Denken Sie an etwas, wenn Sie eine neue Datenbank erstellen? Ich denke, die meisten von Ihnen würden nein sagen, da wir alle Standardparameter verwenden, obwohl sie bei weitem nicht optimal sind. Es gibt jedoch eine Reihe von Disc-Einstellungen, die wirklich dazu beitragen, die Zuverlässigkeit und Leistung des Systems zu verbessern.
Wir werden nicht über die Bedeutung des NTFS-Dateisystems für die Datenzuverlässigkeit sprechen, obwohl dieses Dateisystem es MS SQL Server ermöglicht, die Festplatte am effektivsten zu nutzen.
Wenn Ihnen die Ressourcen ausgehen und etwas langsam funktioniert, fällt Ihnen als erstes ein Upgrade ein. Ein Upgrade ist jedoch nicht in jedem Fall erforderlich. Sie können mit dem Tuning davonkommen, obwohl es nicht getan werden sollte, wenn der Server langsam läuft, sondern in der Phase des Designs und der Installation.
Optimierung ist ein komplexer Prozess und bezieht sich oft nicht nur auf ein bestimmtes Programm (in unserem Fall auf eine bestimmte Datenbank), sondern auch auf Betriebssystem und Hardware. Obwohl wir hauptsächlich über Datenbanken sprechen werden, können wir die äußeren Dinge nicht ignorieren.
Datenarchitektur
SQL Server speichert, liest und schreibt Daten in Blöcken von jeweils 8 KB. Diese Blöcke werden Seiten genannt. Eine Datenbank kann 128 Seiten pro Megabyte speichern (1 Megabyte oder 1048576 Byte dividiert durch 8 Kilobyte oder 8192 Byte). Alle Seiten werden in einem Extent gespeichert. Ein Extent besteht aus den letzten 8 aufeinanderfolgenden Seiten oder 64 KB. Somit speichert 1 Megabyte 16 Extents.
Seiten und Extents sind die Grundlage der physischen Datenbankstruktur von SQL Server. MS SQL Server verwendet verschiedene Seitentypen, von denen einige den zugewiesenen Speicherplatz nachverfolgen, andere Benutzerdaten und Indizes enthalten. Seiten, die den zugewiesenen Speicherplatz verfolgen, enthalten die dicht komprimierten Daten. Es ermöglicht MS SQL Server, sie zum einfachen Lesen effektiv im Speicher zu speichern.
SQL Server verwendet zwei Arten von Extents:
- Extents, die Seiten von zwei bis zu vielen Objekten speichern, werden gemischte Extents genannt. Jede Tabelle beginnt als gemischter Extent. Sie verwenden gemischte Ausdehnung hauptsächlich für die Seiten, die Speicherplatz speichern und kleine Objekte enthalten.
- Extents, bei denen alle 8 Seiten einem Objekt zugeordnet sind, werden einheitliche Extents genannt. Sie werden verwendet, wenn eine Tabelle oder ein Index mehr als 64 KB benötigt.
Der erste Extent für jede Datei ist einheitlich und enthält Seiten des Dateikopfes, die nächsten Extents enthalten jeweils 3 zugeordnete Seiten. Der Server weist diese gemischten Extents zu, wenn Sie eine Basisdatendatei erstellen, und verwendet diese Seiten für seine internen Aufgaben. Die Dateikopfseite enthält Dateiattribute, wie den Namen der in der Datei gespeicherten Datenbank, Dateigruppe, Mindestgröße, Inkrementgröße. Dies ist die erste Seite jeder Datei (Seite 0).
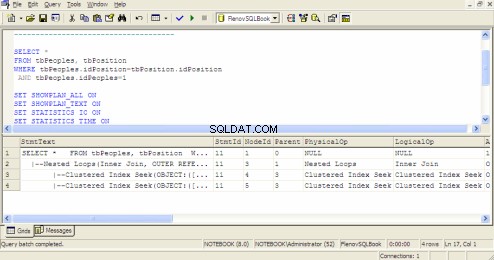
Abfrageausführungsplan in SQL Query Analyzer
Freier Speicherplatz auf Seite (PFS ) auf einer zugewiesenen Seite, die Informationen über den in der Datei verfügbaren freien Speicherplatz enthält. Diese Informationen werden auf Seite 1 gespeichert. Jede dieser Seiten kann bis zu 8000 zusammenhängende Seiten umfassen, was ungefähr 64 MB an Daten entspricht.
