Eine der vielen neuen Funktionen, die bereits in SQL Server 2008 eingeführt wurden, war die Datenkomprimierung. Die Komprimierung entweder auf Zeilen- oder Seitenebene bietet die Möglichkeit, Speicherplatz zu sparen, mit dem Nachteil, dass etwas mehr CPU zum Komprimieren und Dekomprimieren der Daten erforderlich ist. Es wird häufig argumentiert, dass die Mehrheit der Systeme IO-gebunden und nicht CPU-gebunden ist, sodass sich der Kompromiss lohnt. Der Fang? Sie mussten die Enterprise Edition verwenden, um die Datenkomprimierung verwenden zu können. Mit der Veröffentlichung von SQL Server 2016 SP1 hat sich das geändert! Wenn Sie die Standard Edition von SQL Server 2016 SP1 und höher ausführen, können Sie jetzt die Datenkomprimierung verwenden. Es gibt auch eine neue eingebaute Funktion für die Komprimierung, COMPRESS (und sein Gegenstück DECOMPRESS). Die Datenkomprimierung funktioniert nicht bei Off-Row-Daten. Wenn Sie also eine Spalte wie NVARCHAR(MAX) in Ihrer Tabelle mit Werten haben, die typischerweise größer als 8000 Byte sind, werden diese Daten nicht komprimiert (danke Adam Machanic für diese Erinnerung). . Die Funktion COMPRESS löst dieses Problem und komprimiert Daten bis zu einer Größe von 2 GB. Obwohl ich argumentieren würde, dass die Funktion nur für große Off-Row-Daten verwendet werden sollte, hielt ich es außerdem für ein lohnendes Experiment, sie direkt mit der Zeilen- und Seitenkomprimierung zu vergleichen.
EINRICHTEN
Für Testdaten arbeite ich mit einem Skript, das Aaron Bertrand zuvor verwendet hat, aber ich habe einige Änderungen vorgenommen. Ich habe zum Testen eine separate Datenbank erstellt, aber Sie können tempdb oder eine andere Beispieldatenbank verwenden, und dann habe ich mit einer Customers-Tabelle begonnen, die drei NVARCHAR-Spalten enthält. Ich habe überlegt, größere Spalten zu erstellen und sie mit Zeichenfolgen aus sich wiederholenden Buchstaben zu füllen, aber die Verwendung von lesbarem Text ergibt ein realistischeres Beispiel und bietet somit eine größere Genauigkeit.
Hinweis: Wenn Sie an der Implementierung der Komprimierung interessiert sind und wissen möchten, wie sich dies auf den Speicher und die Leistung in Ihrer Umgebung auswirkt, empfehle ich Ihnen dringend, sie zu testen. Ich gebe Ihnen die Methodik mit Beispieldaten; die Implementierung in Ihrer Umgebung sollte keine zusätzliche Arbeit erfordern.
