PostgreSQL ist ein großartiges Projekt und entwickelt sich mit erstaunlicher Geschwindigkeit. Wir werden uns mit einer Reihe von Blogbeiträgen auf die Entwicklung der Fehlertoleranzfunktionen in PostgreSQL in allen Versionen konzentrieren. Dies ist der vierte Beitrag der Serie und wir werden über synchrones Commit und seine Auswirkungen auf die Fehlertoleranz und Zuverlässigkeit von PostgreSQL sprechen.
Wenn Sie den Evolutionsfortschritt von Anfang an miterleben möchten, sehen Sie sich bitte die ersten drei Blogposts der folgenden Serie an. Jeder Beitrag ist unabhängig, sodass Sie den einen nicht wirklich lesen müssen, um den anderen zu verstehen.
- Entwicklung der Fehlertoleranz in PostgreSQL
- Entwicklung der Fehlertoleranz in PostgreSQL:Replikationsphase
- Entwicklung der Fehlertoleranz in PostgreSQL:Zeitreise
Synchrones Commit
Standardmäßig implementiert PostgreSQL die asynchrone Replikation, bei der Daten gestreamt werden, wann immer es für den Server zweckmäßig ist. Dies kann bei einem Failover zu Datenverlust führen. Es ist möglich, Postgres zu bitten, einen (oder mehrere) Standbys zu verlangen, um die Replikation der Daten vor dem Commit zu bestätigen, dies wird als synchrone Replikation (synchrones Commit) bezeichnet ) .
Bei der synchronen Replikation verzögert sich die Replikation direkt wirkt sich auf die verstrichene Zeit von Transaktionen auf dem Master aus. Bei asynchroner Replikation kann der Master mit voller Geschwindigkeit weitermachen.
Die synchrone Replikation garantiert, dass Daten mindestens geschrieben werden zwei Knoten, bevor dem Benutzer oder der Anwendung mitgeteilt wird, dass eine Transaktion festgeschrieben wurde.
Der Benutzer kann den Commit-Modus jeder Transaktion auswählen , sodass sowohl synchrone als auch asynchrone Commit-Transaktionen gleichzeitig ausgeführt werden können.
Dies ermöglicht flexible Kompromisse zwischen Leistung und Sicherheit der Transaktionsdauerhaftigkeit.
Synchrones Commit konfigurieren
Um die synchrone Replikation in Postgres einzurichten, müssen wir synchronous_commit konfigurieren Parameter in postgresql.conf.
Der Parameter gibt an, ob der Transaktionscommit darauf wartet, dass WAL-Einträge auf die Festplatte geschrieben werden, bevor der Befehl einen Erfolg zurückgibt Hinweis an den Kunden. Gültige Werte sind on , remote_apply , remote_write , lokal , und aus . Wir werden besprechen, wie die Dinge in Bezug auf die synchrone Replikation funktionieren, wenn wir synchronous_commit einrichten Parameter mit jedem der definierten Werte.
Beginnen wir mit der Postgres-Dokumentation (9.6):
Hier verstehen wir das Konzept des synchronen Commit, wie wir es im Einführungsteil des Beitrags beschrieben haben, es steht Ihnen frei, die synchrone Replikation einzurichten, aber wenn Sie dies nicht tun, besteht immer das Risiko, Daten zu verlieren. Aber ohne das Risiko einer Datenbankinkonsistenz, im Gegensatz zum Ausschalten von fsync off – aber das ist ein Thema für einen anderen Post –. Schließlich schließen wir, dass wir keine Daten zwischen Replikationsverzögerungen verlieren wollen und sicher sein wollen, dass die Daten auf mindestens zwei Knoten geschrieben werden, bevor der Benutzer/die Anwendung darüber informiert wird, dass die Transaktion festgeschrieben wurde , müssen wir akzeptieren, dass etwas Leistung verloren geht.
