Dieser Artikel enthält eine Schritt-für-Schritt-Anleitung zur Nutzung von Machine Learning-Funktionen mit 2UDA. In diesem Artikel verwenden wir ein Beispiel für Tiere, um vorherzusagen, ob es sich um Säugetiere, Vögel, Fische oder Insekten handelt.
Softwareversionen
Wir werden 2UDA Version 11.6-1 verwenden, um das Modell des maschinellen Lernens zu implementieren. 2UDA-Version 11.6-1 kombiniert:
- PostgreSQL 11.6
- Orange 3.23.0
Die neueste Version von 2UDA finden Sie hier.
Schritt 1:Trainingsdatensatz in PostgreSQL laden
Der Beispieldatensatz, der zum Trainieren unseres Modells verwendet wird, ist hier im offiziellen Orange GitHub-Repository verfügbar.
Befolgen Sie diese Schritte, um die Trainingsdaten in PostgreSQL-Tabellen zu laden:
- Stellen Sie eine Verbindung zu PostgreSQL über psql, OmniDB oder ein anderes Tool her, mit dem Sie vertraut sind.
- Erstellen Sie eine Tabelle, um unsere Trainingsdaten zu speichern . Hier heißt es training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Trainingsdaten per COPY-Abfrage in die Tabelle einfügen. Stellen Sie vor dem Ausführen der COPY-Abfrage sicher, dass PostgreSQL über erforderliche Leseberechtigungen für die Datendatei verfügt, andernfalls schlägt der COPY-Vorgang fehl.
HINWEIS: Bitte stellen Sie sicher, dass Sie einen Tabulator eingeben Leerzeichen zwischen einfachen Anführungszeichen nach dem Trennzeichen Schlüsselwort.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Unten finden Sie den Screenshot des Trainingsdatensatzes
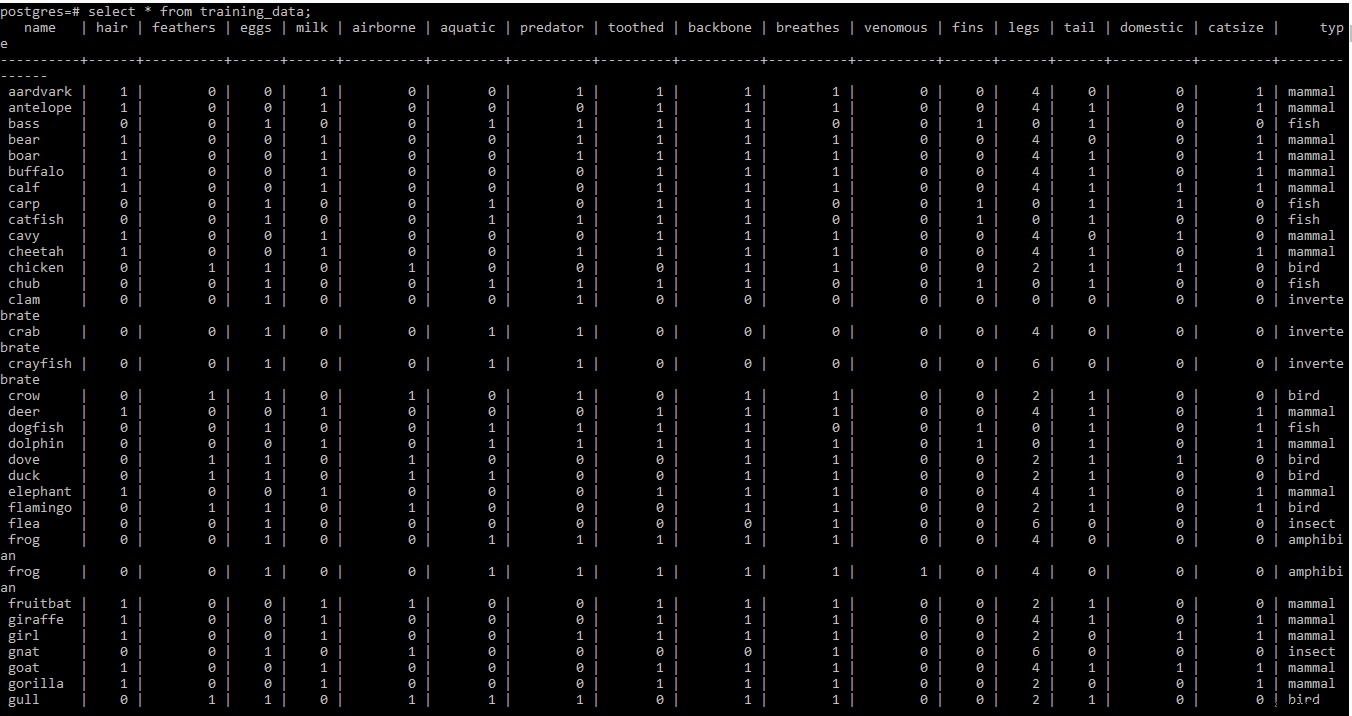
HINWEIS: Zeilen zwei und drei des Trainingsdatensatzes in der .tab Datei enthalten einige Metainformationen. Da es an dieser Stelle nicht benötigt wird, wurde es aus der Datei entfernt.
