In unseren früheren Hybrid-Cloud-Blogs erwähnen wir oft, dass eine der Hauptoptionen für die Nutzung der Hybrid-Cloud-Topologie darin besteht, diese als Ziel für die Notfallwiederherstellung zu verwenden. Es ist für eine Organisationsstruktur üblich, dass ein Notfallwiederherstellungsplan (DRP) immer vor der architektonischen Implementierung Ihrer Datenbankeinrichtung in Angriff genommen wird, entweder in der Cloud oder vor Ort. Sie denken vielleicht, dass alles unvorhersehbar scheitern und Ihr Geschäft tragisch beeinflussen kann, wenn es nicht richtig angegangen und verstanden wird. Die Bewältigung dieser Herausforderungen erfordert einen effektiven DRP (Disaster Recovery Plan), für den Ihr System gemäß Ihrer Anwendung, Infrastruktur und Ihren Geschäftsanforderungen gut konfiguriert ist. Der Schlüssel zum Erfolg in solchen Situationen ist, wie schnell wir das Problem beheben oder beheben können.
Während DRP sich um die Katastrophenumstände kümmert, stellt Business Continuity sicher, dass DRP bei Bedarf jederzeit getestet und betriebsbereit ist. Ihre Disaster Recovery-Optionen für Ihre Datenbanken müssen einen kontinuierlichen Betrieb sicherstellen und an die Grenzen der Erwartungen gehen. Es muss mit Ihrer gewünschten RTO und RPO übereinstimmen. Es muss unbedingt sichergestellt werden, dass Produktionsdatenbanken für die Anwendungen auch im Katastrophenfall verfügbar sind; Andernfalls könnte es zu einem teuren Geschäft werden. DBAs, die Architekten, müssen sicherstellen, dass Datenbankumgebungen Katastrophen standhalten und die SLAs für die Notfallwiederherstellung erfüllen. Datenbankbereitstellungen müssen korrekt konfiguriert werden, um sicherzustellen, dass Katastrophen die Datenbankverfügbarkeit und die Geschäftskontinuität nicht beeinträchtigen.
Optionen für die Notfallwiederherstellung
Ihr PostgreSQL-Cluster muss mit einem systematischen Ansatz konfiguriert werden, der den Best Practices verpflichtet und den Industriestandards entspricht. Neben den systematischen Ansätzen helfen Ihnen die folgenden Prozesse oder Mechanismen sicherzustellen, dass Ihr in einer Hybrid Cloud bereitgestelltes PostgreSQL diese Präsenzen aufweist:
-
Failover/Switchover
-
Automatisierte Sicherung
-
Hochverfügbar
-
Load-Balancing
-
Hochverteilte Umgebung
Failover/Switchover
Failover ist ein automatisierter Prozess, falls Ihr Master ausfällt; Entweder der Hot-Standby- oder der Warm-Standby-Server wird in die Rolle des Primär-/Master-Servers hochgestuft. Es ist eine bewährte Methode, die es einer Umgebung mit hoher Verfügbarkeit ermöglicht, mindestens einen sekundären Knoten zu haben, der als Kandidat für einen Failover-Knoten fungiert. Sobald der primäre Server ausfällt, sollte der Standby-Server mit den Failover-Prozeduren beginnen, und dann übernimmt der sekundäre oder Standby-Server die Rolle eines Masters. Ein Failover-System verwendet in der Regel mindestens zwei Server, die als Primär- und Standby-Server dienen. Seine Konnektivitätsprüfung wird durch einen Heartbeat-Mechanismus unterstützt, der ununterbrochene Prüfungen durchführt und überprüft, ob beide in einem guten Zustand sind und die Kommunikation aktiv ist. In einigen Fällen kann die Konnektivität jedoch einen Fehlalarm auslösen. Daher befindet sich in einigen Setups und Umgebungen das Vorhandensein eines dritten Systems, wie z. B. eines Überwachungsknotens, in einem separaten Netzwerk oder Rechenzentrum. Dies ist eine narrensichere Option, um ein unangemessenes oder unerwünschtes Failover zu verhindern. Ein narrensicherer Verifizierungsknoten kann zusätzliche Funktionen und Prüfungen besitzen, was die Komplexität erhöht. Dieses Setup erfordert vollständige und strenge Tests, um sicherzustellen, dass das Failover richtig durchgeführt wird, wenn es eine Änderung in der Implementierung gibt. Dies ist auch wichtig, um eine Verschlechterung Ihres PostgreSQL zu verhindern
Nehmen wir an, Sie haben Ihren sekundären oder Standby-Cluster in einem anderen Rechenzentrum mit einem anderen Hardware-Setup; Möglicherweise möchten Sie kein abruptes Failover durchführen, insbesondere wenn dies aufgrund eines Fehlalarms kein Idealfall ist. In diesem Szenario muss Ihr Datenwiederherstellungszielknoten oder -cluster jedoch über dieselben Ressourcen und Spezifikationen wie Ihr primärer Knoten oder Cluster verfügen. Wenn sich Ihr Datenwiederherstellungsziel in einer öffentlichen Cloud und das primäre lokal befindet, stellen Sie sicher, dass es bereits in Ihrer Kapazitätsplanung berücksichtigt wurde und die Ressourcen fast die gleichen Spezifikationen haben, um unerwünschte Ergebnisse zu vermeiden.
