Im ersten Teil dieser Blogserie habe ich einige Benchmark-Ergebnisse präsentiert, die zeigen, wie sich die Leistung von PostgreSQL OLTP seit 8.3, veröffentlicht im Jahr 2008, verändert hat. In diesem Teil plane ich dasselbe zu tun, aber für analytische / BI-Abfragen, die große Verarbeitungsmengen haben Datenmengen.
Es gibt eine Reihe von Industrie-Benchmarks zum Testen dieser Workload, aber der wahrscheinlich am häufigsten verwendete ist TPC-H, also werde ich ihn für diesen Blogbeitrag verwenden. Es gibt auch TPC-DS, einen weiteren TPC-Benchmark zum Testen von Entscheidungsunterstützungssystemen, der als Weiterentwicklung oder Ersatz von TPC-H angesehen werden kann. Ich habe mich aus mehreren Gründen entschieden, bei TPC-H zu bleiben.
Erstens ist TPC-DS viel komplexer, sowohl in Bezug auf das Schema (mehr Tabellen) als auch auf die Anzahl der Abfragen (22 vs. 99). Dies richtig abzustimmen, insbesondere wenn es um mehrere PostgreSQL-Versionen geht, wäre viel schwieriger. Zweitens verwenden einige der TPC-DS-Abfragen Funktionen, die von älteren PostgreSQL-Versionen nicht unterstützt werden (z. B. Gruppierungssätze), wodurch diese Abfragen für einige Versionen irrelevant werden. Und schließlich würde ich sagen, dass die Leute mit TPC-H viel vertrauter sind als mit TPC-DS.
Das Ziel dabei ist nicht, einen Vergleich mit anderen Datenbankprodukten zu ermöglichen, sondern lediglich eine angemessene langfristige Charakterisierung der Entwicklung der PostgreSQL-Leistung seit PostgreSQL 8.3 bereitzustellen.
Hinweis :Für eine sehr interessante Analyse des TPC-H-Benchmarks empfehle ich dringend das Papier „TPC-H Analyzed:Hidden Messages and Lessons Learned from an Influential Benchmark“ von Boncz, Neumann und Erling.
Die Hardware
Die meisten Ergebnisse in diesem Blogbeitrag stammen aus der „größeren Kiste“, die ich in unserem Büro habe und die diese Parameter hat:
- 2x E5-2620 v4 (16 Kerne, 32 Threads)
- 64 GB Arbeitsspeicher
- Intel Optane 900P 280 GB NVMe-SSD (Daten)
- 3 x 7.2k SATA RAID0 (temporärer Tablespace)
- Kernel 5.6.15, ext4-Dateisystem
Ich bin sicher, dass Sie deutlich kräftigere Maschinen kaufen können, aber ich glaube, dass dies gut genug ist, um uns relevante Daten zu liefern. Es gab zwei Konfigurationsvarianten – eine mit deaktivierter Parallelität, eine mit aktivierter Parallelität. Die meisten Parameterwerte sind in beiden Fällen gleich, abgestimmt auf die verfügbaren Hardwareressourcen (CPU, RAM, Speicher). Genauere Informationen zur Konfiguration findest du am Ende dieses Beitrags.
Der Maßstab
Ich möchte ganz klar sagen, dass es nicht mein Ziel ist, einen gültigen TPC-H-Benchmark zu implementieren, der alle vom TPC geforderten Kriterien erfüllen könnte. Mein Ziel ist es, zu bewerten, wie sich die Leistung verschiedener analytischer Abfragen im Laufe der Zeit verändert hat, und nicht irgendein abstraktes Maß für die Leistung pro Dollar oder ähnliches zu verfolgen.
Daher habe ich mich entschieden, nur eine Teilmenge von TPC-H zu verwenden – im Wesentlichen nur die Daten zu laden und die 22 Abfragen auszuführen (gleiche Parameter für alle Versionen). Es gibt keine Datenaktualisierungen, der Datensatz ist nach dem anfänglichen Laden statisch. Ich habe eine Reihe von Skalierungsfaktoren ausgewählt, 1, 10 und 75, sodass wir Ergebnisse für „fits-in-shared-buffers“ (1), „fits-in-memory“ (10) und „more-than-memory“ (75) haben. . Ich würde 100 wählen, um daraus eine „schöne Sequenz“ zu machen, die in einigen Fällen nicht in den 280-GB-Speicher passen würde (dank Indizes, temporären Dateien usw.). Beachten Sie, dass der Skalierungsfaktor 75 nicht einmal von TPC-H als gültiger Skalierungsfaktor erkannt wird.
