Leistung ist in jedem System immer wichtig. Sie müssen die verfügbaren Ressourcen gut nutzen, um die bestmögliche Reaktionszeit zu gewährleisten, und es gibt verschiedene Möglichkeiten, dies zu tun. Jede Verbindung zu einer Datenbank verbraucht Ressourcen, daher besteht eine dieser Möglichkeiten darin, einen guten Verbindungsmanager zwischen Ihrer Anwendung und der Datenbank zu haben. In diesem Blog werden wir über pgBouncer sprechen, einen Verbindungspooler für PostgreSQL, und wir werden zeigen, wie Sie dies implementieren können, um Ihre PostgreSQL-Leistung zu verbessern.
Verbindungspooler
Abhängig vom Datenverkehr Ihrer Systeme kann es sinnvoll sein, ein externes Tool hinzuzufügen, um die Belastung Ihrer Datenbank zu verringern und die Leistung zu verbessern. Vielleicht ist es nicht genug, aber es ist ein guter Ausgangspunkt. Zu diesem Zweck ist es eine gute Idee, einen Verbindungspooler
zu implementierenEin Verbindungspooling ist eine Methode, einen Pool von Verbindungen zu erstellen und diese wiederzuverwenden, wodurch vermieden wird, ständig neue Verbindungen zur Datenbank zu öffnen, was die Leistung Ihrer Anwendungen erheblich steigern wird. PgBouncer ist ein beliebter Verbindungspooler, der für PostgreSQL entwickelt wurde.
Wie PgBouncer funktioniert
PgBouncer fungiert als PostgreSQL-Server, Sie müssen also nur mit den PgBouncer-Informationen (IP-Adresse/Hostname und Port) auf Ihre Datenbank zugreifen, und PgBouncer stellt eine Verbindung zum PostgreSQL-Server her, oder es wird wiederverwenden, falls vorhanden.
Wenn PgBouncer eine Verbindung erhält, führt es die Authentifizierung durch, die von der in der Konfigurationsdatei angegebenen Methode abhängt. PgBouncer unterstützt alle Authentifizierungsmechanismen, die der PostgreSQL-Server unterstützt. Danach sucht PgBouncer nach einer zwischengespeicherten Verbindung mit derselben Kombination aus Benutzername und Datenbank. Wenn eine zwischengespeicherte Verbindung gefunden wird, gibt es die Verbindung an den Client zurück, wenn nicht, erstellt es eine neue Verbindung. Abhängig von der PgBouncer-Konfiguration und der Anzahl aktiver Verbindungen kann es möglich sein, dass die neue Verbindung in die Warteschlange gestellt wird, bis sie erstellt werden kann, oder sogar abgebrochen wird.
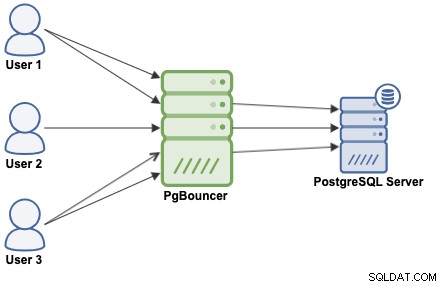
Das PgBouncer-Verhalten hängt vom konfigurierten Pooling-Modus ab:
-
session pooling (default):Wenn sich ein Client verbindet, wird ihm für das Ganze eine Serververbindung zugewiesen Dauer, während der der Client verbunden bleibt. Wenn der Client die Verbindung trennt, wird die Serververbindung wieder in den Pool gestellt.
-
Transaktionspooling:Eine Serververbindung wird einem Client nur während einer Transaktion zugewiesen. Wenn PgBouncer feststellt, dass die Transaktion beendet ist, wird die Serververbindung wieder in den Pool gestellt.
-
Anweisungspooling:Die Serververbindung wird unmittelbar nach Abschluss einer Abfrage wieder in den Pool gestellt. Transaktionen mit mehreren Anweisungen sind in diesem Modus nicht zulässig, da sie beschädigt würden.
Wie man PgBouncer mit ClusterControl implementiert
Dazu gehen wir davon aus, dass Sie Ihren PostgreSQL-Cluster in Betrieb haben und ClusterControl verwenden, um ihn zu verwalten. Andernfalls können Sie diesem Blogpost folgen, um PostgreSQL für Hochverfügbarkeit einfach bereitzustellen.
