müssen Sie nur Ihren Master-Server auswählen und die IP-Adresse eingeben für Ihren neuen Slave-Server und den Datenbankport. Dann können Sie wählen, ob ClusterControl die Software installieren soll und ob der Replikations-Slave synchron oder asynchron sein soll. Auch hier gilt:Wenn Sie einen Knoten in einem anderen Rechenzentrum hinzufügen, sollten Sie die asynchrone Replikation verwenden, um Probleme im Zusammenhang mit der Netzwerkleistung zu vermeiden.
Auf diese Weise können Sie beliebig viele Replikate hinzufügen und den Leseverkehr mithilfe eines Lastenausgleichs verteilen, den Sie auch mit ClusterControl implementieren können.
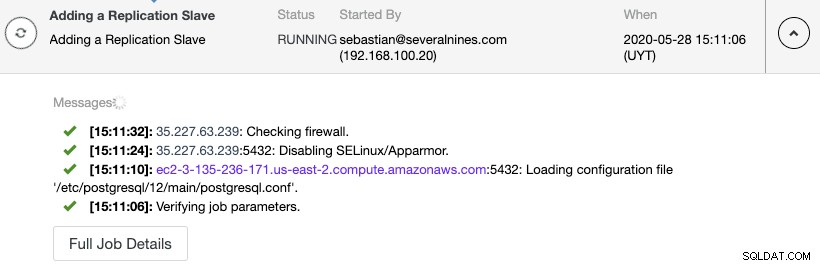
Sie können die Erstellung von Replikations-Slaves im Aktivitätsmonitor von ClusterControl überwachen.
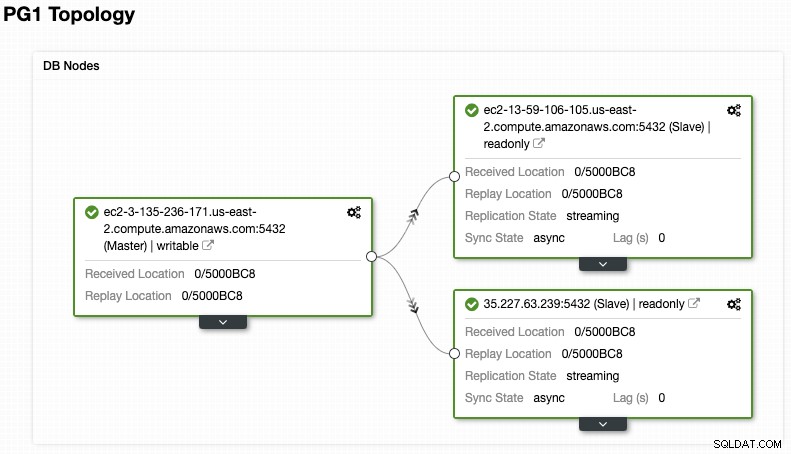
Und überprüfen Sie Ihre endgültige Topologie im Abschnitt "Topologieansicht".
Cluster-zu-Cluster-Replikation in der Cloud
Anstatt die Option „Replikations-Slave hinzufügen“ zu verwenden, um eine Multi-Cloud-Umgebung zu haben, können Sie die ClusterControl-Cluster-zu-Cluster-Replikationsfunktion verwenden, um einen Remote-Cluster hinzuzufügen. Im Moment hat diese Funktion eine Einschränkung für PostgreSQL, die es Ihnen erlaubt, nur einen Remote-Knoten zu haben, also ist es der vorherigen Methode ziemlich ähnlich, aber wir arbeiten daran, diese Einschränkung bald in einer zukünftigen Version zu entfernen.
Um einen neuen Slave-Cluster zu erstellen, gehen Sie zu ClusterControl -> Cluster auswählen -> Cluster-Aktionen -> Slave-Cluster erstellen.