Das Transaktionsprotokoll sammelt alle Informationen über die Änderungen, die auf dem Server stattfinden, um eine Datenbank im Moment eines Systemfehlers wiederherzustellen und die Datenintegrität sicherzustellen.
Beachten Sie, dass alle Zahlen Vielfache von 8 oder 16 sind. Dies liegt daran, dass der Festplattencontroller Daten dieser Größe leichter lesen kann. Die Daten werden seitenweise von der Platte gelesen, also 8 Kilobyte, was ein recht optimaler Wert ist.
Seitenschutz
Ab MS SQL Server 2005 verfügt der Datenbankserver über eine neue Option – die Datenkontrolle auf Seitenebene. Wenn die AGE_VERIFY_CHECKSUM Parameter aktiviert ist (standardmäßig aktiviert), kontrolliert der Server die Prüfsummen der Seiten. Wenn wir im Handbuch nach diesem Parameter suchen, werden wir sehen, dass die Prüfsumme die Verfolgung der Ein-/Ausgabefehler ermöglicht, die das Betriebssystem nicht verfolgen kann. Was sind das für Fehler? Es scheint, dass es sich um interne Probleme des Datenbankservers handelt.
Die Datenintegritätsprüfung geht nie schief, also ist es besser, sie zu aktivieren. Dazu müssen wir den folgenden Befehl ausführen:
ALTER DATABASE имя базы SET PAGE_VERIFY
Wenn auf der Seite ein Fehler auftritt, benachrichtigt uns der Server darüber. Aber wie können wir es schnell beheben? Dafür gibt es die Möglichkeit, Daten auf Seitenebene wiederherzustellen.
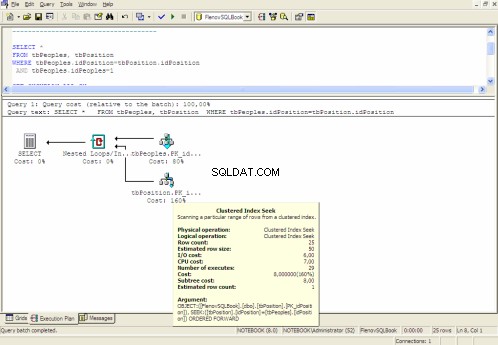
Grafischer Ausführungsplan
Dateiwachstum
Wenn wir eine Datenbank erstellen, werden wir aufgefordert, die Anfangsgröße und die Inkrementmethode auszuwählen. Wenn der aktuelle Speicherplatz knapp wird, erweitert der Server ihn entsprechend der voreingestellten Inkrementmethode.
Es gibt drei Inkrementmethoden für Dateien:
- Wachstum in Megabyte.
- Wachstum in Prozent.
- Manuelles Wachstum.
Die ersten beiden Methoden werden automatisch durchgeführt, aber sie werden nur für Testdatenbanken empfohlen, da ein Administrator keine Kontrolle über die Dateigröße hat.
Wenn eine Datei um eine bestimmte Menge an Megabyte erhöht wird, kann die Geschwindigkeit der Dateneinfügung an einem bestimmten Punkt zunehmen und das Dateiwachstum kann zu häufig werden, und dies ist mit zusätzlichen Kosten verbunden. Dateiwachstum in Prozent ist ebenfalls unrentabel. Es wird empfohlen, ein Dateiwachstum von 10 % zu verwenden, was für kleine und mittlere Datenbanken in Ordnung ist. Aber wenn es 1000 Gigabyte erreicht, werden bei jedem Wachstum 100 Gigabyte benötigt. Dies führt zu einer sinnlosen Verschwendung von Speicherplatz.
Kontrollieren Sie immer Änderungen in der Größe von Dateien und Transaktionsprotokollen. Dadurch können Sie die Disc-Ressourcen auf die effektivste Weise nutzen.
Eigenschaften der MS SQL Server-Datenbank
Datenkomprimierung
Die Festplatte bleibt ein sensibler Punkt eines Computers. Die Leistung von Prozessoren wächst rasant, während Festplatten nichts Neues bieten können. Um die Anzahl der Ein-/Ausgabeoperationen einzusparen und die auf der Festplatte gespeicherten Daten zu reduzieren, können Sie Datenträger mit Komprimierung verwenden. Nur solche Discs eignen sich gut zum Speichern von schreibgeschützten Dateigruppen. Vielleicht liegt es daran, dass für das Schreiben eine Komprimierung erforderlich ist und zusätzliche Prozessorkosten anfallen.
