Es ist jetzt fast zwei Monate her, dass wir SCUMM (Severalnines ClusterControl Unified Management and Monitoring) veröffentlicht haben. SCUMM verwendet Prometheus als zugrunde liegende Methode, um Zeitreihendaten von Exporteuren zu sammeln, die auf Datenbankinstanzen und Load Balancern ausgeführt werden. Dieser Blog zeigt Ihnen, wie Sie Probleme beheben können, wenn Prometheus-Exporter nicht ausgeführt werden oder wenn die Diagramme keine Daten anzeigen oder „Keine Datenpunkte“ anzeigen.
Was ist Prometheus?
Prometheus ist ein Open-Source-Überwachungssystem mit einem dimensionalen Datenmodell, einer flexiblen Abfragesprache, einer effizienten Zeitreihendatenbank und einem modernen Alarmierungsansatz. Es ist eine Überwachungsplattform, die Metriken von überwachten Zielen sammelt, indem sie HTTP-Endpunkte von Metriken auf diesen Zielen kratzt. Es bietet dimensionale Daten, leistungsstarke Abfragen, großartige Visualisierung, effiziente Speicherung, einfache Bedienung, präzise Warnungen, viele Client-Bibliotheken und viele Integrationen.
Prometheus im Einsatz für SCUMM-Dashboards
Prometheus sammelt Metrikdaten von Exporteuren, wobei jeder Exporteur auf einer Datenbank oder einem Load-Balancer-Host läuft. Das folgende Diagramm zeigt Ihnen, wie diese Exporter mit dem Server verbunden sind, der den Prometheus-Prozess hostet. Es zeigt, dass auf dem ClusterControl-Knoten Prometheus ausgeführt wird, wo auch process_exporter und node_exporter ausgeführt werden.
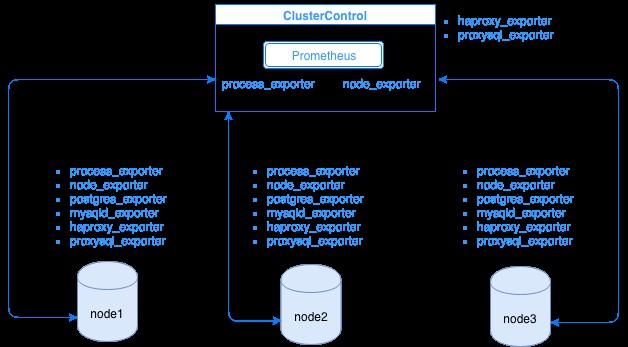
Das Diagramm zeigt, dass Prometheus auf dem ClusterControl-Host und den Exportern process_exporter ausgeführt wird und node_exporter werden ebenfalls ausgeführt, um Metriken von seinem eigenen Knoten zu sammeln. Optional können Sie Ihren ClusterControl-Host auch als Ziel festlegen, in dem Sie HAProxy oder ProxySQL einrichten können.
Für die obigen Cluster-Knoten (node1, node2 und node3) kann mysqld_exporter oder postgres_exporter ausgeführt werden, die die Agenten sind, die Daten intern in diesem Knoten auslesen und an den Prometheus-Server weiterleiten und in seinem eigenen Datenspeicher speichern. Sie können seine physischen Daten über /var/lib/prometheus/data innerhalb des Hosts finden, auf dem Prometheus eingerichtet ist.
Wenn Sie beispielsweise Prometheus im ClusterControl-Host einrichten, sollten die folgenden Ports geöffnet sein. Siehe unten:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusBasierend auf der Ausgabe habe ich auch ProxySQL auf dem Host testccnode ausgeführt, auf dem ClusterControl gehostet wird.
Häufige Probleme mit SCUMM-Dashboards, die Prometheus verwenden
Wenn Dashboards aktiviert sind, installiert ClusterControl Binärdateien und Exporter wie node_exporter, process_exporter, mysqld_exporter, postgres_exporter und daemon und stellt sie bereit. Dies sind die gemeinsamen Sätze von Paketen für die Datenbankknoten. Wenn diese eingerichtet und installiert sind, werden die folgenden Daemon-Befehle gestartet und wie unten gezeigt ausgeführt:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusFür einen PostgreSQL-Knoten
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterEs hat die gleichen Exporter wie für einen MySQL-Knoten, unterscheidet sich aber nur beim postgres_exporter, da dies ein PostgreSQL-Datenbankknoten ist.
Wenn jedoch ein Knoten unter einer Stromunterbrechung, einem Systemabsturz oder einem Systemneustart leidet, werden diese Exporter nicht mehr ausgeführt. Prometheus wird melden, dass ein Exporteur ausgefallen ist. ClusterControl testet Prometheus selbst und fragt nach den Status des Exporteurs. Es reagiert also auf diese Informationen und startet den Exporter neu, wenn er heruntergefahren ist.
