In Teil 1 dieser Serie haben Sie Flask und Connexion verwendet, um eine REST-API zu erstellen, die CRUD-Operationen für eine einfache In-Memory-Struktur namens PEOPLE bereitstellt . Das hat gezeigt, wie das Connexion-Modul Ihnen hilft, eine schöne REST-API zusammen mit einer interaktiven Dokumentation zu erstellen.
Wie einige in den Kommentaren zu Teil 1 angemerkt haben, die PEOPLE Die Struktur wird bei jedem Neustart der Anwendung neu initialisiert. In diesem Artikel erfahren Sie, wie Sie PEOPLE speichern Struktur und die von der API bereitgestellten Aktionen an eine Datenbank mit SQLAlchemy und Marshmallow.
SQLAlchemy stellt ein objektrelationales Modell (ORM) bereit, das Python-Objekte in einer Datenbankdarstellung der Objektdaten speichert. Das kann Ihnen helfen, weiterhin pythonisch zu denken und sich nicht darum zu kümmern, wie die Objektdaten in einer Datenbank dargestellt werden.
Marshmallow bietet Funktionen zum Serialisieren und Deserialisieren von Python-Objekten, während sie aus und in unsere JSON-basierte REST-API fließen. Marshmallow konvertiert Python-Klasseninstanzen in Objekte, die in JSON konvertiert werden können.
Den Python-Code für diesen Artikel finden Sie hier.
Kostenloser Bonus: Klicken Sie hier, um eine Kopie des Leitfadens „REST-API-Beispiele“ herunterzuladen und eine praktische Einführung in die Python- und REST-API-Prinzipien mit umsetzbaren Beispielen zu erhalten.
An wen richtet sich dieser Artikel?
Wenn Ihnen Teil 1 dieser Serie gefallen hat, erweitert dieser Artikel Ihren Werkzeuggürtel noch weiter. Sie verwenden SQLAlchemy, um auf eine Datenbank auf eine eher pythonische Weise als mit reinem SQL zuzugreifen. Sie verwenden Marshmallow auch zum Serialisieren und Deserialisieren der von der REST-API verwalteten Daten. Dazu nutzen Sie grundlegende objektorientierte Programmierfunktionen, die in Python verfügbar sind.
Sie werden SQLAlchemy auch verwenden, um eine Datenbank zu erstellen und mit ihr zu interagieren. Dies ist notwendig, um die REST-API mit PEOPLE zum Laufen zu bringen in Teil 1 verwendete Daten.
Die HTML- und JavaScript-Dateien der in Teil 1 vorgestellten Webanwendung werden geringfügig modifiziert, um die Änderungen ebenfalls zu unterstützen. Sie können die endgültige Version des Codes aus Teil 1 hier einsehen.
Zusätzliche Abhängigkeiten
Bevor Sie mit dem Erstellen dieser neuen Funktionalität beginnen, müssen Sie die von Ihnen erstellte virtuelle Umgebung aktualisieren, um den Code von Teil 1 auszuführen, oder eine neue Umgebung für dieses Projekt erstellen. Der einfachste Weg, dies zu tun, nachdem Sie Ihre virtuelle Umgebung aktiviert haben, ist die Ausführung dieses Befehls:
$ pip install Flask-SQLAlchemy flask-marshmallow marshmallow-sqlalchemy marshmallow
Dies fügt Ihrer virtuellen Umgebung mehr Funktionalität hinzu:
-
Flask-SQLAlchemyfügt SQLAlchemy zusammen mit einigen Verbindungen zu Flask hinzu, wodurch Programme auf Datenbanken zugreifen können. -
flask-marshmallowfügt die Flask-Teile von Marshmallow hinzu, mit denen Programme Python-Objekte in und aus serialisierbaren Strukturen konvertieren können. -
marshmallow-sqlalchemyfügt SQLAlchemy einige Marshmallow-Hooks hinzu, damit Programme von SQLAlchemy generierte Python-Objekte serialisieren und deserialisieren können. -
marshmallowfügt den Großteil der Marshmallow-Funktionalität hinzu.
Personendaten
Wie oben erwähnt, die PEOPLE Datenstruktur im vorherigen Artikel ist ein In-Memory-Python-Wörterbuch. In diesem Wörterbuch haben Sie den Nachnamen der Person als Suchschlüssel verwendet. Die Datenstruktur sah im Code so aus:
# Data to serve with our API
PEOPLE = {
"Farrell": {
"fname": "Doug",
"lname": "Farrell",
"timestamp": get_timestamp()
},
"Brockman": {
"fname": "Kent",
"lname": "Brockman",
"timestamp": get_timestamp()
},
"Easter": {
"fname": "Bunny",
"lname": "Easter",
"timestamp": get_timestamp()
}
}
Die Änderungen, die Sie am Programm vornehmen, verschieben alle Daten in eine Datenbanktabelle. Das bedeutet, dass die Daten auf Ihrer Festplatte gespeichert werden und zwischen den Ausführungen von server.py bestehen bleiben Programm.
Da der Nachname der Wörterbuchschlüssel war, beschränkte der Code die Änderung des Nachnamens einer Person:Nur der Vorname konnte geändert werden. Außerdem ermöglicht Ihnen der Wechsel zu einer Datenbank, den Nachnamen zu ändern, da dieser nicht mehr als Suchschlüssel für eine Person verwendet wird.
Konzeptionell kann man sich eine Datenbanktabelle als ein zweidimensionales Array vorstellen, bei dem die Zeilen Datensätze und die Spalten Felder in diesen Datensätzen sind.
Datenbanktabellen haben normalerweise einen automatisch inkrementierenden ganzzahligen Wert als Suchschlüssel für Zeilen. Dies wird als Primärschlüssel bezeichnet. Jeder Datensatz in der Tabelle hat einen Primärschlüssel, dessen Wert in der gesamten Tabelle eindeutig ist. Wenn Sie einen Primärschlüssel haben, der von den in der Tabelle gespeicherten Daten unabhängig ist, können Sie jedes andere Feld in der Zeile ändern.
Hinweis:
Der automatisch inkrementierende Primärschlüssel bedeutet, dass die Datenbank sich um Folgendes kümmert:
- Inkrementieren des größten vorhandenen Primärschlüsselfelds jedes Mal, wenn ein neuer Datensatz in die Tabelle eingefügt wird
- Diesen Wert als Primärschlüssel für die neu eingefügten Daten verwenden
Dies garantiert einen eindeutigen Primärschlüssel, wenn die Tabelle wächst.
