PostgreSQL ist ein großartiges Projekt und entwickelt sich mit erstaunlicher Geschwindigkeit. Wir werden uns mit einer Reihe von Blogbeiträgen auf die Entwicklung der Fehlertoleranzfunktionen in PostgreSQL in allen Versionen konzentrieren. Dies ist der dritte Beitrag der Serie und wir werden über Zeitachsenprobleme und deren Auswirkungen auf die Fehlertoleranz und Zuverlässigkeit von PostgreSQL sprechen.
Wenn Sie den Evolutionsfortschritt von Anfang an miterleben möchten, sehen Sie sich bitte die ersten beiden Blogposts der Serie an:
- Entwicklung der Fehlertoleranz in PostgreSQL
- Entwicklung der Fehlertoleranz in PostgreSQL:Replikationsphase

Zeitpläne
Die Möglichkeit, die Datenbank zu einem früheren Zeitpunkt wiederherzustellen, schafft einige Komplexitäten, auf die wir einige der Fälle abdecken, indem wir Failover erläutern (Abb. 1), Umschaltung (Abb. 2) und pg_rewind (Abb. 3) Fälle später in diesem Thema.
Angenommen, Sie haben im ursprünglichen Verlauf der Datenbank am Dienstagabend um 17:15 Uhr eine kritische Tabelle gelöscht, aber Ihren Fehler erst am Mittwochmittag bemerkt. Unbeeindruckt holen Sie Ihr Backup heraus, stellen am Dienstagabend um 17:14 Uhr den Zeitpunkt wieder her und sind einsatzbereit. In dieser Geschichte des Datenbankuniversums haben Sie die Tabelle nie gelöscht. Aber nehmen Sie an, Sie erkennen später, dass dies keine so gute Idee war, und möchten irgendwann am Mittwochmorgen in die ursprüngliche Geschichte zurückkehren. Sie können dies nicht, wenn Ihre Datenbank während des Betriebs einige der WAL-Segmentdateien überschrieben hat, die zu dem Zeitpunkt geführt haben, zu dem Sie jetzt zurückkehren möchten.
Um dies zu vermeiden, müssen Sie daher die Reihe von WAL-Datensätzen, die nach einer Point-in-Time-Wiederherstellung generiert wurden, von denen unterscheiden, die im ursprünglichen Datenbankverlauf generiert wurden.
Um mit diesem Problem fertig zu werden, hat PostgreSQL eine Vorstellung von Zeitleisten. Immer wenn eine Archivwiederherstellung abgeschlossen ist, wird eine neue Zeitachse erstellt, um die Reihe von WAL-Einträgen zu identifizieren, die nach dieser Wiederherstellung generiert wurden. Die Timeline-ID-Nummer ist Teil der WAL-Segmentdateinamen, sodass eine neue Timeline die von früheren Timelines generierten WAL-Daten nicht überschreibt. Es ist tatsächlich möglich, viele verschiedene Zeitlinien zu archivieren.
Betrachten Sie die Situation, in der Sie sich nicht ganz sicher sind, zu welchem Zeitpunkt Sie wiederherstellen sollen, und daher mehrere Point-in-Time-Wiederherstellungen durch Versuch und Irrtum durchführen müssen, bis Sie die beste Stelle gefunden haben, um von der alten Historie abzuzweigen. Ohne Fristen würde dieser Prozess schnell ein unüberschaubares Durcheinander erzeugen. Mit Zeitachsen können Sie zu jedem früheren Zustand zurückkehren, einschließlich Zuständen in Zeitachsenzweigen, die Sie zuvor verlassen haben.
Jedes Mal, wenn eine neue Zeitleiste erstellt wird, erstellt PostgreSQL eine „Zeitleistenverlaufs“-Datei, die zeigt, von welcher Zeitleiste und wann abgezweigt wurde. Diese Verlaufsdateien sind erforderlich, damit das System bei der Wiederherstellung aus einem Archiv, das mehrere Zeitachsen enthält, die richtigen WAL-Segmentdateien auswählen kann. Daher werden sie genau wie WAL-Segmentdateien im WAL-Archivbereich archiviert. Die Verlaufsdateien sind nur kleine Textdateien, daher ist es billig und angemessen, sie auf unbestimmte Zeit aufzubewahren (im Gegensatz zu den großen Segmentdateien). Sie können, wenn Sie möchten, Kommentare zu einer Verlaufsdatei hinzufügen, um Ihre eigenen Notizen darüber aufzuzeichnen, wie und warum diese bestimmte Zeitachse erstellt wurde. Solche Kommentare sind besonders wertvoll, wenn Sie als Ergebnis des Experimentierens ein Dickicht aus verschiedenen Zeitlinien haben.