Beachten Sie jedoch, dass Exporter, die nicht über ClusterControl installiert wurden, nach einem Absturz nicht neu gestartet werden. Der Grund dafür ist, dass sie nicht von systemd oder einem Daemon überwacht werden, der als Sicherheitsskript fungiert, das einen Prozess bei einem Absturz oder einem abnormalen Herunterfahren neu starten würde. Daher zeigt der folgende Screenshot, wie es aussieht, wenn die Exporter nicht ausgeführt werden. Siehe unten:
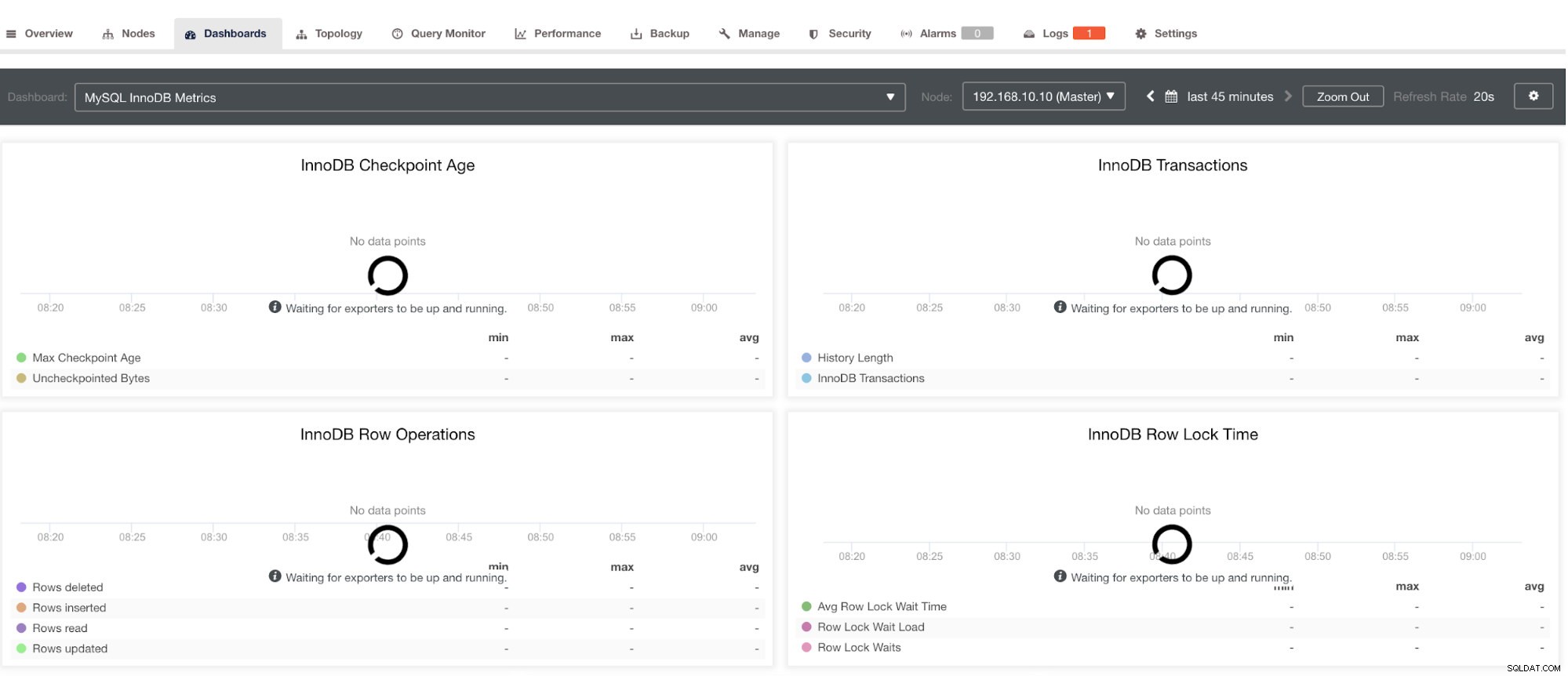
und im PostgreSQL-Dashboard haben dasselbe Ladesymbol mit der Bezeichnung „Keine Datenpunkte“ im Diagramm. Siehe unten:
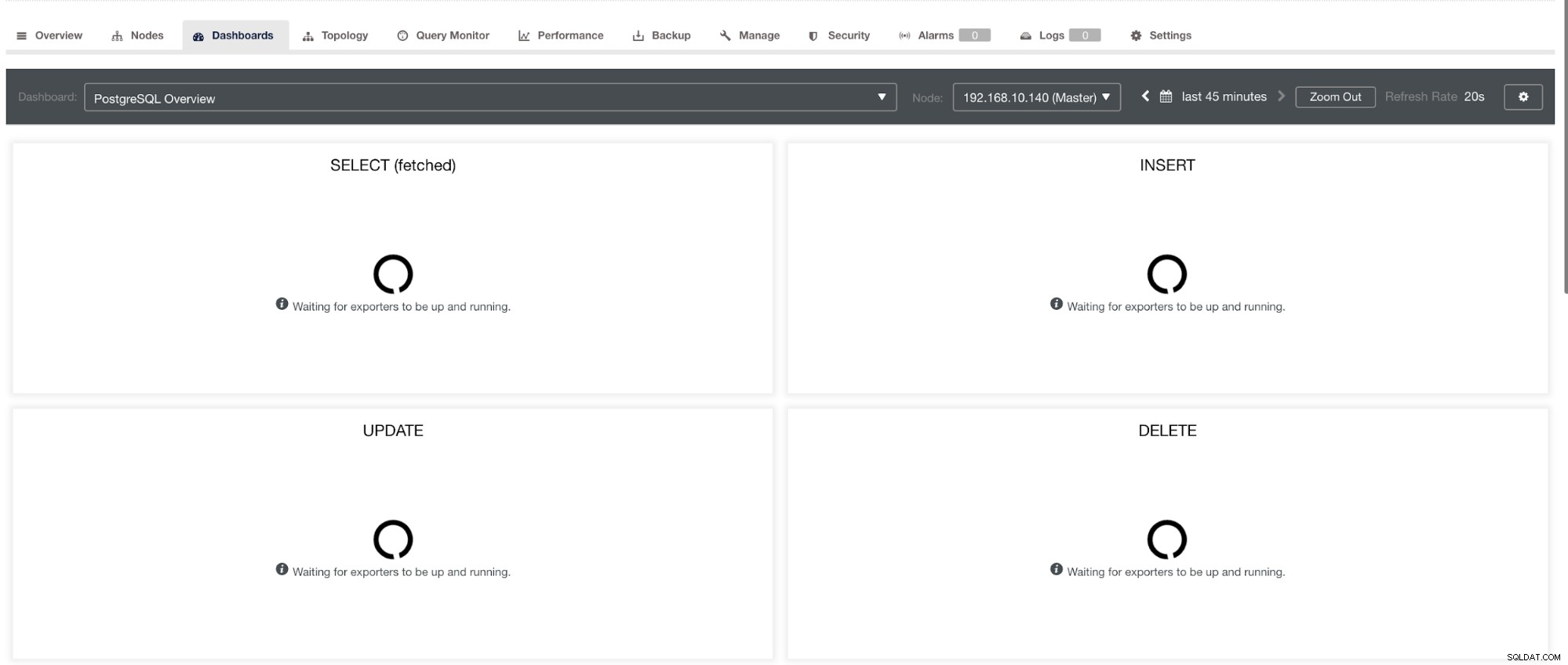
Daher können diese durch verschiedene Techniken behoben werden, die in den folgenden Abschnitten folgen werden.