Gehen Sie zu ClusterControl -> PostgreSQL-Cluster auswählen -> Cluster-Aktionen -> Load Balancer hinzufügen -> PgBouncer. Dort können Sie einen neuen PgBouncer-Knoten bereitstellen, der im ausgewählten Datenbankknoten bereitgestellt wird, oder sogar einen vorhandenen PgBouncer-Knoten importieren.
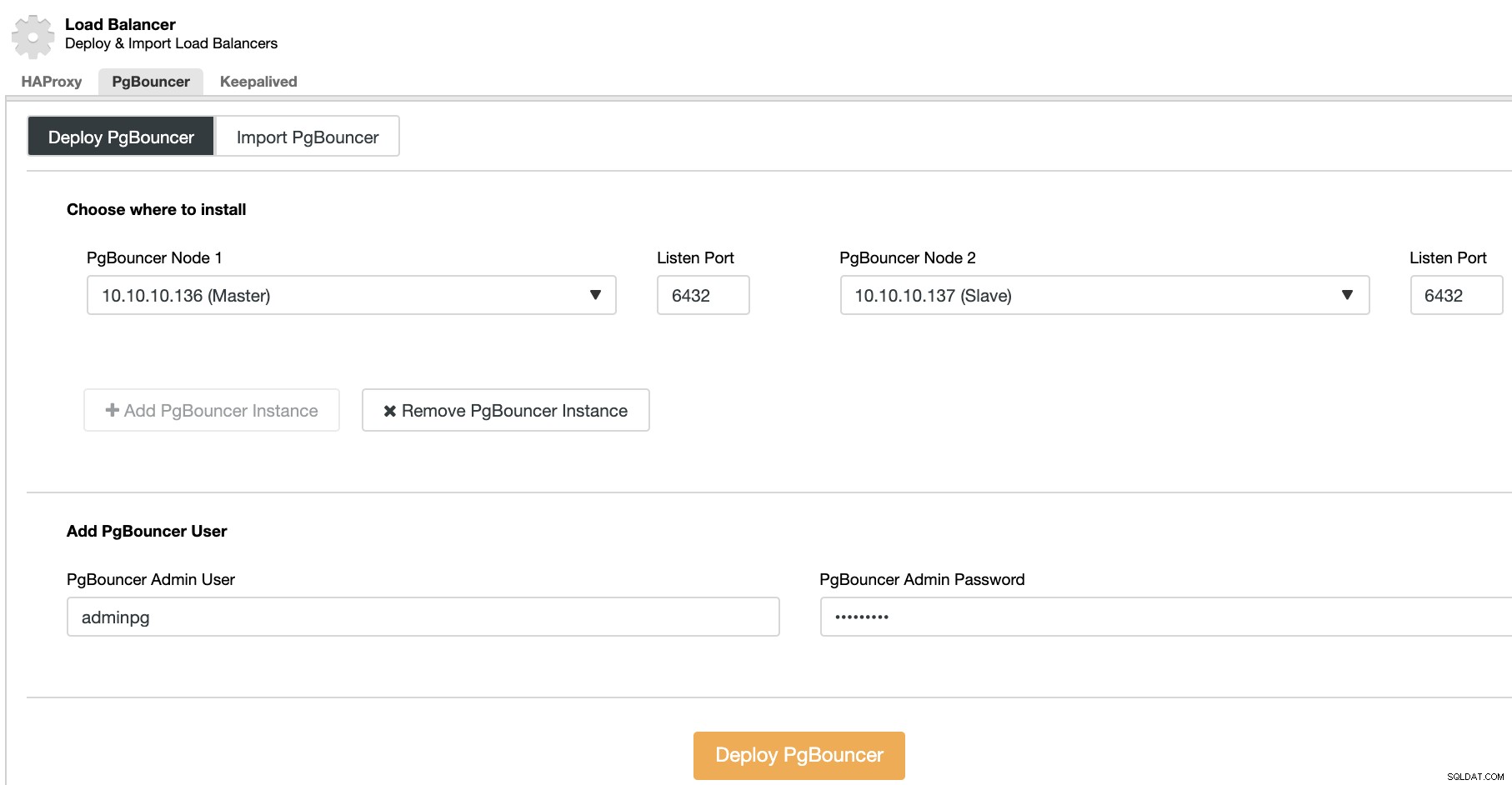
Sie müssen die IP-Adresse oder den Hostnamen, den Listen-Port und den PgBouncer angeben Referenzen. Wenn Sie auf Deploy PgBouncer klicken, greift ClusterControl auf den Knoten zu, installiert und konfiguriert alles ohne manuellen Eingriff.
