Vor ein paar Jahren (auf der pgconf.eu 2014 in Madrid) hielt ich einen Vortrag mit dem Titel „Performance Archaeology“, der zeigte, wie sich die Leistung in den letzten PostgreSQL-Versionen verändert hat. Ich habe diesen Vortrag gehalten, weil ich denke, dass die langfristige Sichtweise interessant ist und uns Einblicke geben kann, die sehr wertvoll sein können. Für Leute, die wie ich tatsächlich an PostgreSQL-Code arbeiten, ist es ein nützlicher Leitfaden für die zukünftige Entwicklung, und für PostgreSQL-Benutzer kann es bei der Bewertung von Upgrades hilfreich sein.
Also habe ich beschlossen, diese Übung zu wiederholen und ein paar Blog-Beiträge zu schreiben, in denen die Leistung für eine Reihe von PostgreSQL-Versionen analysiert wird. Im Vortrag 2014 habe ich mit PostgreSQL 7.4 begonnen, das zu diesem Zeitpunkt etwa 10 Jahre alt war (Release 2003). Dieses Mal fange ich mit PostgreSQL 8.3 an, das ungefähr 12 Jahre alt ist.
Warum nicht wieder mit PostgreSQL 7.4 beginnen? Es gibt ungefähr drei Hauptgründe, warum ich mich entschieden habe, mit PostgreSQL 8.3 zu beginnen. Erstens allgemeine Faulheit. Je älter die Version, desto schwieriger kann es sein, sie mit aktuellen Compiler-Versionen usw. zu erstellen. Zweitens braucht es Zeit, um ordnungsgemäße Benchmarks auszuführen, insbesondere bei größeren Datenmengen, sodass das Hinzufügen einer einzelnen Hauptversion leicht ein paar Tage Maschinenzeit hinzufügen kann. Es schien sich einfach nicht zu lohnen. Und schließlich führte 8.3 eine Reihe wichtiger Änderungen ein – Autovacuum-Verbesserungen (standardmäßig aktiviert, gleichzeitige Worker-Prozesse, …), in den Kern integrierte Volltextsuche, verteilte Checkpoints und so weiter. Daher halte ich es für absolut sinnvoll, mit PostgreSQL 8.3 zu beginnen. Die vor etwa 12 Jahren veröffentlicht wurde, wird dieser Vergleich also tatsächlich einen längeren Zeitraum abdecken.
Ich habe mich entschieden, drei grundlegende Workload-Typen zu bewerten – OLTP, Analysen und Volltextsuche. Ich denke, dass OLTP und Analytik eine ziemlich offensichtliche Wahl sind, da die meisten Anwendungen eine Mischung aus diesen beiden Grundtypen sind. Die Volltextsuche ermöglicht es mir, Verbesserungen bei speziellen Arten von Indizes zu demonstrieren, die auch verwendet werden, um beliebte Datentypen wie JSONB, von PostGIS verwendete Typen usw. zu indizieren.
Warum überhaupt?
Lohnt sich der Aufwand tatsächlich? Schließlich führen wir während der Entwicklung ständig Benchmarks durch, um zu zeigen, dass ein Patch hilft und/oder dass er keine Regressionen verursacht, richtig? Das Problem ist, dass dies normalerweise nur „Teil“-Benchmarks sind, die zwei bestimmte Commits vergleichen, und normalerweise mit einer ziemlich begrenzten Auswahl an Workloads, die unserer Meinung nach relevant sein könnten. Was durchaus Sinn macht – Sie können einfach nicht für jeden Commit eine volle Batterie an Workloads ausführen.
Hin und wieder (normalerweise kurz nach der Veröffentlichung einer neuen Hauptversion von PostgreSQL) führen Leute Tests durch, in denen die neue Version mit der vorherigen verglichen wird, was nett ist, und ich ermutige Sie, solche Benchmarks durchzuführen (sei es eine Art Standard-Benchmark oder etwas Spezifisches für Ihre Anwendung). Es ist jedoch schwierig, diese Ergebnisse zu einer längerfristigen Ansicht zu kombinieren, da diese Tests unterschiedliche Konfigurationen und Hardware verwenden (normalerweise eine neuere für die neuere Version) und so weiter. Daher ist es schwierig, Änderungen im Allgemeinen klar zu beurteilen.