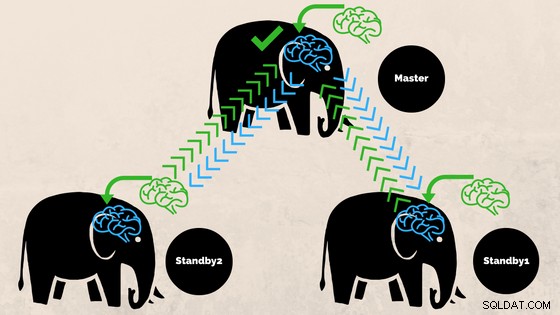
Sehen wir uns an, wie verschiedene Einstellungen für unterschiedliche Synchronisierungsstufen funktionieren. Bevor wir beginnen, lassen Sie uns darüber sprechen, wie Commit von der PostgreSQL-Replikation verarbeitet wird. Der Client führt Abfragen auf dem Master-Knoten aus, die Änderungen werden in ein Transaktionsprotokoll (WAL) geschrieben und über das Netzwerk in WAL auf dem Standby-Knoten kopiert. Der Wiederherstellungsprozess auf dem Standby-Knoten liest dann die Änderungen von WAL und wendet sie auf die Datendateien an, genau wie bei der Wiederherstellung nach einem Absturz. Wenn sich der Standby