Sie können den Fortschritt im Aktivitätsbereich von ClusterControl überwachen. Wenn es fertig ist, müssen Sie den neuen Pool erstellen. Gehen Sie dazu zu ClusterControl -> Select the PostgreSQL cluster -> Nodes -> PgBouncer Node.
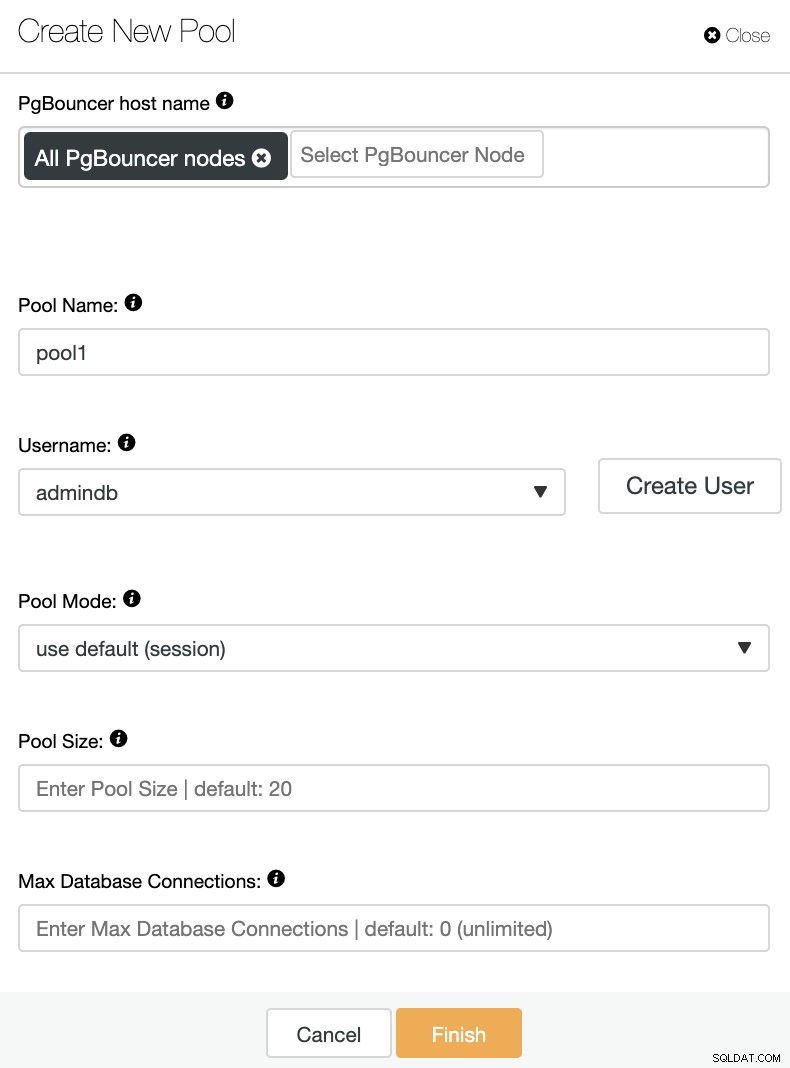
Hier müssen Sie die folgenden Informationen hinzufügen:
-
PgBouncer-Hostname:Wählen Sie die Knotenhosts aus, um den Verbindungspool zu erstellen.
-
Poolname:Pool- und Datenbanknamen müssen identisch sein.
-
Benutzername: Wählen Sie einen Benutzer aus dem primären PostgreSQL-Knoten aus oder erstellen Sie einen neuen.
-
Pool-Modus:Dies kann einer der zuvor erwähnten Modi sein:Sitzung (Standard), Transaktion, oder Statement-Pooling.
-
Pool-Größe:Maximale Größe der Pools für diese Datenbank. Der Standardwert ist 20.