Sie werden unten bemerken, dass wir nach dem Erstellen der Datenbank den Abfragespeicher aktivieren. Warum eine separate Tabelle erstellen, um zu versuchen, unsere Leistungsmetriken zu verfolgen, wenn wir einfach die in SQL Server integrierte Funktionalität nutzen können?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Jetzt richten wir einige Dinge in der Datenbank ein:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Mit der erstellten Tabelle fügen wir einige Daten hinzu, aber wir fügen 5 Millionen Zeilen statt 1 Million hinzu. Die Ausführung auf meinem Laptop dauert etwa acht Minuten.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Jetzt erstellen wir drei weitere Tabellen:eine für die Zeilenkomprimierung, eine für die Seitenkomprimierung und eine für die COMPRESS-Funktion. Beachten Sie, dass Sie mit der COMPRESS-Funktion die Spalten als VARBINARY-Datentypen erstellen müssen. Folglich gibt es keine Nonclustered-Indizes für die Tabelle (da Sie keinen Indexschlüssel für eine varbinary-Spalte erstellen können).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Als Nächstes kopieren wir die Daten aus [dbo].[Customers] in die anderen drei Tabellen. Dies ist ein direkter INSERT für unsere Seiten- und Zeilentabellen und dauert etwa zwei bis drei Minuten für jeden INSERT, aber es gibt ein Skalierbarkeitsproblem mit der COMPRESS-Funktion:Der Versuch, 5 Millionen Zeilen auf einen Schlag einzufügen, ist einfach nicht sinnvoll. Das folgende Skript fügt Zeilen in Stapeln von 50.000 ein und fügt nur 1 Million Zeilen anstelle von 5 Millionen ein. Ich weiß, das bedeutet, dass wir hier zum Vergleich nicht wirklich von Apfel zu Apfel stehen, aber damit bin ich einverstanden. Das Einfügen von 1 Million Zeilen dauert auf meiner Maschine 10 Minuten; Fühlen Sie sich frei, das Skript zu optimieren und 5 Millionen Zeilen für Ihre eigenen Tests einzufügen.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Wenn alle unsere Tabellen ausgefüllt sind, können wir eine Größenprüfung durchführen. An diesem Punkt haben wir keine ROW- oder PAGE-Komprimierung implementiert, aber die COMPRESS-Funktion wurde verwendet:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
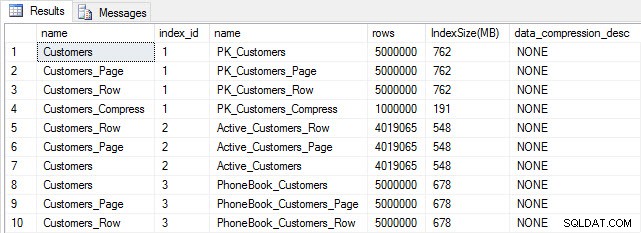 Tabellen- und Indexgröße nach dem Einfügen
Tabellen- und Indexgröße nach dem Einfügen
Wie erwartet haben alle Tabellen außer Customers_Compress ungefähr die gleiche Größe. Jetzt erstellen wir die Indizes für alle Tabellen neu und implementieren die Zeilen- und Seitenkomprimierung für Customers_Row bzw. Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Wenn wir die Tabellengröße nach der Komprimierung überprüfen, können wir jetzt unsere Speicherplatzeinsparungen sehen:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
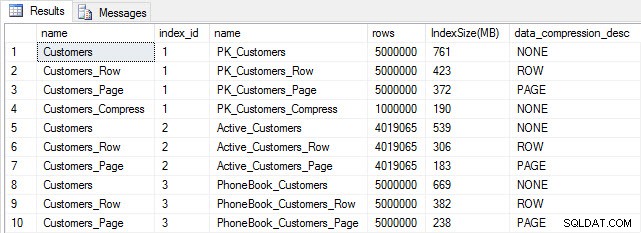
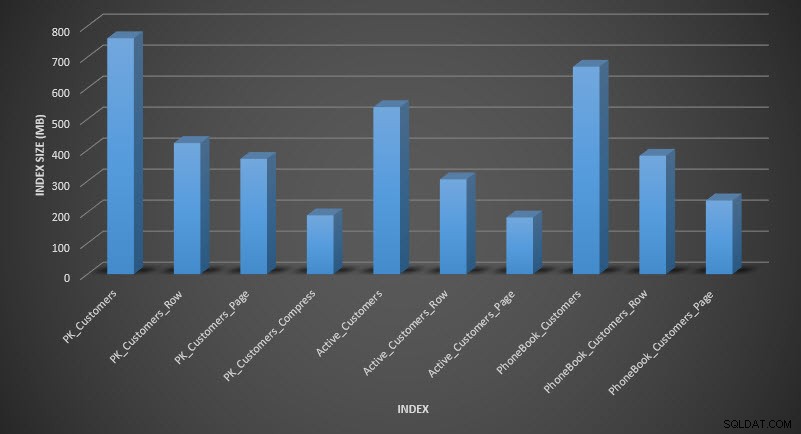 Indexgröße nach Komprimierung
Indexgröße nach Komprimierung
Wie erwartet verringert die Zeilen- und Seitenkomprimierung die Größe der Tabelle und ihrer Indizes erheblich. Die COMPRESS-Funktion hat uns am meisten Platz gespart – der Clustered-Index ist ein Viertel der Größe der Originaltabelle.
