Einer der wichtigsten Aspekte der Hochverfügbarkeit ist die Fähigkeit, schnell auf Ausfälle zu reagieren. Es ist nicht ungewöhnlich, Datenbanken manuell zu verwalten und Überwachungssoftware den Zustand der Datenbank im Auge behalten zu lassen. Im Falle eines Ausfalls sendet die Überwachungssoftware eine Warnung an das Bereitschaftspersonal. Dies bedeutet, dass möglicherweise jemand aufwachen, sich an einen Computer begeben und sich bei Systemen anmelden und Protokolle einsehen muss – das heißt, es gibt eine ziemliche Vorlaufzeit, bevor die Behebung beginnen kann. Idealerweise sollte der gesamte Prozess automatisiert werden.
In diesem Blog sehen wir uns an, wie man ein vollständig automatisiertes System bereitstellt, das erkennt, wenn die primäre Datenbank ausfällt, und Failover-Verfahren einleitet, indem es eine sekundäre Datenbank fördert. Wir werden ClusterControl verwenden, um ein automatisches Failover der Moodle PostgreSQL-Datenbank durchzuführen.
Vorteil des automatischen Failover
- Weniger Zeit zum Wiederherstellen des Datenbankdienstes
- Höhere Systemverfügbarkeit
- Weniger Abhängigkeit vom DBA oder Administrator, der die Hochverfügbarkeit für die Datenbank eingerichtet hat
Architektur
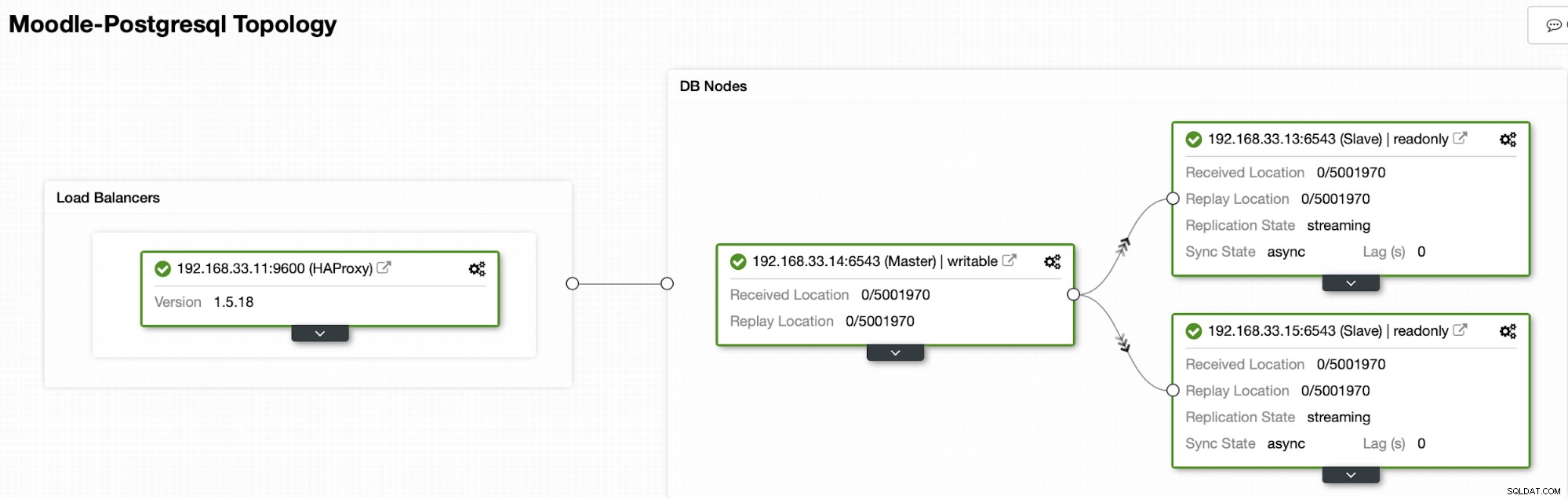
Derzeit haben wir einen primären Postgres-Server und zwei sekundäre Server unter HAProxy Load Balancer der den Moodle-Datenverkehr an den primären PostgreSQL-Knoten sendet. Die Cluster-Wiederherstellung und die automatische Knotenwiederherstellung in ClusterControl sind die wichtigen Einstellungen, um den automatischen Failover-Prozess durchzuführen.

Steuern, auf welchen Server ein Failover erfolgen soll
ClusterControl bietet Whitelisting und Blacklisting einer Reihe von Servern, die Sie am Failover teilnehmen oder als Kandidaten ausschließen möchten.