Das Standardverhalten der Wiederherstellung besteht darin, entlang derselben Zeitlinie wiederherzustellen, die aktuell war, als die Basissicherung erstellt wurde. Wenn Sie in eine untergeordnete Zeitachse zurückkehren möchten (d. h. Sie möchten zu einem Zustand zurückkehren, der selbst nach einem Wiederherstellungsversuch generiert wurde), müssen Sie die Ziel-Zeitachsen-ID in recovery.conf angeben. Sie können keine Zeitachsen wiederherstellen, die vor der Basissicherung verzweigt sind.
Zur Vereinfachung des Zeitleistenkonzepts in PostgreSQL, zeitleistenbezogene Probleme im Falle eines Failovers , Umschaltung und pg_rewind sind mit Abb.1, Abb.2 und Abb.3 zusammengefasst und erklärt.
Failover-Szenario:
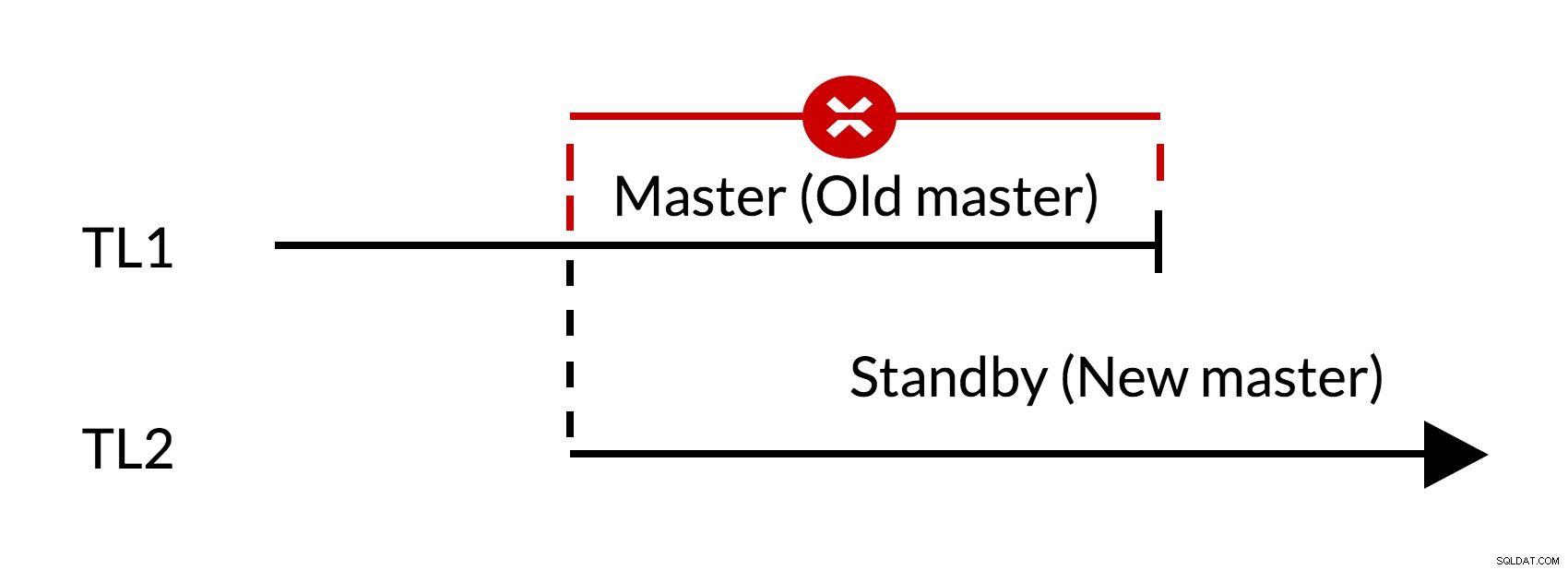
Abb. 1 Failover
- Es gibt noch ausstehende Änderungen im alten Master (TL1)
- Die Erhöhung der Zeitachse stellt den neuen Änderungsverlauf dar (TL2)
- Änderungen der alten Zeitachse können nicht auf den Servern wiedergegeben werden, die zur neuen Zeitachse gewechselt sind
- Der alte Meister kann dem neuen Meister nicht folgen
Umschaltszenario:
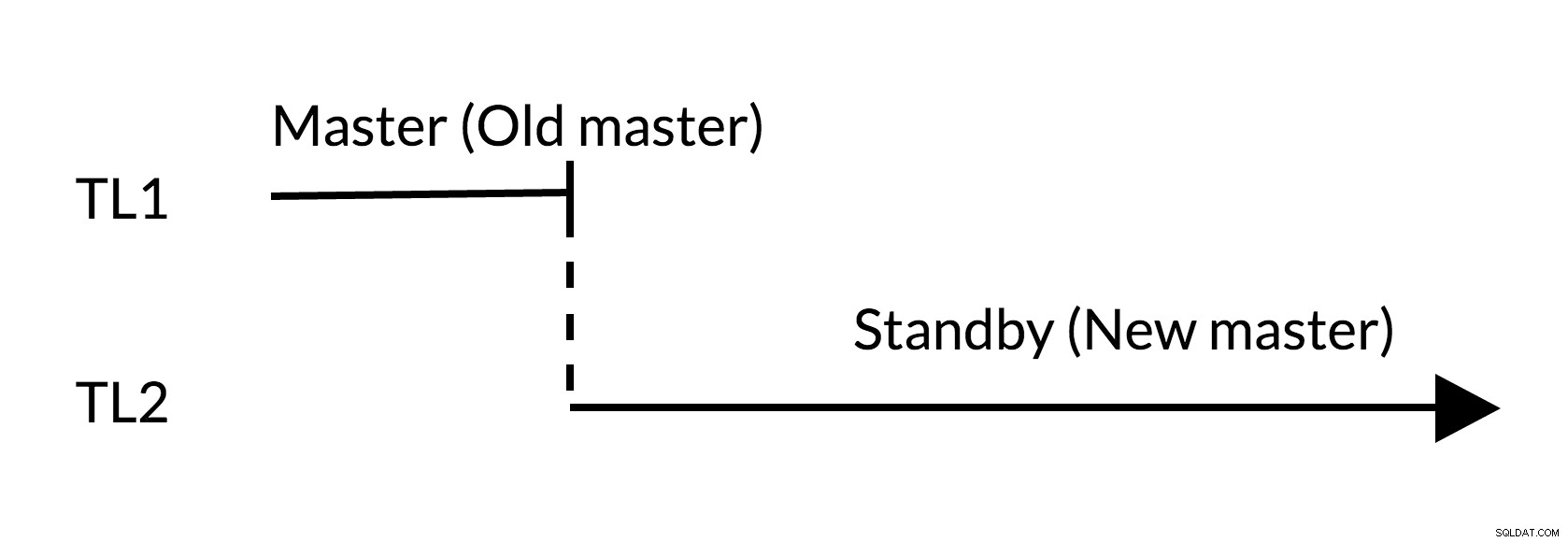 Umschaltung in Abb. 2
Umschaltung in Abb. 2
- Es gibt keine ausstehenden Änderungen im alten Master (TL1)
- Die Erhöhung der Zeitachse repräsentiert den neuen Änderungsverlauf (TL2)
- Der alte Master kann Standby für den neuen Master werden
pg_rewind Szenario:
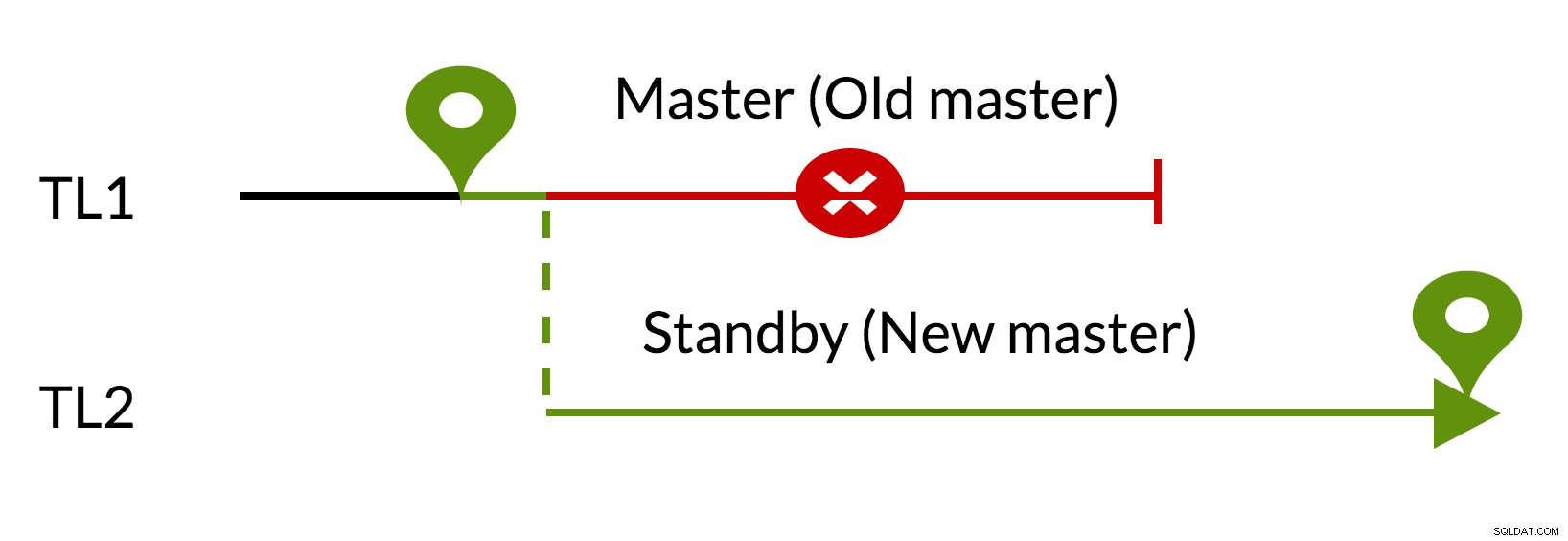 Abb.3 pg_rewind
Abb.3 pg_rewind
- Ausstehende Änderungen werden mit Daten aus dem neuen Master (TL1) entfernt
- Der alte Master kann dem neuen Master folgen (TL2)
pg_rewind
pg_rewind ist ein Tool zum Synchronisieren eines PostgreSQL-Clusters mit einer anderen Kopie desselben Clusters, nachdem die Zeitachsen der Cluster auseinandergegangen sind. Ein typisches Szenario besteht darin, einen alten Master-Server nach einem Failover als Standby-Server wieder online zu schalten, der dem neuen Master folgt.
Das Ergebnis entspricht dem Ersetzen des Zieldatenverzeichnisses durch das Quellverzeichnis. Alle Dateien werden kopiert, einschließlich Konfigurationsdateien. Der Vorteil von pg_rewind gegenüber einem neuen Basis-Backup oder Tools wie rsync besteht darin, dass pg_rewind nicht alle unveränderten Dateien im Cluster durchlesen muss. Das macht es viel schneller, wenn die Datenbank groß ist und sich nur ein kleiner Teil davon zwischen den Clustern unterscheidet.
Wie es funktioniert?
Die Grundidee besteht darin, alles aus dem neuen Cluster in den alten Cluster zu kopieren, mit Ausnahme der Blöcke, von denen wir wissen, dass sie gleich sind.
- Scannen Sie das WAL-Protokoll des alten Clusters, beginnend mit dem letzten Prüfpunkt vor dem Punkt, an dem der Zeitachsenverlauf des neuen Clusters vom alten Cluster abzweigte. Notieren Sie sich für jeden WAL-Datensatz die berührten Datenblöcke. Dies ergibt eine Liste aller Datenblöcke, die im alten Cluster geändert wurden, nachdem der neue Cluster abgezweigt wurde.