im Hot-Standby befindet -Modus können Clients schreibgeschützte Abfragen auf dem Knoten ausgeben, während dies geschieht. Weitere Einzelheiten zur Funktionsweise der Replikation finden Sie im Blogbeitrag zur Replikation in dieser Reihe.
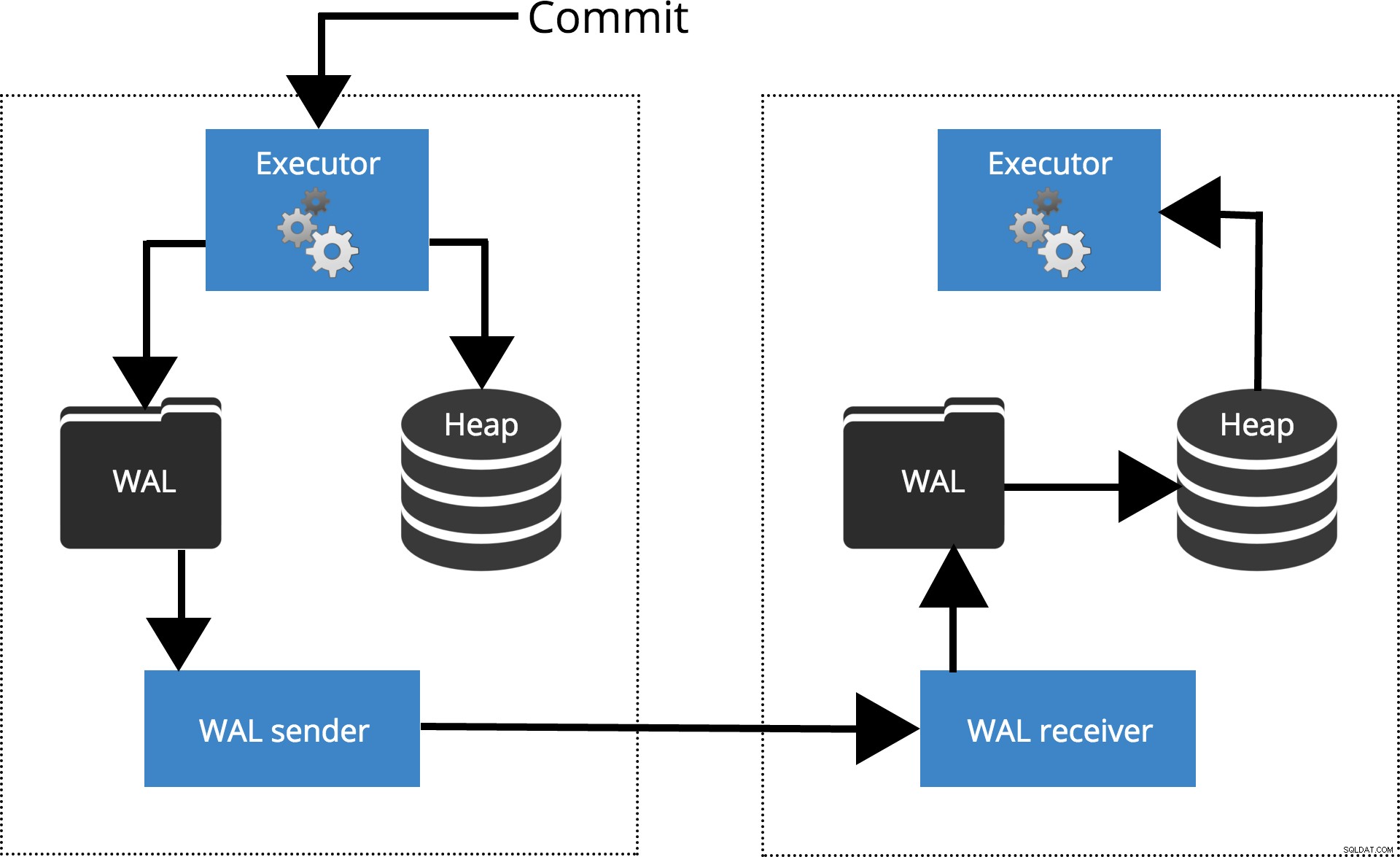
Abb.1 Funktionsweise der Replikation
synchronous_commit =aus
Wenn wir sychronous_commit = off, setzen das COMMIT wartet nicht darauf, dass der Transaktionsdatensatz auf die Platte geleert wird. Dies wird in Abb. 2 unten hervorgehoben.
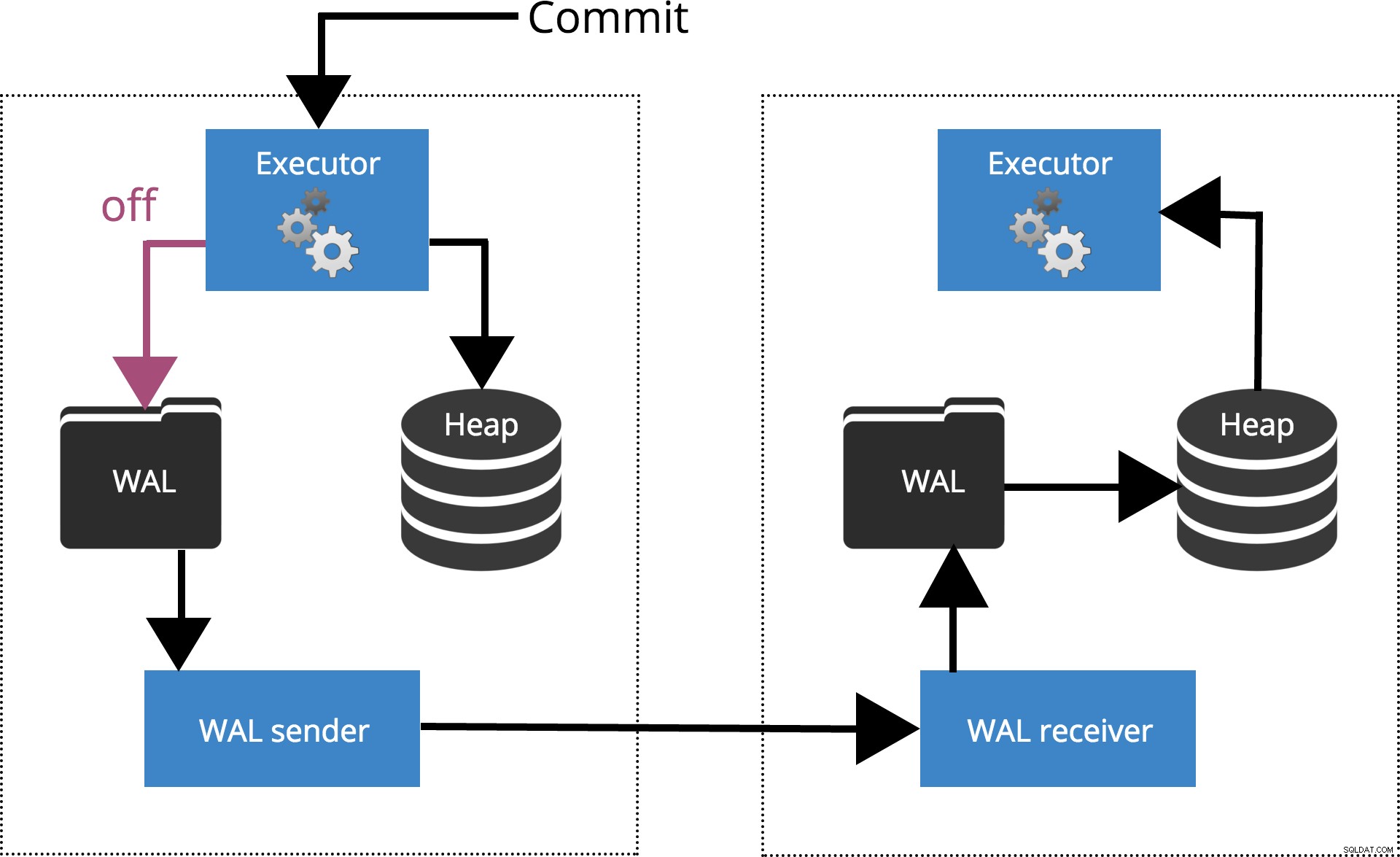
Abb.2 Synchronous_commit =Off
synchronous_commit =lokal