Sie werden einer Datenbankkonvention folgen und die Tabelle im Singular benennen, sodass die Tabelle person genannt wird . Unsere PEOPLE übersetzen obige Struktur in eine Datenbanktabelle mit dem Namen person gibt dir das:
| Personen-ID | Name | Name | Zeitstempel |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockmann | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Ostern | Hase | 2018-08-08 21:16:01.886834 |
Jede Spalte in der Tabelle hat einen Feldnamen wie folgt:
person_id: Primärschlüsselfeld für jede Personlname: Nachname der Personlname: Vorname der Persontimestamp: Zeitstempel, der Einfüge-/Aktualisierungsaktionen zugeordnet ist
Datenbankinteraktion
Sie werden SQLite als Datenbank-Engine verwenden, um die PEOPLE zu speichern Daten. SQLite ist die am weitesten verbreitete Datenbank der Welt und wird kostenlos mit Python geliefert. Es ist schnell, erledigt seine ganze Arbeit mit Dateien und eignet sich für sehr viele Projekte. Es ist ein vollständiges RDBMS (Relational Database Management System), das SQL enthält, die Sprache vieler Datenbanksysteme.
Stellen Sie sich für den Moment die person vor Tabelle existiert bereits in einer SQLite-Datenbank. Wenn Sie Erfahrung mit RDBMS haben, kennen Sie wahrscheinlich SQL, die strukturierte Abfragesprache, die die meisten RDBMS verwenden, um mit der Datenbank zu interagieren.
Im Gegensatz zu Programmiersprachen wie Python definiert SQL nicht wie um die Daten zu bekommen:es beschreibt was Daten erwünscht sind, bleibt das wie bis zur Datenbank-Engine.
Eine SQL-Abfrage, die alle Daten in unserer person erhält Tabelle, sortiert nach Nachnamen, würde so aussehen:
SELECT * FROM person ORDER BY 'lname';
Diese Abfrage weist die Datenbank-Engine an, alle Felder aus der Personentabelle abzurufen und sie in der standardmäßig aufsteigenden Reihenfolge unter Verwendung von lname zu sortieren Feld.
Wenn Sie diese Abfrage für eine SQLite-Datenbank ausführen, die person enthält Tabelle, wären die Ergebnisse eine Reihe von Datensätzen, die alle Zeilen in der Tabelle enthalten, wobei jede Zeile die Daten aus allen Feldern enthält, aus denen eine Zeile besteht. Unten sehen Sie ein Beispiel, in dem das SQLite-Befehlszeilentool die obige Abfrage für person ausführt Datenbanktabelle:
sqlite> SELECT * FROM person ORDER BY lname;
2|Brockman|Kent|2018-08-08 21:16:01.888444
3|Easter|Bunny|2018-08-08 21:16:01.889060
1|Farrell|Doug|2018-08-08 21:16:01.886834
Die obige Ausgabe ist eine Liste aller Zeilen in person Datenbanktabelle mit Pipe-Zeichen (‘|’), die die Felder in der Zeile trennen, was zu Anzeigezwecken von SQLite erledigt wird.
Python ist vollständig in der Lage, mit vielen Datenbank-Engines zu kommunizieren und die obige SQL-Abfrage auszuführen. Die Ergebnisse wären höchstwahrscheinlich eine Liste von Tupeln. Die äußere Liste enthält alle Datensätze in person Tisch. Jedes einzelne innere Tupel würde alle Daten enthalten, die jedes für eine Tabellenzeile definierte Feld darstellen.
Das Abrufen von Daten auf diese Weise ist nicht sehr pythonisch. Die Liste der Datensätze ist in Ordnung, aber jeder einzelne Datensatz ist nur ein Tupel von Daten. Es ist Sache des Programms, den Index jedes Felds zu kennen, um ein bestimmtes Feld abzurufen. Der folgende Python-Code verwendet SQLite, um zu demonstrieren, wie die obige Abfrage ausgeführt und die Daten angezeigt werden:
1import sqlite3
2
3conn = sqlite3.connect('people.db')
4cur = conn.cursor()
5cur.execute('SELECT * FROM person ORDER BY lname')
6people = cur.fetchall()
7for person in people:
8 print(f'{person[2]} {person[1]}')
Das obige Programm macht folgendes:
-
Zeile 1 importiert die
sqlite3Modul. -
Zeile 3 stellt eine Verbindung zur Datenbankdatei her.
-
Zeile 4 erstellt einen Cursor aus der Verbindung.
-
Zeile 5 verwendet den Cursor, um einen
SQLauszuführen als String ausgedrückte Abfrage. -
Zeile 6 erhält alle Datensätze, die von
SQLzurückgegeben werden Abfrage und ordnet sie denpeoplezu Variable. -
Linie 7 &8 über die
peopleiterieren Listenvariable und geben Sie den Vor- und Nachnamen jeder Person aus.
Die people Variable aus Zeile 6 oben würde in Python so aussehen:
people = [
(2, 'Brockman', 'Kent', '2018-08-08 21:16:01.888444'),
(3, 'Easter', 'Bunny', '2018-08-08 21:16:01.889060'),
(1, 'Farrell', 'Doug', '2018-08-08 21:16:01.886834')
]
Die Ausgabe des obigen Programms sieht so aus:
Kent Brockman
Bunny Easter
Doug Farrell
Im obigen Programm müssen Sie wissen, dass der Vorname einer Person im Index 2 steht , und der Nachname einer Person befindet sich im Index 1 . Schlimmer noch, die interne Struktur von person muss auch bekannt sein, wenn Sie die Iterationsvariable person übergeben als Parameter einer Funktion oder Methode.
Es wäre viel besser, wenn Sie das, was Sie für person zurückbekommen würden war ein Python-Objekt, wobei jedes der Felder ein Attribut des Objekts ist. Dies ist eine der Aufgaben von SQLAlchemy.
Kleine Bobby-Tische
Im obigen Programm ist die SQL-Anweisung eine einfache Zeichenfolge, die zur Ausführung direkt an die Datenbank übergeben wird. In diesem Fall ist das kein Problem, da das SQL ein String-Literal ist, das vollständig unter der Kontrolle des Programms steht. Der Anwendungsfall für Ihre REST-API nimmt jedoch Benutzereingaben aus der Webanwendung und verwendet sie zum Erstellen von SQL-Abfragen. Dies kann Ihre Anwendung für Angriffe öffnen.
