Vakuum ist eine der wichtigsten Funktionen zum Zurückgewinnen gelöschter Tupel in Tabellen und Indizes. Ohne Vakuum würden Tabellen und Indizes ins Unermessliche wachsen. Dieser Blogbeitrag beschreibt die Option PARALLEL für den Befehl VACUUM, die neu in PostgreSQL13 eingeführt wurde.
Vakuumverarbeitungsphasen
Bevor wir die neue Option ausführlich besprechen, sehen wir uns die Details der Vakuumfunktion an.
Vakuum (ohne FULL-Option) besteht aus fünf Phasen. Für eine Tabelle mit zwei Indizes funktioniert es beispielsweise wie folgt:
- Heap-Scan-Phase
- Scanne die Tabelle von oben und sammle Mülltupel im Speicher.
- Index Vakuumphase
- Saugen Sie beide Indexe nacheinander ab.
- Heap-Vakuumphase
- Sauge den Haufen (Tabelle).
- Indexbereinigungsphase
- Bereinigen Sie beide Indizes nacheinander.
- Heap-Truncation-Phase
- Leere Seiten am Ende der Tabelle abschneiden.
In der Heap-Scan-Phase kann das Vakuum die Sichtbarkeitskarte verwenden, um die Verarbeitung von Seiten zu überspringen, von denen bekannt ist, dass sie keinen Müll enthalten, während sowohl in der Index-Vakuum-Phase als auch in der Index-Bereinigungsphase, je nach Indexzugriffsmethoden, ein ganzer Index-Scan durchgeführt wird ist erforderlich.
Zum Beispiel erfordern Btree-Indizes, der beliebteste Indextyp, einen vollständigen Index-Scan, um Garbage-Tupel zu entfernen und eine Indexbereinigung durchzuführen. Da Vakuum immer durch einen einzelnen Prozess durchgeführt wird, werden die Indizes einzeln verarbeitet. Die längere Ausführungszeit des Vakuums auf besonders großen Tischen ärgert die Benutzer oft.
PARALLEL-Option
Um dieses Problem anzugehen, habe ich 2016 einen Patch zur Parallelisierung von Vakuum vorgeschlagen. Nach einem langen Überprüfungsprozess und vielen Reformen wurde die Option PARALLEL in PostgreSQL 13 eingeführt. Mit dieser Option kann Vakuum die Index-Vakuumphase und die Index-Bereinigungsphase mit durchführen Parallelarbeiter. Parallele Vakuumarbeiter werden gestartet, bevor sie entweder in die Index-Vakuumphase oder die Index-Bereinigungsphase eintreten, und am Ende der Phase beendet werden. Ein einzelner Worker wird einem Index zugewiesen. Das parallele Vakuumieren ist im Autovakuum immer deaktiviert.
Die Option PARALLEL ohne ganzzahliges Argument berechnet automatisch den Grad der Parallelität basierend auf der Anzahl der Indizes in der Tabelle.
VACUUM (PARALLEL) tbl;
Da der Leader-Prozess immer einen Index verarbeitet, beträgt die maximale Anzahl paralleler Worker (Anzahl der Indizes in der Tabelle – 1), was weiter auf max_parallel_maintenance_workers begrenzt ist. Der Zielindex muss größer oder gleich min_parallel_index_scan_size sein.
Mit der Option PARALLEL können wir den Grad der Parallelität angeben, indem wir einen ganzzahligen Wert ungleich Null übergeben. Das folgende Beispiel verwendet drei Worker für insgesamt vier parallele Prozesse.
VACUUM (PARALLEL 3) tbl;
Die Option PARALLEL ist standardmäßig aktiviert; Um paralleles Vakuum zu deaktivieren, setzen Sie max_parallel_maintenance_workers auf 0 oder geben Sie PARALLEL 0 an .
VACUUM (PARALLEL 0) tbl; -- disable parallel vacuum
Wenn wir uns die VACUUM VERBOSE-Ausgabe ansehen, können wir sehen, dass ein Worker den Index verarbeitet.
Die als "durch parallelen Arbeiter" gedruckten Informationen werden vom Arbeiter gemeldet.