Gleiches gilt für die Anwendungsleistung, die natürlich der „ultimative Maßstab“ ist. Aber die Leute aktualisieren möglicherweise nicht auf jede Hauptversion (manchmal können sie ein paar Versionen überspringen, z. B. von 9.5 auf 12). Und wenn sie upgraden, wird es oft mit Hardware-Upgrades usw. kombiniert. Ganz zu schweigen davon, dass sich Anwendungen im Laufe der Zeit weiterentwickeln (neue Funktionen, zusätzliche Komplexität), die Datenmengen und die Anzahl gleichzeitiger Benutzer wachsen usw.
Das versucht diese Blogserie aufzuzeigen – langfristige Trends in der PostgreSQL-Leistung für einige grundlegende Workloads, damit wir – die Entwickler – ein warmes und wohliges Gefühl über die gute Arbeit im Laufe der Jahre bekommen. Und um den Benutzern zu zeigen, dass, obwohl PostgreSQL zu diesem Zeitpunkt ein ausgereiftes Produkt ist, es immer noch signifikante Verbesserungen in jeder neuen Hauptversion gibt.
Es ist nicht mein Ziel, diese Benchmarks zum Vergleich mit anderen Datenbankprodukten zu verwenden oder Ergebnisse zu produzieren, die einem offiziellen Ranking (wie dem TPC-H) entsprechen. Mein Ziel ist einfach, mich als PostgreSQL-Entwickler weiterzubilden, vielleicht einige Probleme zu identifizieren und zu untersuchen und die Erkenntnisse mit anderen zu teilen.
Fairer Vergleich?
Ich denke nicht, dass solche Vergleiche von Versionen, die über 12 Jahre veröffentlicht wurden, nicht ganz fair sein können, da jede Software in einem bestimmten Kontext entwickelt wird – Hardware ist ein gutes Beispiel für ein Datenbanksystem. Wenn Sie sich die Maschinen ansehen, die Sie vor 12 Jahren benutzt haben, wie viele Kerne hatten sie, wie viel RAM? Welche Art von Speicher wurde verwendet?
Ein typischer Midrange-Server im Jahr 2008 hatte vielleicht 8-12 Kerne, 16 GB RAM und ein RAID mit ein paar SAS-Laufwerken. Ein typischer Midrange-Server verfügt heute möglicherweise über ein paar Dutzend Kerne, Hunderte von GB RAM und SSD-Speicher.
Die Softwareentwicklung ist nach Priorität organisiert – es gibt immer mehr potenzielle Aufgaben, als Sie Zeit haben, also müssen Sie Aufgaben mit dem besten Kosten-Nutzen-Verhältnis für Ihre Benutzer auswählen (insbesondere diejenigen, die das Projekt direkt oder indirekt finanzieren). Und im Jahr 2008 waren einige Optimierungen wahrscheinlich noch nicht relevant – die meisten Maschinen hatten nicht extrem viel RAM, so dass sich beispielsweise die Optimierung für große gemeinsam genutzte Puffer noch nicht lohnte. Und viele der CPU-Engpässe wurden von E/A überschattet, weil die meisten Maschinen über „Spinning-Rost“-Speicher verfügten.
Anmerkung:Natürlich gab es auch damals schon Kunden mit ziemlich großen Maschinen. Einige verwendeten Community-Postgres mit verschiedenen Optimierungen, andere entschieden sich für eine der verschiedenen Postgres-Forks mit zusätzlichen Funktionen (z. B. massive Parallelität, verteilte Abfragen, Verwendung von FPGA usw.). Und das hat natürlich auch die Community-Entwicklung beeinflusst.
Als die größeren Maschinen im Laufe der Jahre immer häufiger wurden, konnten sich immer mehr Menschen Maschinen mit viel RAM und einer hohen Anzahl von Kernen leisten, wodurch sich das Kosten-Nutzen-Verhältnis verschob. Die Engpässe wurden untersucht und behoben, sodass neuere Versionen eine bessere Leistung erbringen.
Daher ist so ein Benchmark immer etwas unfair – je nach Setup (Hardware, Config) wird entweder die ältere oder die neuere Version favorisiert. Ich habe versucht, Hardware- und Konfigurationsparameter so auszuwählen, dass es für ältere Versionen nicht zu schlecht ist.
