Ich habe begonnen, über das Tool (pglupgrade) zu schreiben, das ich entwickelt habe, um automatisierte Upgrades von PostgreSQL-Clustern nahezu ohne Ausfallzeiten durchzuführen. In diesem Beitrag werde ich über das Tool sprechen und seine Designdetails besprechen.
Den ersten Teil der Reihe können Sie hier einsehen: Near-Zero Downtime Automated Upgrades of PostgreSQL Clusters in Cloud (Part I).

Das Tool ist in Ansible geschrieben. Ich habe bereits Erfahrung in der Arbeit mit Ansible und arbeite derzeit auch im 2ndQuadrant damit, weshalb es für mich eine komfortable Option war. Davon abgesehen können Sie die Upgrade-Logik für minimale Ausfallzeiten, die später in diesem Beitrag erläutert wird, mit Ihrem bevorzugten Automatisierungstool implementieren.
Weiterführende Literatur:Blogposts Ansible Loves PostgreSQL , PostgreSQL Planet in Ansible Galaxy und Präsentation Verwalten von PostgreSQL mit Ansible.
Pglupgrade Playbook
In Ansible Playbooks sind die wichtigsten Skripts, die entwickelt werden, um Prozesse wie die Bereitstellung von Cloud-Instanzen und das Upgrade von Datenbankclustern zu automatisieren. Playbooks können ein oder mehrere Plays enthalten . Playbooks können auch Variablen enthalten , Rollen und Handler falls definiert.
Das Tool besteht aus zwei Haupt-Playbooks. Das erste Playbook ist provision.yml das den Prozess zum Erstellen von Linux-Maschinen in der Cloud gemäß den Spezifikationen automatisiert (Dies ist ein optionales Playbook, das nur zum Bereitstellen von Cloud-Instanzen geschrieben wurde und nicht direkt mit dem Upgrade zusammenhängt ). Das zweite (und wichtigste) Playbook ist pglupgrade.yml das den Aktualisierungsprozess von Datenbankclustern automatisiert.
Pglupgrade Playbook hat acht Plays, um das Upgrade zu orchestrieren. Verwenden Sie für jedes Spiel eine Konfigurationsdatei (config.yml ), einige Aufgaben auf den Hosts oder Hostgruppen ausführen, die in der Host-Inventardatei definiert sind (host.ini ).
Inventardatei
Eine Bestandsdatei teilt Ansible mit, welche Server für die Verbindung über SSH benötigt werden, welche Verbindungsinformationen erforderlich sind und optional welche Variablen diesen Servern zugeordnet sind. Unten sehen Sie eine Beispiel-Inventardatei, die verwendet wurde, um automatisierte Cluster-Upgrades für eine der Fallstudien durchzuführen, die für das Tool entwickelt wurden. Wir werden diese Fallstudien in den kommenden Posts dieser Serie besprechen.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
Inventardatei (host.ini )
Die Beispielinventardatei enthält fünf Hosts unter fünf Gastgebergruppen die old-primary enthalten , new-primary , old-standbys , new-standbys und pgbouncer . Ein Server kann mehreren Gruppen angehören. Zum Beispiel die old-standbys ist eine Gruppe, die new-standbys enthält Gruppe, d. h. die Hosts, die unter old-standbys definiert sind Gruppe (54.77.249.81 und 54.154.49.180) gehört ebenfalls zu den new-standbys Gruppe. Mit anderen Worten, die new-standbys Gruppe wird von (Kindern von) old-standbys geerbt Gruppe. Dies wird durch die Verwendung des speziellen :children erreicht Suffix.
Sobald die Inventardatei fertig ist, kann das Ansible-Playbook über ansible-playbook ausgeführt werden Befehl, indem Sie auf die Inventardatei zeigen (wenn sich die Inventardatei nicht am Standardspeicherort befindet, wird ansonsten die Standardinventardatei verwendet), wie unten gezeigt:
$ ansible-playbook -i hosts.ini pglupgrade.yml
Ausführen eines Ansible-Playbooks
Konfigurationsdatei
Pglupgrade Playbook verwendet eine Konfigurationsdatei (config.yml ), mit der Benutzer Werte für die logischen Upgrade-Variablen angeben können.
