TeamCity ist ein in Java entwickelter Continuous-Integration- und Continuous-Delivery-Server. Es ist als Clouddienst und lokal verfügbar. Wie Sie sich vorstellen können, sind kontinuierliche Integrations- und Bereitstellungstools für die Softwareentwicklung von entscheidender Bedeutung, und ihre Verfügbarkeit darf nicht beeinträchtigt werden. Glücklicherweise kann TeamCity in einem hochverfügbaren Modus bereitgestellt werden.
Dieser Blogpost behandelt die Vorbereitung und Bereitstellung einer hochverfügbaren Umgebung für TeamCity.
Die Umwelt
TeamCity besteht aus mehreren Elementen. Es gibt eine Java-Anwendung und eine Datenbank, die sie sichert. Es verwendet auch Agenten, die mit der primären TeamCity-Instanz kommunizieren. Die hochverfügbare Bereitstellung besteht aus mehreren TeamCity-Instanzen, von denen eine als primäre und die anderen als sekundäre fungiert. Diese Instanzen teilen sich den Zugriff auf dieselbe Datenbank und das Datenverzeichnis. Ein hilfreiches Schema ist auf der TeamCity-Dokumentationsseite verfügbar, wie unten gezeigt:

Wie wir sehen können, gibt es zwei gemeinsam genutzte Elemente – das Datenverzeichnis und die Datenbank. Wir müssen dafür sorgen, dass diese auch hochverfügbar sind. Es gibt verschiedene Optionen, die Sie verwenden können, um ein gemeinsames Mount zu erstellen. Wir verwenden jedoch GlusterFS. Für die Datenbank verwenden wir eines der unterstützten Verwaltungssysteme für relationale Datenbanken – PostgreSQL, und wir verwenden ClusterControl, um darauf basierend einen Stack mit hoher Verfügbarkeit zu erstellen.
So konfigurieren Sie GlusterFS
Beginnen wir mit den Grundlagen. Wir möchten Hostnamen und /etc/hosts auf unseren TeamCity-Knoten konfigurieren, wo wir auch GlusterFS bereitstellen werden. Dazu müssen wir auf allen das Repository für die neuesten Pakete von GlusterFS einrichten:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateDann können wir GlusterFS auf allen unseren TeamCity-Knoten installieren:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS verwendet Port 24007 für die Verbindung zwischen den Knoten; wir müssen sicherstellen, dass es offen und für alle Knoten zugänglich ist.
Sobald die Konnektivität hergestellt ist, können wir einen GlusterFS-Cluster erstellen, indem wir ihn von einem Knoten aus ausführen:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Jetzt können wir testen, wie der Status aussieht:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Es sieht so aus, als ob alles in Ordnung ist und die Konnektivität vorhanden ist.
Als Nächstes sollten wir ein Blockgerät für die Verwendung durch GlusterFS vorbereiten. Dies muss auf allen Knoten ausgeführt werden. Erstellen Sie zuerst eine Partition:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.Formatieren Sie dann diese Partition:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Schließlich müssen wir auf allen Knoten ein Verzeichnis erstellen, das zum Mounten der Partition verwendet wird, und die fstab bearbeiten, um sicherzustellen, dass sie beim Start gemountet wird:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabÜberprüfen wir jetzt, ob das funktioniert:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Jetzt können wir einen der Knoten verwenden, um das GlusterFS-Volume zu erstellen und zu starten:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successBitte beachten Sie, dass wir den Wert „3“ für die Anzahl der Replikate verwenden. Das bedeutet, dass jeder Band in drei Exemplaren existieren wird. In unserem Fall enthält jeder Baustein, jedes /dev/sdb1-Volume auf allen Knoten alle Daten.
Sobald die Volumes gestartet wurden, können wir ihren Status überprüfen:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksWie Sie sehen können, sieht alles in Ordnung aus. Wichtig ist, dass GlusterFS Port 49152 für den Zugriff auf dieses Volume ausgewählt hat, und wir müssen sicherstellen, dass es auf allen Knoten erreichbar ist, auf denen wir es mounten werden.
Der nächste Schritt wird die Installation des GlusterFS-Client-Pakets sein. Für dieses Beispiel muss es auf denselben Knoten wie der GlusterFS-Server installiert sein:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.Als Nächstes müssen wir auf allen Knoten ein Verzeichnis erstellen, das als freigegebenes Datenverzeichnis für TeamCity verwendet werden soll. Dies muss auf allen Knoten geschehen:
example@sqldat.com:~# sudo mkdir /teamcity-storageMounten Sie zuletzt das GlusterFS-Volume auf allen Knoten:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageDamit sind die Vorbereitungen für den gemeinsamen Speicher abgeschlossen.
Aufbau eines hochverfügbaren PostgreSQL-Clusters
Sobald die gemeinsame Speichereinrichtung für TeamCity abgeschlossen ist, können wir jetzt unsere hochverfügbare Datenbankinfrastruktur aufbauen. TeamCity kann verschiedene Datenbanken verwenden; Wir werden jedoch PostgreSQL in diesem Blog verwenden. Wir werden ClusterControl nutzen, um die Datenbankumgebung bereitzustellen und dann zu verwalten.
Der Leitfaden von TeamCity zum Aufbau einer Multi-Node-Bereitstellung ist hilfreich, scheint aber die hohe Verfügbarkeit von allem außer TeamCity außer Acht zu lassen. Der Leitfaden von TeamCity schlägt einen NFS- oder SMB-Server für die Datenspeicherung vor, der allein keine Redundanz aufweist und zu einem Single Point of Failure wird. Wir haben dies durch die Verwendung von GlusterFS behoben. Sie erwähnen eine gemeinsam genutzte Datenbank, da ein einzelner Datenbankknoten offensichtlich keine hohe Verfügbarkeit bietet. Wir müssen einen ordentlichen Stack aufbauen:

In unserem Fall. Es besteht aus drei PostgreSQL-Knoten, einem primären und zwei Replikaten. Wir werden HAProxy als Load Balancer verwenden und Keepalived verwenden, um Virtual IP zu verwalten, um einen einzelnen Endpunkt bereitzustellen, mit dem sich die Anwendung verbinden kann. ClusterControl behandelt Fehler, indem es die Replikationstopologie überwacht und bei Bedarf alle erforderlichen Wiederherstellungen durchführt, z. B. Neustart von fehlgeschlagenen Prozessen oder Failover auf eines der Replikate, wenn der primäre Knoten ausfällt.
Zunächst werden wir die Datenbankknoten bereitstellen. Bitte beachten Sie, dass ClusterControl eine SSH-Konnektivität vom ClusterControl-Knoten zu allen von ihm verwalteten Knoten benötigt.

Dann wählen wir einen Benutzer aus, mit dem wir uns mit dem verbinden Datenbank, ihr Passwort und die bereitzustellende PostgreSQL-Version:

Als Nächstes definieren wir, welche Knoten für die Bereitstellung von PostgreSQL verwendet werden sollen :
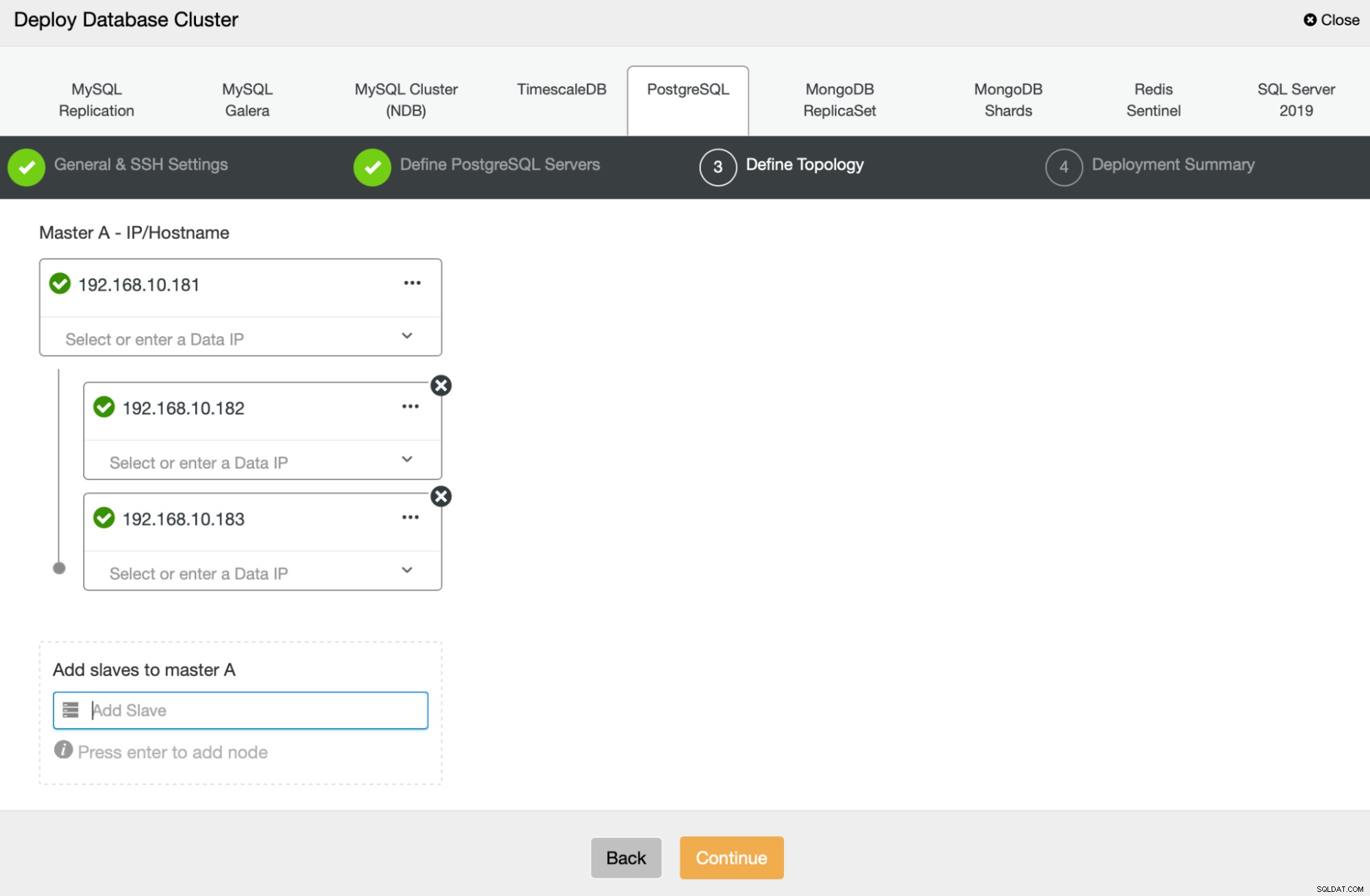
Schließlich können wir definieren, ob die Knoten asynchrone oder synchrone Replikation verwenden sollen. Der Hauptunterschied zwischen diesen beiden besteht darin, dass die synchrone Replikation sicherstellt, dass jede auf dem primären Knoten ausgeführte Transaktion immer auf den Replikaten repliziert wird. Die synchrone Replikation verlangsamt jedoch auch den Commit. Wir empfehlen, die synchrone Replikation für die beste Dauerhaftigkeit zu aktivieren, aber Sie sollten später überprüfen, ob die Leistung akzeptabel ist.