Fehlerbehebung bei Prometheus
Prometheus-Agenten, die als Exporter bekannt sind, verwenden die folgenden Ports:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) und den eigenen 9090, der einem Prometheus gehört Prozess. Dies sind die Ports für diese Agenten, die von ClusterControl verwendet werden.
Um mit der Fehlerbehebung der SCUMM-Dashboard-Probleme zu beginnen, können Sie damit beginnen, die vom Datenbankknoten geöffneten Ports zu überprüfen. Sie können den folgenden Listen folgen:
-
Überprüfen Sie, ob die Ports offen sind
z. B.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporEs besteht die Möglichkeit, dass die Ports nicht geöffnet sind, weil eine Firewall (wie iptables oder firewalld) das Öffnen des Ports blockiert oder der Prozess-Daemon selbst nicht läuft.
-
Verwenden Sie curl vom Host-Monitor und überprüfen Sie, ob der Port erreichbar und offen ist.
z. B.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0Im Idealfall fand ich diesen Ansatz für mich praktisch machbar, da ich vom Terminal aus leicht grep und debuggen kann.
-
Warum nicht die Web-Benutzeroberfläche verwenden?
-
Prometheus legt Port 9090 offen, der von ClusterControl in unseren SCUMM-Dashboards verwendet wird. Abgesehen davon können die Ports, die die Exporteure verfügbar machen, auch zur Fehlerbehebung und Bestimmung der verfügbaren Metriknamen mit PromQL verwendet werden. Auf dem Server, auf dem Prometheus läuft, können Sie https://