Sie erinnern sich aus Teil 1, dass die REST-API eine einzelne person erhält aus den PEOPLE Daten sahen so aus:
GET /api/people/{lname}
Das bedeutet, dass Ihre API eine Variable erwartet, lname , im URL-Endpunktpfad, der verwendet wird, um eine einzelne person zu finden . Das Modifizieren des Python-SQLite-Codes von oben, um dies zu tun, würde in etwa so aussehen:
1lname = 'Farrell'
2cur.execute('SELECT * FROM person WHERE lname = \'{}\''.format(lname))
Das obige Code-Snippet bewirkt Folgendes:
-
Zeile 1 setzt den
lnameVariable zu'Farrell'. Dies würde aus dem Endpunktpfad der REST-API-URL stammen. -
Zeile 2 verwendet Python-String-Formatierung, um einen SQL-String zu erstellen und auszuführen.
Der Einfachheit halber setzt der obige Code den lname -Variable in eine Konstante, aber in Wirklichkeit würde sie aus dem API-URL-Endpunktpfad stammen und könnte alles sein, was vom Benutzer bereitgestellt wird. Das durch die Zeichenfolgenformatierung generierte SQL sieht folgendermaßen aus:
SELECT * FROM person WHERE lname = 'Farrell'
Wenn dieses SQL von der Datenbank ausgeführt wird, sucht es nach person Tabelle für einen Datensatz, bei dem der Nachname gleich 'Farrell' ist . Das ist beabsichtigt, aber jedes Programm, das Benutzereingaben akzeptiert, ist auch offen für böswillige Benutzer. Im Programm oben, wo der lname Variable durch Benutzereingaben gesetzt wird, öffnet dies Ihr Programm für einen sogenannten SQL-Injection-Angriff. Dies wird liebevoll als Little Bobby Tables bezeichnet:
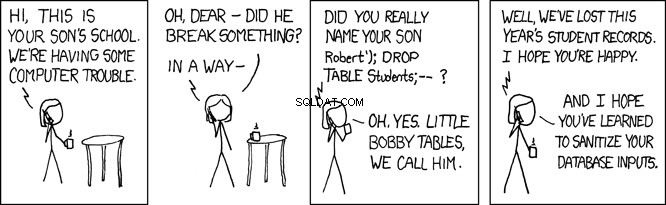
Stellen Sie sich beispielsweise einen böswilligen Benutzer vor, der Ihre REST-API folgendermaßen aufruft:
GET /api/people/Farrell');DROP TABLE person;
Die obige REST-API-Anforderung legt den lname fest Variable zu 'Farrell');DROP TABLE person;' , was im obigen Code diese SQL-Anweisung generieren würde:
SELECT * FROM person WHERE lname = 'Farrell');DROP TABLE person;
Die obige SQL-Anweisung ist gültig, und wenn sie von der Datenbank ausgeführt wird, findet sie einen Datensatz, in dem lname stimmt mit 'Farrell' überein . Dann findet es das SQL-Anweisungstrennzeichen ; und wird gleich weitermachen und die gesamte Tabelle fallen lassen. Dies würde Ihre Anwendung im Wesentlichen ruinieren.
Sie können Ihr Programm schützen, indem Sie alle Daten bereinigen, die Sie von Benutzern Ihrer Anwendung erhalten. Das Bereinigen von Daten in diesem Zusammenhang bedeutet, dass Ihr Programm die vom Benutzer bereitgestellten Daten untersucht und sicherstellt, dass sie nichts Gefährliches für das Programm enthalten. Dies kann schwierig zu machen sein und müsste überall dort durchgeführt werden, wo Benutzerdaten mit der Datenbank interagieren.
Es gibt einen anderen Weg, der viel einfacher ist:Verwenden Sie SQLAlchemy. Es wird Benutzerdaten für Sie bereinigen, bevor Sie SQL-Anweisungen erstellen. Dies ist ein weiterer großer Vorteil und Grund, SQLAlchemy bei der Arbeit mit Datenbanken zu verwenden.
Modellieren von Daten mit SQLAlchemy
SQLAlchemy ist ein großes Projekt und bietet viele Funktionen, um mit Datenbanken unter Verwendung von Python zu arbeiten. Eines der Dinge, die es bietet, ist ein ORM oder Object Relational Mapper, und das werden Sie verwenden, um die person zu erstellen und mit ihr zu arbeiten Datenbanktabelle. Dadurch können Sie eine Reihe von Feldern aus der Datenbanktabelle einem Python-Objekt zuordnen.
Die objektorientierte Programmierung ermöglicht es Ihnen, Daten mit Verhalten zu verbinden, den Funktionen, die mit diesen Daten arbeiten. Indem Sie SQLAlchemy-Klassen erstellen, können Sie die Felder aus den Zeilen der Datenbanktabelle mit dem Verhalten verbinden, sodass Sie mit den Daten interagieren können. Hier ist die SQLAlchemy-Klassendefinition für die Daten in person Datenbanktabelle:
class Person(db.Model):
__tablename__ = 'person'
person_id = db.Column(db.Integer,
primary_key=True)
lname = db.Column(db.String)
fname = db.Column(db.String)
timestamp = db.Column(db.DateTime,
default=datetime.utcnow,
onupdate=datetime.utcnow)
Die Klasse person erbt von db.Model , zu dem Sie gelangen, wenn Sie mit dem Erstellen des Programmcodes beginnen. Im Moment bedeutet dies, dass Sie von einer Basisklasse namens Model erben , die Attribute und Funktionen bereitstellt, die allen davon abgeleiteten Klassen gemeinsam sind.
Die restlichen Definitionen sind Attribute auf Klassenebene, die wie folgt definiert sind:
-
__tablename__ = 'person'verbindet die Klassendefinition mit derpersonDatenbanktabelle. -
person_id = db.Column(db.Integer, primary_key=True)erstellt eine Datenbankspalte, die eine Ganzzahl enthält, die als Primärschlüssel für die Tabelle dient. Dies teilt der Datenbank auch dieseperson_idmit wird ein automatisch inkrementierender Integer-Wert sein. -
lname = db.Column(db.String)erstellt das Nachnamenfeld, eine Datenbankspalte, die einen Zeichenfolgenwert enthält. -
fname = db.Column(db.String)erstellt das Vornamensfeld, eine Datenbankspalte, die einen Zeichenfolgenwert enthält. -
timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)erstellt ein Zeitstempelfeld, eine Datenbankspalte, die einen Datums-/Uhrzeitwert enthält. Derdefault=datetime.utcnowDer Parameter setzt den Zeitstempelwert standardmäßig auf den aktuellenutcnowWert, wenn ein Datensatz erstellt wird. Deronupdate=datetime.utcnowParameter aktualisiert den Zeitstempel mit dem aktuellenutcnowWert, wenn der Datensatz aktualisiert wird.