Wenn wir synchronous_commit = local, setzen das COMMIT wartet, bis der Transaktionsdatensatz auf die lokale Festplatte geleert wird. Dies wird in Abb. 3 unten hervorgehoben.
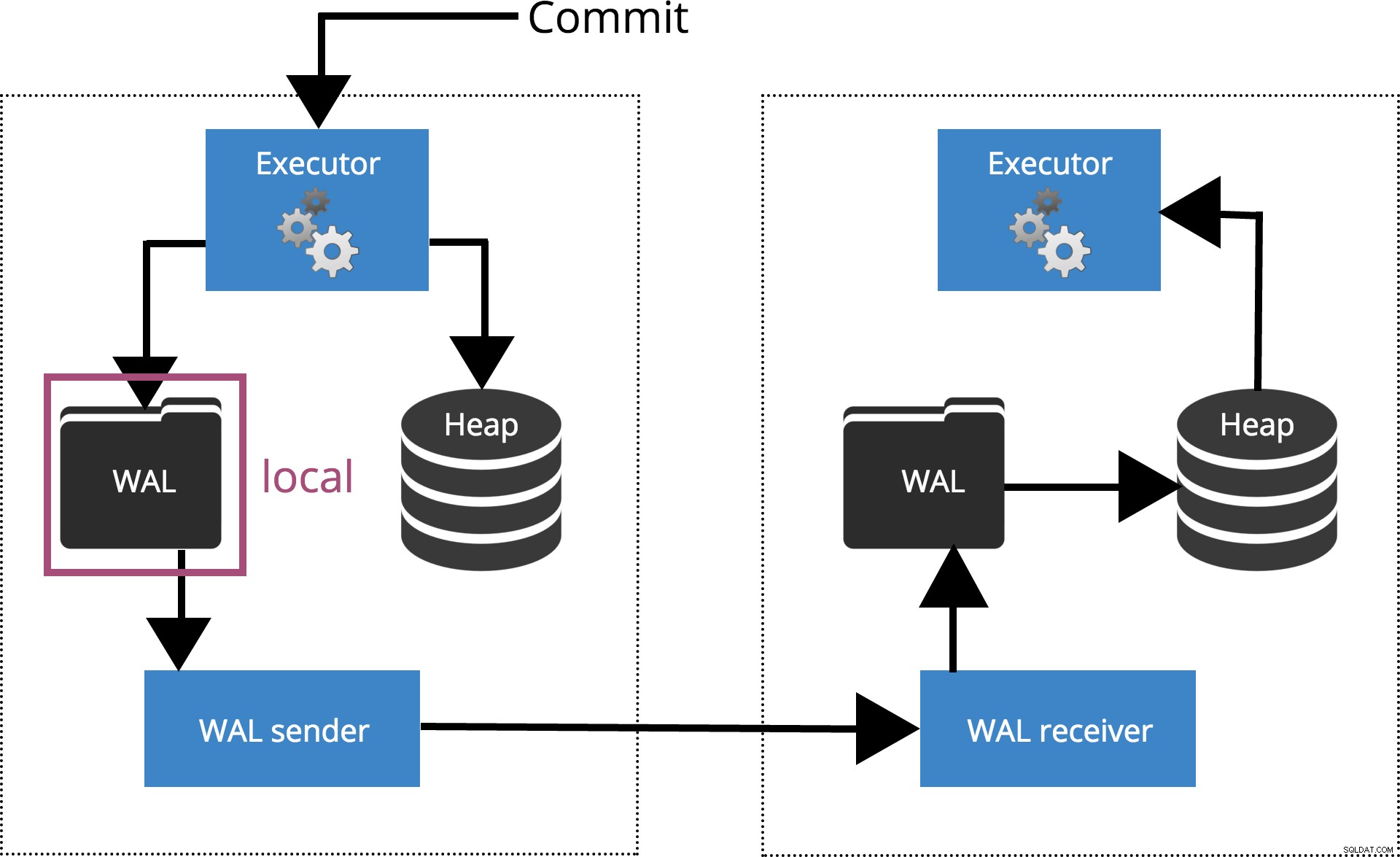
Abb.3 Synchronous_commit =local
synchronous_commit =on (Standard)
Wenn wir synchronous_commit = on, setzen das COMMIT wird warten, bis der/die durch synchronous_standby_names angegebene(n) Server Bestätigen Sie, dass der Transaktionsdatensatz sicher auf die Festplatte geschrieben wurde. Dies wird in Abb. 4 unten hervorgehoben.
Hinweis: Wenn synchronous_standby_names leer ist, verhält sich diese Einstellung genauso wie synchronous_commit = local .