Der Punkt, den ich zu machen versuche, ist, dass dies nicht bedeutet, dass die älteren PostgreSQL-Versionen Mist waren – so funktioniert Softwareentwicklung. Sie beheben die Engpässe, auf die Ihre Benutzer wahrscheinlich stoßen werden, nicht die Engpässe, auf die sie in 10 Jahren stoßen könnten.
Hardware
Ich bevorzuge Benchmarks auf physischer Hardware, auf die ich direkten Zugriff habe, weil ich so alle Details kontrollieren kann, ich Zugriff auf alle Details habe und so weiter. Also habe ich die Maschine verwendet, die ich in unserem Büro habe – nichts Besonderes, aber hoffentlich gut genug für diesen Zweck.
- 2x E5-2620 v4 (16 Kerne, 32 Threads)
- 64 GB Arbeitsspeicher
- Intel Optane 900P 280 GB NVMe-SSD (Daten)
- 3 x 7.2k SATA RAID0 (temporärer Tablespace)
- Kernel 5.6.15, ext4
- gcc 9.2.0, clang 9.0.1
Ich habe auch eine zweite – viel kleinere – Maschine mit nur 4 Kernen und 8 GB RAM verwendet, die im Allgemeinen die gleichen Verbesserungen / Rückgänge zeigt, nur weniger ausgeprägt.
pgbench
Als Benchmarking-Tool habe ich den bekannten pgbench verwendet, wobei ich die neueste Version (ab PostgreSQL 13) verwendet habe, um alle Versionen zu testen. Dies eliminiert mögliche Verzerrungen aufgrund von Optimierungen, die im Laufe der Zeit in pgbench vorgenommen wurden, und macht die Ergebnisse vergleichbarer.
Der Benchmark testet eine Reihe verschiedener Fälle, wobei eine Reihe von Parametern variiert werden, nämlich:
Skala
- klein – Daten passen in gemeinsam genutzte Puffer, zeigen Sperrprobleme usw.
- mittel – Daten, die größer als gemeinsam genutzte Puffer sind, aber in RAM passen, normalerweise CPU-gebunden (oder möglicherweise I/O für Lese-Schreib-Workloads)
- groß – Daten größer als RAM, hauptsächlich I/O-gebunden
Modi
- schreibgeschützt – pgbench -S
- Lesen-Schreiben – pgbench -N
Kundenzahlen
- 1, 4, 8, 16, 32, 64, 128, 256
- Die Anzahl der pgbench-Threads (-j) wird entsprechend angepasst
Ergebnisse
OK, schauen wir uns die Ergebnisse an. Ich werde zuerst Ergebnisse aus dem NVMe-Speicher präsentieren, dann zeige ich einige interessante Ergebnisse mit dem SATA-RAID-Speicher.
NVMe-SSD / schreibgeschützt
Für den kleinen Datensatz (der vollständig in gemeinsam genutzte Puffer passt) sehen die schreibgeschützten Ergebnisse wie folgt aus:
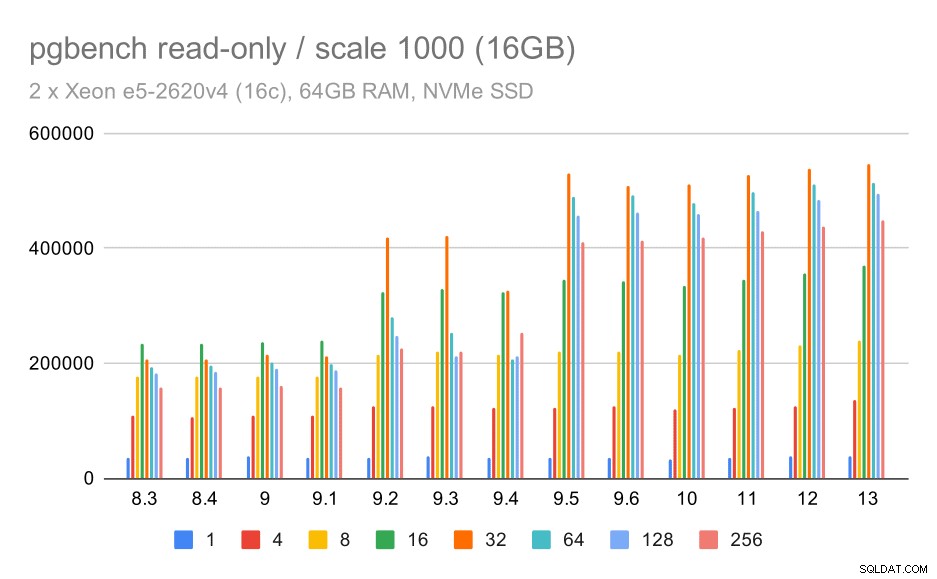
pgbench-Ergebnisse / schreibgeschützt bei kleinem Datensatz (Skala 100, d. h. 1,6 GB)
In 9.2, das eine Reihe von Leistungsverbesserungen enthielt, gab es eindeutig eine signifikante Steigerung des Durchsatzes, zum Beispiel Fast-Path für das Sperren. Der Durchsatz für einen einzelnen Client sinkt tatsächlich etwas – von 47.000 tps auf nur etwa 42.000 tps. Aber für höhere Clientzahlen ist die Verbesserung in 9.2 ziemlich deutlich.