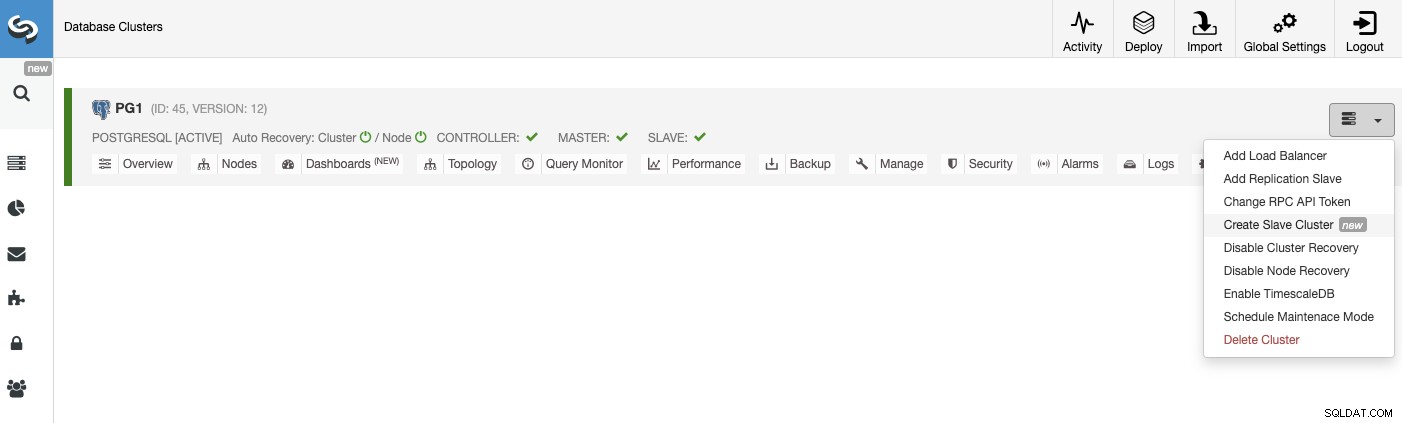
Der Slave-Cluster wird erstellt, indem Daten vom aktuellen Master-Cluster gestreamt werden.
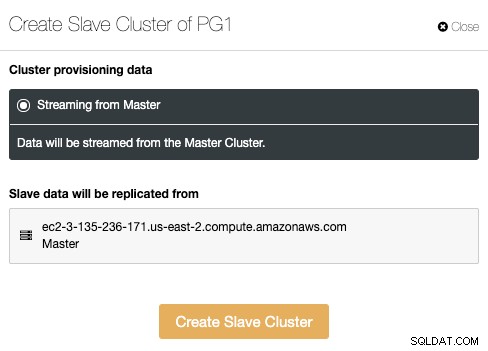
In diesem Abschnitt müssen Sie den Master-Knoten des aktuellen Clusters auswählen wo die Daten repliziert werden.
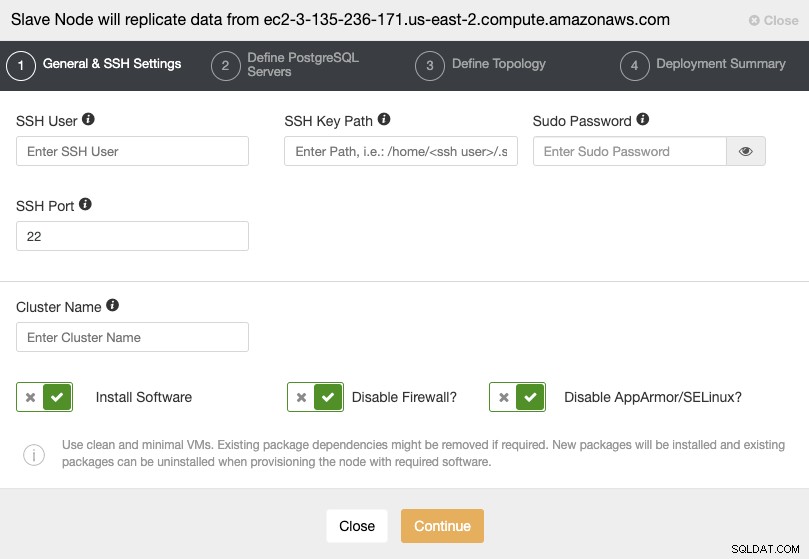
Wenn Sie zum nächsten Schritt gehen, müssen Sie User, Key or angeben Passwort und Port, um sich per SSH mit Ihren Servern zu verbinden. Außerdem benötigen Sie einen Namen für Ihr Slave-Cluster und wenn Sie möchten, dass ClusterControl die entsprechende Software und Konfigurationen für Sie installiert.