VACUUM (PARALLEL, VERBOSE) tbl; INFO: vacuuming "public.tbl" INFO: launched 2 parallel vacuum workers for index vacuuming (planned: 2) INFO: scanned index "i1" to remove 112834 row versions DETAIL: CPU: user: 9.80 s, system: 3.76 s, elapsed: 23.20 s INFO: scanned index "i2" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.64 s, system: 8.98 s, elapsed: 42.84 s INFO: scanned index "i3" to remove 112834 row versions by parallel vacuum worker DETAIL: CPU: user: 10.65 s, system: 8.98 s, elapsed: 43.96 s INFO: "tbl": removed 112834 row versions in 112834 pages DETAIL: CPU: user: 1.12 s, system: 2.31 s, elapsed: 22.01 s INFO: index "i1" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i2" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: index "i3" now contains 150000000 row versions in 411289 pages DETAIL: 112834 index row versions were removed. 0 index pages have been deleted, 0 are currently reusable. CPU: user: 0.00 s, system: 0.00 s, elapsed: 0.00 s. INFO: "tbl": found 112834 removable, 112833240 nonremovable row versions in 553105 out of 735295 pages DETAIL: 0 dead row versions cannot be removed yet, oldest xmin: 430046 There were 444 unused item identifiers. Skipped 0 pages due to buffer pins, 0 frozen pages. 0 pages are entirely empty. CPU: user: 18.00 s, system: 8.99 s, elapsed: 91.73 s. VACUUM
Indexzugriffsmethoden im Vergleich zum Grad der Parallelität
Vakuum führt die Index-Vakuumphase und die Index-Bereinigungsphase nicht immer parallel durch. Wenn die Indexgröße klein ist oder bekannt ist, dass der Prozess schnell abgeschlossen werden kann, verursachen die Kosten für das Starten und Verwalten paralleler Worker für die Parallelisierung stattdessen Overhead. Abhängig von den Index-Zugriffsmethoden und ihrer Größe ist es besser, diese Phasen nicht durch einen parallelen Vakuum-Worker-Prozess auszuführen.
Beispielsweise kann beim Vakuumieren eines ausreichend großen btree-Index die Index-Vakuumphase des Index von einem parallelen Vakuum-Worker ausgeführt werden, da immer ein vollständiger Index-Scan erforderlich ist, während die Index-Bereinigungsphase von einem parallelen Vakuum-Worker des Index ausgeführt wird Staubsaugen wird nicht durchgeführt (d. h. es liegt kein Müll auf dem Tisch). Dies liegt daran, dass btree-Indizes in der Indexbereinigungsphase die Erfassung der Indexstatistiken erfordern, die auch während der Indexvakuumphase erfasst werden. Andererseits erfordern Hash-Indizes in der Index-Bereinigungsphase immer keinen Scan des Index.
Um verschiedene Arten von Index-Vakuum-Strategien zu unterstützen, können Entwickler von Index-Zugriffsmethoden diese Verhalten spezifizieren, indem sie Flags für die amparallelvacuumoptions setzen Feld der IndexAmRoutine Struktur. Die verfügbaren Flags sind wie folgt:
- VACUUM_OPTION_NO_PARALLEL (Standard)
- paralleles Vakuum ist in beiden Phasen deaktiviert.
- VACUUM_OPTION_PARALLEL_BULKDEL
- Die Index-Vakuumphase kann parallel durchgeführt werden.
- VACUUM_OPTION_PARALLEL_COND_CLEANUP
- Die Index-Bereinigungsphase kann parallel durchgeführt werden, wenn die Index-Vakuumphase noch nicht durchgeführt wurde.
- VACUUM_OPTION_PARALLEL_CLEANUP
- Die Index-Bereinigungsphase kann parallel durchgeführt werden, selbst wenn die Index-Vakuumphase den Index bereits verarbeitet hat.
Die folgende Tabelle zeigt, wie das in PostgreSQL integrierte Index-AM paralleles Vakuum unterstützt.
| nbtree | Hash | gin | Grundlagen | spgist | brin | Blüte | |
| VACUUM_OPTION_PARALLEL_BULKDEL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| VACUUM_OPTION_PARALLEL_COND_CLEANUP | ✓ | ✓ | ✓ | ||||
| VACUUM_OPTION_CLEANUP | ✓ | ✓ | ✓ |
Siehe ‘src/include/command/vacuum.h‘ für weitere Details.
Leistungsüberprüfung
Ich habe die Leistung des parallelen Vakuums auf meinem Laptop (Core i7 2,6 GHz, 16 GB RAM, 512 GB SSD) bewertet. Die Tabellengröße beträgt 6 GB und hat acht 3-GB-Indizes. Das Gesamtverhältnis beträgt 30 GB, was nicht in den Arbeitsspeicher der Maschine passt. Für jede Bewertung machte ich mehrere Prozent des Tisches nach dem Staubsaugen gleichmäßig schmutzig und führte dann ein Vakuum durch, während ich den Parallelgrad änderte. Das folgende Diagramm zeigt die Ausführungszeit des Vakuums.
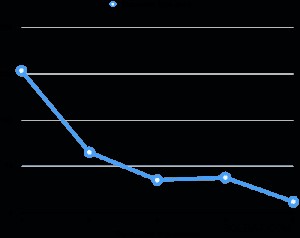
In allen Auswertungen machte die Ausführungszeit des Index-Vakuums mehr als 95 % der gesamten Ausführungszeit aus. Daher hat die Parallelisierung der Index-Vakuumphase dazu beigetragen, die Vakuumausführungszeit erheblich zu verkürzen.
Danke
Besonderer Dank geht an Amit Kapila für die engagierte Prüfung, Beratung und Übergabe dieser Funktion an PostgreSQL 13. Ich danke allen Entwicklern, die an dieser Funktion beteiligt waren, für die Prüfung, das Testen und die Diskussion.