Aber macht es überhaupt Sinn, 1-GB- oder 10-GB-Datensätze zu benchmarken? Die Leute neigen dazu, sich auf viel größere Datenbanken zu konzentrieren, daher könnte es ein bisschen dumm erscheinen, diese zu testen. Aber ich glaube nicht, dass das nützlich wäre – die überwiegende Mehrheit der Datenbanken in freier Wildbahn ist meiner Erfahrung nach ziemlich klein. Und selbst wenn die gesamte Datenbank groß ist, arbeiten die Leute normalerweise nur mit einer kleinen Teilmenge davon – aktuelle Daten, ungelöste Bestellungen usw. Daher halte ich es für sinnvoll, auch mit diesen kleinen Datensätzen zu testen.
Daten werden geladen
Sehen wir uns zunächst an, wie lange es dauert, Daten in die Datenbank zu laden – ohne und mit Parallelität. Ich zeige nur Ergebnisse aus dem 75-GB-Datensatz, da das Gesamtverhalten für die kleineren Fälle fast gleich ist.
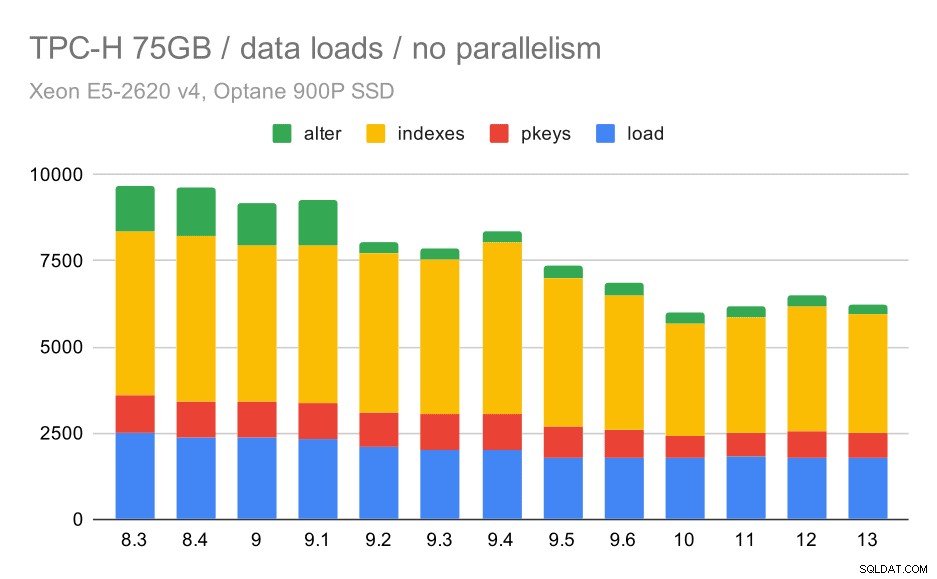
TPC-H-Datenladedauer – Skalierung auf 75 GB, keine Parallelität
Sie können deutlich sehen, dass es einen stetigen Trend zu Verbesserungen gibt, die etwa 30 % der Dauer einsparen, indem Sie lediglich die Effizienz in allen vier Schritten verbessern – KOPIEREN, Erstellen von Primärschlüsseln und Indizes und (insbesondere) Einrichten von Fremdschlüsseln. Die „alter“-Verbesserung in 9.2 ist besonders deutlich.
| KOPIE | PKEYS | INDEXES | ALTER | |
| 8.3 | 2531 | 1156 | 1922 | 1615 |
| 8.4 | 2374 | 1171 | 1891 | 1370 |
| 9.0 | 2374 | 1137 | 1797 | 1282 |
| 9.1 | 2376 | 1118 | 1807 | 1268 |
| 9.2 | 2104 | 1120 | 1833 | 1157 |
| 9.3 | 2008 | 1089 | 1836 | 1229 |
| 9.4 | 1990 | 1168 | 1818 | 1197 |
| 9.5 | 1982 | 1000 | 1903 | 1203 |
| 9.6 | 1779 | 872 | 1797 | 1174 |
| 10 | 1773 | 777 | 1469 | 1012 |
| 11 | 1807 | 762 | 1492 | 758 |
| 12 | 1760 | 768 | 1513 | 741 |
| 13 | 1782 | 836 | 1587 | 675 |
Sehen wir uns nun an, wie die Aktivierung der Parallelität das Verhalten ändert. Das folgende Diagramm vergleicht Ergebnisse mit aktivierter Parallelität – markiert mit „(p)“ – mit Ergebnissen mit deaktivierter Parallelität.