Hinweis:UTC-Zeitstempel
Sie fragen sich vielleicht, warum der Zeitstempel in der obigen Klasse standardmäßig datetime.utcnow() ist und von ihm aktualisiert wird -Methode, die eine UTC oder koordinierte Weltzeit zurückgibt. Auf diese Weise können Sie die Quelle Ihres Zeitstempels standardisieren.
Die Quelle oder Nullzeit ist eine Linie, die vom Nord- zum Südpol der Erde durch das Vereinigte Königreich nach Norden und Süden verläuft. Dies ist die Nullzeitzone, von der alle anderen Zeitzonen versetzt sind. Indem Sie dies als Nullzeitquelle verwenden, sind Ihre Zeitstempel Offsets von diesem Standardbezugspunkt.
Sollte auf Ihre Anwendung aus verschiedenen Zeitzonen zugegriffen werden, haben Sie eine Möglichkeit, Datums-/Uhrzeitberechnungen durchzuführen. Sie benötigen lediglich einen UTC-Zeitstempel und die Zielzeitzone.
Wenn Sie lokale Zeitzonen als Ihre Zeitstempelquelle verwenden würden, könnten Sie keine Datums-/Uhrzeitberechnungen ohne Informationen über die lokalen Zeitzonen durchführen, die von der Nullzeit abweichen. Ohne die Quelleninformationen des Zeitstempels könnten Sie überhaupt keine Datums-/Uhrzeitvergleiche oder Berechnungen durchführen.
Das Arbeiten mit Zeitstempeln basierend auf UTC ist ein guter Standard, dem man folgen sollte. Hier ist eine Toolkit-Site, mit der Sie arbeiten und sie besser verstehen können.
Wohin gehst du mit dieser person? Klassendefinition? Das Endziel besteht darin, eine Abfrage mit SQLAlchemy ausführen zu können und eine Liste von Instanzen der person zurückzugeben Klasse. Sehen wir uns als Beispiel die vorherige SQL-Anweisung an:
SELECT * FROM people ORDER BY lname;
Zeigen Sie das gleiche kleine Beispielprogramm von oben, aber jetzt mit SQLAlchemy:
1from models import Person
2
3people = Person.query.order_by(Person.lname).all()
4for person in people:
5 print(f'{person.fname} {person.lname}')
Ignorieren Sie Zeile 1 für den Moment, was Sie wollen, ist die ganze person Datensätze in aufsteigender Reihenfolge nach lname sortiert Feld. Was Sie von den SQLAlchemy-Anweisungen zurückbekommen Person.query.order_by(Person.lname).all() ist eine Liste von person Objekte für alle Datensätze in der person Datenbanktabelle in dieser Reihenfolge. Im obigen Programm die people Variable enthält die Liste von person Objekte.
Das Programm iteriert über die people Variable, wobei jede person genommen wird wiederum und Ausdrucken des Vor- und Nachnamens der Person aus der Datenbank. Beachten Sie, dass das Programm keine Indizes verwenden muss, um den fname zu erhalten oder lname Werte:Es verwendet die Attribute, die auf der person definiert sind Objekt.
Die Verwendung von SQLAlchemy ermöglicht es Ihnen, in Objekten mit Verhalten statt in reinem SQL zu denken . Dies wird noch vorteilhafter, wenn Ihre Datenbanktabellen größer und die Interaktionen komplexer werden.
Modellierte Daten serialisieren/deserialisieren
Das Arbeiten mit modellierten SQLAlchemy-Daten in Ihren Programmen ist sehr bequem. Es ist besonders praktisch in Programmen, die die Daten manipulieren, vielleicht Berechnungen durchführen oder sie verwenden, um Präsentationen auf dem Bildschirm zu erstellen. Ihre Anwendung ist eine REST-API, die im Wesentlichen CRUD-Operationen für die Daten bereitstellt und als solche nicht viel Datenmanipulation durchführt.
Die REST-API arbeitet mit JSON-Daten, und hier können Sie auf ein Problem mit dem SQLAlchemy-Modell stoßen. Da die von SQLAlchemy zurückgegebenen Daten Python-Klasseninstanzen sind, kann Connexion diese Klasseninstanzen nicht in JSON-formatierte Daten serialisieren. Erinnern Sie sich aus Teil 1 daran, dass Connexion das Tool ist, mit dem Sie die REST-API mithilfe einer YAML-Datei entworfen und konfiguriert und Python-Methoden damit verbunden haben.
In diesem Zusammenhang bedeutet Serialisieren das Konvertieren von Python-Objekten, die andere Python-Objekte und komplexe Datentypen enthalten können, in einfachere Datenstrukturen, die in JSON-Datentypen geparst werden können, die hier aufgelistet sind:
string: ein Zeichenfolgentypnumber: von Python unterstützte Zahlen (Integer, Floats, Longs)object: ein JSON-Objekt, das ungefähr einem Python-Wörterbuch entsprichtarray: entspricht ungefähr einer Python-Listeboolean: in JSON alstruedargestellt oderfalse, aber in Python alsTrueoderFalsenull: im Wesentlichen einNonein Python
Als Beispiel Ihre person Klasse enthält einen Zeitstempel, der ein Python DateTime ist . Es gibt keine Datums-/Zeitdefinition in JSON, daher muss der Zeitstempel in eine Zeichenfolge umgewandelt werden, um in einer JSON-Struktur vorhanden zu sein.
Ihre person -Klasse ist einfach genug, sodass das Abrufen der Datenattribute daraus und das manuelle Erstellen eines Wörterbuchs zur Rückgabe von unseren REST-URL-Endpunkten nicht sehr schwierig wäre. In einer komplexeren Anwendung mit vielen größeren SQLAlchemy-Modellen wäre dies nicht der Fall. Eine bessere Lösung ist die Verwendung eines Moduls namens Marshmallow, das die Arbeit für Sie erledigt.