Nachdem wir auf „Bereitstellen“ geklickt haben, wird ein Bereitstellungsjob gestartet. Wir können den Fortschritt auf der Registerkarte „Aktivität“ in der ClusterControl-Benutzeroberfläche überwachen. Wir sollten schließlich sehen, dass der Job abgeschlossen und der Cluster erfolgreich bereitgestellt wurde.

Stellen Sie HAProxy-Instanzen bereit, indem Sie zu Verwalten -> Load-Balancer gehen. Wählen Sie HAProxy als Load Balancer aus und füllen Sie das Formular aus. Die wichtigste Wahl ist, wo Sie HAProxy bereitstellen möchten. Wir haben in diesem Fall einen Datenbankknoten verwendet, aber in einer Produktionsumgebung möchten Sie höchstwahrscheinlich Load Balancer von Datenbankinstanzen trennen. Wählen Sie als Nächstes aus, welche PostgreSQL-Knoten in HAProxy enthalten sein sollen. Wir wollen sie alle.

Jetzt wird die HAProxy-Bereitstellung gestartet. Wir möchten es mindestens noch einmal wiederholen, um zwei HAProxy-Instanzen für Redundanz zu erstellen. In dieser Bereitstellung haben wir uns für drei HAProxy-Load-Balancer entschieden. Unten sehen Sie einen Screenshot des Einstellungsbildschirms während der Konfiguration der Bereitstellung eines zweiten HAProxy:
Wenn alle unsere HAProxy-Instanzen betriebsbereit sind, können wir Keepalived bereitstellen . Die Idee dabei ist, dass Keepalived mit HAProxy verbunden wird und den Prozess von HAProxy überwacht. Einer der Instanzen mit funktionierendem HAProxy wird eine virtuelle IP zugewiesen. Diese VIP sollte von der Anwendung verwendet werden, um eine Verbindung zur Datenbank herzustellen. Keepalived erkennt, wenn dieser HAProxy nicht mehr verfügbar ist, und wechselt zu einer anderen verfügbaren HAProxy-Instanz.
Der Bereitstellungsassistent fordert uns auf, HAProxy-Instanzen zu übergeben, die von Keepalived überwacht werden sollen. Außerdem müssen wir die IP-Adresse und die Netzwerkschnittstelle für VIP übergeben.

Der letzte und letzte Schritt besteht darin, eine Datenbank für TeamCity zu erstellen:

Damit haben wir die Bereitstellung des hochverfügbaren PostgreSQL-Clusters abgeschlossen.
Bereitstellung von TeamCity als Multi-Knoten
Der nächste Schritt ist die Bereitstellung von TeamCity in einer Umgebung mit mehreren Knoten. Wir werden drei TeamCity-Knoten verwenden. Zuerst müssen wir Java JRE und JDK installieren, die den Anforderungen von TeamCity entsprechen.
apt install default-jre default-jdkJetzt müssen wir auf allen Knoten TeamCity herunterladen. Wir werden in einem lokalen, nicht freigegebenen Verzeichnis installieren.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzDann können wir TeamCity auf einem der Knoten starten:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logSobald TeamCity gestartet ist, können wir auf die Benutzeroberfläche zugreifen und mit der Bereitstellung beginnen. Zunächst müssen wir den Speicherort des Datenverzeichnisses übergeben. Dies ist das freigegebene Volume, das wir auf GlusterFS erstellt haben.