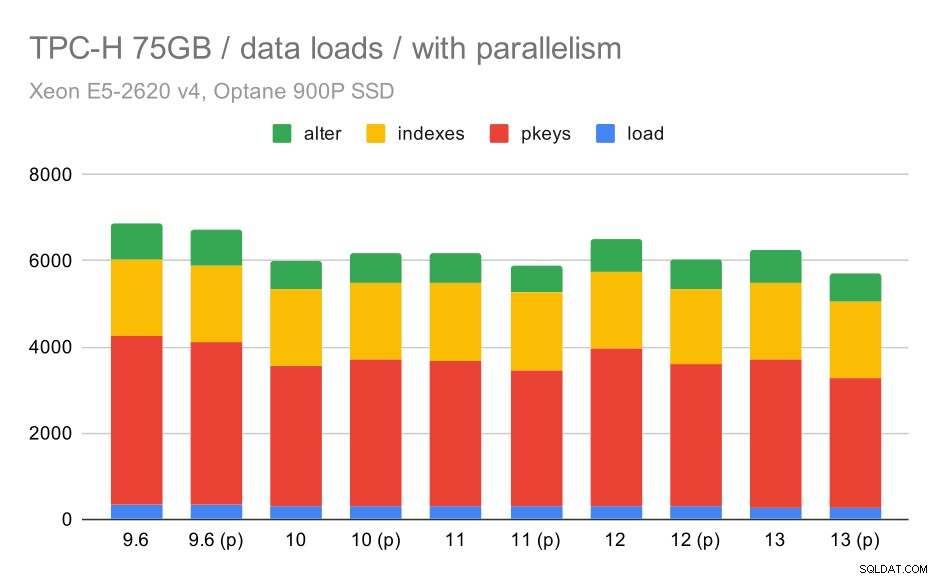
TPC-H-Datenladedauer – Skalierung auf 75 GB, Parallelität aktiviert.
Leider scheint der Effekt der Parallelität in diesem Test sehr begrenzt zu sein – es hilft ein bisschen, aber die Unterschiede sind ziemlich gering. Die Gesamtverbesserung bleibt also bei etwa 30 %.
| KOPIE | PKEYS | INDEXES | ALTER | |
| 9.6 | 344 | 3902 | 1786 | 831 |
| 9.6 (p) | 346 | 3781 | 1780 | 832 |
| 10 | 318 | 3259 | 1766 | 671 |
| 10 (p) | 315 | 3400 | 1769 | 693 |
| 11 | 319 | 3357 | 1817 | 690 |
| 11 (p) | 320 | 3144 | 1791 | 618 |
| 12 | 314 | 3643 | 1803 | 754 |
| 12 (p) | 313 | 3296 | 1752 | 657 |
| 13 | 276 | 3437 | 1790 | 744 |
| 13 (P) | 274 | 3011 | 1770 | 641 |
Abfragen
Jetzt können wir uns die Abfragen ansehen. TPC-H hat 22 Abfragevorlagen – ich habe einen Satz tatsächlicher Abfragen generiert und sie auf allen Versionen zweimal ausgeführt – zuerst nach dem Löschen aller Caches und dem Neustart der Instanz, dann mit dem aufgewärmten Cache. Alle in den Charts dargestellten Zahlen sind die besten dieser beiden Läufe (in den meisten Fällen natürlich der zweite).
Keine Parallelität
Ohne Parallelität sind die Ergebnisse für den kleinsten Datensatz ziemlich klar – jeder Balken wird in mehrere Teile mit unterschiedlichen Farben für jede der 22 Abfragen aufgeteilt. Es ist schwer zu sagen, welcher Teil welcher genauen Abfrage zugeordnet ist, aber es reicht aus, um Fälle zu identifizieren, in denen sich eine Abfrage zwischen zwei Durchläufen verbessert oder viel verschlechtert. Zum Beispiel ist im ersten Diagramm sehr deutlich, dass Q21 zwischen 8,3 und 8,4 viel schneller wurde.
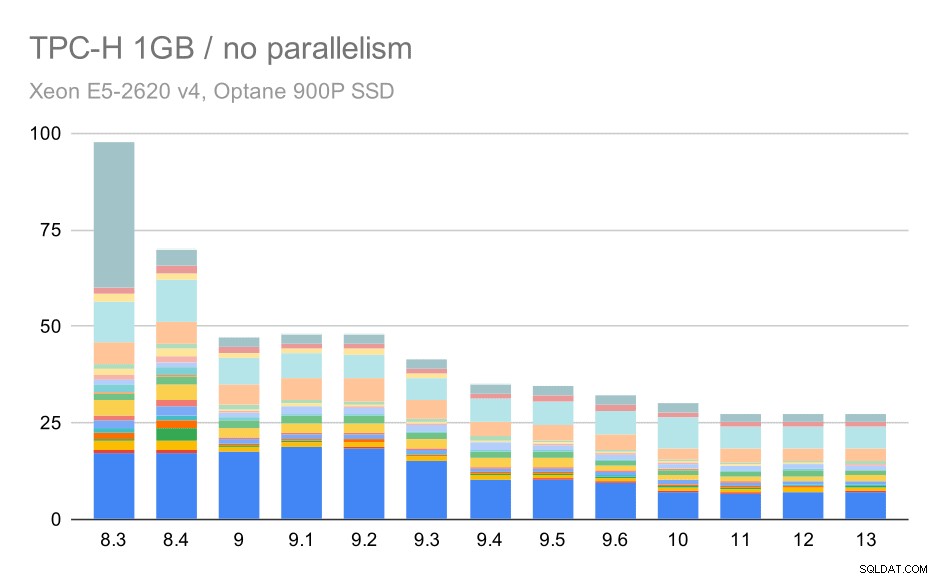
TPC-H-Abfragen bei kleinem Datensatz (1 GB) – Parallelität deaktiviert
Für die 10-GB-Skala sind die Ergebnisse etwas schwer zu interpretieren, da auf 8.3 eine der Abfragen (Q21) so viel Zeit zur Ausführung benötigt, dass sie alles andere in den Schatten stellt.