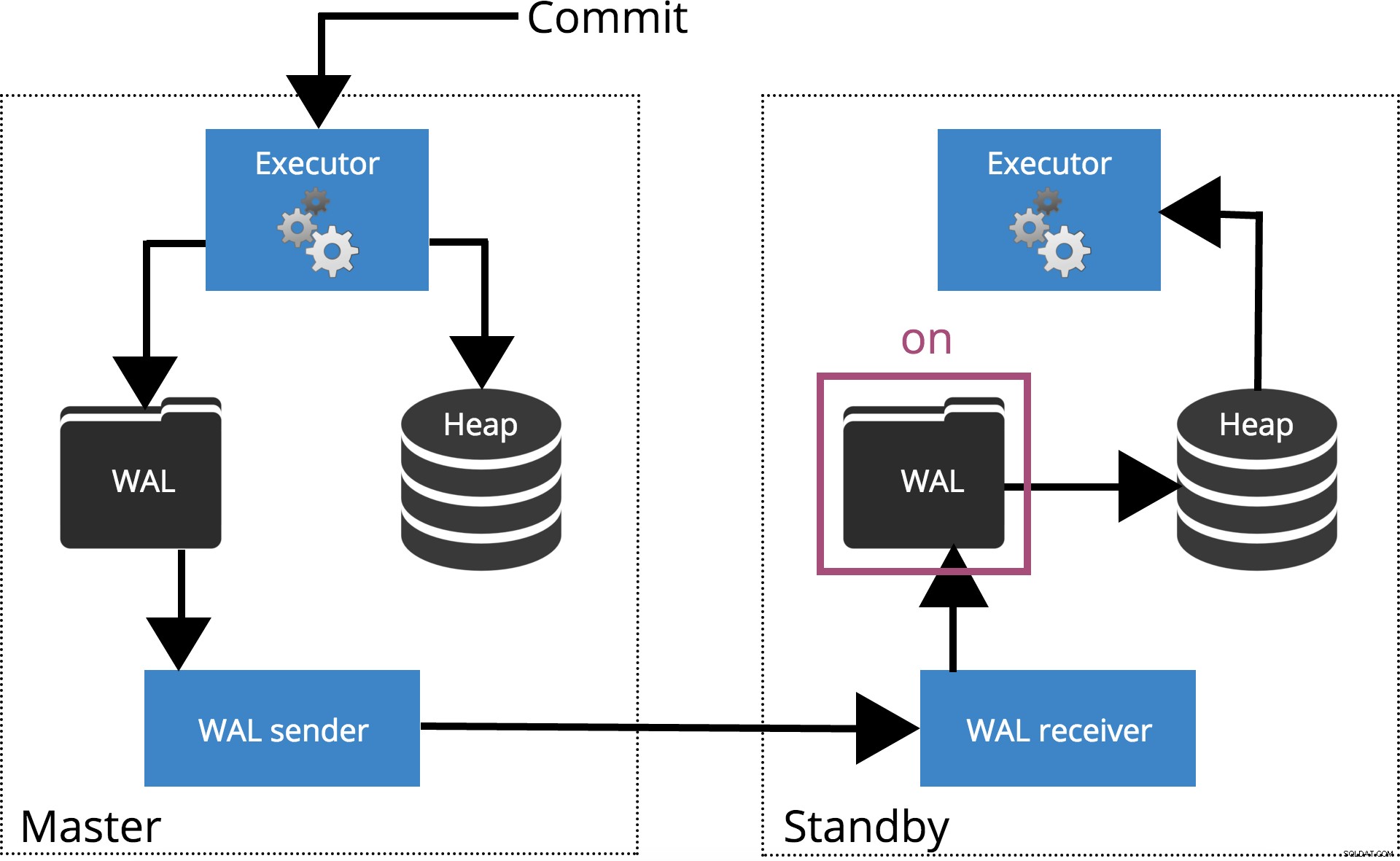
Abb.4 synchrone_commit =ein
synchronous_commit =remote_write
Wenn wir synchronous_commit = remote_write, setzen das COMMIT wird warten, bis der/die durch synchronous_standby_names angegebene(n) Server Bestätigen Sie das Schreiben des Transaktionsdatensatzes an das Betriebssystem, hat aber nicht unbedingt die Platte erreicht. Dies wird in Abb. 5 unten hervorgehoben.
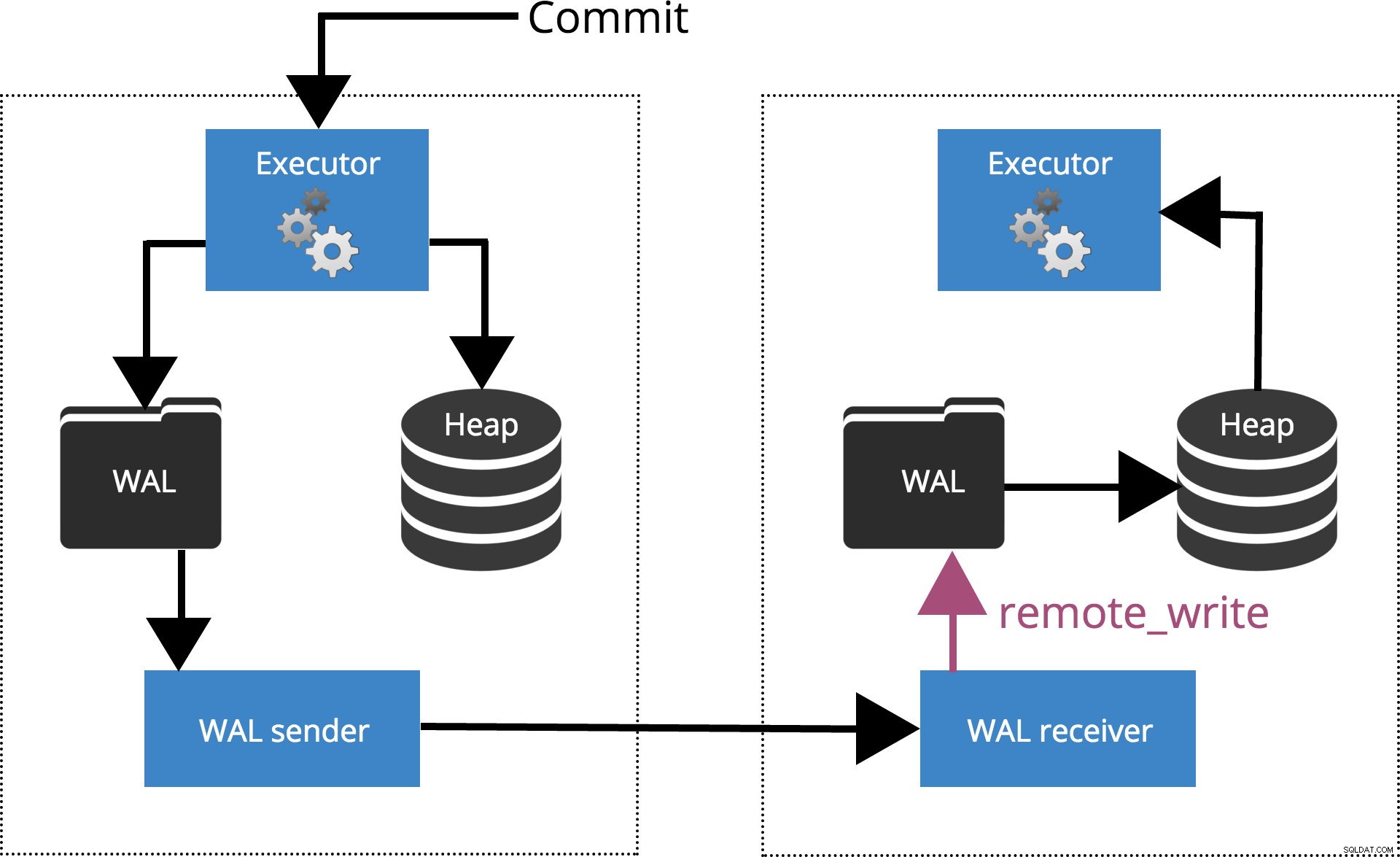
Abb.5 synchrone_commit =remote_write
synchronous_commit =remote_apply
Wenn wir synchronous_commit = remote_apply, setzen das COMMIT wird warten, bis der/die durch synchronous_standby_names angegebene(n) Server