UNTERSUCHUNG DER ABFRAGELEISTUNG
Bevor wir die Abfrageleistung testen, beachten Sie, dass wir den Abfragespeicher verwenden können, um die Leistung von INSERT und REBUILD zu untersuchen:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
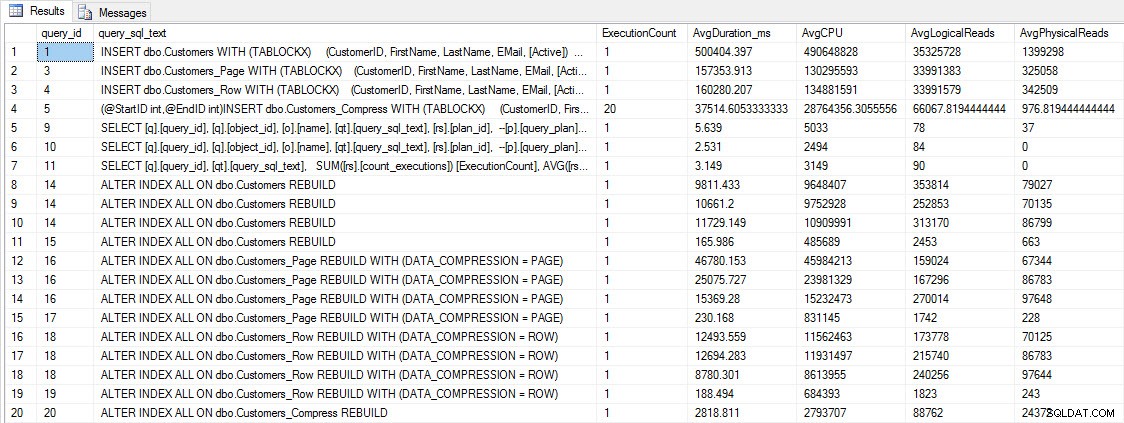 INSERT- und REBUILD-Leistungskennzahlen
INSERT- und REBUILD-Leistungskennzahlen
Obwohl diese Daten interessant sind, bin ich eher neugierig, wie sich die Komprimierung auf meine täglichen SELECT-Abfragen auswirkt. Ich habe einen Satz von drei gespeicherten Prozeduren, die jeweils eine SELECT-Abfrage haben, sodass jeder Index verwendet wird. Ich habe diese Prozeduren für jede Tabelle erstellt und dann ein Skript geschrieben, um Werte für Vor- und Nachnamen zum Testen abzurufen. Hier ist das Skript zum Erstellen der Prozeduren.
Sobald wir die gespeicherten Prozeduren erstellt haben, können wir das folgende Skript ausführen, um sie aufzurufen. Starten Sie das und warten Sie dann ein paar Minuten…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Sehen Sie sich nach ein paar Minuten an, was sich im Abfragespeicher befindet:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Sie werden sehen, dass die meisten gespeicherten Prozeduren nur 20 Mal ausgeführt wurden, weil zwei Prozeduren gegen [dbo].[Customers_Compress] wirklich sind langsam. Das ist keine Überraschung; Weder [FirstName] noch [LastName] sind indiziert, daher muss jede Abfrage die Tabelle scannen. Ich möchte nicht, dass diese beiden Abfragen meine Tests verlangsamen, also werde ich die Arbeitslast ändern und EXEC [dbo].[usp_FindActiveCustomer_CS] und EXEC [dbo].[usp_FindAnyCustomer_CS] auskommentieren und dann erneut starten. Dieses Mal lasse ich es etwa 10 Minuten lang laufen, und wenn ich mir die Ausgabe des Abfragespeichers erneut ansehe, habe ich jetzt einige gute Daten. Rohe Zahlen sind unten, mit den Diagrammen der Manager-Favoriten unten.