Schritt 2:Workflow mit Orange erstellen
- Gehen Sie zum Desktop und doppelklicken Sie auf das orange Symbol.
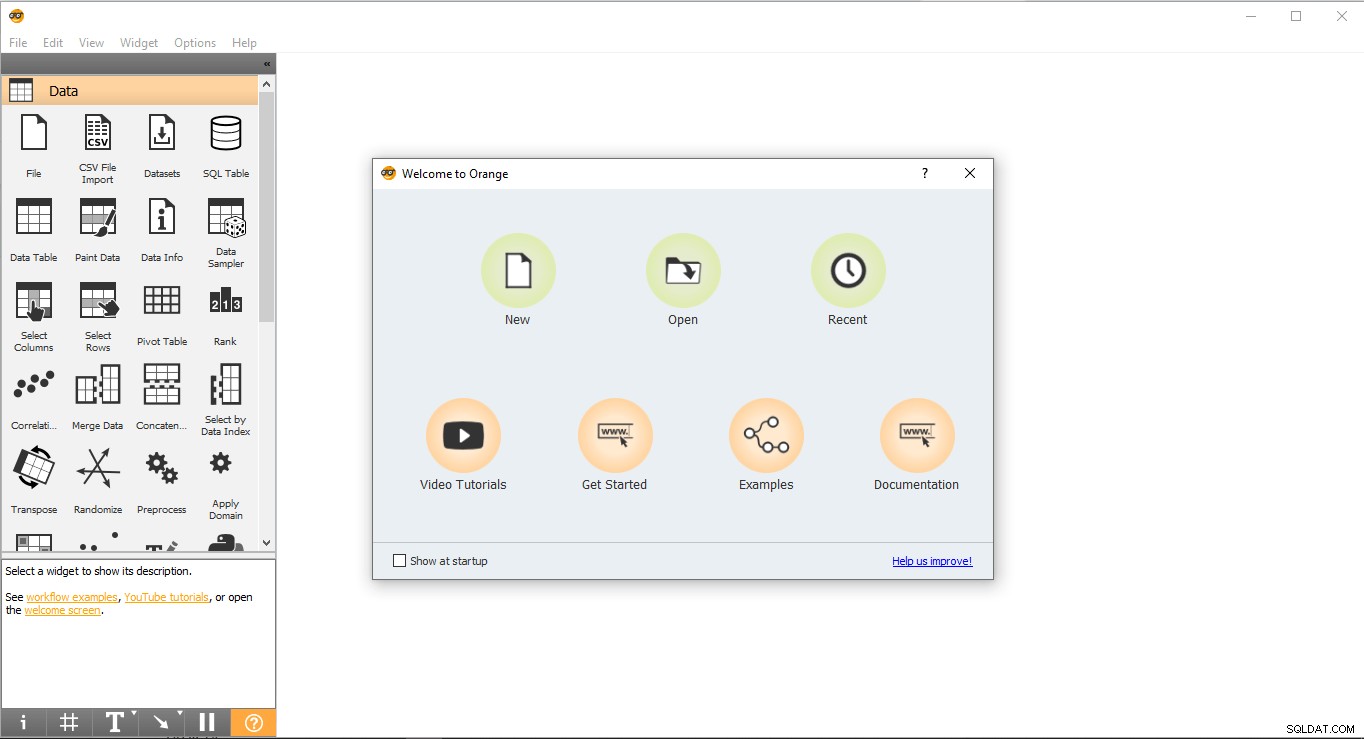
- So sieht die Startseite aus. Wählen Sie Neu aus Option und es wird ein leeres Projekt erstellt.