Bestätigen Sie, dass der Transaktionsdatensatz in die Datenbank übernommen wurde. Dies wird in Abb. 6 unten hervorgehoben.
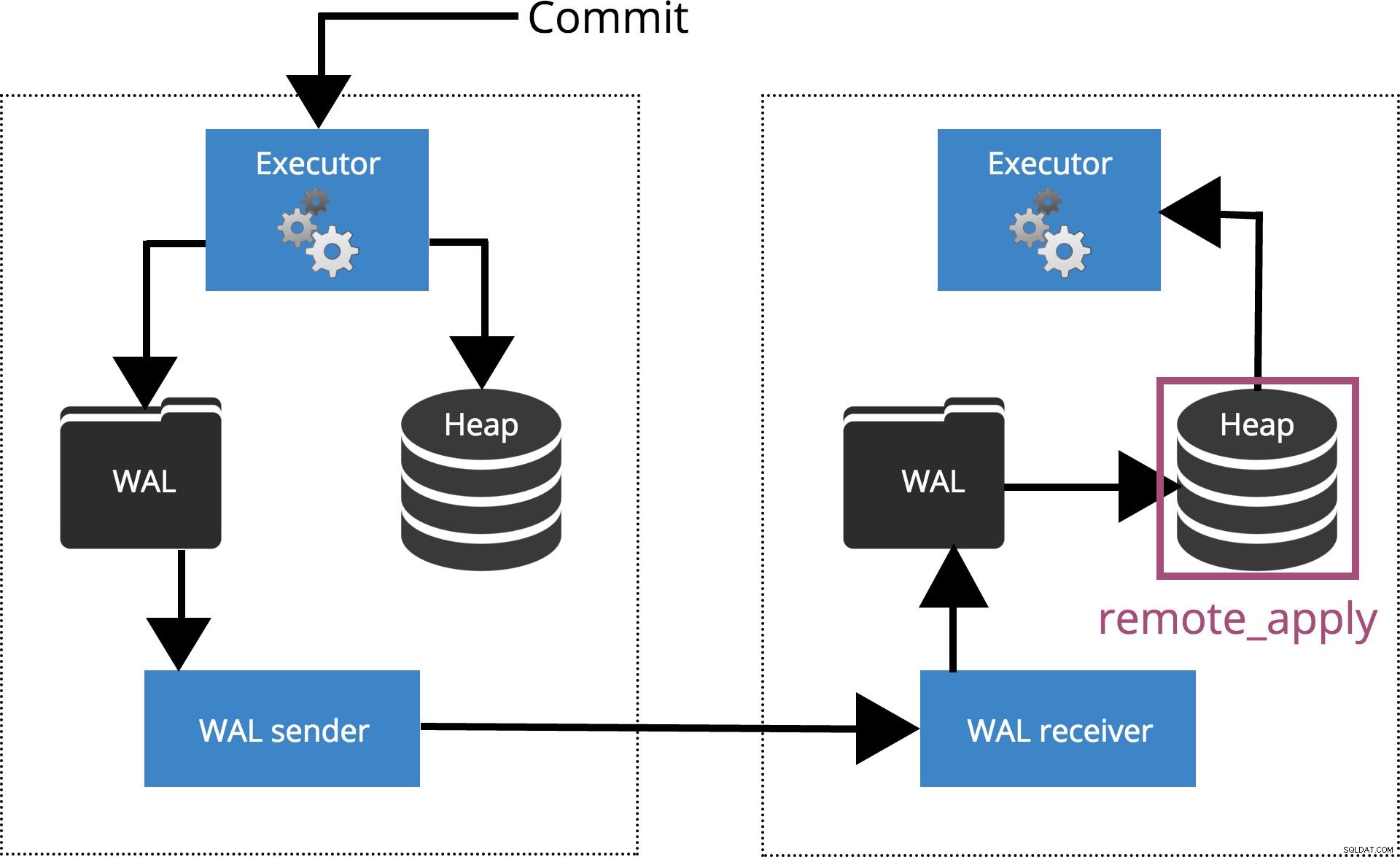
Abb.6 Synchronous_commit =Remote_Apply
Sehen wir uns nun sychronous_standby_names an Parameter im Detail, auf den oben beim Setzen von synchronous_commit verwiesen wird als on , remote_apply oder remote_write .
synchronous_standby_names =‘standby_name [, …]’
Der synchrone Commit wartet auf die Antwort von einem der Standbys, die in der Reihenfolge ihrer Priorität aufgeführt sind. Das bedeutet, dass, wenn der erste Standby verbunden ist und streamt, der synchrone Commit immer auf