Marshmallow hilft Ihnen, ein PersonSchema zu erstellen Klasse, die wie die SQLAlchemy person ist Klasse, die wir erstellt haben. Anstatt jedoch Datenbanktabellen und Feldnamen auf die Klasse und ihre Attribute abzubilden, wird hier das PersonSchema class definiert, wie die Attribute einer Klasse in JSON-freundliche Formate konvertiert werden. Hier ist die Marshmallow-Klassendefinition für die Daten in unserer person Tabelle:
class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
Die Klasse PersonSchema erbt von ma.ModelSchema , zu dem Sie gelangen, wenn Sie mit dem Erstellen des Programmcodes beginnen. Im Moment bedeutet dies PersonSchema erbt von einer Marshmallow-Basisklasse namens ModelSchema , die Attribute und Funktionen bereitstellt, die allen davon abgeleiteten Klassen gemeinsam sind.
Der Rest der Definition lautet wie folgt:
-
class Metadefiniert eine Klasse namensMetainnerhalb deiner Klasse. DasModelSchemaKlasse, die dasPersonSchemaKlasse erbt von sucht nach diesem internenMeta-Klasse und verwendet sie, um das SQLAlchemy-Modellpersonzu finden und diedb.session. So findet Marshmallow Attribute inpersonKlasse und den Typ dieser Attribute, damit sie weiß, wie sie serialisiert/deserialisiert werden. -
modelteilt der Klasse mit, welches SQLAlchemy-Modell zum Serialisieren/Deserialisieren von Daten zu und von Daten verwendet werden soll. -
db.sessionteilt der Klasse mit, welche Datenbanksitzung verwendet werden soll, um Attributdatentypen zu prüfen und zu bestimmen.
Wohin gehst du mit dieser Klassendefinition? Sie möchten eine Instanz einer person serialisieren können Klasse in JSON-Daten und um JSON-Daten zu deserialisieren und eine person zu erstellen Klasseninstanzen daraus.
Erstellen Sie die initialisierte Datenbank
SQLAlchemy verarbeitet viele der Interaktionen, die für bestimmte Datenbanken spezifisch sind, und ermöglicht es Ihnen, sich auf die Datenmodelle sowie deren Verwendung zu konzentrieren.
Da Sie nun, wie bereits erwähnt, tatsächlich eine Datenbank erstellen, verwenden Sie SQLite. Sie tun dies aus mehreren Gründen. Es kommt mit Python und muss nicht als separates Modul installiert werden. Es speichert alle Datenbankinformationen in einer einzigen Datei und ist daher einfach einzurichten und zu verwenden.
Die Installation eines separaten Datenbankservers wie MySQL oder PostgreSQL würde gut funktionieren, erfordert jedoch die Installation und Inbetriebnahme dieser Systeme, was den Rahmen dieses Artikels sprengen würde.
Da SQLAlchemy die Datenbank verwaltet, spielt es in vielerlei Hinsicht keine Rolle, was die zugrunde liegende Datenbank ist.
Sie werden ein neues Dienstprogramm namens build_database.py erstellen um die SQLite people.db zu erstellen und zu initialisieren Datenbankdatei, die Ihre person enthält Datenbanktabelle. Dabei erstellen Sie zwei Python-Module, config.py und models.py , die von build_database.py verwendet wird und die modifizierte server.py aus Teil 1.
Hier finden Sie den Quellcode für die Module, die Sie gerade erstellen und die hier vorgestellt werden:
-
config.pybekommt die notwendigen Module in das Programm importiert und konfiguriert. Dazu gehören Flask, Connexion, SQLAlchemy und Marshmallow. Weil es von beidenbuild_database.pyverwendet wird undserver.py, gelten einige Teile der Konfiguration nur fürserver.pyAnwendung. -
models.pyist das Modul, in dem Sie diepersonerstellen SQLAlchemy undPersonSchemaDie oben beschriebenen Marshmallow-Klassendefinitionen. Dieses Modul ist abhängig vonconfig.pyfür einige der dort erstellten und konfigurierten Objekte.
Konfigurationsmodul
Die config.py Modul ist, wie der Name schon sagt, der Ort, an dem alle Konfigurationsinformationen erstellt und initialisiert werden. Wir werden dieses Modul für unsere beiden build_database.py verwenden Programmdatei und die bald zu aktualisierende server.py Datei aus dem Artikel Teil 1. Das bedeutet, dass wir hier Flask, Connexion, SQLAlchemy und Marshmallow konfigurieren werden.
Obwohl die Datei build_database.py Das Programm verwendet weder Flask, Connexion noch Marshmallow, sondern SQLAlchemy, um unsere Verbindung zur SQLite-Datenbank herzustellen. Hier ist der Code für die config.py Modul:
1import os
2import connexion
3from flask_sqlalchemy import SQLAlchemy
4from flask_marshmallow import Marshmallow
5
6basedir = os.path.abspath(os.path.dirname(__file__))
7
8# Create the Connexion application instance
9connex_app = connexion.App(__name__, specification_dir=basedir)
10
11# Get the underlying Flask app instance
12app = connex_app.app
13
14# Configure the SQLAlchemy part of the app instance
15app.config['SQLALCHEMY_ECHO'] = True
16app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////' + os.path.join(basedir, 'people.db')
17app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
18
19# Create the SQLAlchemy db instance
20db = SQLAlchemy(app)
21
22# Initialize Marshmallow
23ma = Marshmallow(app)
Folgendes macht der obige Code:
-
Zeilen 2 – 4 Importieren Sie Connexion wie in
server.pyProgramm aus Teil 1. Es importiert auchSQLAlchemyausflask_sqlalchemyModul. Dadurch erhält Ihr Programm Datenbankzugriff. Zuletzt importiert esMarshmallowausflask_marshamllowModul. -
Zeile 6 erstellt die Variable
basedirzeigt auf das Verzeichnis, in dem das Programm läuft. -
Zeile 9 verwendet das
basedir-Variable, um die Connexion-App-Instanz zu erstellen, und geben Sie ihr den Pfad zuswagger.ymlDatei. -
Zeile 12 erstellt eine Variable
app, die die von Connexion initialisierte Flask-Instanz ist. -
Zeile 15 verwendet die
app-Variable zum Konfigurieren von Werten, die von SQLAlchemy verwendet werden. Zuerst setzt esSQLALCHEMY_ECHOaufTrue. Dies veranlasst SQLAlchemy, ausgeführte SQL-Anweisungen an die Konsole zurückzugeben. Dies ist sehr nützlich, um Probleme beim Erstellen von Datenbankprogrammen zu debuggen. Setzen Sie dies aufFalsefür Produktionsumgebungen. -
Zeile 16 setzt
SQLALCHEMY_DATABASE_URIzusqlite:////' + os.path.join(basedir, 'people.db'). Dies weist SQLAlchemy an, SQLite als Datenbank und eine Datei mit dem Namenpeople.dbzu verwenden im aktuellen Verzeichnis als Datenbankdatei. Unterschiedliche Datenbank-Engines wie MySQL und PostgreSQL haben unterschiedlicheSQLALCHEMY_DATABASE_URIZeichenfolgen, um sie zu konfigurieren. -
Zeile 17 setzt
SQLALCHEMY_TRACK_MODIFICATIONSzuFalse, wodurch das standardmäßig aktivierte SQLAlchemy-Ereignissystem deaktiviert wird. Das Ereignissystem erzeugt Ereignisse, die in ereignisgesteuerten Programmen nützlich sind, fügt jedoch einen erheblichen Overhead hinzu. Da Sie kein ereignisgesteuertes Programm erstellen, schalten Sie diese Funktion aus. -
Zeile 19 erstellt die
dbVariable durch Aufrufen vonSQLAlchemy(app). Dadurch wird SQLAlchemy initialisiert, indem dieappübergeben wird Konfigurationsinformationen gerade eingestellt. DiedbVariable ist das, was inbuild_database.pyimportiert wird Programm, um ihm Zugriff auf SQLAlchemy und die Datenbank zu gewähren. Es dient dem gleichen Zweck inserver.pyProgramm undpeople.pyModul. -
Zeile 23 erstellt das
maVariable durch Aufrufen vonMarshmallow(app). Dadurch wird Marshmallow initialisiert und eine Selbstprüfung der an die App angefügten SQLAlchemy-Komponenten ermöglicht. Aus diesem Grund wird Marshmallow nach SQLAlchemy initialisiert.