pgbench-Ergebnisse / schreibgeschützt auf mittlerem Datensatz (Maßstab 1000, also 16 GB)
Für den mittleren Datensatz (der größer ist als gemeinsam genutzte Puffer, aber immer noch in den Arbeitsspeicher passt) scheint es auch in 9.2 eine gewisse Verbesserung zu geben, wenn auch nicht so deutlich wie oben, gefolgt von einer viel deutlicheren Verbesserung in 9.5, höchstwahrscheinlich dank Verbesserungen der Lock-Skalierbarkeit .
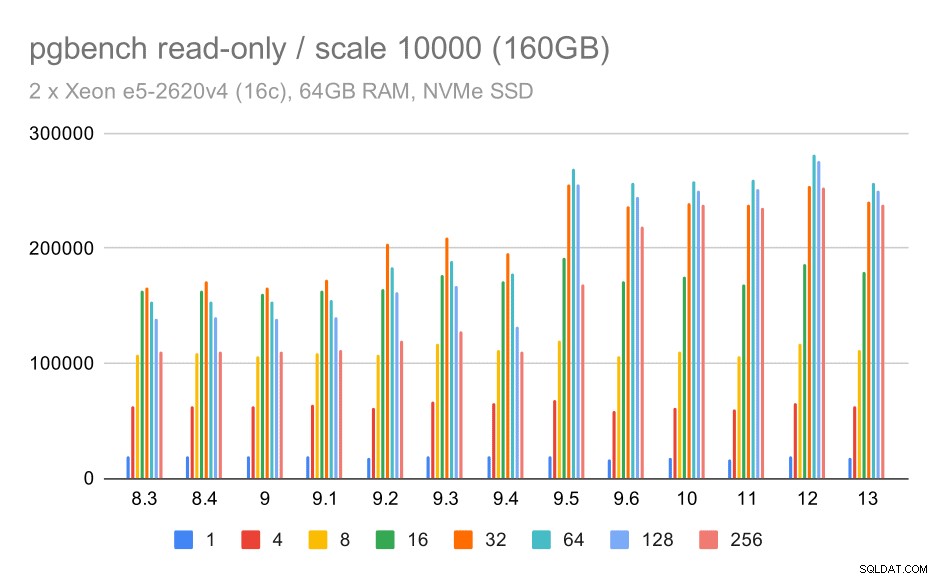
pgbench-Ergebnisse / schreibgeschützt bei großem Datensatz (Skalierung 10000, d. h. 160 GB)
Beim größten Datensatz, bei dem es hauptsächlich um die Fähigkeit zur effizienten Nutzung des Speichers geht, gibt es auch eine gewisse Beschleunigung – höchstwahrscheinlich auch dank der Verbesserungen von 9.5.