- Kopieren Sie alle diese geänderten Blöcke aus dem neuen Cluster in den alten Cluster.
- Kopieren Sie alle anderen Dateien wie Clog- und Konfigurationsdateien aus dem neuen Cluster in den alten Cluster, alles außer den Beziehungsdateien.
- Wenden Sie die WAL vom neuen Cluster an, beginnend mit dem Prüfpunkt, der beim Failover erstellt wurde. (Genau genommen wendet pg_rewind die WAL nicht an, es erstellt nur eine Backup-Label-Datei, die angibt, dass beim Start von PostgreSQL die Wiedergabe von diesem Prüfpunkt aus gestartet und die gesamte erforderliche WAL angewendet wird.)
Hinweis: wal_log_hints muss in postgresql.conf gesetzt werden, damit pg_rewind funktioniert. Dieser Parameter kann nur beim Serverstart gesetzt werden. Der Standardwert ist aus .
Schlussfolgerung
In diesem Blogbeitrag haben wir Zeitpläne in Postgres und den Umgang mit Failover- und Switchover-Fällen besprochen. Wir haben auch darüber gesprochen, wie pg_rewind funktioniert und welche Vorteile es für die Fehlertoleranz und Zuverlässigkeit von Postgres hat. Wir werden im nächsten Blogbeitrag mit dem synchronen Commit fortfahren.
Referenzen
PostgreSQL-Dokumentation
PostgreSQL 9 Administration Cookbook – Second Edition
pg_rewind Nordic PGDay Präsentation von Heikki Linnakangas