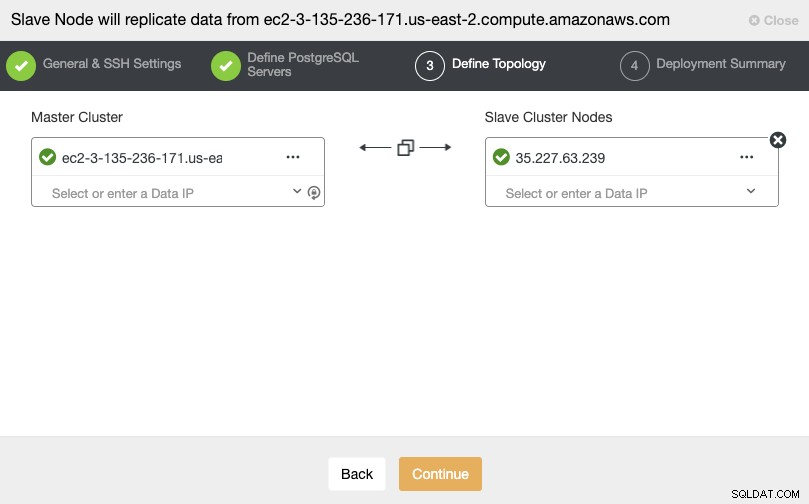
Nachdem Sie die SSH-Zugangsdaten eingerichtet haben, müssen Sie die Datenbankversion definieren, datadir, Port und Admin-Anmeldeinformationen. Da die Streaming-Replikation verwendet wird, stellen Sie sicher, dass Sie dieselbe Datenbankversion und dieselben Anmeldeinformationen verwenden, die im Master-Cluster verwendet werden. Sie können auch angeben, welches Repository verwendet werden soll.
In diesem Schritt müssen Sie den Server für den neuen Slave-Cluster hinzufügen . Für diese Aufgabe können Sie sowohl die IP-Adresse als auch den Hostnamen des Datenbankknotens eingeben.
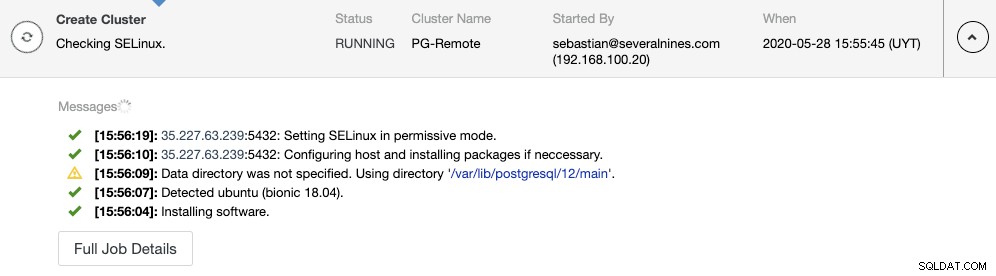
Sie können die Erstellung des Slave-Clusters im ClusterControl-Aktivitätsmonitor überwachen. Sobald die Aufgabe abgeschlossen ist, können Sie den Cluster auf dem Hauptbildschirm von ClusterControl sehen.
Fazit
Mit diesen ClusterControl-Funktionen können Sie die Replikation zwischen verschiedenen Cloud-Anbietern für eine PostgreSQL-Datenbank (und verschiedene Technologien) schnell einrichten und die Einrichtung auf einfache und benutzerfreundliche Weise verwalten. Über die Kommunikation zwischen den Cloud-Anbietern müssen Sie aus Sicherheitsgründen den Datenverkehr nur von bekannten Quellen einschränken, also nur von Cloud-Anbieter 1 zu Cloud-Anbieter 2 und umgekehrt.