Wenn Sie Ihren Failover-Mechanismus in Ihrem PostgreSQL-Cluster innerhalb einer Hybrid Cloud nutzen und vorbereiten, müssen Sie sicherstellen, dass Ihr Tool perfekt geeignet ist, um die Aufgabe zu erfüllen, die erreicht werden soll. Es gibt Tools von Drittanbietern, die im Hinblick auf erweitertes Failover nicht in PostgreSQL gebündelt sind. Da sind zum Beispiel ClusterControl, pg_auto_failover von CitusData (c/o Microsoft), Pgpool-II, Bucardo und andere. Diese fortschrittlichen Dienstprogramme bieten Node Fencing oder bekannt als STONITH (Shoot the other Node in the Head). Dadurch wird sichergestellt, dass Ihr ausgefallener Primär- oder Master-Knoten keine Schreibvorgänge akzeptiert oder wieder in seinen vorherigen Zustand zurückkehrt, um normale Transaktionen zu bedienen. Dieses Problem wird allgemein als Split-Brain-Szenario bezeichnet. Die Datensynchronisierung geht aufgrund eines Fehlers (Hardware- oder Ressourcenebene) verloren, aber Ihre primären Server, bei denen es sich angeblich nur um einen primären Server handelt, verhalten sich immer noch so, als würden sie normale Empfänger von Datenschreibanforderungen tun, was eine clusterweite Datenbeschädigung verursacht.
Automatisierte Sicherung
Backups bieten immer eine hohe Sicherheit und Schutz vor Datenverlust. Backup maximiert Ihre RPO, da es hilft, Datenverluste im Katastrophenfall zu minimieren. Dinge, die Sie für Ihr automatisiertes Backup berücksichtigen und vorbereiten müssen, umfassen Ihre Backup-Appliance/-Hardware, Backup-Datenredundanz, Sicherheit, Leistung, Geschwindigkeit und Datenspeicherung.
Backup-Appliance
Sie müssen hier die beste Wahl für Ihre Backup-Appliance haben. Geschwindigkeit, erhebliches Speichervolumen und hohe Verfügbarkeit können Ihre gewünschte Wahl sein. Einige verlassen sich auf SAN- oder NAS-Speicher oder verteilen ihre Daten auf andere externe Backup-Speicheranbieter. Es ist wichtig, dass Ihre Backup-Appliance Geschwindigkeit zum Schreiben und Lesen von Daten bietet, insbesondere wenn Sie Komprimierung und Verschlüsselung für Ihre Daten im Ruhezustand anwenden. Dekomprimierung und Entschlüsselung erfordern Ressourcen, daher müssen Sie überlegen, wann Sie die Datenwiederherstellung verwenden müssen. In diesem Zustand müssen Sie feststellen, dass Sie Ihr maximales RPO erreichen und Ihren Kunden das erreichbare SLA (Service-Level-Agreement) zusagen müssen. Es ist auch ideal, dass Sie Ihr Backup möglicherweise von Ihrem lokalen Netzwerk isolieren oder an einem entfernten Ort speichern müssen. Ein alternativer Ansatz ist die Zusammenarbeit mit Drittanbietern. Zum Beispiel kann das Speichern Ihres Backups in der Cloud eine Option sein, und ihre Einrichtung ist hochentwickelt und erfüllt Ihre Anforderungen.
Backup-Datenredundanz
Die Verteilung Ihrer Daten auf mehrere Standorte ist eine ideale Lösung. Dies erhöht Ihre Datenwiederherstellungschancen, z. B. wenn ein menschlicher Fehler oder ein Softwarelogikfehler dazu führt, dass Sie alte Sicherungskopien löschen, aber fälschlicherweise die gesamten wichtigen Sicherungskopien löschen. In einigen anspruchsvollen Umgebungen, z. B. beim Speichern in einer Cloud-Umgebung wie Amazon S3, bietet Cloud Storage von Google oder Azure Blob Storage die Replikation Ihrer gespeicherten Datei an. Dies bietet mehr Redundanz und kann flexibel nach Ihren Anforderungen eingerichtet werden.