Model-Modul
Die models.py Modul wird erstellt, um die person bereitzustellen und PersonSchema Klassen genau wie in den Abschnitten oben über das Modellieren und Serialisieren der Daten beschrieben. Hier ist der Code für dieses Modul:
1from datetime import datetime
2from config import db, ma
3
4class Person(db.Model):
5 __tablename__ = 'person'
6 person_id = db.Column(db.Integer, primary_key=True)
7 lname = db.Column(db.String(32), index=True)
8 fname = db.Column(db.String(32))
9 timestamp = db.Column(db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow)
10
11class PersonSchema(ma.ModelSchema):
12 class Meta:
13 model = Person
14 sqla_session = db.session
Folgendes macht der obige Code:
-
Zeile 1 importiert die
datetimeObjekt ausdatetimeModul, das mit Python geliefert wird. Auf diese Weise können Sie einen Zeitstempel in derpersonerstellen Klasse. -
Zeile 2 importiert die
dbundmaInstanzvariablen, die in derconfig.pydefiniert sind Modul. Dadurch erhält das Modul Zugriff auf SQLAlchemy-Attribute und -Methoden, die andbangehängt sind -Variable und die Marshmallow-Attribute und -Methoden, die anmaangehängt sind Variable. -
Zeilen 4 – 9 definieren Sie die
personKlasse wie oben im Abschnitt Datenmodellierung besprochen, aber jetzt wissen Sie, wo diedb.Modelvon denen die Klasse erbt stammt. Dies ergibt diepersonKlasse SQLAlchemy Features, wie eine Verbindung zur Datenbank und Zugriff auf ihre Tabellen. -
Zeilen 11 – 14 Definieren Sie das
PersonSchemaclass as was discussed in the data serialzation section above. This class inherits fromma.ModelSchemaand gives thePersonSchemaclass Marshmallow features, like introspecting thepersonclass to help serialize/deserialize instances of that class.
Creating the Database
You’ve seen how database tables can be mapped to SQLAlchemy classes. Now use what you’ve learned to create the database and populate it with data. You’re going to build a small utility program to create and build the database with the People Daten. Here’s the build_database.py program:
1import os
2from config import db
3from models import Person
4
5# Data to initialize database with
6PEOPLE = [
7 {'fname': 'Doug', 'lname': 'Farrell'},
8 {'fname': 'Kent', 'lname': 'Brockman'},
9 {'fname': 'Bunny','lname': 'Easter'}
10]
11
12# Delete database file if it exists currently
13if os.path.exists('people.db'):
14 os.remove('people.db')
15
16# Create the database
17db.create_all()
18
19# Iterate over the PEOPLE structure and populate the database
20for person in PEOPLE:
21 p = Person(lname=person['lname'], fname=person['fname'])
22 db.session.add(p)
23
24db.session.commit()
Here’s what the above code is doing:
-
Line 2 imports the
dbinstance from theconfig.pymodule. -
Line 3 imports the
personclass definition from themodels.pymodule. -
Lines 6 – 10 create the
PEOPLEdata structure, which is a list of dictionaries containing your data. The structure has been condensed to save presentation space. -
Lines 13 &14 perform some simple housekeeping to delete the
people.dbfile, if it exists. This file is where the SQLite database is maintained. If you ever have to re-initialize the database to get a clean start, this makes sure you’re starting from scratch when you build the database. -
Line 17 creates the database with the
db.create_all()call. This creates the database by using thedbinstance imported from theconfigmodule. Thedbinstance is our connection to the database. -
Lines 20 – 22 iterate over the
PEOPLElist and use the dictionaries within to instantiate apersonKlasse. After it is instantiated, you call thedb.session.add(p)Funktion. This uses the database connection instancedbto access thesessionobject. The session is what manages the database actions, which are recorded in the session. In this case, you are executing theadd(p)method to add the newpersoninstance to thesessionobject. -
Line 24 calls
db.session.commit()to actually save all the person objects created to the database.
Hinweis: At Line 22, no data has been added to the database. Everything is being saved within the session object. Only when you execute the db.session.commit() call at Line 24 does the session interact with the database and commit the actions to it.
In SQLAlchemy, the session is an important object. It acts as the conduit between the database and the SQLAlchemy Python objects created in a program. The session helps maintain the consistency between data in the program and the same data as it exists in the database. It saves all database actions and will update the underlying database accordingly by both explicit and implicit actions taken by the program.