Jetzt können Sie das Machine Learning-Modell auf das Dataset anwenden.
Schritt 3:Modell für maschinelles Lernen auswählen, um die Daten zu trainieren
Für diesen Artikel k-am nächsten Nachbarn (KNN) Machine Learning-Modell wird verwendet, um die Daten zu trainieren. Sobald der Datentrainingsprozess abgeschlossen ist, werden im nächsten Schritt Testdaten an die Vorhersage übergeben Widget, um die Genauigkeit der Vorhersagen zu überprüfen.
Schritt 4:Trainingsdaten von PostgreSQL in Orange importieren
Dieses Trainings-Dataset wird zum Trainieren des Modells für maschinelles Lernen verwendet.
- Ziehen und Ablegen von SQL-Tabellen Widget aus den Daten Speisekarte.
- Widget umbenennen (optional)
- Klicken Sie mit der rechten Maustaste auf die SQL-Tabelle Widget.
- Wählen Sie Umbenennen .
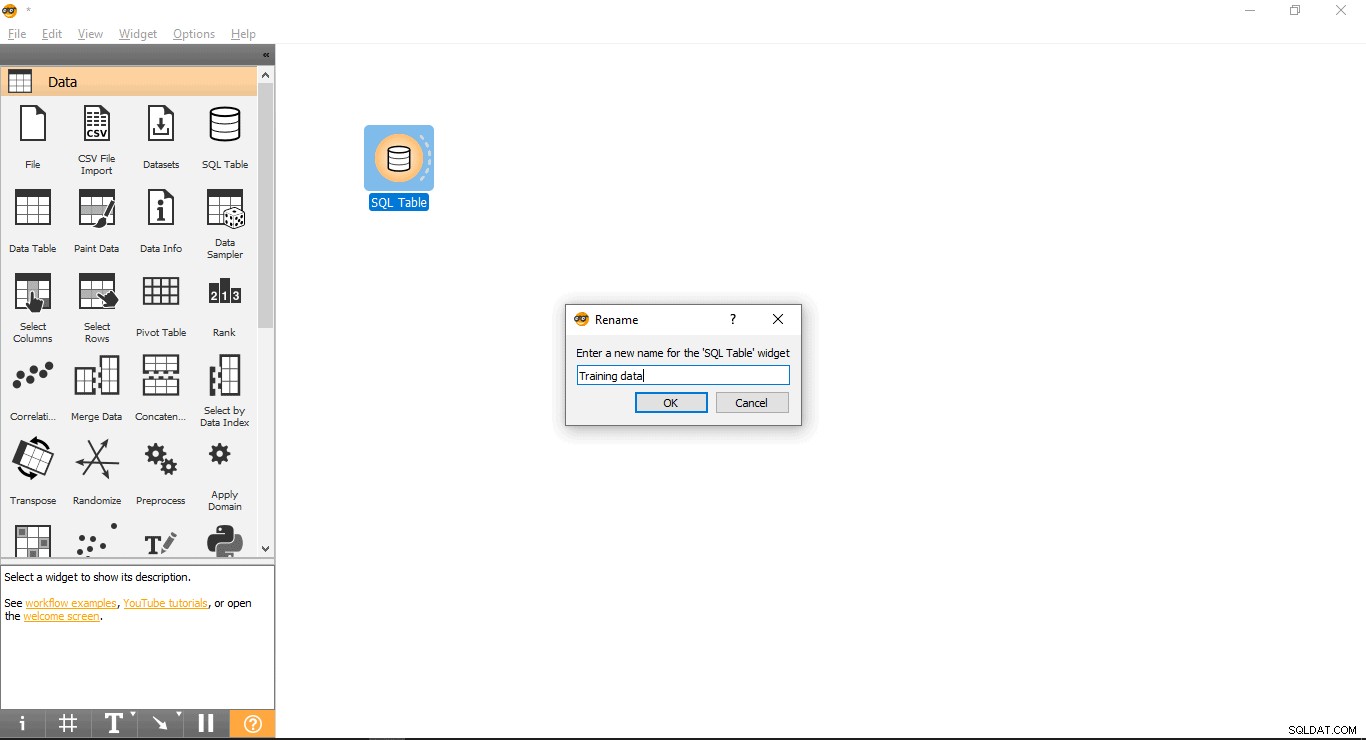
- Stellen Sie eine Verbindung mit PostgreSQL her, um den Trainingsdatensatz zu laden:
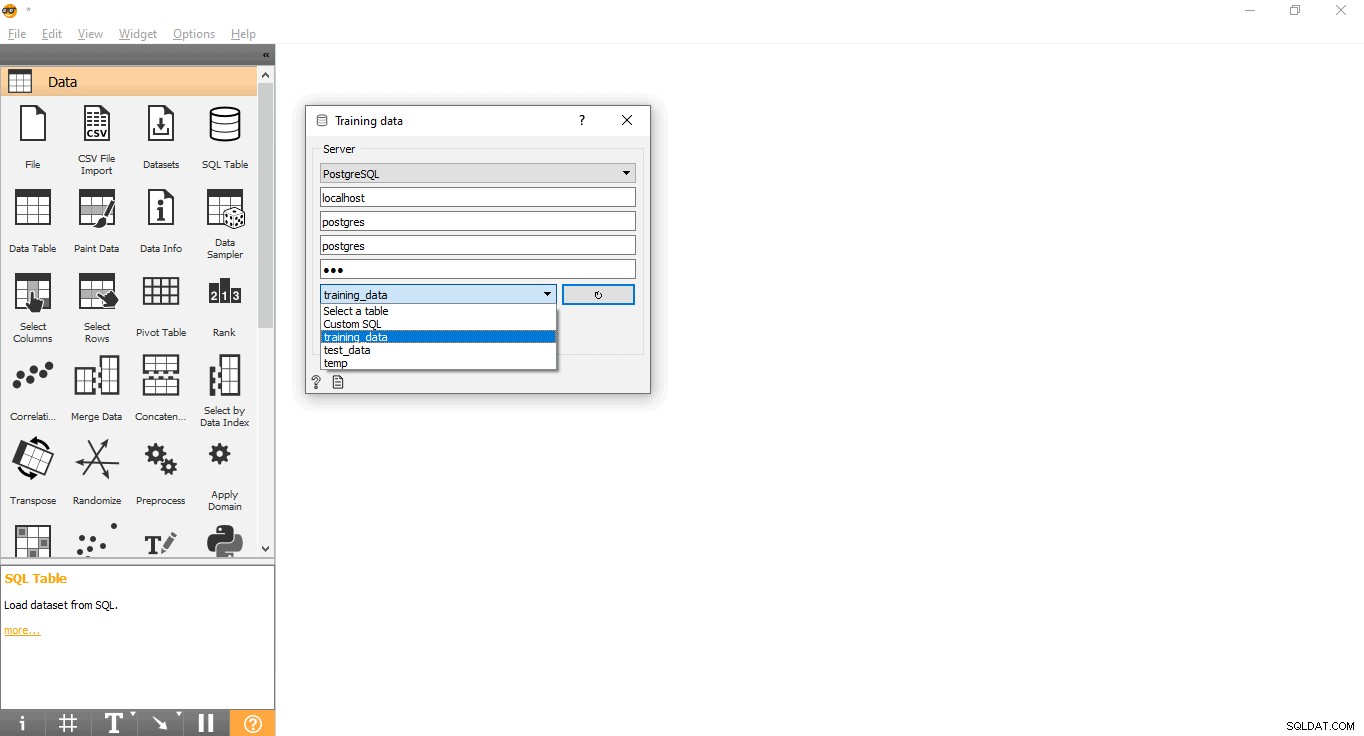
- Doppelklicken Sie auf die Trainingsdaten Widget.
