In unserem letzten Artikel über Cursors in PostgreSQL haben wir über ommonable xpressions (CTE) gesprochen. Heute entdecken wir weiterhin neue Alternativen zu Cursorn, indem wir eine weniger bekannte Funktion von PostgreSQL verwenden.
Wir verwenden die Daten, die wir im vorherigen Artikel (oben verlinkt) importiert haben. Ich warte einen Moment, bis Sie dem Verfahren dort folgen.
Verstanden? Okay.
Die Daten sind ein Taxonomie-Diagramm der natürlichen Welt. Als Erinnerung an die Grundschulbiologie werden diese Daten von Carl von Linné in Königreich, Stamm, Klasse, Ordnung, Familie, Gattung und Art organisiert. Natürlich hat sich die Wissenschaft in den letzten 250 Jahren ganz leicht weiterentwickelt, sodass die taxonomische Tabelle 21 Ebenen tief ist. Wir finden den Hierarchiebaum in einer Tabelle, die (nicht überraschend) itis.hierarchy heißt .
Das Thema dieses Artikels ist die Verwendung von ltrees in PostgreSQL. Insbesondere, wie man sie zum sehr effizienten Durchlaufen eines komplexen Datensatzes verwendet. In diesem Sinne können wir sie als einen weiteren Ersatz für Cursor betrachten.
Die Daten werden (leider für uns) nicht in einem ltree-Format kuratiert, also werden wir sie für den Artikel ein wenig umwandeln.
Zuerst müssen Sie ltree in der Datenbank installieren, die Sie verwenden, um diesem Artikel zu folgen. Natürlich müssen Sie ein Superuser sein, um Erweiterungen zu installieren.
CREATE EXTENSION IF NOT EXISTS ltree;
Jetzt verwenden wir diese Erweiterung, um einige sehr effiziente Suchvorgänge bereitzustellen. Wir müssen die Daten in eine Nachschlagetabelle umwandeln. Um diese Transformation durchzuführen, verwenden wir die CTE-Technik, die wir im letzten Artikel behandelt haben. Nebenbei werden wir die lateinischen Namen und die englischen Namen zum Taxonomiebaum hinzufügen. Dies hilft uns, Artikel nach Nummer, lateinischen Namen oder englischen Namen zu suchen.
-- We need a little helper function to strip out illegal label names.
CREATE OR REPLACE FUNCTION strip_label(thelabel text)
RETURNS TEXT
AS $$
-- make sure all the characters in the label are legal
SELECT SELECT
regexp_replace(
regexp_replace(
regexp_replace(
regexp_replace(
-- strip anything not alnum (yes, this could be way more accurate)
thelabel, '[^[:alnum:]]', '_','g'),
-- consolidate underscores
'_+', '_', 'g'),
-- strip leading/trailing underscores
'^_*', '', 'g'),
'_*$', '', 'g');
$$
LANGUAGE sql;
CREATE MATERIALIZED VIEW itis.world_view AS
WITH RECURSIVE world AS (
-- Start with the basic kingdoms
SELECT h1.tsn, h1.parent_tsn, h1.tsn::text numeric_taxonomy,
-- There is no guarantee that there will be a textual name
COALESCE(l1.completename,h1.tsn::text,'')::text latin_taxonomy,
-- and again no guarantee of a common english name
COALESCE(v1.vernacular_name, lower(l1.completename),h1.tsn::text,'unk')::text english_taxonomy
FROM itis.hierarchy h1
LEFT JOIN itis.longnames l1
ON h1.tsn = l1.tsn
LEFT JOIN itis.vernaculars v1
ON (h1.tsn, 'English') = (v1.tsn, v1.language)
WHERE h1.parent_tsn = 0
UNION ALL
SELECT h1.tsn, h1.parent_tsn, w1.numeric_taxonomy || '.' || h1.tsn,
w1.latin_taxonomy || '.' || COALESCE(strip_label(l1.completename), h1.tsn::text,'unk'),
w1.english_taxonomy || '.' || strip_label(COALESCE(v1.vernacular_name, lower(l1.completename), h1.tsn::text, 'unk'))
FROM itis.hierarchy h1
JOIN world w1
ON h1.parent_tsn = w1.tsn
LEFT JOIN itis.longnames l1
ON h1.tsn = l1.tsn
LEFT JOIN -- just change this to "itis.vernaculars v1" to allow mulitples and all languages. (Millions of records.)