Wie unten gezeigt, die config.yml speichert hauptsächlich PostgreSQL-spezifische Variablen, die zum Einrichten eines PostgreSQL-Clusters erforderlich sind, z. B. postgres_old_datadir und postgres_new_datadir um den Pfad des PostgreSQL-Datenverzeichnisses für die alte und neue PostgreSQL-Version zu speichern; postgres_new_confdir um den Pfad des PostgreSQL-Konfigurationsverzeichnisses für die neue PostgreSQL-Version zu speichern; postgres_old_dsn und postgres_new_dsn um die Verbindungszeichenfolge für den pglupgrade_user zu speichern um sich mit der pglupgrade_database verbinden zu können des neuen und des alten Primärservers. Die Verbindungszeichenfolge selbst besteht aus den konfigurierbaren Variablen, sodass der Benutzer (pglupgrade_user ) und die Datenbank (pglupgrade_database ) Informationen können für die verschiedenen Anwendungsfälle geändert werden.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" Konfigurationsdatei (config.yml )
Als wichtiger Schritt für jedes Upgrade können die PostgreSQL-Versionsinformationen für die aktuelle Version (postgres_old_version ) und die Version, auf die aktualisiert wird (postgres_new_version ). Im Gegensatz zur physischen Replikation, bei der die Replikation eine Kopie des Systems auf Byte-/Blockebene ist, ermöglicht die logische Replikation eine selektive Replikation wo die Replikation die logischen Daten kopieren kann, einschließlich angegebener Datenbanken und der Tabellen in diesen Datenbanken. Aus diesem Grund config.yml ermöglicht die Konfiguration, welche Datenbank über pglupgrade_database repliziert werden soll Variable. Außerdem muss der Benutzer der logischen Replikation über Replikationsberechtigungen verfügen, weshalb pglupgrade_user Variable sollte in der Konfigurationsdatei angegeben werden. Es gibt andere Variablen, die sich auf funktionierende Interna von pglogical beziehen, wie z. B. subscription_name und replication_set die in der pglogischen Rolle verwendet werden.
Hochverfügbarkeitsdesign des Pglupgrade-Tools
Das Pglupgrade-Tool wurde entwickelt, um dem Benutzer die Flexibilität in Bezug auf Hochverfügbarkeitseigenschaften (HA) für die verschiedenen Systemanforderungen zu geben. Die initial_standbys Variable (siehe config.yml ) ist der Schlüssel zum Festlegen von HA-Eigenschaften des Clusters während des Upgrade-Vorgangs.
Wenn beispielsweise initial_standbys auf 1 gesetzt ist (kann auf eine beliebige Zahl gesetzt werden, die die Clusterkapazität zulässt), bedeutet dies, dass im aktualisierten Cluster zusammen mit dem Master 1 Standby erstellt wird, bevor die Replikation beginnt. Mit anderen Worten, wenn Sie 4 Server haben und initial_standbys auf 1 setzen, haben Sie 1 Primär- und 1 Standby-Server in der aktualisierten neuen Version sowie 1 Primär- und 1 Standby-Server in der alten Version.
Diese Option ermöglicht die Wiederverwendung der vorhandenen Server, während das Upgrade noch läuft. Im Beispiel mit 4 Servern können die alten Primär- und Standby-Server als 2 neue Standby-Server neu erstellt werden, nachdem die Replikation abgeschlossen ist.
Wenn initial_standbys Variable auf 0 gesetzt ist, werden keine anfänglichen Standby-Server im neuen Cluster erstellt, bevor die Replikation beginnt.
Wenn die initial_standbys Konfiguration klingt verwirrend, keine Sorge. Dies wird im nächsten Blogbeitrag besser erklärt, wenn wir zwei verschiedene Fallstudien diskutieren.
Schließlich ermöglicht die Konfigurationsdatei die Angabe alter und neuer Servergruppen. Dies könnte auf zwei Arten bereitgestellt werden. Erstens, wenn ein Cluster vorhanden ist, die IP-Adressen der Server (können entweder Bare-Metal- oder virtuelle Server sein ) sollte in hosts.ini eingetragen werden Datei, indem die gewünschten HA-Eigenschaften während des Upgrade-Vorgangs berücksichtigt werden.
Die zweite Möglichkeit besteht darin, provision.yml auszuführen Playbook (So habe ich die Cloud-Instanzen bereitgestellt, aber Sie können Ihre eigenen Bereitstellungsskripts verwenden oder Instanzen manuell bereitstellen ), um leere Linux-Server in der Cloud (AWS EC2-Instanzen) bereitzustellen und die IP-Adressen der Server in die hosts.ini zu bekommen Datei. So oder so, config.yml erhält Host-Informationen über hosts.ini Datei.