:9090/targets besuchen . Der folgende Screenshot zeigt es in Aktion: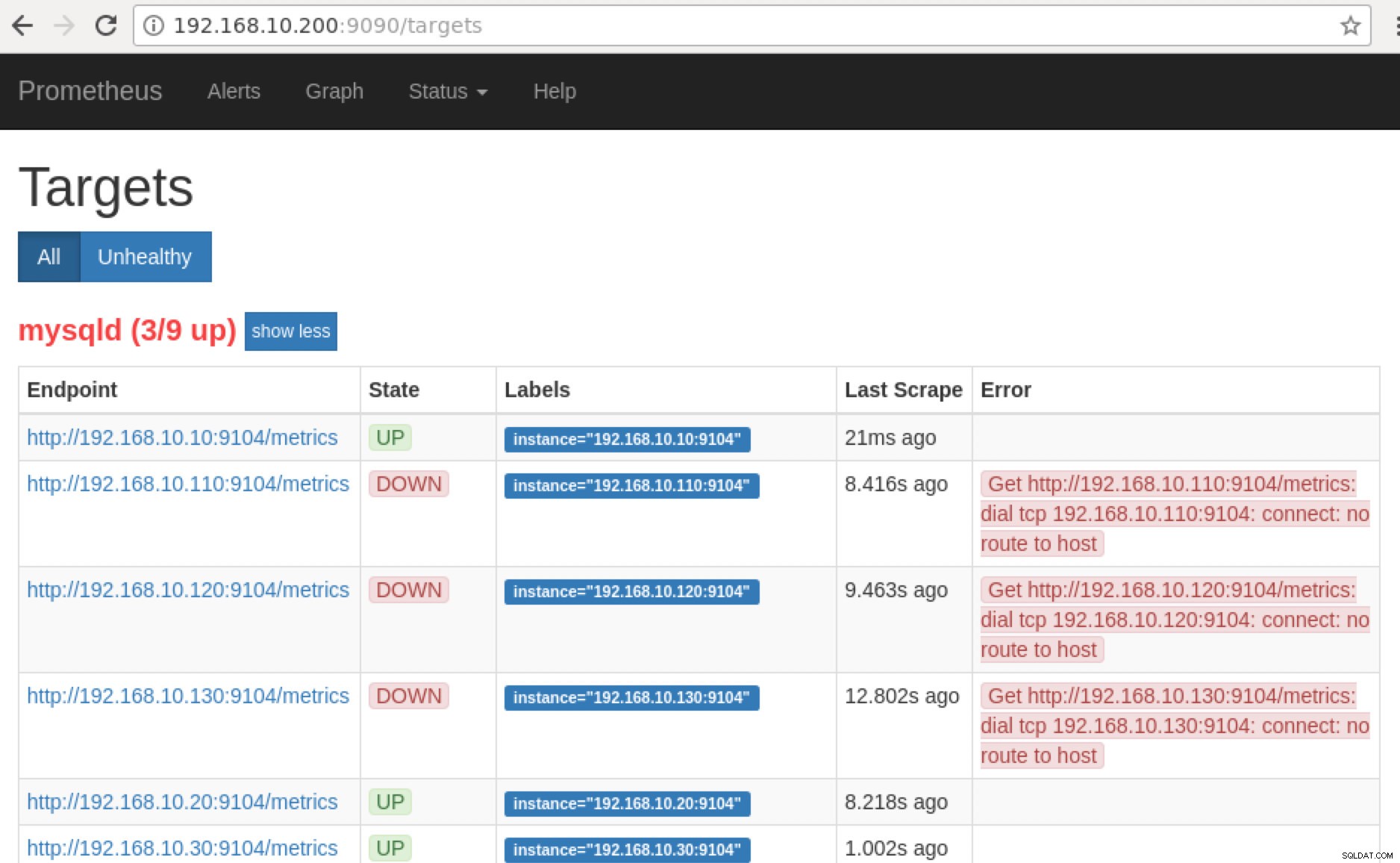
und auf „Endpoints“ klicken, können Sie die Metriken ebenso wie im folgenden Screenshot überprüfen:
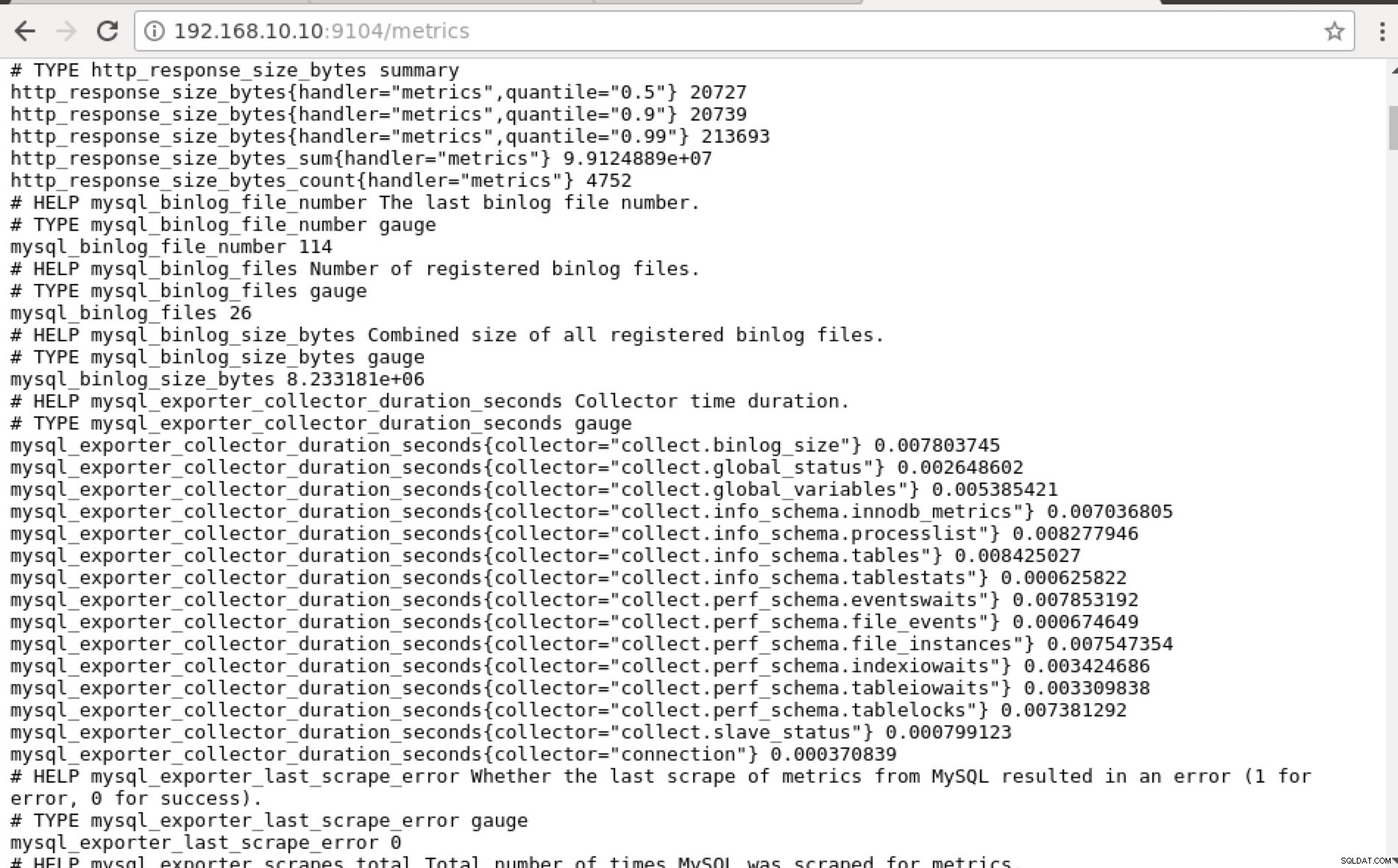
Anstatt die IP-Adresse zu verwenden, können Sie dies auch lokal über localhost auf diesem bestimmten Knoten überprüfen, z. B. indem Sie https://localhost:9104/metrics entweder in einer Web-UI-Oberfläche oder mit cURL aufrufen.
Gehen wir nun zurück zu den „Zielen ” sehen Sie die Liste der Knoten, bei denen ein Problem mit dem Port auftreten kann. Die Gründe, die dies verursachen könnten, sind unten aufgeführt:
- Server ist ausgefallen
- Netzwerk ist nicht erreichbar oder Ports nicht geöffnet, weil eine Firewall läuft
- Der Daemon läuft nicht dort, wo
_exporter Läuft nicht. Beispielsweise läuft mysqld_exporter nicht.
-
Wenn diese Exporter laufen, können Sie den Prozess mit dem Daemon starten und ausführen Befehl. Sie können sich auf die verfügbaren laufenden Prozesse beziehen, die ich im obigen Beispiel verwendet oder im vorherigen Abschnitt dieses Blogs erwähnt habe.
Was ist mit diesen „Keine Datenpunkte“-Grafiken in meinem Dashboard?
SCUMM-Dashboards bieten ein allgemeines Anwendungsszenario, das häufig von MySQL verwendet wird. Es gibt jedoch einige Variablen, wenn der Aufruf einer solchen Metrik in einer bestimmten MySQL-Version oder einem MySQL-Anbieter wie MariaDB oder Percona Server möglicherweise nicht verfügbar ist.