Hochverfügbar
Ein hochverfügbarer PostgreSQL-Cluster in einer Hybrid Cloud stellt immer sicher, dass Ihre Datenbankkommunikation die Verfügbarkeit gewährleistet. Der Idealfall der Hochverfügbarkeit hängt von der Messung Ihrer Verfügbarkeit ab. In diesem Fall kann ein übliches Setup für ein in einer Hybrid Cloud bereitgestelltes PostgreSQL entweder Ihre in einer öffentlichen Cloud gehostete Datenbank sein Ihr sekundärer Cluster sein, der als Ihr Datenwiederherstellungscluster fungiert, falls der primäre Cluster ausfällt oder eine Netzwerkkatastrophe erleidet und dauern kann viel Ausfallzeit. Bei einigen Konfigurationen ist es möglich, dass der sekundäre Cluster in der öffentlichen Cloud nicht genau so ausgereift ist wie der primäre, sagen wir, dies ist Ihre lokale oder private Cloud. Ihre Anwendung kann herumspielen, um die Besucher oder den Datenverkehr zu begrenzen, die eine Verbindung zu Ihrer Datenbank herstellen können. Diese Art von Szenario kann Ihre Einrichtungskosten senken, aber dies hängt natürlich nur von Ihren Anforderungen ab. Wenn Ihr Anwendungstyp massiv ist und ununterbrochen normale bis ausgelastete Verkehrssituationen empfangen muss, stellen Sie sicher, dass Ihre sekundären Cluster-Ressourcen so leistungsfähig wie die primären sein müssen, um eine hohe Verfügbarkeit zu gewährleisten, d. h. 99,9999999 %.
Um einen hochverfügbaren PostgreSQL-Cluster in einer Hybrid-Cloud-Umgebung zu erreichen, benötigen Sie einen Failover-Mechanismus. Im Falle eines Ausfalls und Ausfall eines primären Clusters oder primären Servers kann ein sekundärer oder Standby-Server unabhängig von seinem Standort die Rolle eines Masters übernehmen. Das Wichtigste ist, dass die Funktionalität und die Leistung, insbesondere aus Sicht der Anwendung oder des Clients, überhaupt nicht oder zumindest sehr minimal beeinträchtigt werden.
Lastenausgleich
Der Lastausgleichsmechanismus für Ihren PostgreSQL-Cluster unterstützt Ihr Hybrid-Cloud-Setup, das besser zu verwalten und weniger riskant ist, insbesondere wenn eine hohe Verkehrslast auftritt. In vielen Situationen wird ein Server stark ausgelastet, wodurch der Server in Panik gerät. Dies führt zu einem unbrauchbaren Zustand des Servers aufgrund ausgelasteter Ressourcen, die von vielen Threads verbraucht werden, die im Hintergrund ausgeführt werden. Diese Situation kann verbessert werden, indem fehlerhafte Abfragen und die Designarchitektur Ihrer Datenbank korrigiert werden. Dies sollte beinhalten, wie Sie die Lese- und Schreiblast verteilen, und ein tiefes Verständnis Ihrer Anwendungsanforderungen wie Master-Master-Setup oder nur ein Master, aber vertikales Skalieren, um höhere Rechen- und Speicherressourcen bereitzustellen. Es gibt auch eine große Auswahl an Tools von Drittanbietern wie pgbouncer und Pgpool II, um Ihre PostgreSQL-Bereitstellung in einer hybriden Cloud-Umgebung zu unterstützen.
Hochverteilte Umgebung
In Bezug auf die Skalierbarkeit bietet eine hohe Verteilung an mehreren Standorten oder verschiedenen Cloud-Anbietern (lokal oder private und öffentliche Cloud) mehr Flexibilität und Verträglichkeit in einer hybriden Cloud-Umgebung, was sich hervorragend für die Notfallwiederherstellung eignet. Es ist flexibel, wenn ein Failover auf einen bestimmten Cloud-Standort erforderlich ist, der für Naturkatastrophen oder Katastrophen günstig ist, insbesondere wenn Ihre bestimmte Region, in der sich Ihr primärer Cluster befindet, derzeit verwüstet oder von einer natürlichen Ursache betroffen ist. Dies ist eine unvermeidliche Ursache, die Sie verstehen und auf die aktuelle Situation vertrauen müssen. Ihre Anwendung und Ihre Kunden müssen kontinuierlich nonstop bedient werden. Dies dient dem Zweck, öffentlich in der Cloud verfügbar zu sein und gleichzeitig in einer privaten oder lokalen Umgebung zu dienen. Dieses Setup erhöht die Komplexität und erfordert fortgeschrittene Kenntnisse auf der Datenbankseite sowie in den Bereichen Sicherheit und Netzwerk. Optimierung und Tuning sind hier erfolgsentscheidend, da es sehr wichtig ist, dass die Leistung zwar eine strengere Sicherheit bietet, um Ihre Daten zu kapseln, während Sie im Internet unterwegs sind, sich aber nachweislich stabilisieren muss und nicht durch das implementierte Setup beeinträchtigt wird.