eine Antwort von ihm wartet, selbst wenn der zweite Standby bereits geantwortet hat. Der Sonderwert von * kann als stanby_name verwendet werden die mit jedem angeschlossenen Standby übereinstimmt.
synchronous_standby_names =‘num (standby_name [, …])’
Der synchrone Commit wartet auf eine Antwort von mindestens num Anzahl der Standbys in der Reihenfolge ihrer Priorität aufgelistet. Es gelten die gleichen Regeln wie oben. Also zum Beispiel das Setzen von synchronous_standby_names = '2 (*)' lässt die synchrone Übergabe auf die Antwort von 2 beliebigen Standby-Servern warten.
synchronous_standby_names ist leer
Wenn dieser Parameter wie gezeigt leer ist, ändert er das Verhalten der Einstellung synchronous_commit auf on , remote_write oder remote_apply sich genauso verhalten wie local (d. h. die COMMIT wird nur auf das Leeren auf die lokale Festplatte warten).
Schlussfolgerung
In diesem Blogbeitrag haben wir die synchrone Replikation besprochen und verschiedene Schutzebenen beschrieben, die in Postgres verfügbar sind. Wir werden im nächsten Blogbeitrag mit der logischen Replikation fortfahren.
Referenzen
Besonderer Dank geht an meinen Kollegen Petr Jelinek, der mir die Idee für Illustrationen gegeben hat.
PostgreSQL-Dokumentation
PostgreSQL 9 Administration Cookbook – Second Edition