Wählen Sie als Nächstes die Datenbank aus. Wir werden einen PostgreSQL-Cluster verwenden, den wir bereits erstellt haben.

Laden Sie den JDBC-Treiber herunter und installieren Sie ihn:

Geben Sie als Nächstes die Zugangsdaten ein. Wir verwenden die von Keepalived bereitgestellte virtuelle IP. Bitte beachten Sie, dass wir Port 5433 verwenden. Dies ist der Port, der für das Lese-/Schreib-Backend von HAProxy verwendet wird; er zeigt immer auf den aktiven primären Knoten. Wählen Sie als Nächstes einen Benutzer und die Datenbank aus, die mit TeamCity verwendet werden sollen.

Sobald dies erledigt ist, beginnt TeamCity mit der Initialisierung der Datenbankstruktur.

Stimmen Sie der Lizenzvereinbarung zu:

Erstellen Sie schließlich einen Benutzer für TeamCity:

Das war's! Wir sollten jetzt die TeamCity-GUI sehen können:

Jetzt müssen wir TeamCity im Mehrknotenmodus einrichten. Zuerst müssen wir die Startskripte auf allen Knoten bearbeiten:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shWir müssen sicherstellen, dass die folgenden zwei Variablen exportiert werden. Bitte vergewissern Sie sich, dass Sie den richtigen Hostnamen, die richtige IP und die richtigen Verzeichnisse für den lokalen und freigegebenen Speicher verwenden:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"Sobald dies erledigt ist, können Sie die restlichen Knoten starten:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startSie sollten die folgende Ausgabe in Verwaltung -> Knotenkonfiguration sehen:Ein Hauptknoten und zwei Standby-Knoten.

Bitte beachten Sie, dass Failover in TeamCity nicht automatisiert ist. Wenn der Hauptknoten nicht mehr funktioniert, sollten Sie sich mit einem der sekundären Knoten verbinden. Gehen Sie dazu zu "Knotenkonfiguration" und stufen Sie ihn zum "Haupt"-Knoten hoch. Auf dem Anmeldebildschirm sehen Sie einen klaren Hinweis darauf, dass dies ein sekundärer Knoten ist:

In der "Knotenkonfiguration" sehen Sie, dass der eine Knoten hat aus dem Cluster gelöscht:

Sie erhalten eine Meldung, dass Sie auf diesen Knoten nicht schreiben können. Mach dir keine Sorgen; Der Schreibvorgang, der erforderlich ist, um diesen Knoten in den „Haupt“-Status zu befördern, wird problemlos funktionieren:

Klicken Sie auf „Aktivieren“ und wir haben erfolgreich einen sekundären TimeCity-Knoten heraufgestuft:

Wenn Knoten1 verfügbar wird und TeamCity auf diesem Knoten erneut gestartet wird, werden wir das tun Sehen Sie, wie es dem Cluster wieder beitritt:

Wenn Sie die Leistung weiter verbessern möchten, können Sie HAProxy + Keepalived vor der TeamCity-Benutzeroberfläche bereitstellen, um einen einzigen Einstiegspunkt für die GUI bereitzustellen. Details zur Konfiguration von HAProxy für TeamCity finden Sie in der Dokumentation.
Abschluss
Wie Sie sehen können, ist die Bereitstellung von TeamCity für Hochverfügbarkeit nicht so schwierig – das meiste davon wurde ausführlich in der Dokumentation behandelt. Wenn Sie nach Möglichkeiten suchen, einiges davon zu automatisieren und ein hochverfügbares Datenbank-Backend hinzuzufügen, sollten Sie ClusterControl 30 Tage lang kostenlos testen. ClusterControl kann das Backend schnell bereitstellen und überwachen und bietet automatisiertes Failover, Wiederherstellung, Überwachung, Sicherungsverwaltung und mehr.
Weitere Tipps zu Softwareentwicklungstools und Best Practices finden Sie unter So unterstützen Sie Ihr DevOps-Team bei seinen Datenbankanforderungen.
Um die neuesten Nachrichten und Best Practices für die Verwaltung Ihrer Open-Source-basierten Datenbankinfrastruktur zu erhalten, vergessen Sie nicht, uns auf Twitter oder LinkedIn zu folgen und unseren Newsletter zu abonnieren. Bis bald!