Workflow des Upgrade-Prozesses
Nach Erläuterung der Konfigurationsdatei (config.yml ), die von pglupgrade Playbook verwendet wird, können wir den Arbeitsablauf des Upgrade-Prozesses erläutern.
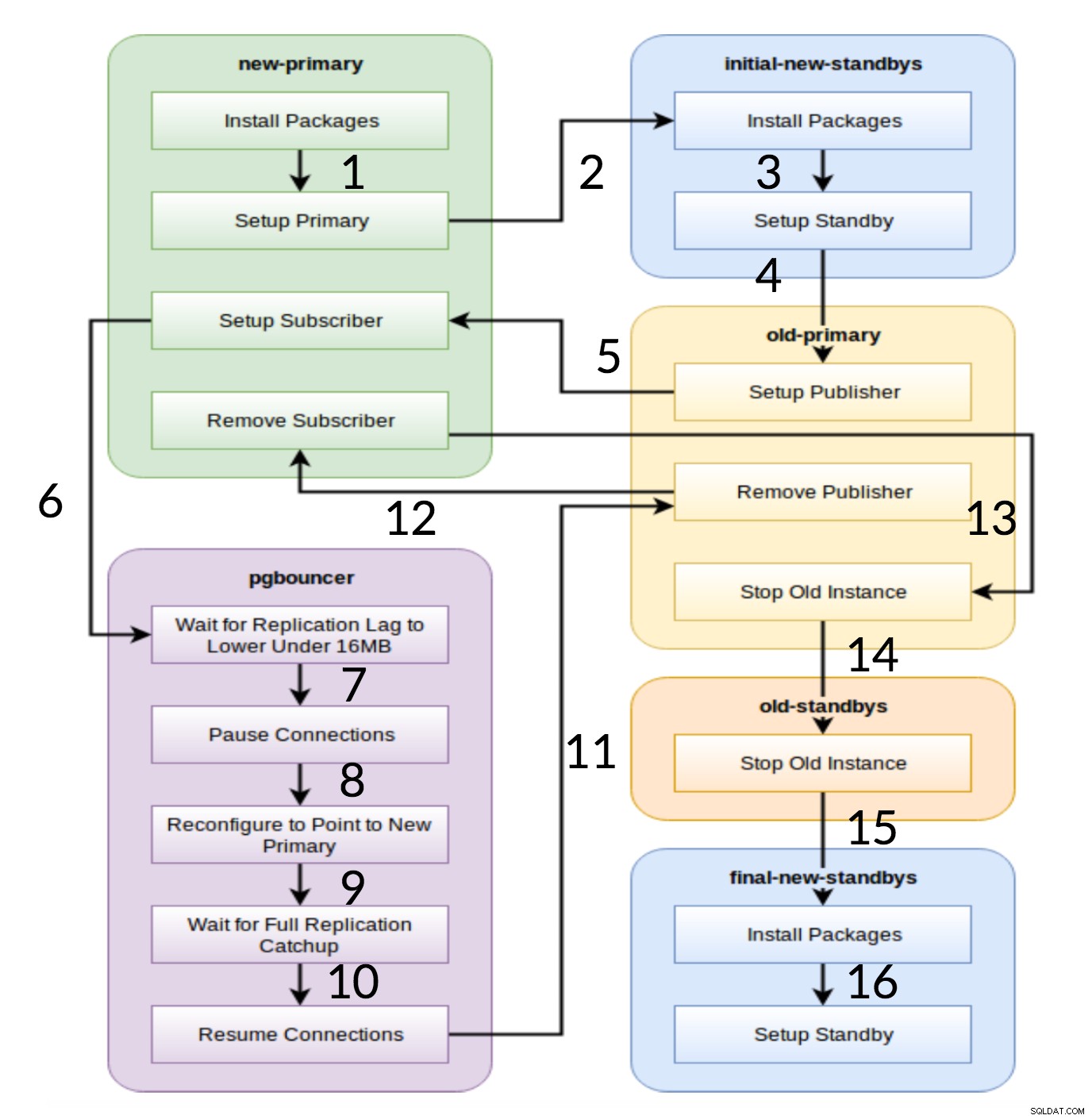
Pglupgrade-Arbeitsablauf
Wie aus dem obigen Diagramm ersichtlich, gibt es sechs Servergruppen, die zu Beginn basierend auf der Konfiguration (beide hosts.ini und die config.yml ). Der new-primary und old-primary Gruppen haben immer einen Server, pgbouncer Gruppe kann einen oder mehrere Server haben und alle Standby-Gruppen können null oder mehr Server enthalten. Hinsichtlich der Implementierung ist der gesamte Prozess in acht Schritte unterteilt. Jeder Schritt entspricht einem Play im pglupgrade-Playbook, das die erforderlichen Aufgaben auf den zugewiesenen Hostgruppen ausführt. Der Upgrade-Prozess wird durch folgende Stücke erklärt:
- Hosts basierend auf der Konfiguration erstellen: Vorbereitungsspiel, das basierend auf der Konfiguration interne Gruppen von Servern aufbaut. Das Ergebnis dieses Spiels (in Kombination mit der
hosts.iniInhalt) sind die sechs Servergruppen (im Workflow-Diagramm mit unterschiedlichen Farben dargestellt), die von den folgenden sieben Spielen verwendet werden. - Neuen Cluster mit initialen Standby(s) einrichten: Richtet einen leeren PostgreSQL-Cluster mit den neuen primären und anfänglichen Standby-Instanzen ein (sofern definiert). Es stellt sicher, dass keine PostgreSQL-Installationen von der vorherigen Verwendung übrig bleiben.