NVMe-SSD / Lese-/Schreibzugriff
Die Lese-Schreib-Ergebnisse zeigen ebenfalls einige Verbesserungen, wenn auch nicht so ausgeprägt. Auf dem kleinen Datensatz sehen die Ergebnisse so aus:
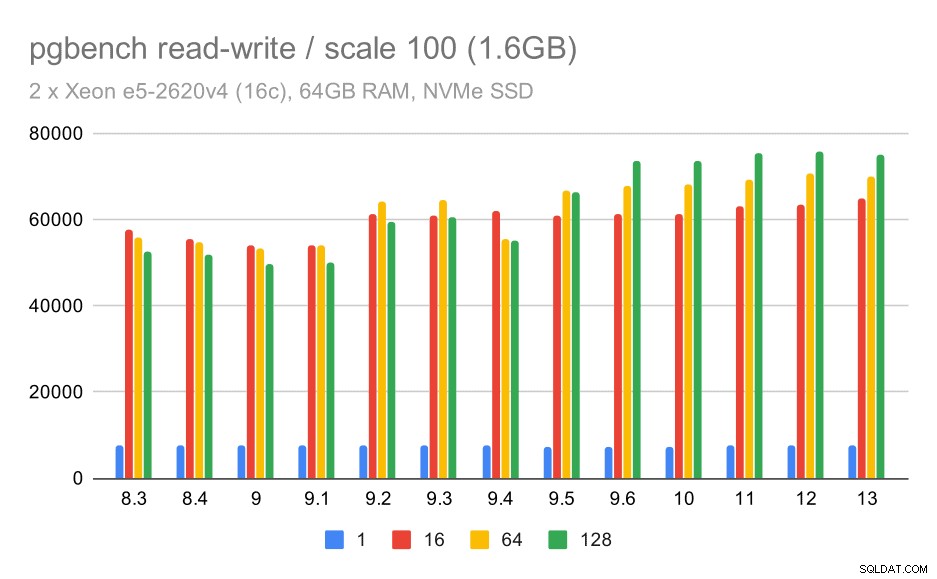
pgbench-Ergebnisse / Lesen-Schreiben bei kleinem Datensatz (Skala 100, dh 1,6 GB)
Also eine bescheidene Verbesserung von etwa 52.000 auf 75.000 tps bei ausreichender Anzahl von Clients.
Für den mittleren Datensatz ist die Verbesserung viel deutlicher – von etwa 27.000 auf 63.000 tps, d. h. der Durchsatz wird mehr als verdoppelt.
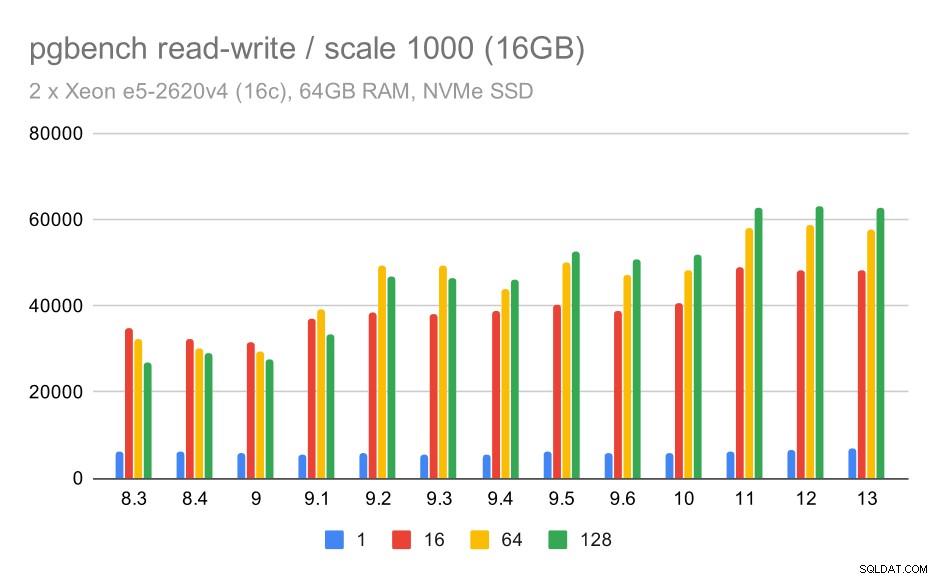
pgbench-Ergebnisse / Read-Write auf mittlerem Datensatz (Maßstab 1000, also 16 GB)
Für den größten Datensatz sehen wir eine ähnliche allgemeine Verbesserung, aber es scheint eine gewisse Regression zwischen 9,5 und 11 zu geben.