-
Max Datenbankverbindungen:Konfigurieren Sie ein datenbankweites Maximum. Der Standardwert ist 0, was unbegrenzt bedeutet.
Jetzt sollten Sie den Pool im Node-Bereich sehen können.
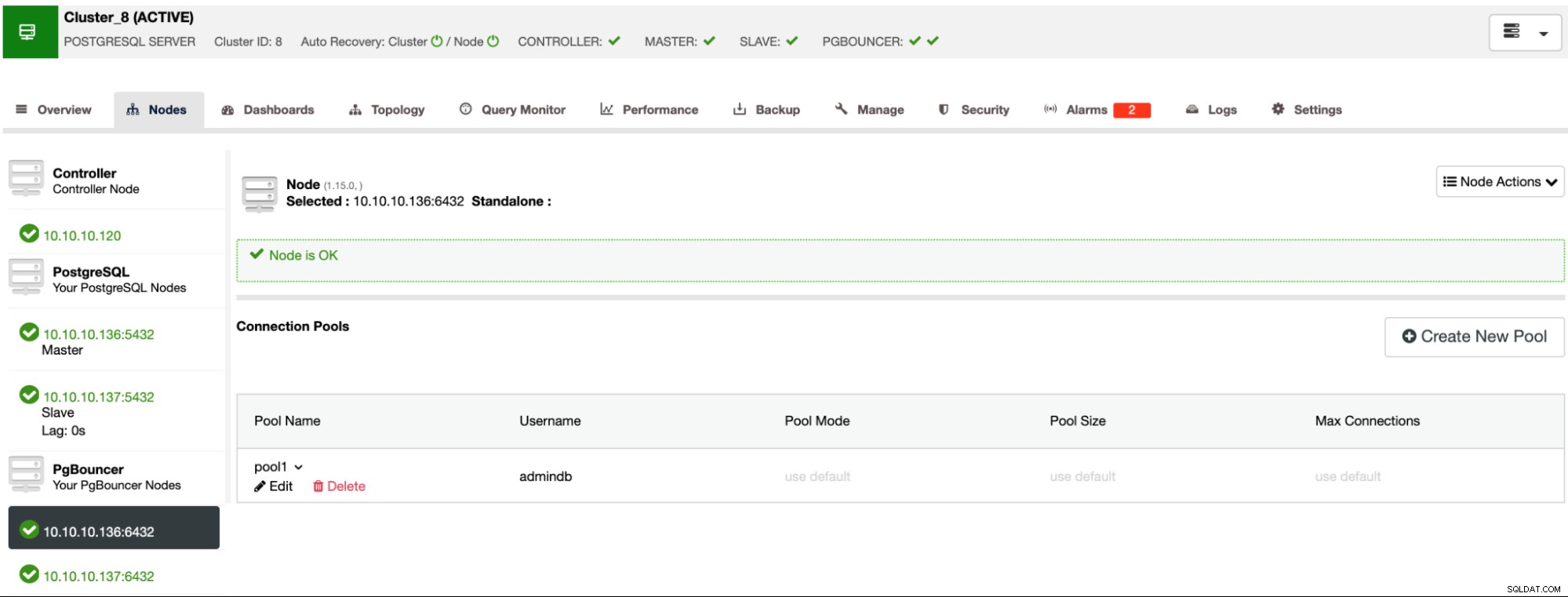
Dies ist eine grundlegende Topologie. Sie können es verbessern, indem Sie beispielsweise Load Balancer-Knoten hinzufügen, mehr als einen, um einen einzelnen Fehlerpunkt zu vermeiden, und ein Tool wie „Keepalived“ verwenden, um die Verfügbarkeit sicherzustellen. Dies kann auch mit ClusterControl erfolgen.
Fazit
Die Verwendung von PgBouncer als Verbindungspooler ist eine gute Möglichkeit, die Datenbankleistung zu verbessern, indem die verfügbaren Ressourcen auf dem Server gut genutzt werden.
Sie können diese Topologie auch verbessern, indem Sie eine Kombination aus PgBouncer + HAProxy verwenden, um Hochverfügbarkeit für Ihren PostgreSQL-Cluster zu erreichen. All diese Dinge können über dieselbe ClusterControl-Benutzeroberfläche erledigt werden.