Aufgrund der Komplexität der Einrichtung ist ein Tool ideal, um die Bereitstellung zu verwalten und den Gesamtstatus Ihrer Datenbanken zu erleichtern, indem es einen Aspekt Ihres Clusters überwacht, aber auf der gesamten Ebene von der lokalen, privaten Cloud, und zum Public-Cloud-Aspekt. Alle Einstellungen müssen auf einem überschaubaren und unkomplizierten Niveau gehalten werden, damit es im Falle von Alarmen und Warnungen einfach ist, das Problem richtig und zeitnah zu beheben und zu beheben.
ClusterControl für die Notfallwiederherstellung in einer Hybrid-Cloud-Umgebung
ClusterControl ermöglicht es der Organisation oder den Unternehmen, die Datenbank flexibel zu verwalten und die Gesamtkomplexität des Setups zu reduzieren. ClusterControl bietet Failover, automatisiertes Backup, bietet eine hochverfügbare Einrichtung, Lastausgleich und unterstützt die Bereitstellung einer verteilten Umgebung, wodurch es einfacher wird, Knoten entweder in einer öffentlichen Cloud oder privat oder vor Ort hinzuzufügen.
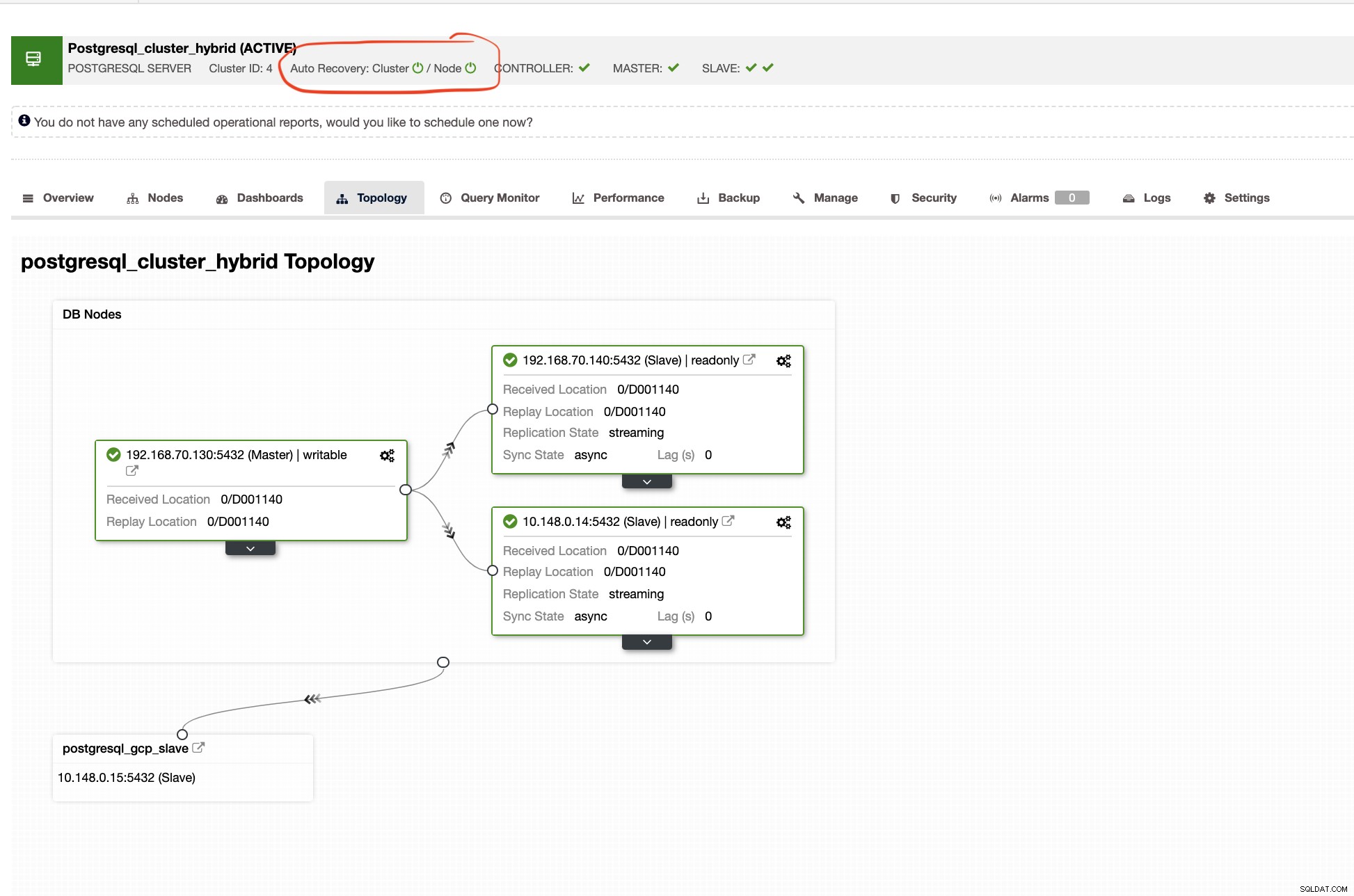
Automatische ClusterControl-Wiederherstellung
Die automatische Wiederherstellung von ClusterControl stellt unzählige Failover-Mechanismen und Wiederherstellungsmerkmale dar, insbesondere wenn ein Knoten ausfällt oder ein Cluster in einen herabgesetzten Zustand übergeht. Das geht ganz einfach, wie im Screenshot unten gezeigt:
Sichern und Wiederherstellen
ClusterControl hat auch eine Sicherungs- und Wiederherstellungsfunktion, mit der Sie Ihre Sicherung verwalten, eine Sicherung erstellen, eine Sicherung planen und eine Sicherung wiederherstellen können. Die Verwaltung Ihres Backups ist sehr einfach und das Erstellen oder Planen eines Backups ist einfach, bietet aber