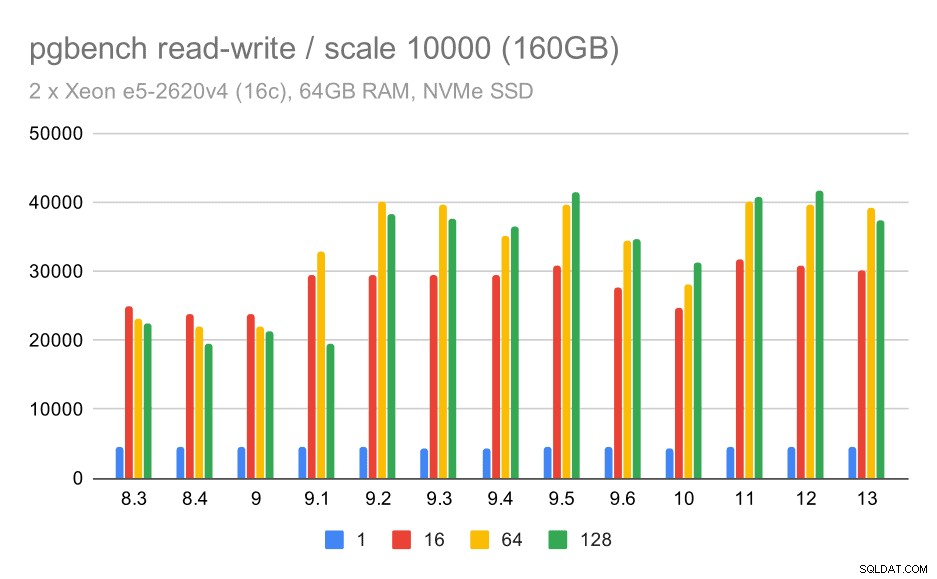
pgbench-Ergebnisse / Lese-/Schreibzugriff auf großen Datensatz (Skalierung 10000, d. h. 160 GB)
SATA-RAID / schreibgeschützt
Für den SATA-RAID-Speicher sind die Read-Only-Ergebnisse nicht so schön. Wir können die kleinen und mittleren Datensätze ignorieren, für die das Speichersystem keine Rolle spielt. Für den großen Datensatz ist der Durchsatz etwas laut, scheint aber mit der Zeit tatsächlich abzunehmen – insbesondere seit PostgreSQL 9.6. Ich weiß nicht, was der Grund dafür ist (nichts in den Versionshinweisen zu 9.6 sticht so hervor wie ein klarer Kandidat), aber es scheint eine Art Rückschritt zu sein.
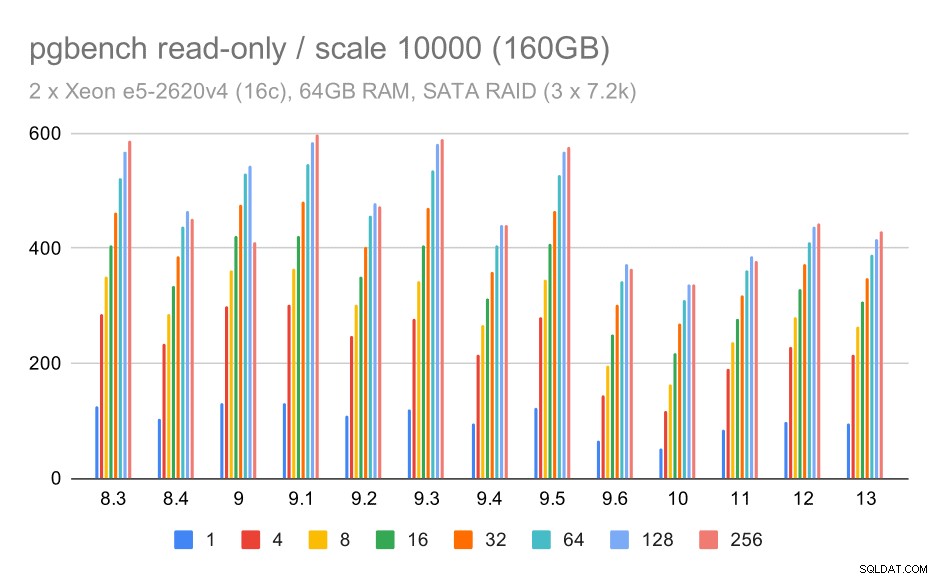
pgbench-Ergebnisse auf SATA-RAID / schreibgeschützt bei großem Datensatz (Skalierung 10000, d. h. 160 GB)
SATA RAID / Read-Write
Das Lese-Schreib-Verhalten scheint jedoch viel schöner zu sein. Auf dem kleinen Datensatz steigt der Durchsatz von etwa 600 tps auf über 6000 tps. Ich wette, das liegt an den Verbesserungen am Group Commit in 9.1 und 9.2.