Es gibt zwei Variablen, die Sie in der cmon-Konfiguration setzen können,
- replication_failover_whitelist :enthält eine Liste von IPs oder Hostnamen von sekundären Servern, die als potenzielle primäre Kandidaten verwendet werden sollten. Wenn diese Variable gesetzt ist, werden nur diese Hosts berücksichtigt.
- replication_failover_blacklist :enthält eine Liste von Hosts, die niemals als primärer Kandidat betrachtet werden. Sie können damit sekundäre Server auflisten, die für Sicherungen oder analytische Abfragen verwendet werden. Wenn die Hardware zwischen sekundären Servern unterschiedlich ist, möchten Sie vielleicht die Server, die langsamere Hardware verwenden, hier platzieren.
Automatischer Failover-Prozess
Schritt 1
Wir haben das Laden der Daten auf dem primären Server (192.168.33.14) mit dem Tool sysbench gestartet.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Schritt 2
Wir werden den Postgres-Primärserver (192.168.33.14) stoppen. In ClusterControl ist der Parameter (enable_cluster_autorecovery) aktiviert, sodass er den nächsten geeigneten primären Server heraufstufen wird.
# service postgresql-12 stopSchritt 3
ClusterControl erkennt Fehler in der primären und befördert eine sekundäre mit den aktuellsten Daten als neue primäre. Es funktioniert auch auf den restlichen sekundären Servern, um sie vom neuen primären Server zu replizieren.

In unserem Fall ist (192.168.33.13) ein neuer primärer Server und sekundäre Server replizieren jetzt von diesem neuen primären Server. Jetzt leitet der HAProxy den Datenbankverkehr von den Moodle-Servern zum neuesten primären Server weiter.
Von (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Von (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Aktuelle Topologie
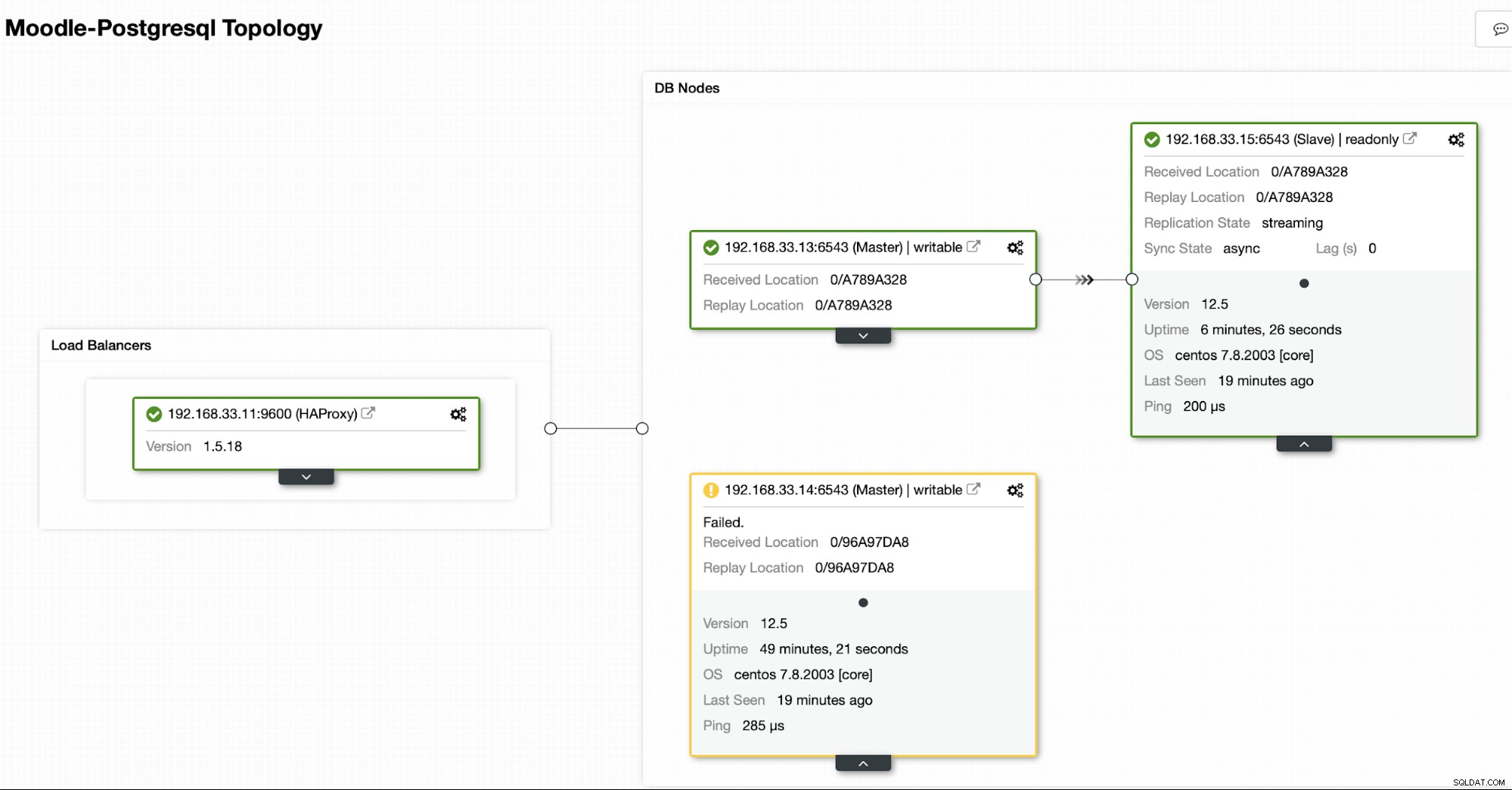
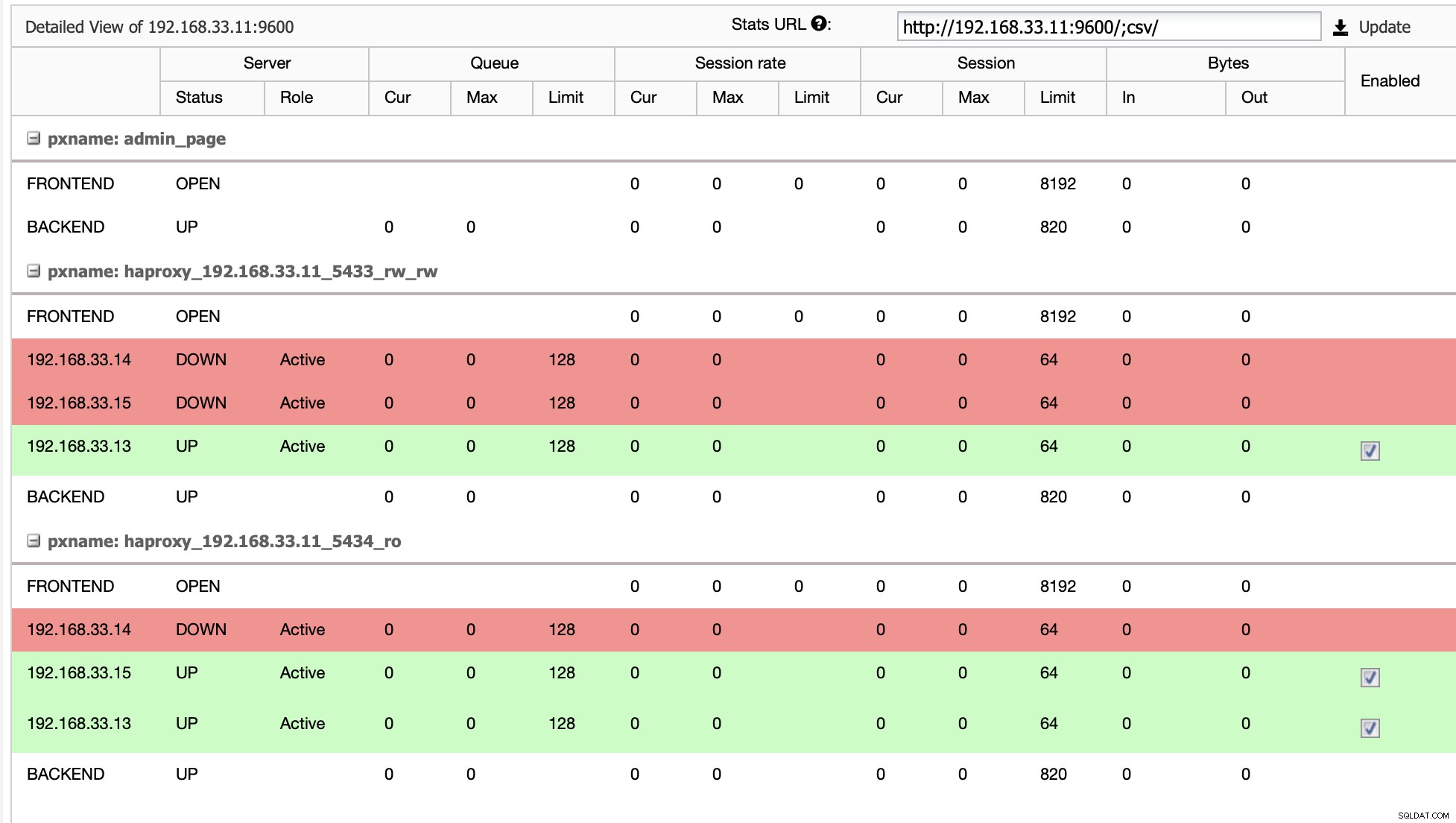
Wenn HAProxy feststellt, dass einer unserer Knoten, entweder primär oder repliziert, ist nicht zugänglich ist, wird es automatisch als offline markiert. HAProxy sendet keinen Datenverkehr von der Moodle-Anwendung an ihn. Diese Prüfung erfolgt durch Zustandsprüfungsskripte, die von ClusterControl zum Zeitpunkt der Bereitstellung konfiguriert werden.