Lassen Sie mich unten ein Beispiel zeigen:
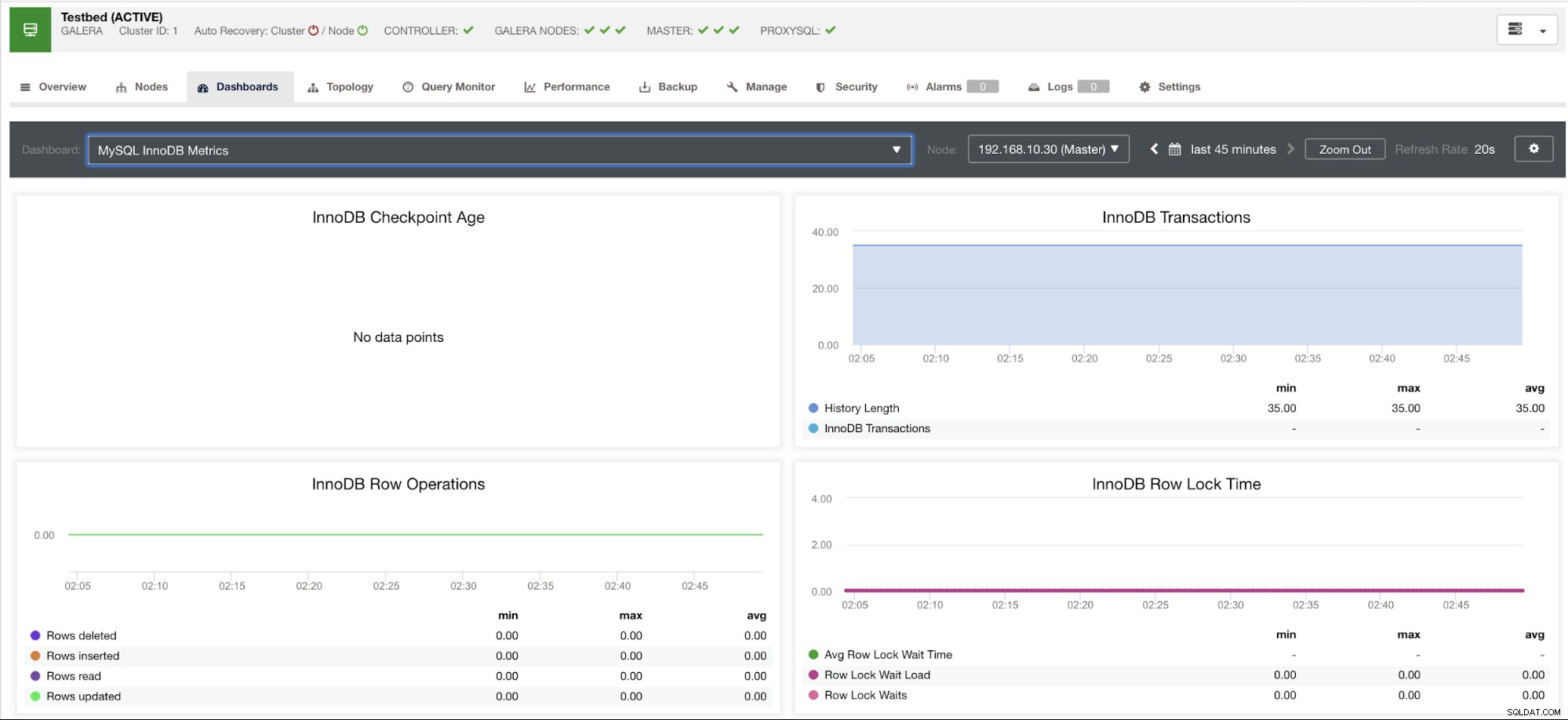
Dieses Diagramm wurde auf einem Datenbankserver erstellt, der auf einem MariaDB-Server der Version 10.3.9-MariaDB-log mit der wsrep_patch_version der wsrep_25.23-Instanz ausgeführt wird. Nun stellt sich die Frage, warum werden keine Datenpunkte geladen? Nun, als ich den Knoten nach einem Checkpoint-Altersstatus abgefragt habe, zeigt er, dass er leer ist oder keine Variable gefunden wurde. Siehe unten:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Ich habe keine Ahnung, warum MariaDB diese Variable nicht hat (bitte teilen Sie uns im Kommentarbereich dieses Blogs mit, wenn Sie die Antwort haben). Dies steht im Gegensatz zu einem Percona XtraDB Cluster Server, wo die Variable Innodb_checkpoint_max_age existiert. Siehe unten:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Das bedeutet jedoch, dass es Diagramme geben kann, in denen keine Datenpunkte gesammelt wurden, weil keine Daten zu dieser bestimmten Metrik gesammelt wurden, als eine Prometheus-Abfrage ausgeführt wurde.
Ein Diagramm ohne Datenpunkte bedeutet jedoch nicht, dass Ihre aktuelle Version von MySQL oder dessen Variante es nicht unterstützt. Beispielsweise gibt es bestimmte Diagramme, die bestimmte Variablen erfordern, die ordnungsgemäß eingerichtet oder aktiviert werden müssen.
Der folgende Abschnitt zeigt, was diese Diagramme sind.
Indexbedingungs-Pushdown-Diagramm (ICP)

Diese Grafik wurde in meinem vorherigen Blog erwähnt. Es stützt sich auf eine globale MySQL-Variable namens innodb_monitor_enable. Diese Variable ist dynamisch, sodass Sie sie ohne einen harten Neustart Ihrer MySQL-Datenbank festlegen können. Es erfordert auch innodb_monitor_enable =module_icp oder Sie können diese globale Variable auf innodb_monitor_enable =all setzen. Um solche Fälle und Verwirrung darüber zu vermeiden, warum ein solches Diagramm keine Datenpunkte anzeigt, müssen Sie in der Regel alle aber mit Vorsicht verwenden. Es kann einen gewissen Overhead geben, wenn diese Variable eingeschaltet und auf all gesetzt ist.