auch erweiterte Optionen. Es bietet auch Cloud-Backup-Optionen, die Ihnen eine Redundanz der Backup-Daten ermöglichen und Ihre Disaster-Recovery-Optionen stärken. Siehe unten:
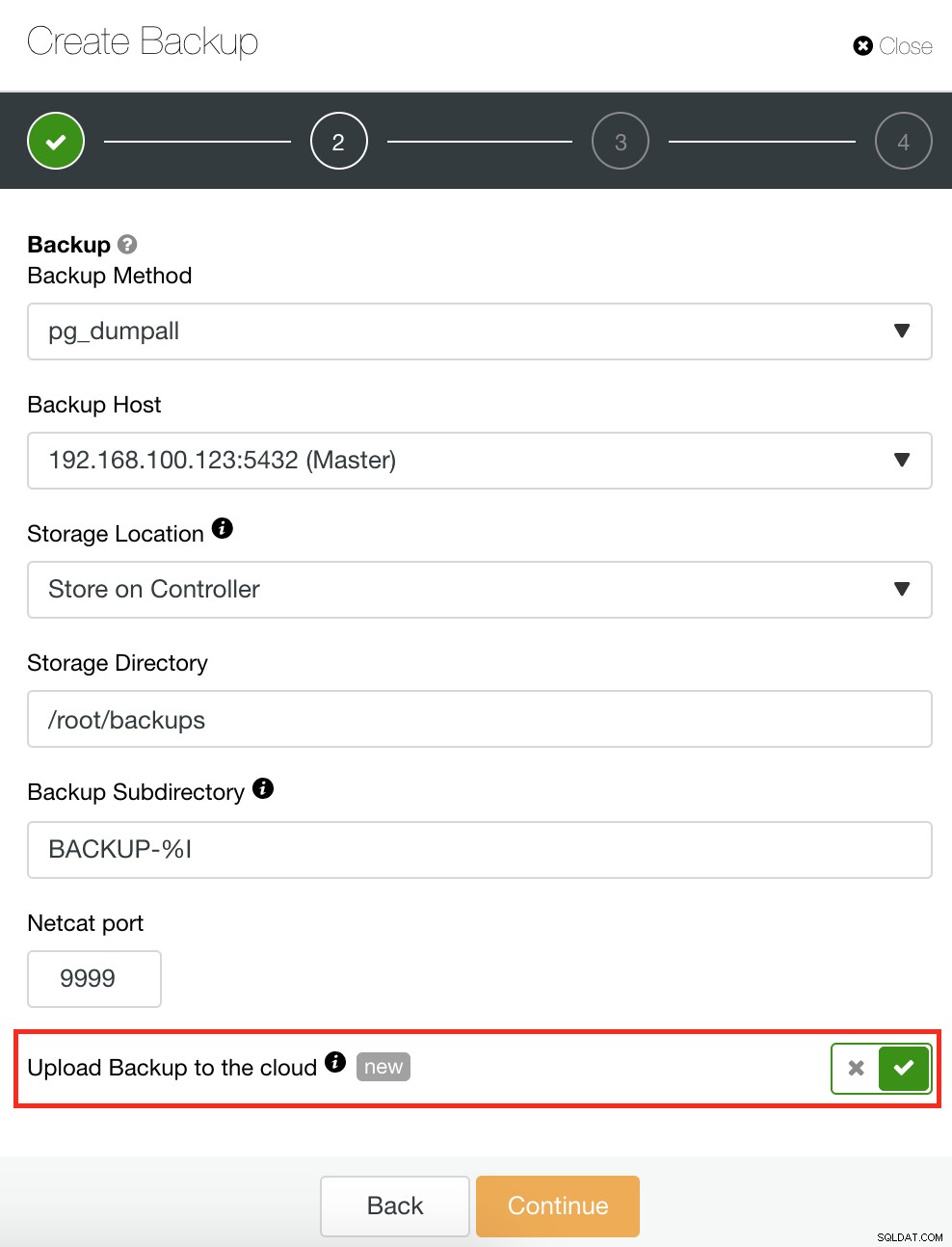
Wie unten gezeigt, bietet die Verwaltung Ihres Backups eine einfache Benutzeroberfläche, auf der Sie auswählen können, welches Backup Sie wiederherstellen möchten, oder Sie müssen es möglicherweise löschen. Die ClusterControl-Sicherung ermöglicht Ihnen die Auswahl einer Aufbewahrungsfrist. Falls Sie also eine lange Liste haben, können einige davon gelöscht werden, wenn die Aufbewahrungsfrist erreicht ist. 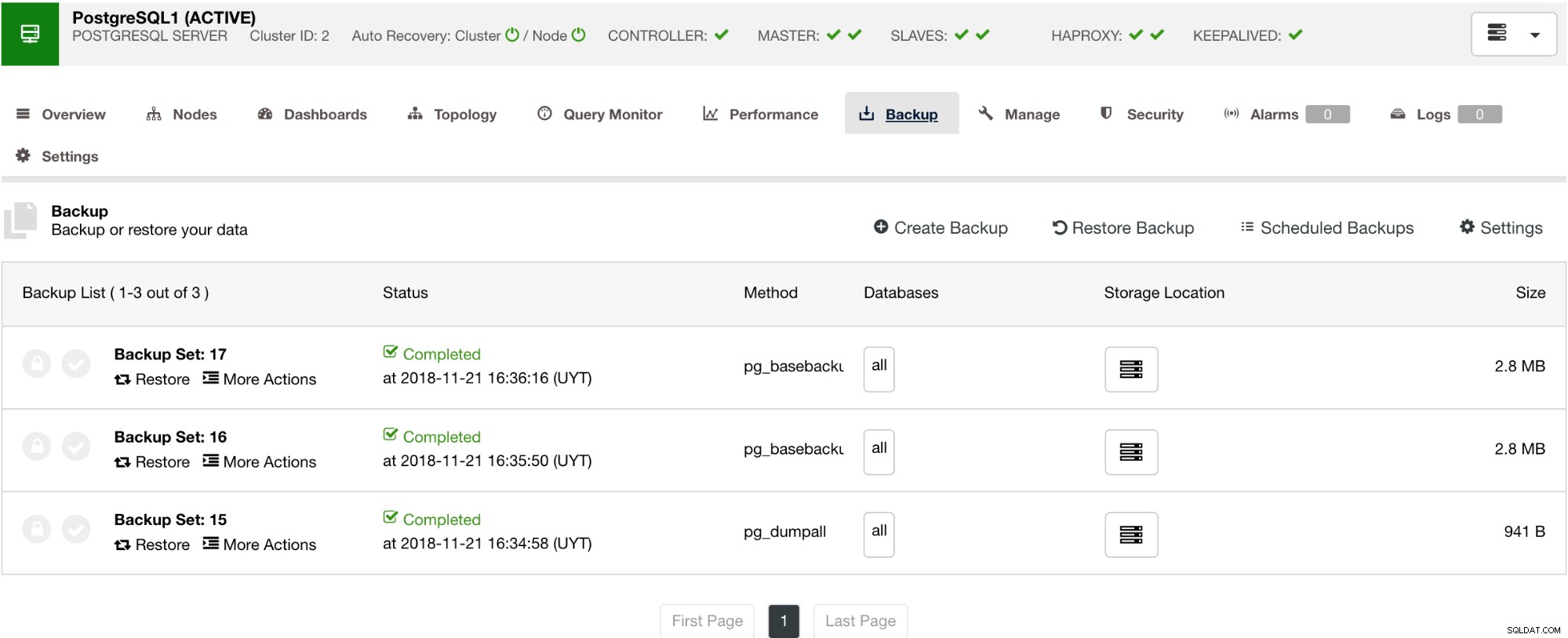
Unterstützt High Availability (HA) und Load Balancing (LB)-Mechanismen