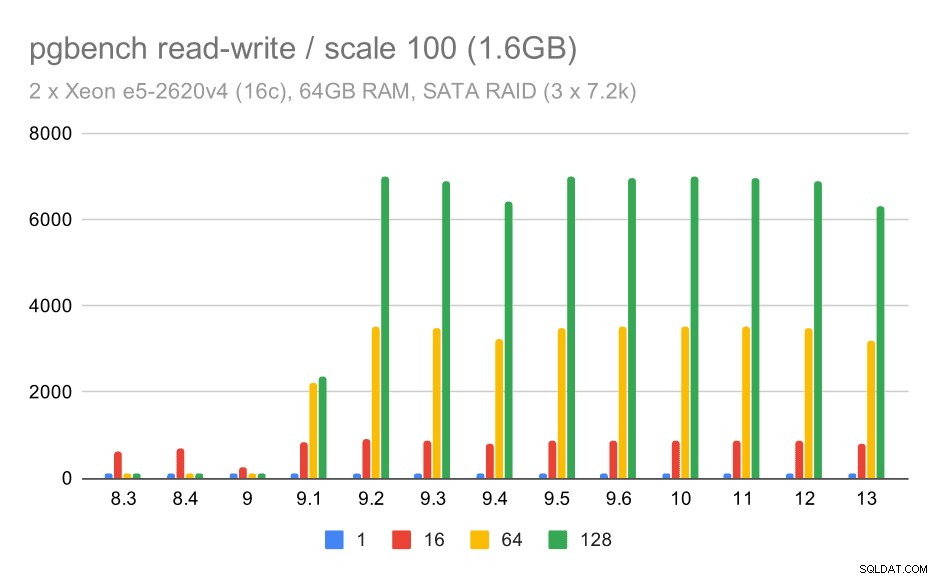
pgbench Ergebnisse auf SATA RAID / Read-Write bei kleinem Datensatz (Skalierung 100, also 1,6GB)
Für die mittleren und großen Skalen sehen wir eine ähnliche – aber kleinere – Verbesserung, da der Speicher auch die I/O-Anforderungen zum Lesen und Schreiben der Datenblöcke verarbeiten muss. Für den mittleren Maßstab müssen wir nur die Schreibvorgänge durchführen (da die Daten in den RAM passen), für den großen Maßstab müssen wir auch die Lesevorgänge durchführen – der maximale Durchsatz ist also noch geringer.
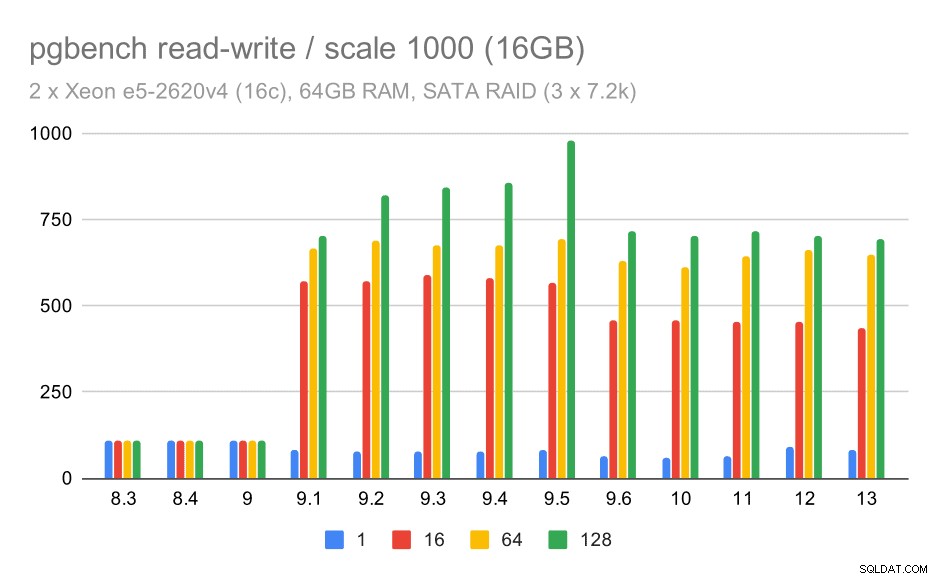
pgbench ergibt auf SATA RAID / read-write auf mittlerem Datensatz (Skala 1000, also 16GB)
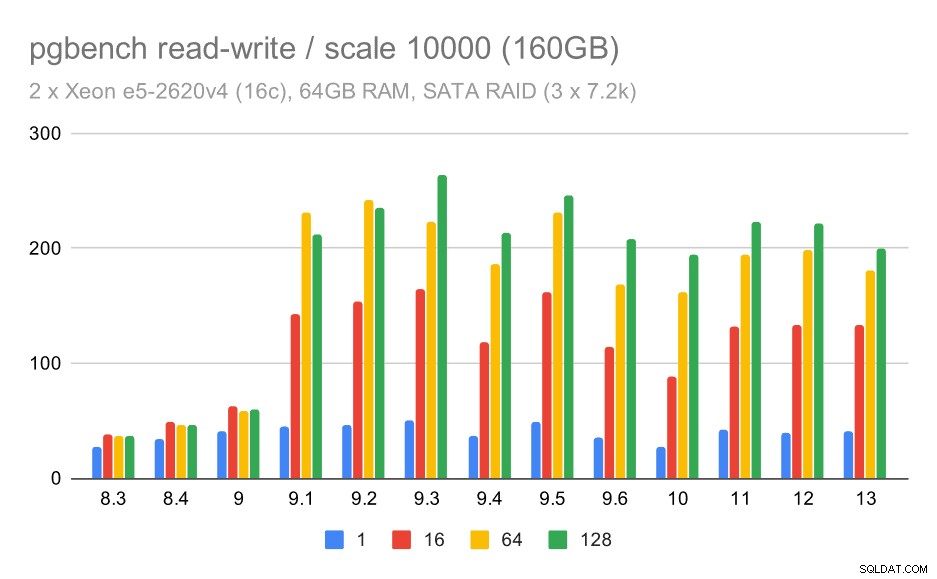
pgbench Ergebnisse auf SATA RAID / Read-Write bei großem Datensatz (Skalierung 10000, d.h. 160GB)
Zusammenfassung und Zukunft
Zusammenfassend scheinen die Schlussfolgerungen für das NVMe-Setup ziemlich positiv zu sein. Für die schreibgeschützte Arbeitslast gibt es dank Skalierbarkeitsoptimierungen eine moderate Beschleunigung in 9.2 und eine erhebliche Beschleunigung in 9.5, während sich die Leistung für die Lese-Schreib-Arbeitslast im Laufe der Zeit in mehreren Versionen / Schritten um etwa das Doppelte verbesserte.
Beim SATA-RAID-Setup fällt das Fazit allerdings etwas gemischt aus. Im Falle der Nur-Lese-Workload gibt es viel Variabilität/Rauschen und mögliche Regression in 9.6. Für die Lese-Schreib-Arbeitslast gibt es in 9.1 eine massive Beschleunigung, bei der der Durchsatz plötzlich von 100 tps auf etwa 600 tps gestiegen ist.
Was ist mit Verbesserungen in zukünftigen PostgreSQL-Versionen? Ich habe keine genaue Vorstellung davon, was die nächste große Verbesserung sein wird – ich bin mir jedoch sicher, dass andere PostgreSQL-Hacker auf brillante Ideen kommen werden, die die Dinge effizienter machen oder die Nutzung verfügbarer Hardwareressourcen ermöglichen. Der Patch zur Verbesserung der Skalierbarkeit bei vielen Verbindungen oder der Patch zur Unterstützung nichtflüchtiger WAL-Puffer sind Beispiele für solche Verbesserungen. Möglicherweise sehen wir einige radikale Verbesserungen bei der PostgreSQL-Speicherung (effizienteres Format auf der Festplatte, Verwendung von direkter E/A usw.), Indizierung usw.