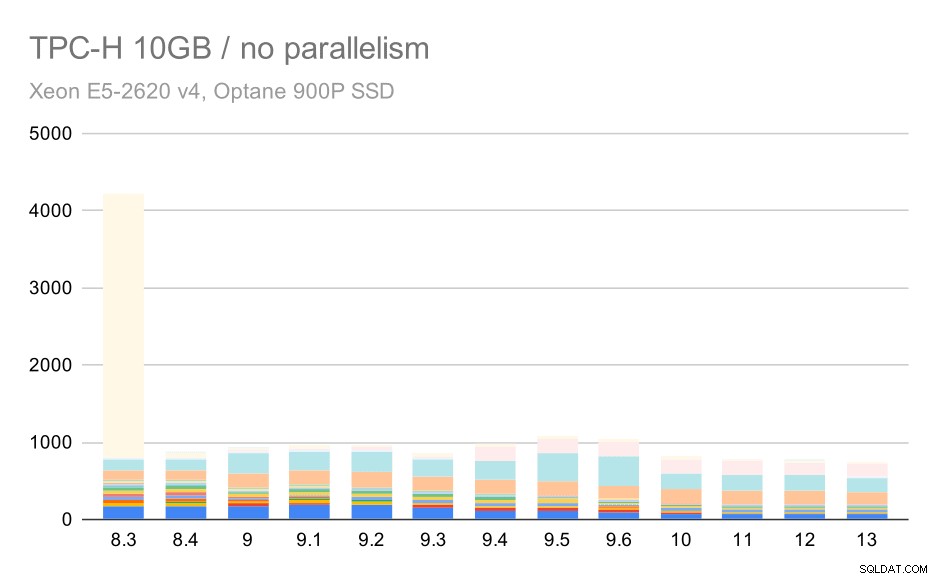
TPC-H-Abfragen auf mittlerem Datensatz (10 GB) – Parallelität deaktiviert
Mal sehen, wie das Diagramm ohne Q21 aussehen würde:
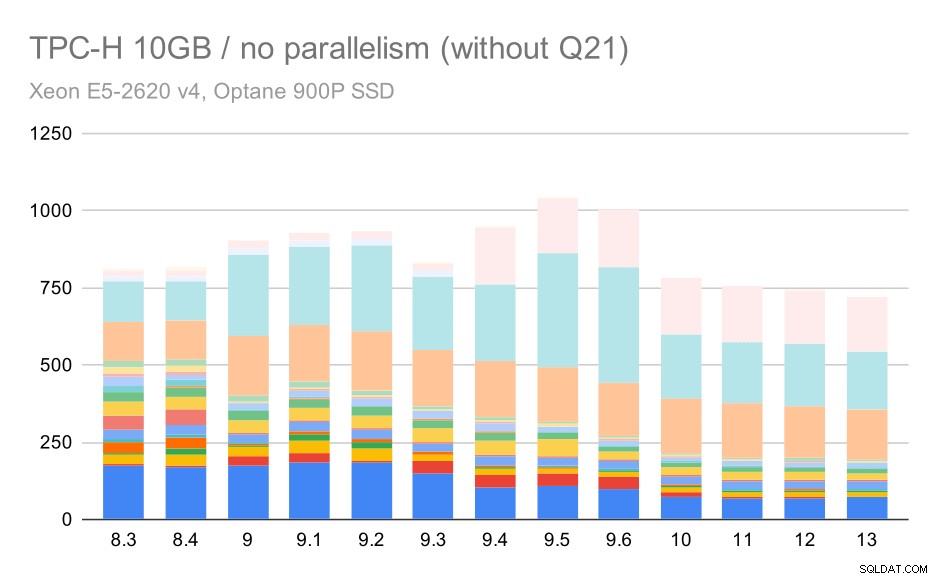
TPC-H-Abfragen auf mittlerem Datensatz (10 GB) – Parallelität deaktiviert, ohne problematisches Q2
Okay, das ist einfacher zu lesen. Wir können deutlich sehen, dass die meisten Abfragen (bis Q17) schneller wurden, aber dann wurden zwei der Abfragen (Q18 und Q20) etwas langsamer. Wir werden ein ähnliches Problem beim größten Datensatz sehen, also werde ich dann diskutieren, was die Hauptursache sein könnte.