Diagramme des MySQL-Leistungsschemas
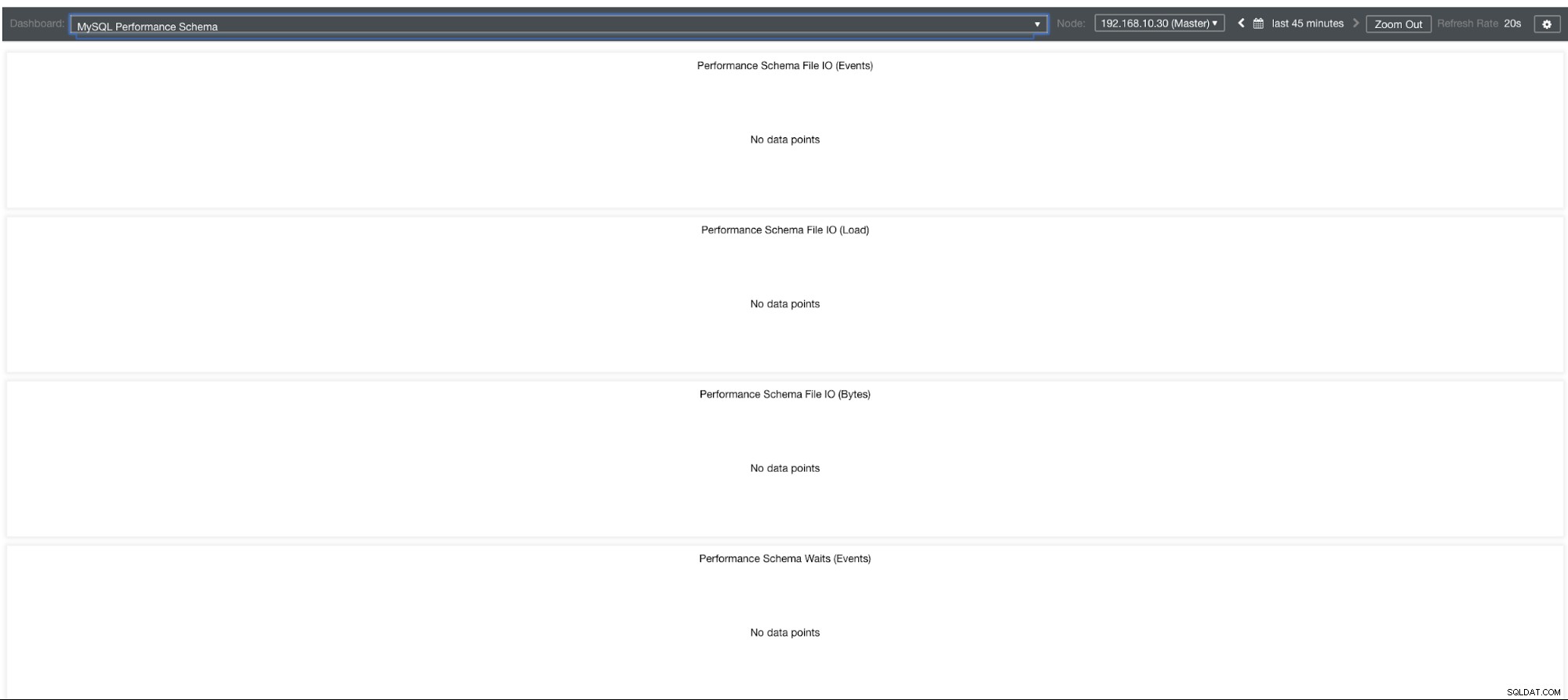
Warum zeigen diese Diagramme also „Keine Datenpunkte“? Wenn Sie einen Cluster mit ClusterControl unter Verwendung unserer Vorlagen erstellen, werden standardmäßig performance_schema-Variablen definiert. Beispielsweise werden die folgenden Variablen gesetzt:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Wenn jedoch performance_schema =OFF, dann ist dies der Grund, warum die zugehörigen Diagramme „Keine Datenpunkte“ anzeigen würden.
Aber ich habe performance_schema aktiviert, warum sind andere Diagramme immer noch ein Problem?
Nun, es gibt immer noch Diagramme, für die mehrere Variablen festgelegt werden müssen. Dies wurde bereits in unserem vorherigen Blog behandelt. Daher müssen Sie innodb_monitor_enable =all und userstat=1 setzen. Das Ergebnis würde so aussehen:
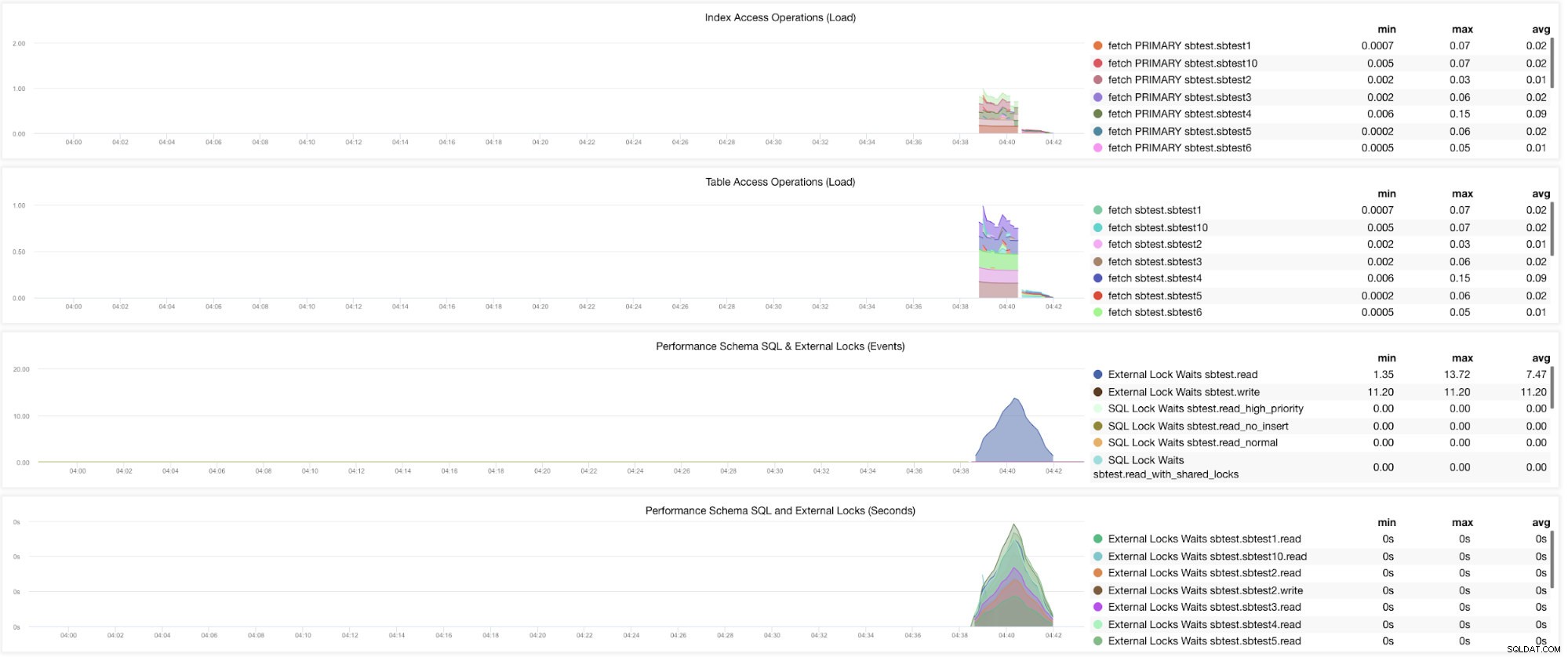
Ich stelle jedoch fest, dass in der Version von MariaDB 10.3 (insbesondere 10.3.11) die Einstellung performance_schema=ON die Metriken auffüllt, die für das MySQL Performance Schema Dashboard benötigt werden. Dies ist ein großer Vorteil, da innodb_monitor_enable=ON nicht gesetzt werden muss, was zusätzlichen Aufwand auf dem Datenbankserver verursachen würde.