Datenkomprimierung und Read-Only-Zustand sind gut für die Archivdaten. Beispielsweise sind Buchhaltungsdaten der vergangenen Jahre zum Schreiben nicht erforderlich und können zu viel Platz beanspruchen. Indem Sie Daten im Archivbereich der Festplatte ablegen, sparen Sie erheblich Platz.
Festplatten für Zuverlässigkeit
Die folgende Methode ermöglicht es, gleichzeitig die Zuverlässigkeit und Leistung zu erhöhen, und bezieht sich wiederum auf Festplatten. Nun, da ist es, die Mechanik ist nicht nur die langsamste, sondern auch die unzuverlässigste. Zur Zuverlässigkeit habe ich keine Statistiken erhoben, aber sowohl zu Hause als auch bei der Arbeit beschäftige ich mich hauptsächlich mit Festplatten.
Um die Leistung und Zuverlässigkeit zu erhöhen, können Sie also einfach zwei oder mehr Festplatten anstelle von einer verwenden. Noch besser ist es, wenn sie an separate Controller angeschlossen werden. Sie können die Datenbank auf einem Datenträger und Transaktionsprotokolle auf einem anderen speichern. Wenn es eine dritte Festplatte gibt, kann sie das System speichern.
Durch das Speichern von Daten und einem Protokoll auf separaten Datenträgern können Sie die Zuverlässigkeit erheblich erhöhen. Angenommen, Sie haben alles auf einer Festplatte und diese fällt aus. Was ist zu tun? Sie können ein Unternehmen erreichen, das versucht, alles wiederherzustellen, oder versuchen, dasselbe selbst zu tun, aber die Chance auf eine Wiederherstellung ist bei weitem nicht 100 %. Außerdem kann es viel Zeit in Anspruch nehmen, den Server wieder betriebsbereit zu machen. Eine schnelle Wiederherstellung kann nur bis zum Zeitpunkt der letzten Sicherungskopie durchgeführt werden. Der Rest ist fragwürdig.
Und jetzt nehmen Sie an, Sie haben Daten und ein Transaktionsprotokoll auf verschiedenen Platten. Wenn die Platte mit dem Protokoll ausgeht, sind noch Daten vorhanden. Die einzige Sache ist, dass Sie keine neuen Daten hinzufügen können, aber wenn Sie ein neues Protokoll erstellen, können Sie weiterarbeiten.
Wenn die Festplatte mit Daten ausfällt, können wir das Transaktionsprotokoll immer noch reservieren, um den kleinsten Datenverlust zu verhindern. Danach stellen wir die Daten aus der kompletten Sicherung wieder her (sollte immer vorher gemacht werden, ein guter Administrator macht das mindestens einmal am Tag) und fügen Änderungen aus der Sicherungskopie des Logs hinzu.
Festplatten für Leistung
Wenn sich Daten und ein Log auf getrennten Platten befinden, bedeutet das nicht nur Sicherheit, sondern auch Performance-Zuwachs. Die Sache ist, dass der Datenbankserver gleichzeitig Daten in die Protokoll- und Datendatei schreiben kann.
Wir können noch weiter gehen und dem Transaktionsprotokoll eine Festplatte und den Daten mehrere Festplatten zuweisen. Der Server arbeitet häufiger mit Daten, weshalb er mehrere Speicher benötigt, mit denen Sie gleichzeitig arbeiten können. Und wenn diese Speicher an verschiedene Controller angeschlossen sind, ist das gleichzeitige Arbeiten garantiert.
Die schnellste und zuverlässigste Variante ist die Verwendung von RAID . Allerdings nicht bei jedem RAID ist zuverlässig und schnell zugleich. Für die Dateigruppen wird empfohlen, RAID10 zu wählen , da es ausgewogene Features enthält, aber je nach Datenbankdaten können Sie eine andere Variante wählen.
Sie können eine Software- oder Hardwarelösung als RAID verwenden . Eine Softwarelösung ist billiger, erfordert jedoch zusätzliche CPU-Ressourcen. Und ein Prozessor hat keine freien Ressourcen. Verwenden Sie daher besser Hardwarelösungen, bei denen ein dedizierter Chip für RAID zuständig ist .
Indizes
Jeder weiß, dass Indizes helfen, die Suchgeschwindigkeit von Daten zu erhöhen. Die meisten von uns wissen, dass Indizes das Einfügen und Aktualisieren von Daten negativ beeinflussen. Je mehr Indizes Sie haben, desto schwieriger ist es für den Server, sie zu verwalten. Dabei denken nicht viele, dass Indizes gewartet werden müssen. Datenbankseiten mit Indexdaten können überlaufen und schließlich unausgeglichen werden.