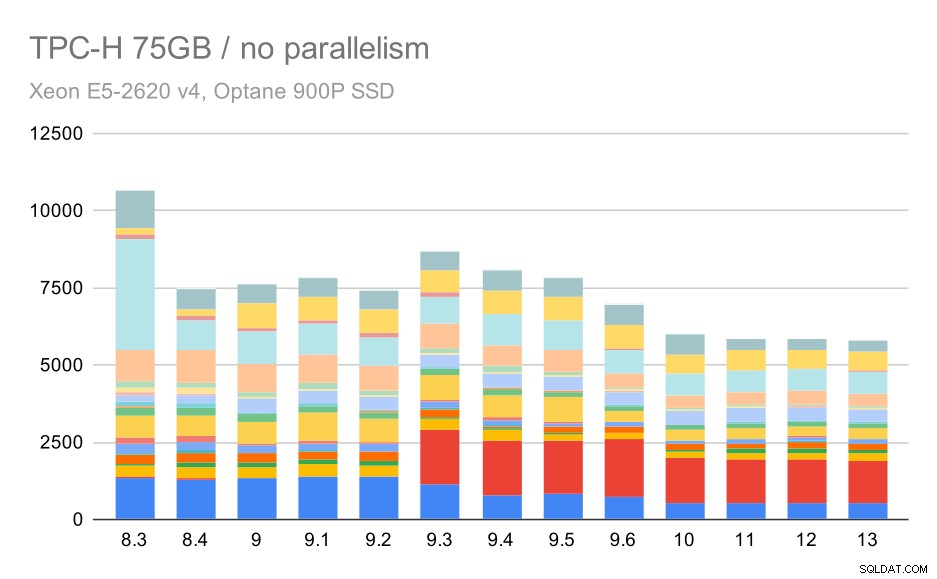
TPC-H-Abfragen bei großen Datensätzen (75 GB) – Parallelität deaktiviert
Wieder sehen wir einen plötzlichen Anstieg für eine der Abfragen in 9.3 – diesmal ist es Q2, ohne das das Diagramm so aussieht:
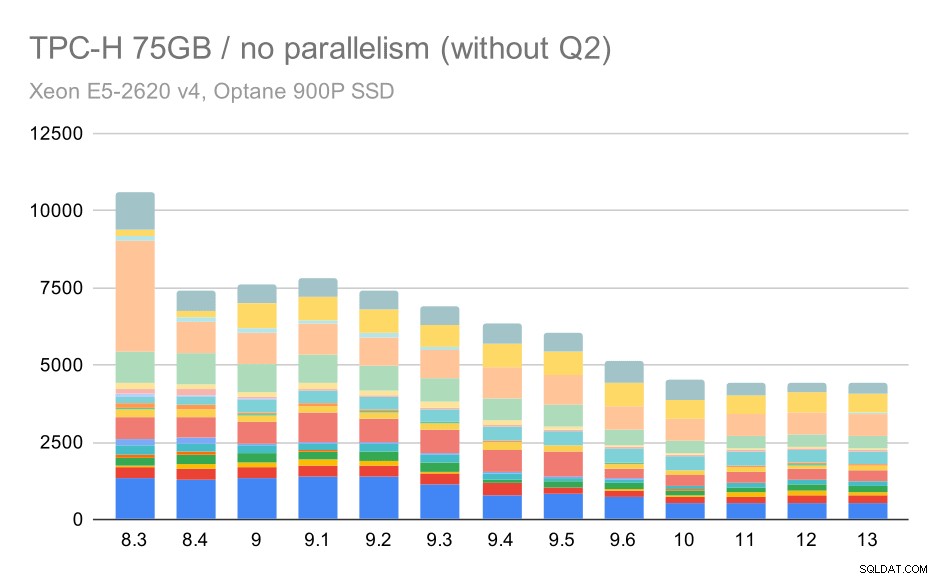
TPC-H-Abfragen bei großen Datensätzen (75 GB) – Parallelität deaktiviert, ohne problematisches Q2
Das ist im Allgemeinen eine ziemlich nette Verbesserung, die die gesamte Ausführung von ~ 2,7 Stunden auf nur ~ 1,2 Stunden beschleunigt, indem lediglich der Planer und Optimierer intelligenter und der Executor effizienter gemacht wurden (denken Sie daran, dass die Parallelität in diesen Läufen deaktiviert war). .