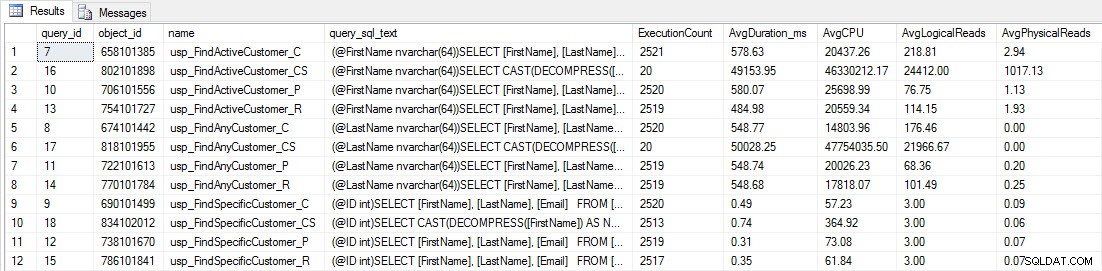 Leistungsdaten aus dem Abfragespeicher
Leistungsdaten aus dem Abfragespeicher
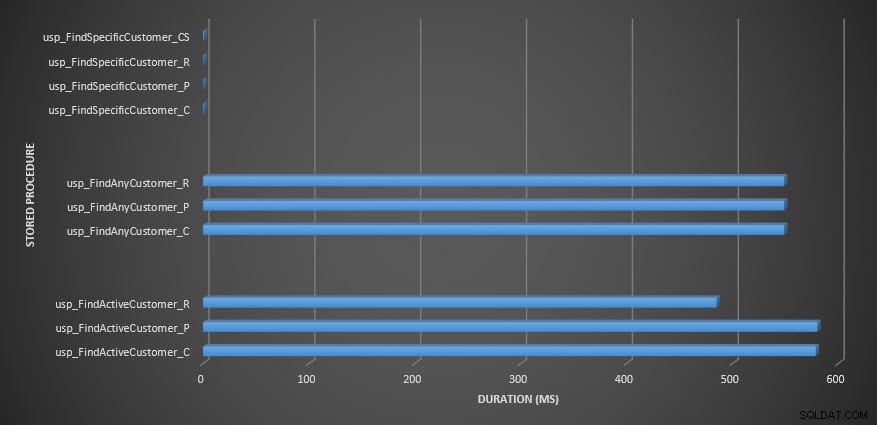 Dauer der gespeicherten Prozedur
Dauer der gespeicherten Prozedur
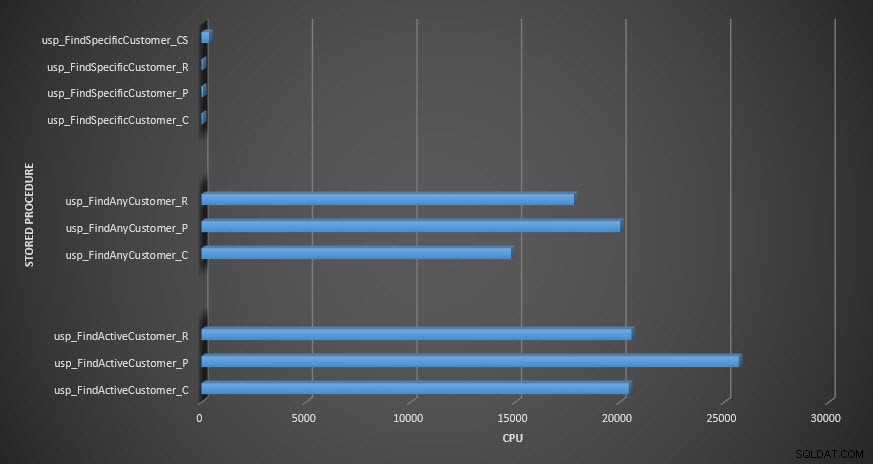 Speicherprozedur-CPU
Speicherprozedur-CPU
Erinnerung:Alle gespeicherten Prozeduren, die mit _C enden, stammen aus der nicht komprimierten Tabelle. Die Prozeduren, die mit _R enden, sind die zeilenkomprimierte Tabelle, die mit _P enden, sind seitenkomprimiert, und die mit _CS verwendet die COMPRESS-Funktion (ich habe die Ergebnisse für diese Tabelle für usp_FindAnyCustomer_CS und usp_FindActiveCustomer_CS entfernt, da sie das Diagramm so sehr verzerrt haben, dass wir die verloren haben Unterschiede in den restlichen Daten). Die Prozeduren usp_FindAnyCustomer_* und usp_FindActiveCustomer_* verwendeten Nonclustered-Indizes und gaben Tausende von Zeilen für jede Ausführung zurück.