Sobald ClusterControl einen Replikatserver zum primären Server hochstuft, markiert unser HAProxy den alten primären Knoten als offline und setzt den heraufgestuften Knoten online.
Sobald der alte primäre Server wieder online ist, wird er nicht automatisch mit dem neuen primären Server synchronisiert. Wir müssen es wieder in die Topologie einlassen, und das kann über die ClusterControl-Schnittstelle erfolgen. Dadurch wird die Möglichkeit von Datenverlust oder Inkonsistenz vermieden, falls wir untersuchen möchten, warum dieser Server überhaupt ausgefallen ist.
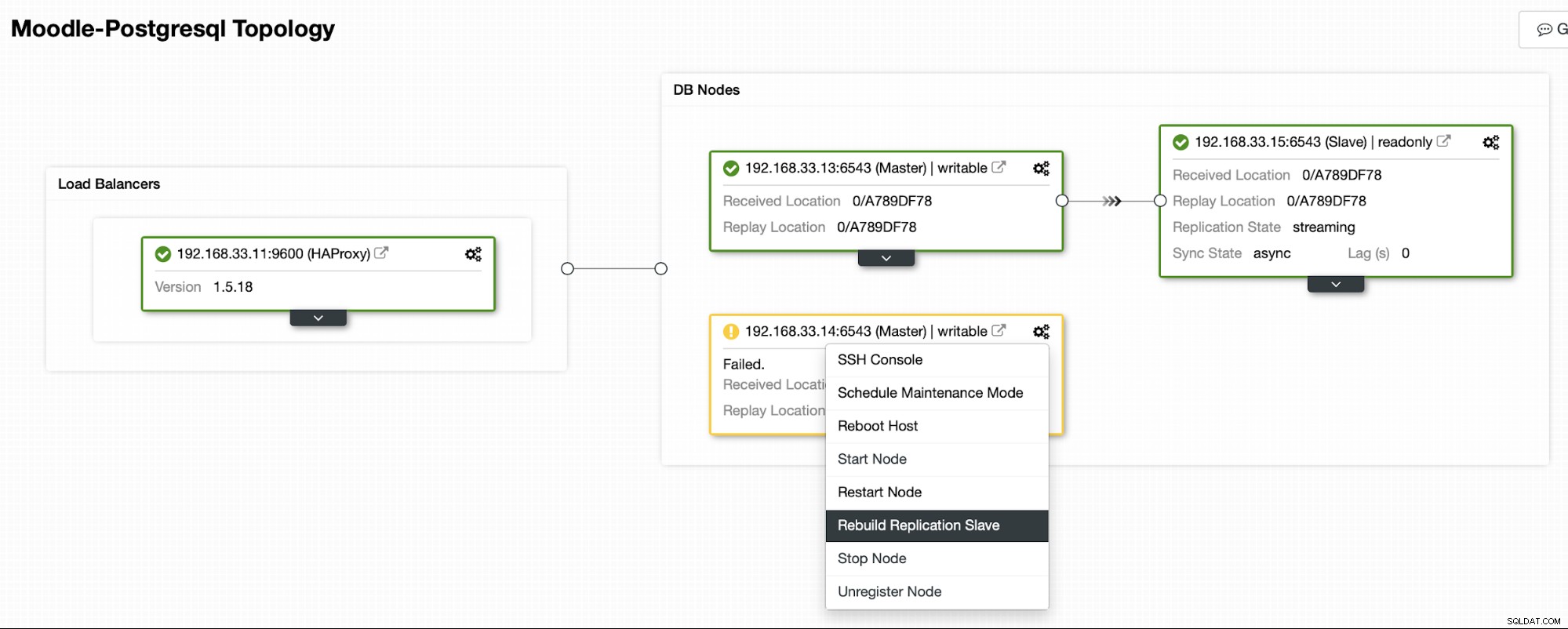
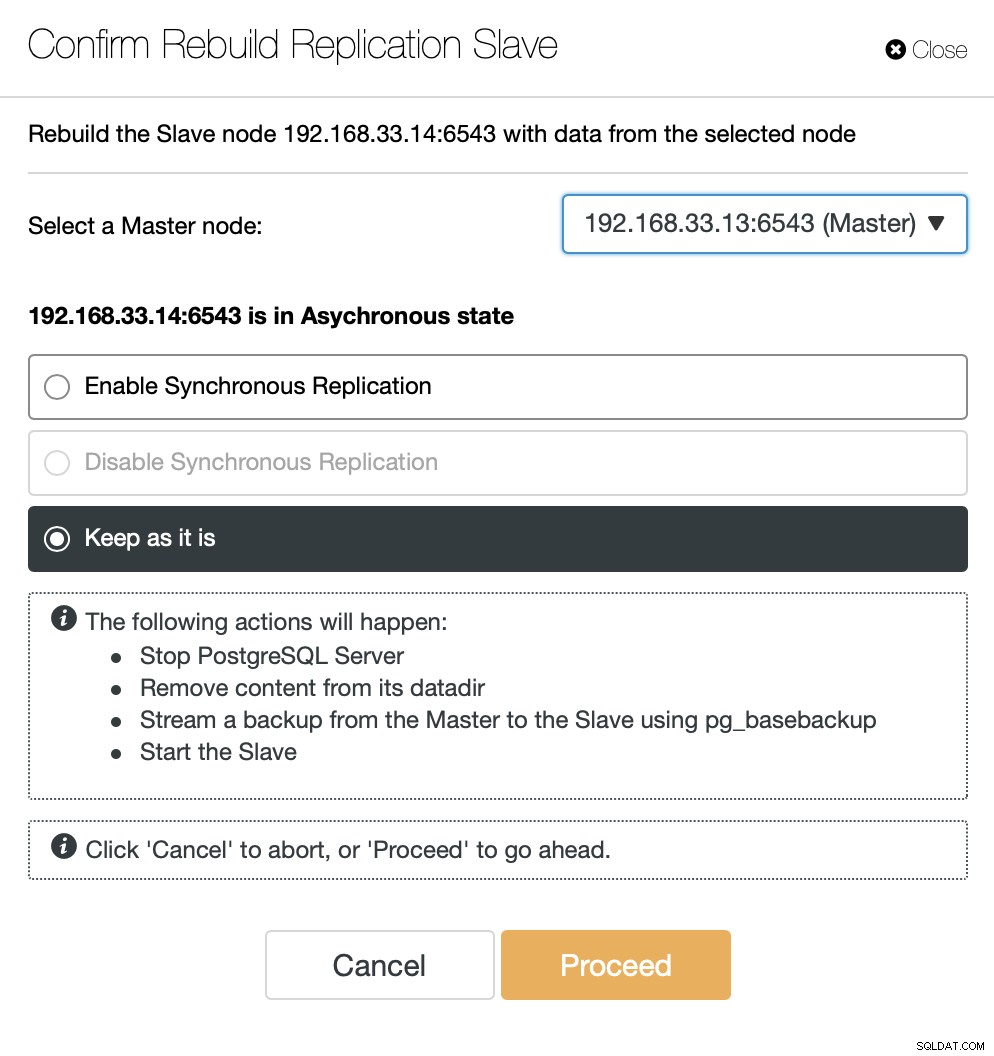
ClusterControl streamt die Sicherung vom neuen primären Server und konfiguriert die Replikation.
Schlussfolgerung
Automatisches Failover ist ein wichtiger Bestandteil jeder Moodle-Produktionsdatenbank. Es kann Ausfallzeiten reduzieren, wenn ein Server ausfällt, aber auch bei der Durchführung allgemeiner Wartungsaufgaben oder Migrationen. Es ist wichtig, es richtig zu machen, da es wichtig ist, dass die Failover-Software die richtigen Entscheidungen trifft.