Was könnte also das Problem mit Q2 sein, das es in 9.3 langsamer macht? Die einfache Antwort ist, dass jedes Mal, wenn Sie den Planer und Optimierer intelligenter machen – entweder indem Sie neue Arten von Pfaden / Plänen erstellen oder ihn von einigen Statistiken abhängig machen, dies auch bedeutet, dass neue Fehler gemacht werden können, wenn die Statistiken oder Schätzungen falsch sind. In Q2 verweist die WHERE-Klausel auf eine aggregierte Unterabfrage – eine vereinfachte Version der Abfrage könnte wie folgt aussehen:
select 1from partuppwhere ps_supplycost =(select min (ps_supplycost) aus Partsupp, Lieferanten, Nation, Region, wobei p_partkey =ps_partkey und s_suppkey =ps_suppkey und s_nationkey =n_nationkey und n_regionkey =r_regionkey und r_name ='America');Das Problem ist, dass wir den Durchschnittswert zum Planungszeitpunkt nicht kennen, was es unmöglich macht, ausreichend gute Schätzungen für die WHERE-Bedingung zu berechnen. Das aktuelle Q2 enthält zusätzliche Joins, und deren Planung hängt grundsätzlich von guten Schätzungen der Joined-Beziehungen ab. In älteren Versionen scheint der Optimierer das Richtige getan zu haben, aber in 9.3 haben wir ihn irgendwie klüger gemacht, aber mit der schlechten Schätzung trifft er nicht die richtige Entscheidung. Mit anderen Worten, die guten Pläne in älteren Versionen waren dank der Einschränkungen des Planers nur Glück.
Ich würde wetten, dass die Regressionen von Q18 und Q20 auf dem kleineren Datensatz auch durch etwas Ähnliches verursacht werden, obwohl ich diese nicht im Detail untersucht habe.