Ich habe erwartet, dass die Dauer für die Prozeduren usp_FindAnyCustomer_* und usp_FindActiveCustomer_* für zeilen- und seitenkomprimierte Tabellen im Vergleich zur nicht komprimierten Tabelle aufgrund des Overheads beim Dekomprimieren der Daten höher ist. Die Daten des Abfragespeichers unterstützen meine Erwartung nicht – die Dauer für diese beiden gespeicherten Prozeduren ist in diesen drei Tabellen ungefähr gleich (oder in einem Fall kürzer!). Das logische IO für die Abfragen war bei den nicht komprimierten und den Seiten- und Zeilen-komprimierten Tabellen nahezu gleich.
In Bezug auf die CPU war sie in den gespeicherten Prozeduren usp_FindActiveCustomer und usp_FindAnyCustomer für die komprimierten Tabellen immer höher. Die CPU war für die usp_FindSpecificCustomer-Prozedur vergleichbar, bei der es sich immer um eine Singleton-Suche gegen den gruppierten Index handelte. Beachten Sie die hohe CPU (aber relativ kurze Dauer) für die usp_FindSpecificCustomer-Prozedur gegenüber der [dbo].[Customer_Compress]-Tabelle, die die DECOMPRESS-Funktion erforderte, um Daten in lesbarem Format anzuzeigen.
ZUSAMMENFASSUNG
Die zusätzliche CPU, die zum Abrufen komprimierter Daten erforderlich ist, ist vorhanden und kann mit Query Store oder herkömmlichen Baseline-Methoden gemessen werden. Basierend auf diesen anfänglichen Tests ist die CPU für Singleton-Lookups vergleichbar, steigt jedoch mit mehr Daten. Ich wollte SQL Server zwingen, mehr als nur 10 Seiten zu dekomprimieren – ich wollte mindestens 100. Ich habe Variationen dieses Skripts ausgeführt, bei denen Zehntausende von Zeilen zurückgegeben wurden und die Ergebnisse mit dem übereinstimmten, was Sie hier sehen. Meine Erwartung ist, dass Abfragen Hunderttausende oder Millionen von Zeilen zurückgeben müssten, um signifikante Unterschiede in der Dauer aufgrund der Zeit zum Dekomprimieren der Daten zu sehen. Wenn Sie sich in einem OLTP-System befinden, möchten Sie nicht so viele Zeilen zurückgeben, daher sollten Ihnen die Tests hier eine Vorstellung davon geben, wie sich die Komprimierung auf die Leistung auswirken kann. Wenn Sie sich in einem Data Warehouse befinden, werden Sie wahrscheinlich eine längere Dauer zusammen mit der höheren CPU sehen, wenn Sie große Datensätze zurückgeben. Während die COMPRESS-Funktion im Vergleich zur Seiten- und Zeilenkomprimierung erhebliche Platzeinsparungen bietet, machen die Leistungseinbußen in Bezug auf die CPU und die Unfähigkeit, die komprimierten Spalten aufgrund ihres Datentyps zu indizieren, sie nur für große Datenmengen rentabel, die dies nicht sein werden gesucht.