Now you’re ready to run the build_database.py program to create and initialize the new database. You do so with the following command, with your Python virtual environment active:
python build_database.py
When the program runs, it will print SQLAlchemy log messages to the console. These are the result of setting SQLALCHEMY_ECHO to True in the config.py Datei. Much of what’s being logged by SQLAlchemy is the SQL commands it’s generating to create and build the people.db SQLite database file. Here’s an example of what’s printed out when the program is run:
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine SELECT CAST('test plain returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,951 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine SELECT CAST('test unicode returns' AS VARCHAR(60)) AS anon_1
2018-09-11 22:20:29,952 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine PRAGMA table_info("person")
2018-09-11 22:20:29,956 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine
CREATE TABLE person (
person_id INTEGER NOT NULL,
lname VARCHAR,
fname VARCHAR,
timestamp DATETIME,
PRIMARY KEY (person_id)
)
2018-09-11 22:20:29,959 INFO sqlalchemy.engine.base.Engine ()
2018-09-11 22:20:29,975 INFO sqlalchemy.engine.base.Engine COMMIT
2018-09-11 22:20:29,980 INFO sqlalchemy.engine.base.Engine BEGIN (implicit)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,983 INFO sqlalchemy.engine.base.Engine ('Farrell', 'Doug', '2018-09-12 02:20:29.983143')
2018-09-11 22:20:29,984 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Brockman', 'Kent', '2018-09-12 02:20:29.984821')
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine INSERT INTO person (lname, fname, timestamp) VALUES (?, ?, ?)
2018-09-11 22:20:29,985 INFO sqlalchemy.engine.base.Engine ('Easter', 'Bunny', '2018-09-12 02:20:29.985462')
2018-09-11 22:20:29,986 INFO sqlalchemy.engine.base.Engine COMMIT
Using the Database
Once the database has been created, you can modify the existing code from Part 1 to make use of it. All of the modifications necessary are due to creating the person_id primary key value in our database as the unique identifier rather than the lname Wert.
Update the REST API
None of the changes are very dramatic, and you’ll start by re-defining the REST API. The list below shows the API definition from Part 1 but is updated to use the person_id variable in the URL path:
| Action | HTTP Verb | URL Path | Beschreibung |
|---|---|---|---|
| Create | POST | /api/people | Defines a unique URL to create a new person |
| Read | GET | /api/people | Defines a unique URL to read a collection of people |
| Read | GET | /api/people/{person_id} | Defines a unique URL to read a particular person by person_id |
| Update | PUT | /api/people/{person_id} | Defines a unique URL to update an existing person by person_id |
| Delete | DELETE | /api/orders/{person_id} | Defines a unique URL to delete an existing person by person_id |
Where the URL definitions required an lname value, they now require the person_id (primary key) for the person record in the people Tisch. This allows you to remove the code in the previous app that artificially restricted users from editing a person’s last name.
In order for you to implement these changes, the swagger.yml file from Part 1 will have to be edited. For the most part, any lname parameter value will be changed to person_id , and person_id will be added to the POST and PUT responses. You can check out the updated swagger.yml file.
Update the REST API Handlers
With the swagger.yml file updated to support the use of the person_id identifier, you’ll also need to update the handlers in the people.py file to support these changes. In the same way that the swagger.yml file was updated, you need to change the people.py file to use the person_id value rather than lname .
Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people :
1from flask import (
2 make_response,
3 abort,
4)
5from config import db
6from models import (
7 Person,
8 PersonSchema,
9)
10
11def read_all():
12 """
13 This function responds to a request for /api/people
14 with the complete lists of people
15
16 :return: json string of list of people
17 """
18 # Create the list of people from our data
19 people = Person.query \
20 .order_by(Person.lname) \
21 .all()
22
23 # Serialize the data for the response
24 person_schema = PersonSchema(many=True)
25 return person_schema.dump(people).data
Here’s what the above code is doing:
-
Lines 1 – 9 import some Flask modules to create the REST API responses, as well as importing the
dbinstance from theconfig.pymodule. In addition, it imports the SQLAlchemypersonand MarshmallowPersonSchemaclasses to access thepersondatabase table and serialize the results. -
Line 11 starts the definition of
read_all()that responds to the REST API URL endpointGET /api/peopleand returns all the records in thepersondatabase table sorted in ascending order by last name. -
Lines 19 – 22 tell SQLAlchemy to query the
persondatabase table for all the records, sort them in ascending order (the default sorting order), and return a list ofpersonPython objects as the variablepeople. -
Line 24 is where the Marshmallow
PersonSchemaclass definition becomes valuable. You create an instance of thePersonSchema, passing it the parametermany=True. This tellsPersonSchemato expect an interable to serialize, which is what thepeoplevariable is. -
Line 25 uses the
PersonSchemainstance variable (person_schema), calling itsdump()method with thepeopleaufführen. The result is an object having adataattribute, an object containing apeoplelist that can be converted to JSON. This is returned and converted by Connexion to JSON as the response to the REST API call.
Hinweis: The people list variable created on Line 24 above can’t be returned directly because Connexion won’t know how to convert the timestamp field into JSON. Returning the list of people without processing it with Marshmallow results in a long error traceback and finally this Exception:
TypeError: Object of type Person is not JSON serializable
Here’s another part of the person.py module that makes a request for a single person from the person Datenbank. Here, read_one(person_id) function receives a person_id from the REST URL path, indicating the user is looking for a specific person. Here’s part of the updated person.py module showing the handler for the REST URL endpoint GET /api/people/{person_id} :
1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: ID of person to find
7 :return: person matching ID
8 """
9 # Get the person requested
10 person = Person.query \
11 .filter(Person.person_id == person_id) \
12 .one_or_none()
13
14 # Did we find a person?
15 if person is not None:
16
17 # Serialize the data for the response
18 person_schema = PersonSchema()
19 return person_schema.dump(person).data
20
21 # Otherwise, nope, didn't find that person
22 else:
23 abort(404, 'Person not found for Id: {person_id}'.format(person_id=person_id))
Here’s what the above code is doing:
-
Lines 10 – 12 use the
person_idparameter in a SQLAlchemy query using thefiltermethod of the query object to search for a person with aperson_idattribute matching the passed-inperson_id. Rather than using theall()query method, use theone_or_none()method to get one person, or returnNoneif no match is found. -
Line 15 determines whether a
personwas found or not. -
Line 17 shows that, if
personwas notNone(a matchingpersonwas found), then serializing the data is a little different. You don’t pass themany=Trueparameter to the creation of thePersonSchema()instance. Instead, you passmany=Falsebecause only a single object is passed in to serialize. -
Line 18 is where the
dumpmethod ofperson_schemais called, and thedataattribute of the resulting object is returned. -
Line 23 shows that, if
personwasNone(a matching person wasn’t found), then the Flaskabort()method is called to return an error.