Ich glaube, dass einige dieser Optimierungsprobleme durch die Anpassung der Kostenparameter (z. B. random_page_cost usw.) behoben werden könnten, aber ich habe das aus Zeitgründen nicht versucht. Es zeigt jedoch, dass Upgrades nicht automatisch alle Abfragen verbessern – manchmal kann ein Upgrade eine Regression auslösen, daher ist ein angemessenes Testen Ihrer Anwendung eine gute Idee.
Parallelität
Sehen wir uns also an, wie stark die Abfrageparallelität die Ergebnisse verändert. Auch hier betrachten wir nur Ergebnisse von Releases seit 9.6, die Ergebnisse mit „(p)“ kennzeichnen, wenn parallele Abfragen aktiviert sind.
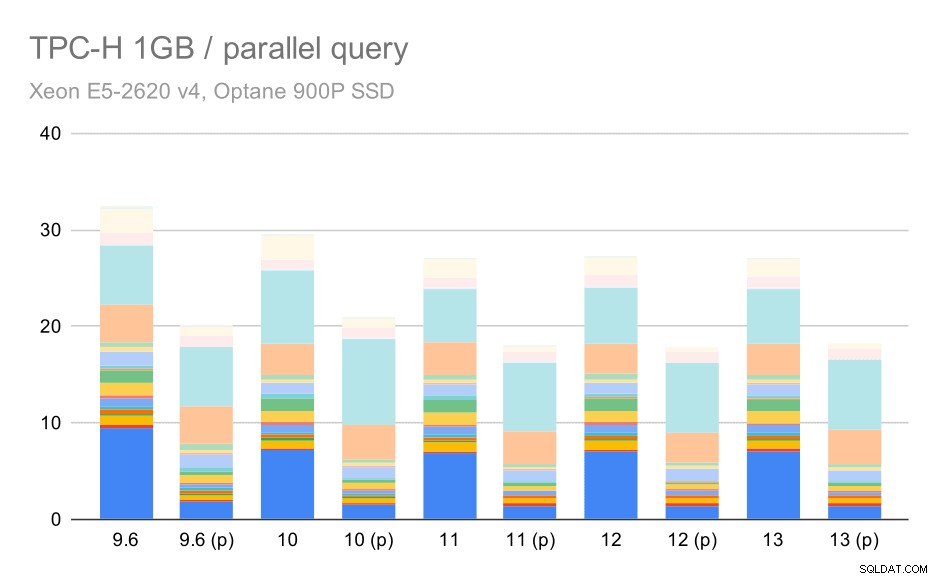
TPC-H-Abfragen bei kleinem Datensatz (1 GB) – Parallelität aktiviert
Natürlich hilft Parallelität ziemlich viel – es spart etwa 30 % selbst bei diesem kleinen Datensatz. Beim mittleren Datensatz gibt es keinen großen Unterschied zwischen regulären und parallelen Läufen:
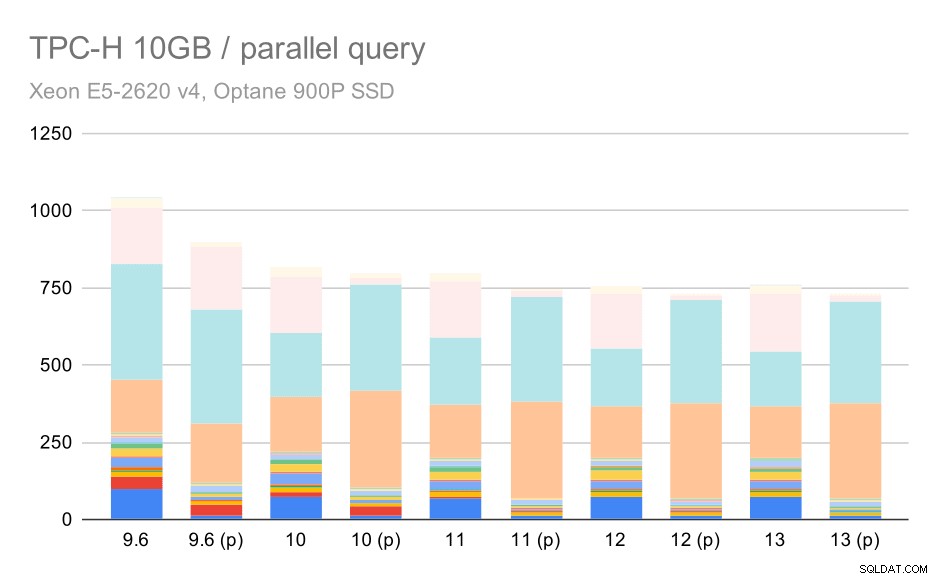
TPC-H-Abfragen auf mittlerem Datensatz (10 GB) – Parallelität aktiviert
Dies ist eine weitere Demonstration des bereits diskutierten Problems – die Aktivierung der Parallelität ermöglicht die Berücksichtigung zusätzlicher Abfragepläne, und die Schätzungen oder Kosten stimmen eindeutig nicht mit der Realität überein, was zu einer schlechten Planauswahl führt.
Und schließlich der große Datensatz, wo die vollständigen Ergebnisse so aussehen:
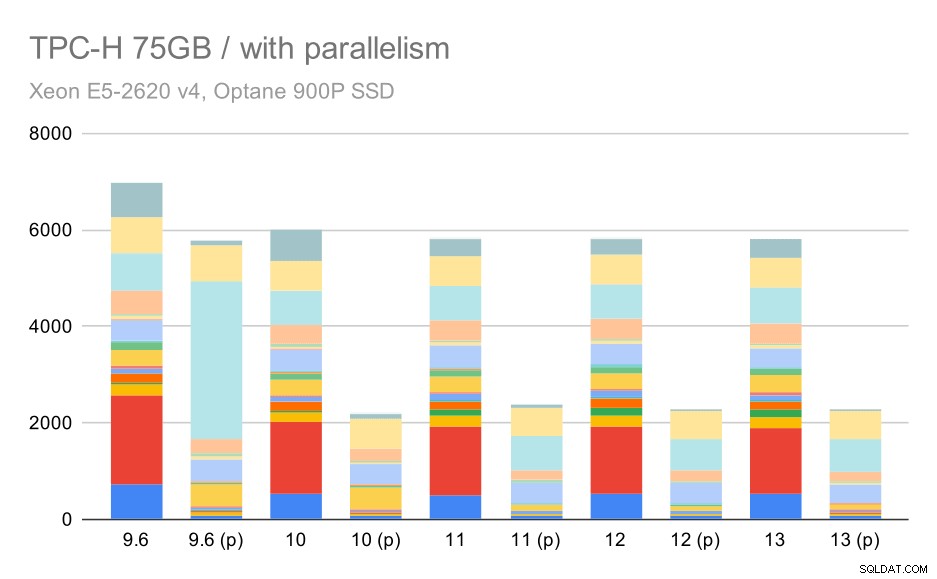
TPC-H-Abfragen bei großen Datensätzen (75 GB) – Parallelität aktiviert
Hier wirkt sich die Aktivierung der Parallelität zu unserem Vorteil aus – der Optimierer schafft es, einen billigeren parallelen Plan für Q2 zu erstellen, wodurch die in 9.3 eingeführte schlechte Planauswahl außer Kraft gesetzt wird. Aber nur der Vollständigkeit halber hier die Ergebnisse ohne Q2.