Erweiterte Fehlerbehebung
Gibt es eine Fehlerbehebung im Voraus, die ich empfehlen kann? Ja da ist! Sie benötigen jedoch zumindest einige JavaScript-Kenntnisse. Da SCUMM-Dashboards, die Prometheus verwenden, auf Highcharts angewiesen sind, kann die Art und Weise, wie die Metriken für PromQL-Anfragen verwendet werden, durch das unten gezeigte app.js-Skript bestimmt werden:
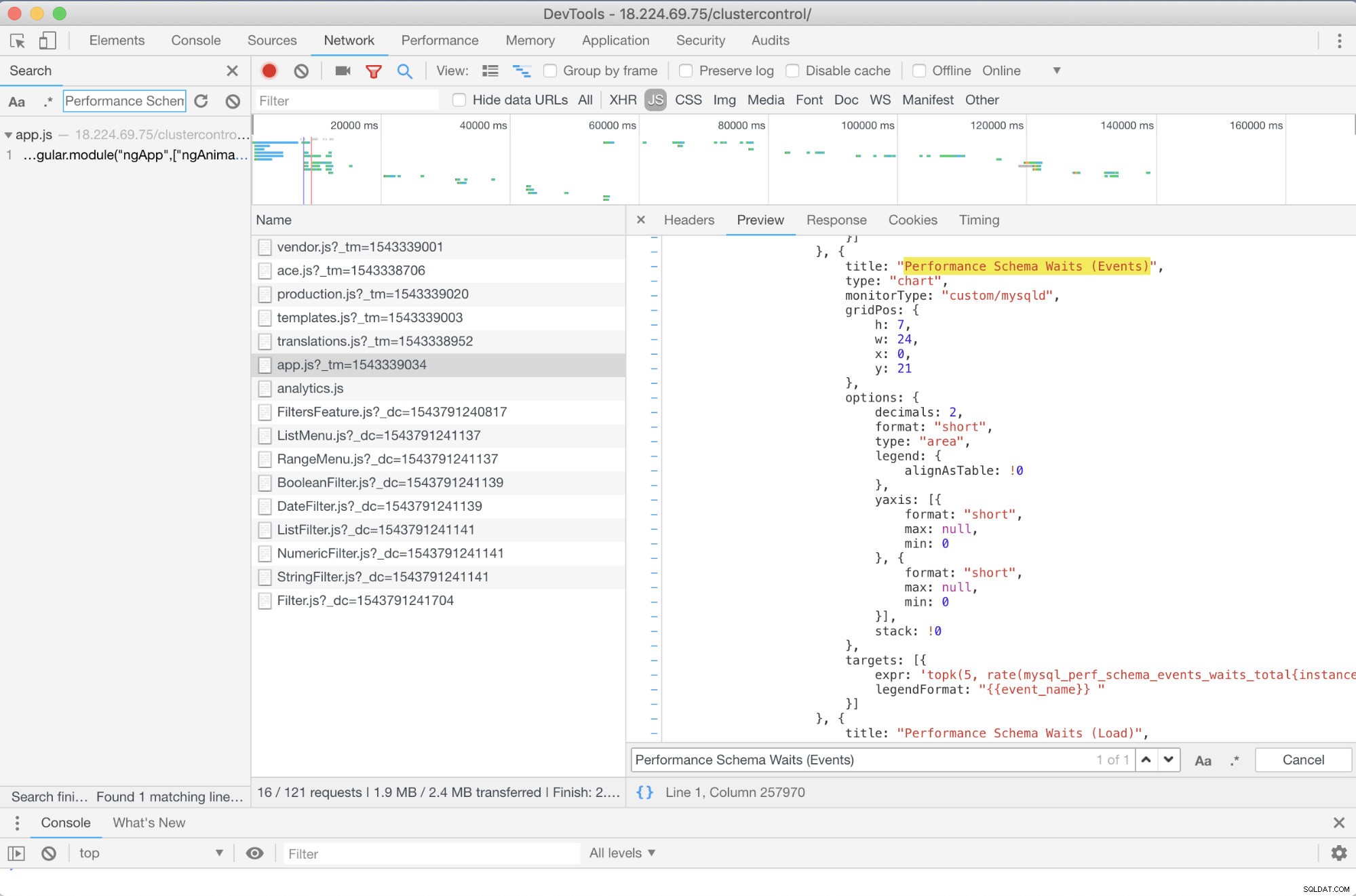
In diesem Fall verwende ich also die DevTools von Google Chrome und habe versucht, nach Performance Schema Waits (Events) zu suchen . Wie kann das helfen? Nun, wenn Sie sich die Ziele ansehen, sehen Sie:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Jetzt können Sie die angeforderten Metriken verwenden, nämlich mysql_perf_schema_events_waits_total. Sie können dies beispielsweise überprüfen, indem Sie https://
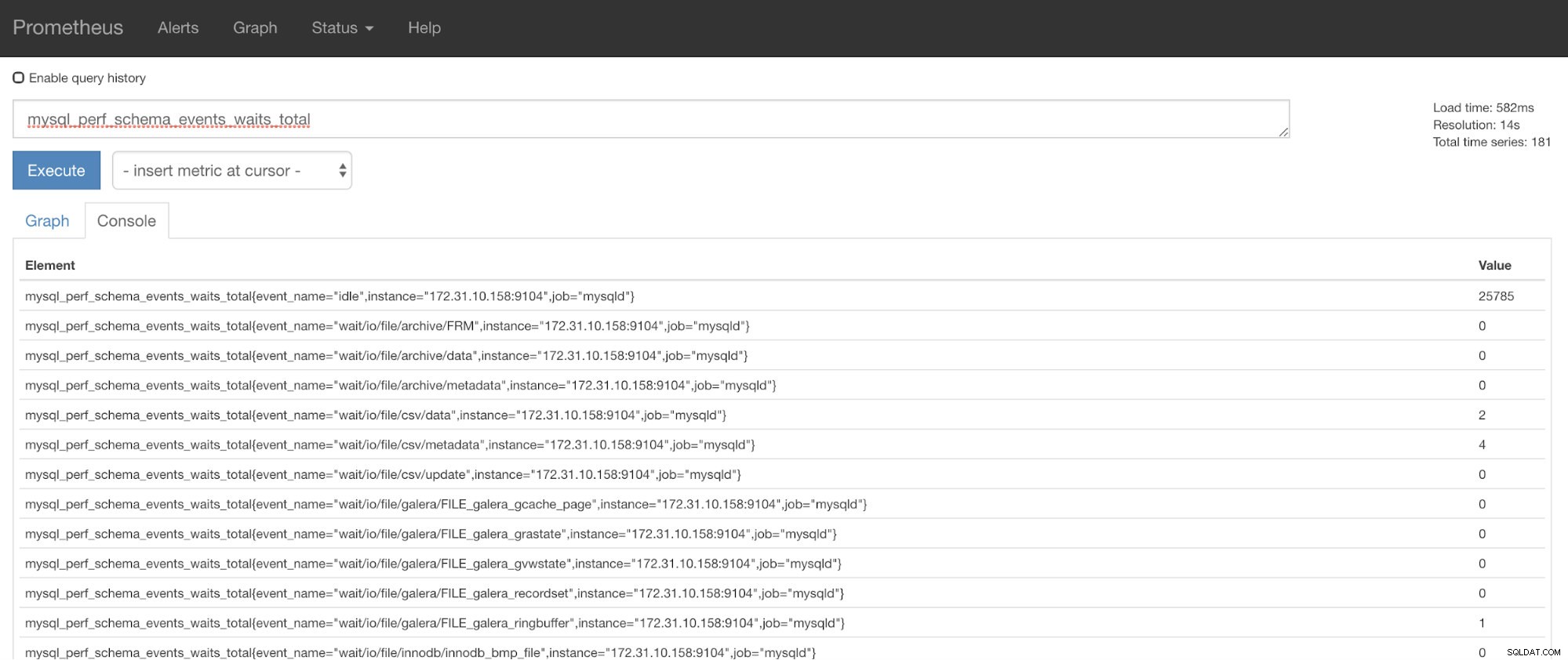
ClusterControl Auto-Recovery zur Rettung!
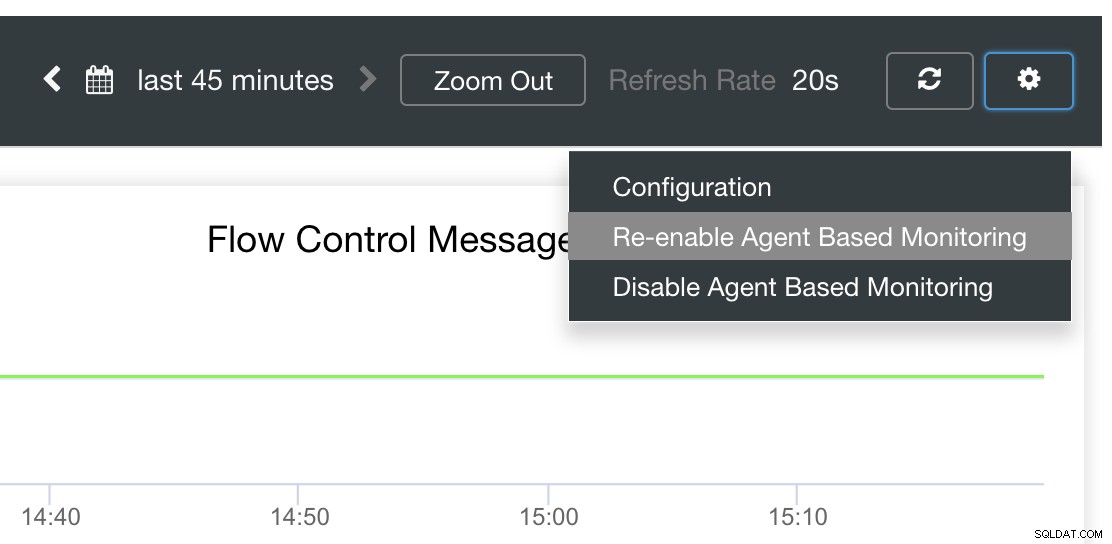