(SELECT tsn, min(vernacular_name) vernacular_name FROM itis.vernaculars WHERE language = 'English' GROUP BY tsn) v1
ON (h1.tsn) = (v1.tsn)
)
SELECT w2.tsn, w2.parent_tsn, w2.numeric_taxonomy::ltree, w2.latin_taxonomy::ltree latin_taxonomy, w2.english_taxonomy::ltree english_taxonomy
FROM world w2
ORDER BY w2.numeric_taxonomy
WITH NO DATA;
Lassen Sie uns einen Moment innehalten und die Blumen in dieser Abfrage riechen. Für den Anfang haben wir es erstellt, ohne Daten zu füllen. Dies gibt uns die Möglichkeit, uns um alle syntaktischen Probleme zu kümmern, bevor wir viele nutzlose Daten generieren. Wir verwenden die iterative Natur des allgemeinen Tabellenausdrucks, um hier eine ziemlich tiefe Struktur zusammenzustellen, und wir könnten sie leicht erweitern, um mehr Sprachen abzudecken, indem wir Daten zur Umgangssprachentabelle hinzufügen. Die materialisierte Ansicht hat auch einige interessante Leistungsmerkmale. Die Tabelle wird abgeschnitten und neu erstellt, wenn ein REFRESH MATERIALIZED VIEW ausgeführt wird heißt.
Als nächstes werden wir unser Weltbild auffrischen. Vor allem, weil es gesund ist, das von Zeit zu Zeit zu tun. Aber in diesem Fall füllt es die materialisierte Ansicht tatsächlich mit Daten aus itis Schema.
REFRESH MATERIALIZED VIEW itis.world_view;Es dauert einige Minuten, um die über 600.000 Zeilen aus den Daten zu erstellen.
Die ersten paar Zeilen sehen so aus:
┌────────────┬─────────┬───────────────────────────────────────────────────────────────────────────────┐
│ parent_tsn │ tsn │ english_taxonomy │
├────────────┼─────────┼───────────────────────────────────────────────────────────────────────────────┤
│ 768374 │ 1009037 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…│
│ │ │…_xanthophilus │
│ 768374 │ 1009038 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…│
│ │ │…_zoyphion │
│ 768374 │ 1009039 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.gastrosericus.gastrosericus…│
│ │ │…_zyx │
│ 768216 │ 768387 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.holotachysphex │
│ 768387 │ 1009040 │ animals.bilateria.protostomia.ecdysozoa.arthropods.hexapods.insects.winged_in…│
│ │ │…sects.modern_wing_folding_insects.holometabola.ants.ants.aculeata.apoid_wasps…│
│ │ │….cicadakillers.crabroninae.larrini.gastrosericina.holotachysphex.holotachysph…│
│ │ │…ex_holognathus │
└────────────┴─────────┴───────────────────────────────────────────────────────────────────────────────┘In einer Taxonomie würde das Diagramm etwa so aussehen:
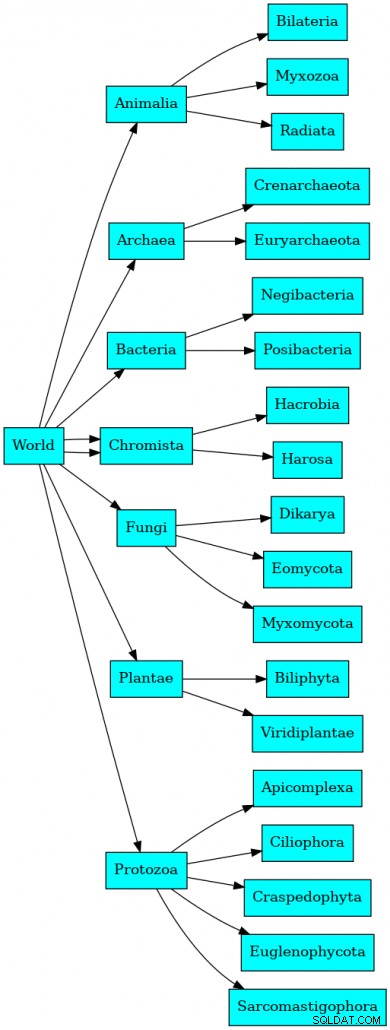
Natürlich wäre es tatsächlich 21 Ebenen tief und mehr als 600.000 Datensätze insgesamt.