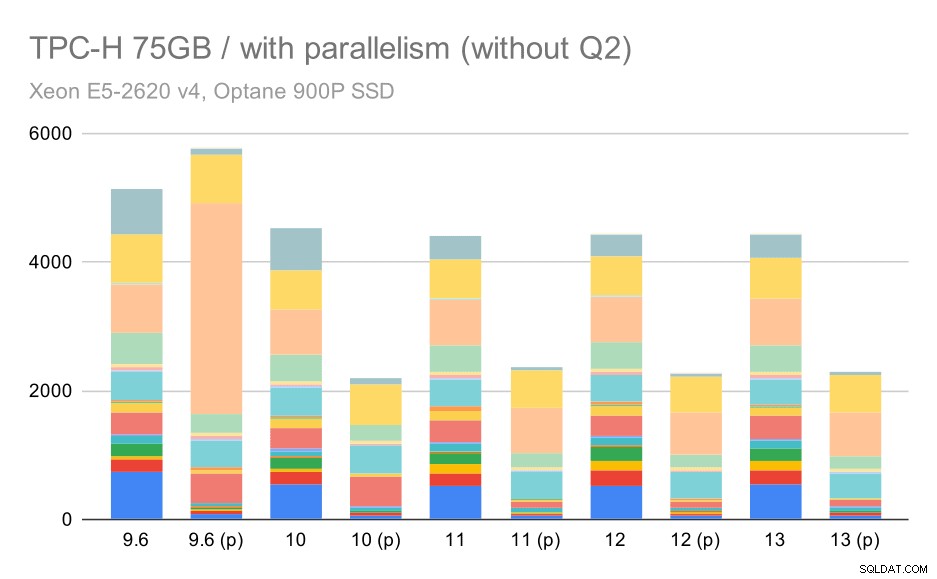
TPC-H-Abfragen bei großen Datensätzen (75 GB) – Parallelität aktiviert, ohne problematisches Q2
Sogar hier können Sie einige schlechte parallele Planoptionen erkennen – zum Beispiel ist der parallele Plan für Q9 schlechter bis 11, wo er schneller wird – wahrscheinlich dank 11, der zusätzliche parallele Executor-Knoten unterstützt. Andererseits werden einige parallele Abfragen (Q18, Q20) auf 11 langsamer, also sind es nicht nur Regenbögen und Einhörner.
Zusammenfassung und Zukunft
Ich denke, dass diese Ergebnisse die seit PostgreSQL 8.3 implementierten Optimierungen gut demonstrieren. Die Tests mit deaktivierter Parallelität veranschaulichen Effizienzverbesserungen (d. h. mehr mit der gleichen Menge an Ressourcen erreichen) – das Laden von Daten wurde um etwa 30 % schneller und Abfragen wurden um etwa das Zweifache schneller. Es ist wahr, dass ich auf einige Probleme mit ineffizienten Abfrageplänen gestoßen bin, aber das ist ein inhärentes Risiko, wenn der Abfrageplaner intelligenter gemacht wird. Wir arbeiten kontinuierlich daran, die Ergebnisse zuverlässiger zu machen, und ich bin mir sicher, dass ich die meisten dieser Probleme durch eine kleine Optimierung der Konfiguration lösen könnte.
Die Ergebnisse mit aktiviertem Parallelismus zeigen, dass wir zusätzliche Ressourcen effektiv nutzen können (insbesondere CPU-Kerne). Die Datenlasten scheinen davon nicht sehr zu profitieren – zumindest nicht in diesem Benchmark, aber die Auswirkungen auf die Abfrageausführung sind erheblich, was zu einer ~2-fachen Beschleunigung führt (obwohl verschiedene Abfragen natürlich unterschiedlich betroffen sind).
Es gibt viele Möglichkeiten, dies in zukünftigen PostgreSQL-Versionen zu verbessern. Beispielsweise gibt es eine Patch-Reihe, die Parallelität für COPY implementiert und das Laden von Daten beschleunigt. Es gibt verschiedene Patches, die die Ausführung analytischer Abfragen verbessern – von kleinen lokalisierten Optimierungen bis hin zu großen Projekten wie spaltenweise Speicherung und Ausführung, Aggregat-Pushdown usw. Auch durch die Verwendung von deklarativer Partitionierung kann viel gewonnen werden – eine Funktion, die ich bei der Arbeit daran meistens ignoriert habe Benchmark, einfach weil es den Umfang viel zu sehr vergrößern würde. Und ich bin mir sicher, dass es viele andere Möglichkeiten gibt, die ich mir nicht einmal vorstellen kann, aber klügere Leute in der PostgreSQL-Community arbeiten bereits daran.
Anhang:PostgreSQL-Konfiguration
Parallelität deaktiviert
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =0max_parallel_maintenance_workers =0# optimizerdefault_statistics_target =1000random_page_cost =60 Effective_cache_size =32 GB
Parallelität aktiviert
shared_buffers =4GBwork_mem =128MBvacuum_cost_limit =1000max_wal_size =24GBcheckpoint_timeout =30mincheckpoint_completion_target =0.9# logginglog_checkpoints =onlog_connections =onlog_disconnections =onlog_line_prefix ='%t %c:%l %x/%v 'log_lock_waits =onlog_temp_files =1024# parallel querymax_parallel_workers_per_gather =16max_parallel_maintenance_workers =16max_worker_processes =32max_parallel_workers =32# optimizerdefault_statistics_target =1000random_page_cost =60 Effective_cache_size =32 GB