Sie müssen nicht manuell einrichten oder nach Möglichkeiten suchen, Hochverfügbarkeit in Ihrem PostgreSQL-Cluster hinzuzufügen. Es gibt eine einfache und bequeme Möglichkeit, die Arbeit mit ClusterControl zu erledigen. Wenn Sie den Beispiel-Screenshot sehen können, hat es ein HAProxy- und Keepalived-Setup. Siehe Screenshot unten:
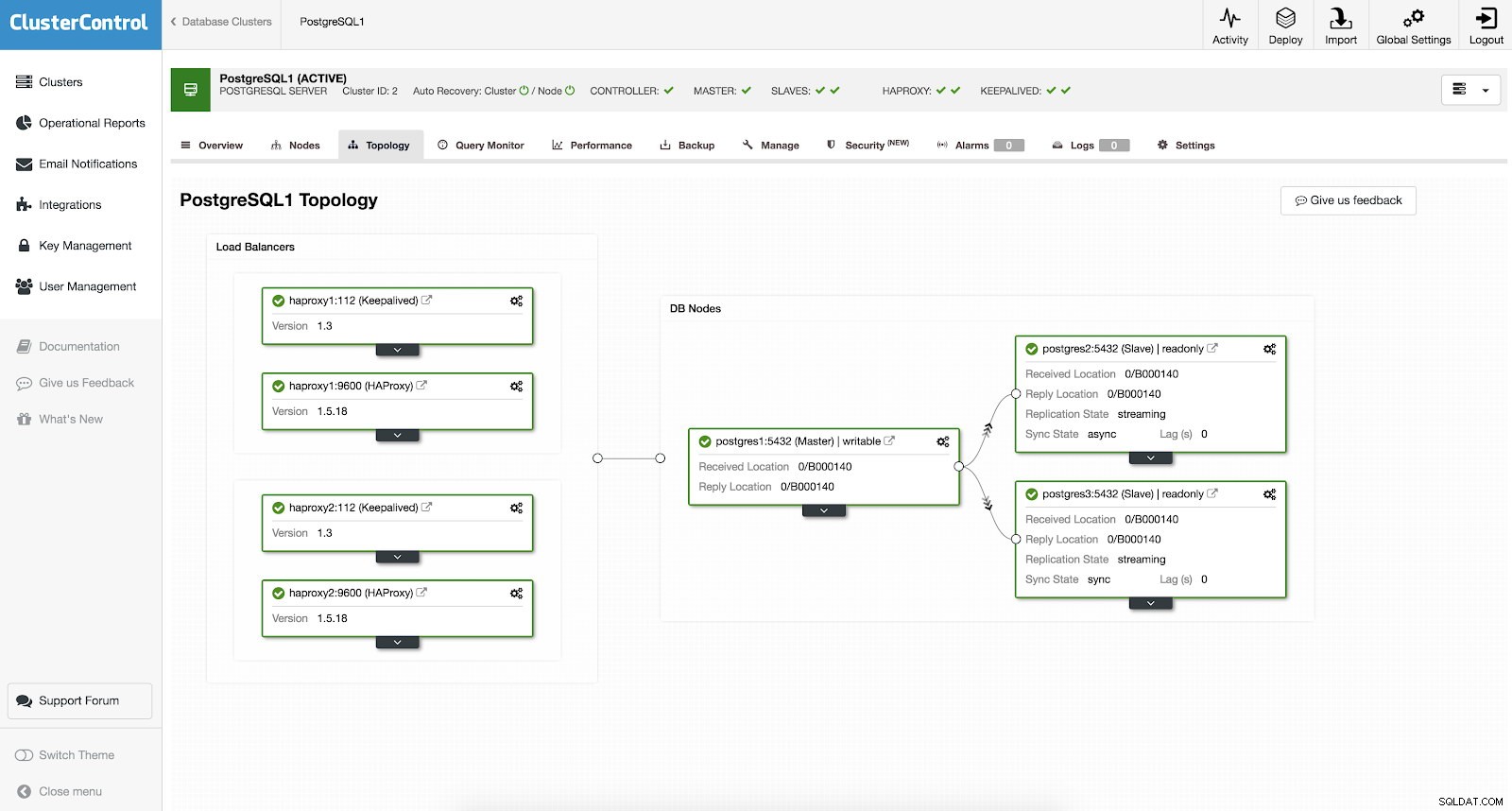
Das Einrichten einer hohen Verfügbarkeit mit ClusterControl kann über
Unterstützt eine verteilte Umgebung
Wenn Sie gleichmäßige Verteilungen von der lokalen oder privaten Cloud zur öffentlichen Cloud haben möchten, unterstützt ClusterControl auch die Cloud-Bereitstellung. Aber für einen PostgreSQL-Cluster und Sie planen, einen sekundären Slave in einer anderen Cloud zu haben, können Sie wie unten gezeigt einen Slave-Cluster erstellen,
und Sie können mit dem Endergebnis wie unten gezeigt ankommen

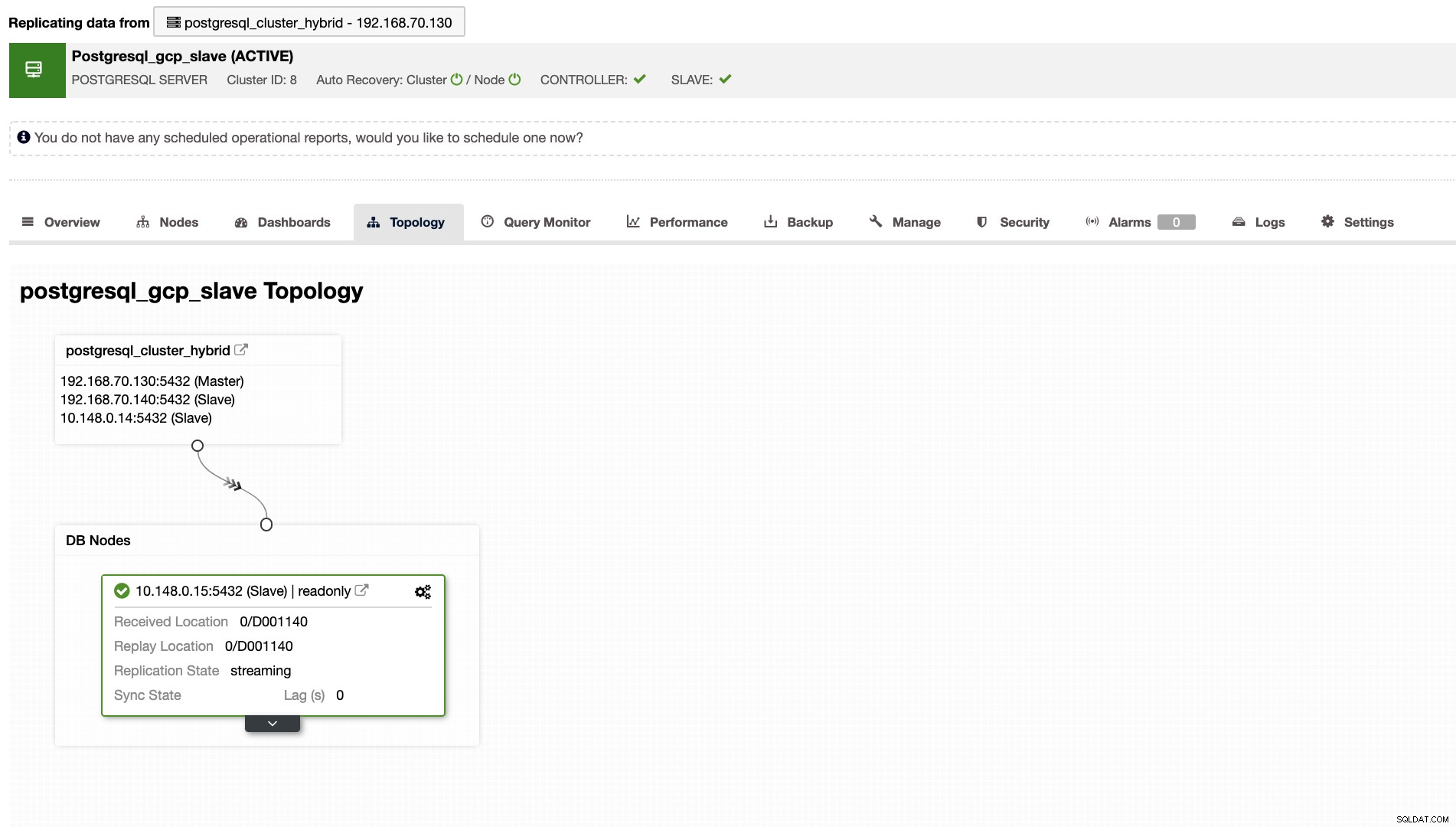
ClusterControl zeigt Ihnen auch die richtige Topologie Ihres Clusters, wann immer Sie eine hybride Cloud-Umgebung eingerichtet haben. Siehe unten,
Während im Slave-Cluster die Topologie ihren Ursprungsbaum zeigt, der ihren Master enthüllt. Der Slave hier zeigt, dass er sich in einem separaten Netzwerk befindet, das sich hauptsächlich in Google Cloud befindet, während der Master lokal ist.
Fazit
Es ist akzeptabel zuzugeben, dass ein hybrides Cloud-Setup, insbesondere mit PostgreSQL-Clustern, die Komplexität erhöht. Sie müssen über das richtige Tool mit verfügbaren Optionen verfügen, um Ihre Disaster-Recovery-Planung zu unterstützen. Diese sind sehr wichtig, um Ihr Unternehmen vor der potenziellen Katastrophe finanzieller Schäden und des Verlusts des Kundenvertrauens zu schützen und zu vermeiden. Investieren Sie in die richtigen Tools und Fähigkeiten Ihrer Technologie und bewahren Sie Ihr Unternehmen vor negativen Auswirkungen.