Ja, wir können verschiedene Parameter ignorieren und Indizes einfach einmal im Monat neu erstellen, was einer Wartung ähnelt. SQL Server enthält zwei Parameter, die verhindern, dass Indizes innerhalb einer halben Stunde nach ihrer Erstellung veraltet sind:FILLFACTOR und PAD_INDEX .
Sie können die Option FILLFACTOR verwenden, um die Leistung der Einfüge- und Aktualisierungsvorgänge zu optimieren, die einen gruppierten oder nicht gruppierten Index enthalten. Indexdaten können in vielen Datenseiten gespeichert werden. Wie ich oben erwähnt habe, besteht jede Seite aus 8 KB. Wenn eine Indexseite voll ist, erstellt der Server eine neue Seite und teilt die Seite für die Dateneinfügung in zwei Teile.
Der Server benötigt Zeit für die Seitenteilung und Erstellung einer neuen Seite. Verwenden Sie zur Optimierung der Seitenaufteilung den FILLFACTOR Option, um den Prozentsatz des freien Speicherplatzes auf allen Blättern der Indexseite zu bestimmen. Je mehr Speicherplatz die Seiten auf Blattebene haben, desto seltener müssen Sie Indexseiten teilen. Dann wird der Indexbaum zu groß und seine Umgehung wird zusätzliche Zeit in Anspruch nehmen.
Der PAD_INDEX Die Option gibt den Füllprozentsatz der Nicht-Blatt-Seiten an. Sie können PAD_INDEX verwenden nur wenn der FILLFACTOR Option wird seit dem Prozentwert von PAD_INDEX angegeben hängt von dem in FILLFACTOR angegebenen Prozentsatz ab .
Statistiken
Statistiken ermöglichen es dem Server, die richtige Entscheidung zwischen Indexnutzung und vollständigem Tabellenscannen zu treffen. Angenommen, Sie haben eine Liste der Mitarbeiter einer Gießerei. Eine solche Liste besteht aus etwa 90 % der Männer.
Angenommen, wir müssen alle Frauen finden. Da es nicht viele davon gibt, ist die Verwendung des Index die effektivste Option. Aber wenn wir alle Männer finden müssen, verlangsamt sich die Indexeffizienz. Die Anzahl der ausgewählten Datensätze ist zu groß und das Umgehen des Indexbaums für jeden von ihnen ist ein Overhead. Es ist viel einfacher, die gesamte Tabelle zu scannen – die Ausführung wird viel schneller sein, da der Server alle Low-Level-Blätter des Index einmal lesen muss, ohne dass mehrere Lesevorgänge aller Ebenen erforderlich sind.
SQL Server sammelt Statistiken durch Lesen aller Feldwerte oder mit einer Vorlage zum Erstellen der gleichmäßig verteilten und sortierten Werteliste. SQL Server erkennt dynamisch den Prozentsatz der Zeilen, die getestet werden müssen, basierend auf der Anzahl der Zeilen in der Tabelle. Beim Sammeln von Statistiken führt der Abfrageoptimierer entweder einen vollständigen Scan oder Zeilenvorlagen aus.
Damit Statistiken funktionieren, müssen sie erstellt werden. Im Falle einer massiven Datenaktualisierung können die Statistiken falsche Daten enthalten und der Server wird eine falsche Entscheidung treffen. Aber alles kann richtig gestellt werden, – Sie müssen Statistiken überwachen. Ausführlichere Informationen finden Sie in den Büchern zu Transact-SQL oder MS SQL Server.
Zusammenfassung
Die Standardeinstellungen erlauben es nicht, das gesamte Potenzial der Hardware zu nutzen und mit der ganzen Vielfalt von Servern zu arbeiten. Die Verantwortung für die Einstellungen liegt bei den Administratoren. Die Tatsache, dass die Microsoft-Produkte über einfache Installationsprogramme, grafische Verwaltungsfunktionen und die Möglichkeit verfügen, offline zu arbeiten, bedeutet nicht, dass dies eine optimale Variante ist.
Wir betrachten solche Datenbankoptimierungsoptionen nicht als Hardwarebeschleunigung. Wenn alle Tuning-Optionen erschöpft sind, ist es besser, über das Upgrade nachzudenken, da die Hardwarebeschleunigung die Systemzuverlässigkeit negativ beeinflusst.
Das Wichtigste ist, dass jede Optimierung des Datenbankservers oder jedes Upgrade nicht hilft, wenn die Abfragen nicht optimiert sind.