Another modification to person.py is creating a new person in the database. This gives you an opportunity to use the Marshmallow PersonSchema to deserialize a JSON structure sent with the HTTP request to create a SQLAlchemy person object. Here’s part of the updated person.py module showing the handler for the REST URL endpoint POST /api/people :
1def create(person):
2 """
3 This function creates a new person in the people structure
4 based on the passed-in person data
5
6 :param person: person to create in people structure
7 :return: 201 on success, 406 on person exists
8 """
9 fname = person.get('fname')
10 lname = person.get('lname')
11
12 existing_person = Person.query \
13 .filter(Person.fname == fname) \
14 .filter(Person.lname == lname) \
15 .one_or_none()
16
17 # Can we insert this person?
18 if existing_person is None:
19
20 # Create a person instance using the schema and the passed-in person
21 schema = PersonSchema()
22 new_person = schema.load(person, session=db.session).data
23
24 # Add the person to the database
25 db.session.add(new_person)
26 db.session.commit()
27
28 # Serialize and return the newly created person in the response
29 return schema.dump(new_person).data, 201
30
31 # Otherwise, nope, person exists already
32 else:
33 abort(409, f'Person {fname} {lname} exists already')
Here’s what the above code is doing:
-
Line 9 &10 set the
fnameandlnamevariables based on thepersondata structure sent as thePOSTbody of the HTTP request. -
Lines 12 – 15 use the SQLAlchemy
personclass to query the database for the existence of a person with the samefnameandlnameas the passed-inperson. -
Line 18 addresses whether
existing_personisNone. (existing_personwas not found.) -
Line 21 creates a
PersonSchema()instance calledschema. -
Line 22 uses the
schemavariable to load the data contained in thepersonparameter variable and create a new SQLAlchemypersoninstance variable callednew_person. -
Line 25 adds the
new_personinstance to thedb.session. -
Line 26 commits the
new_personinstance to the database, which also assigns it a new primary key value (based on the auto-incrementing integer) and a UTC-based timestamp. -
Line 33 shows that, if
existing_personis notNone(a matching person was found), then the Flaskabort()method is called to return an error.
Update the Swagger UI
With the above changes in place, your REST API is now functional. The changes you’ve made are also reflected in an updated swagger UI interface and can be interacted with in the same manner. Below is a screenshot of the updated swagger UI opened to the GET /people/{person_id} Sektion. This section of the UI gets a single person from the database and looks like this:
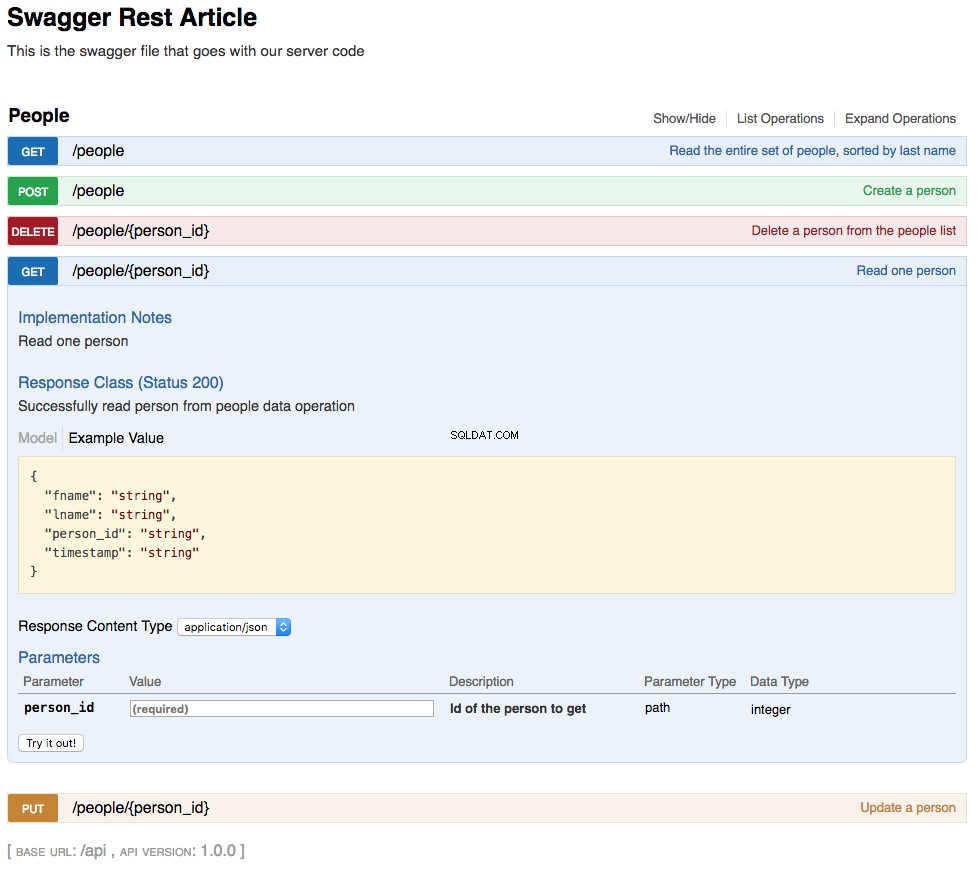
As shown in the above screenshot, the path parameter lname has been replaced by person_id , which is the primary key for a person in the REST API. The changes to the UI are a combined result of changing the swagger.yml file and the code changes made to support that.
Update the Web Application
The REST API is running, and CRUD operations are being persisted to the database. So that it is possible to view the demonstration web application, the JavaScript code has to be updated.
The updates are again related to using person_id instead of lname as the primary key for person data. In addition, the person_id is attached to the rows of the display table as HTML data attributes named data-person-id , so the value can be retrieved and used by the JavaScript code.
This article focused on the database and making your REST API use it, which is why there’s just a link to the updated JavaScript source and not much discussion of what it does.
Example Code
All of the example code for this article is available here. There’s one version of the code containing all the files, including the build_database.py utility program and the server.py modified example program from Part 1.
Schlussfolgerung
Congratulations, you’ve covered a lot of new material in this article and added useful tools to your arsenal!
You’ve learned how to save Python objects to a database using SQLAlchemy. You’ve also learned how to use Marshmallow to serialize and deserialize SQLAlchemy objects and use them with a JSON REST API. The things you’ve learned have certainly been a step up in complexity from the simple REST API of Part 1, but that step has given you two very powerful tools to use when creating more complex applications.
SQLAlchemy and Marshmallow are amazing tools in their own right. Using them together gives you a great leg up to create your own web applications backed by a database.
In Part 3 of this series, you’ll focus on the R part of RDBMS :relationships, which provide even more power when you are using a database.