Schließlich ist die Hauptfrage, gibt es eine einfache Möglichkeit, fehlgeschlagene Exporter neu zu starten? Ja! Wir haben bereits erwähnt, dass ClusterControl den Status der Exporte überwacht und sie bei Bedarf neu startet. Falls Sie bemerken, dass SCUMM-Dashboards Diagramme nicht normal laden, stellen Sie sicher, dass Sie die automatische Wiederherstellung aktiviert haben. Siehe folgendes Bild:

Wenn dies aktiviert ist, stellt dies sicher, dass die Datei
Es ist auch möglich, die Exporter neu zu installieren oder neu zu konfigurieren.
Schlussfolgerung
In diesem Blog haben wir gesehen, wie ClusterControl Prometheus verwendet, um SCUMM-Dashboards anzubieten. Es bietet eine Reihe leistungsstarker Funktionen, von hochauflösenden Überwachungsdaten bis hin zu umfangreichen Grafiken. Sie haben gelernt, dass Sie mit PromQL unsere SCUMM-Dashboards bestimmen und Fehler beheben können, mit denen Sie Zeitreihendaten in Echtzeit aggregieren können. Sie können auch Diagramme erstellen oder alle gesammelten Metriken über die Konsole anzeigen.
Sie haben auch gelernt, wie Sie unsere SCUMM-Dashboards debuggen, insbesondere wenn keine Datenpunkte erfasst werden.
Wenn Sie Fragen haben, fügen Sie bitte Ihre Kommentare hinzu oder lassen Sie es uns über unsere Community-Foren wissen.