Jetzt kommen wir zum lustigen Teil! ltrees bieten eine Möglichkeit, einige sehr komplexe Abfragen in einer Hierarchie durchzuführen. Die Hilfe dazu finden Sie in der PostgreSQL-Dokumentation, daher gehen wir hier nicht sehr tief darauf ein. Zum (sehr schnellen) Verständnis wird jedes Segment eines ltree als Label bezeichnet. Also dieser ltree kingdom.phylum.class.order.family.genus.species hat 7 Labels.
Abfragen für einen ltree verwenden eine spezielle Notation, die in eingeschränkter Form regulären Ausdrücken ähnelt.
Hier ist ein einfaches Beispiel:Animalia.*.Homo_sapiens
Eine Abfrage, um die Menschheit in der Welt zu finden, würde also so aussehen:
SELECT tsn, parent_tsn, latin_taxonomy, english_taxonomy
FROM itis.world_view WHERE latin_taxonomy ~ 'Animalia.*.Homo_sapiens';Was zu dem erwarteten Ergebnis führt:
┌────────┬────────────┬────────────────────────────────────────────────┬─────────────────────────────────────────────┐
│ tsn │ parent_tsn │ latin_taxonomy │ english_taxonomy │
├────────┼────────────┼────────────────────────────────────────────────┼─────────────────────────────────────────────┤
│ 180092 │ 180091 │ Animalia.Bilateria.Deuterostomia.Chordata.Vert…│ animals.bilateria.deuterostomia.chordates.v…│
│ │ │…ebrata.Gnathostomata.Tetrapoda.Mammalia.Theria…│…ertebrates.gnathostomata.tetrapoda.mammals.…│
│ │ │….Eutheria.Primates.Haplorrhini.Simiiformes.Hom…│…theria.eutheria.primates.haplorrhini.simiif…│
│ │ │…inoidea.Hominidae.Homininae.Homo.Homo_sapiens │…ormes.hominoidea.Great_Apes.African_apes.ho…│
│ │ │ │…minoids.Human │
└────────┴────────────┴────────────────────────────────────────────────┴─────────────────────────────────────────────┘Dabei würde es PostgreSQL natürlich nie belassen. Es gibt einen umfangreichen Satz von Operatoren, Indizes, Transformationen und Beispielen.
Werfen Sie einen Blick auf die zahlreichen Möglichkeiten, die diese Technik freisetzt.
Stellen Sie sich nun vor, dass diese Technik auf andere komplexe Datentypen wie Teilenummern, Fahrzeugidentifikationsnummern, Stücklistenstrukturen oder andere Klassifizierungssysteme angewendet wird. Es ist nicht notwendig, diese Struktur dem Endbenutzer wegen der unerschwinglich komplexen Lernkurve für ihre direkte Verwendung offenzulegen. Aber es ist durchaus möglich, einen „Lookup“-Bildschirm basierend auf einer Struktur wie dieser zu erstellen, die sehr leistungsfähig ist und die Komplexität der Implementierung verbirgt.
Für unseren nächsten Artikel in der Serie werden wir die Verwendung von Plug-in-Sprachen untersuchen. Im Zusammenhang mit der Suche nach Alternativen zu Cursorn in PostgreSQL verwenden wir eine Sprache unserer Wahl, um die Daten auf die für unsere Bedürfnisse am besten geeignete Weise zu modellieren. Bis zum nächsten Mal!