- Ändern Sie die alte Primärdatenbank, um die logische Replikation zu unterstützen: Installiert die pglogical-Erweiterung. Legt dann den Herausgeber fest, indem er alle Tabellen und Sequenzen zur Replikation hinzufügt.
- Auf die neue Primärdatenbank replizieren: Richtet den Abonnenten auf dem neuen Master ein, der als Auslöser zum Starten der logischen Replikation fungiert. Dieses Spiel schließt die Replikation der vorhandenen Daten ab und beginnt mit der Erfassung der Änderungen seit Beginn der Replikation.
- Stellen Sie den Pgbouncer (und die Anwendungen) auf den neuen primären Server um: Wenn die Replikationsverzögerung gegen Null konvergiert, hält der Pgbouncer an, um die Anwendung schrittweise umzuschalten. Dann zeigt es pgbouncer config auf die neue primäre und wartet, bis die Replikationsdifferenz null erreicht. Schließlich wird pgbouncer wieder aufgenommen und alle wartenden Transaktionen werden an die neue Primärdatenbank weitergegeben und beginnen dort mit der Verarbeitung. Erste Standbys werden bereits verwendet und antworten auf Leseanforderungen.
- Bereinigen Sie die Replikationseinrichtung zwischen der alten primären und der neuen primären: Beendet die Verbindung zwischen dem alten und dem neuen primären Server. Da alle Anwendungen auf den neuen primären Server verschoben und das Upgrade abgeschlossen ist, ist keine logische Replikation mehr erforderlich. Die Replikation zwischen Primär- und Standby-Servern wird mit der physischen Replikation fortgesetzt.
- Beenden Sie den alten Cluster: Der Postgres-Dienst wird auf alten Hosts angehalten, um sicherzustellen, dass keine Anwendung mehr eine Verbindung zu ihm herstellen kann.
- Rekonfigurieren Sie die restlichen Standbys für die neue primäre: Stellt andere Standbys wieder her, wenn andere Hosts als anfängliche Standbys vorhanden sind. In der zweiten Fallstudie müssen keine Standby-Server mehr neu aufgebaut werden. Dieser Schritt bietet die Möglichkeit, den alten Primärserver als neuen Standby-Server neu zu erstellen, wenn in der Gruppe new-standbys in der hosts.ini darauf verwiesen wird. Die Wiederverwendbarkeit vorhandener Server (sogar des alten Primärservers) wird durch die Verwendung des zweistufigen Standby-Konfigurationsdesigns des pglupgrade-Tools erreicht. Der Benutzer kann angeben, welche Server vor dem Upgrade Standby-Server des neuen Clusters werden sollen und welche nach dem Upgrade Standby-Server werden sollen.
Schlussfolgerung
In diesem Beitrag haben wir die Implementierungsdetails und das Hochverfügbarkeitsdesign des pglupgrade-Tools besprochen. Dabei haben wir auch einige Schlüsselkonzepte der Ansible-Entwicklung (d. h. Playbook, Inventory und Config-Dateien) am Beispiel des Tools erwähnt. Wir haben den Arbeitsablauf des Upgrade-Prozesses veranschaulicht und zusammengefasst, wie jeder Schritt mit einem entsprechenden Spiel funktioniert. Wir werden pglupgrade weiterhin erläutern, indem wir Fallstudien in kommenden Beiträgen dieser Reihe zeigen.
Danke fürs Lesen!