- Geben Sie Anmeldeinformationen ein, um eine Verbindung zur PostgreSQL-Datenbank herzustellen.
- Klicken Sie auf die Schaltfläche Neu laden, um alle verfügbaren Tabellen aus der angegebenen Datenbank zu laden.
- Wählen Sie die Tabelle training_data aus dem Drop-down-Menü und schließen Sie das Pop-up.
Schritt 5:Zielspalte hinzufügen
Dieser Schritt ist wichtig, da das Machine Learning-Modell versuchen wird, die Daten für diese Zielvariable/Spalte vorherzusagen:
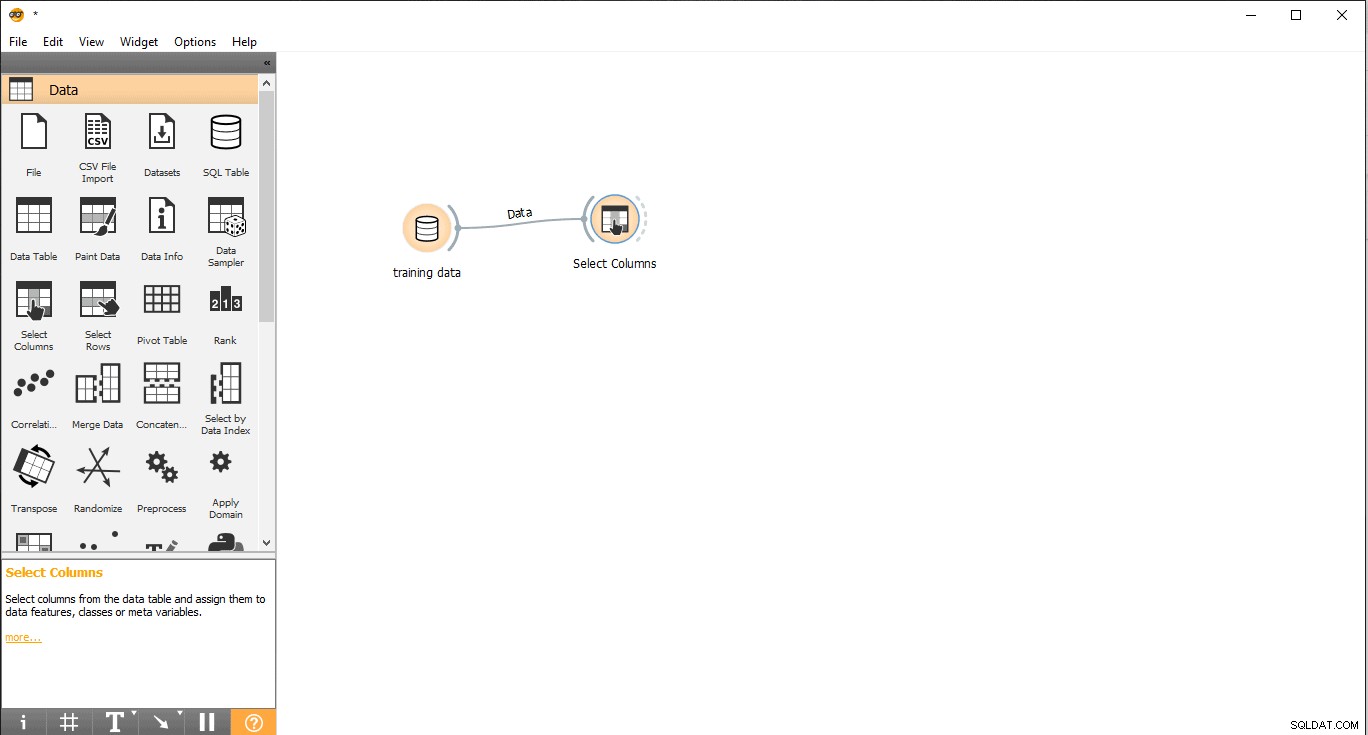
- Ziehen und legen Sie Spalten auswählen ab Widget aus den Daten Menü.
- Doppelklicken Sie auf Spalten auswählen Widget.
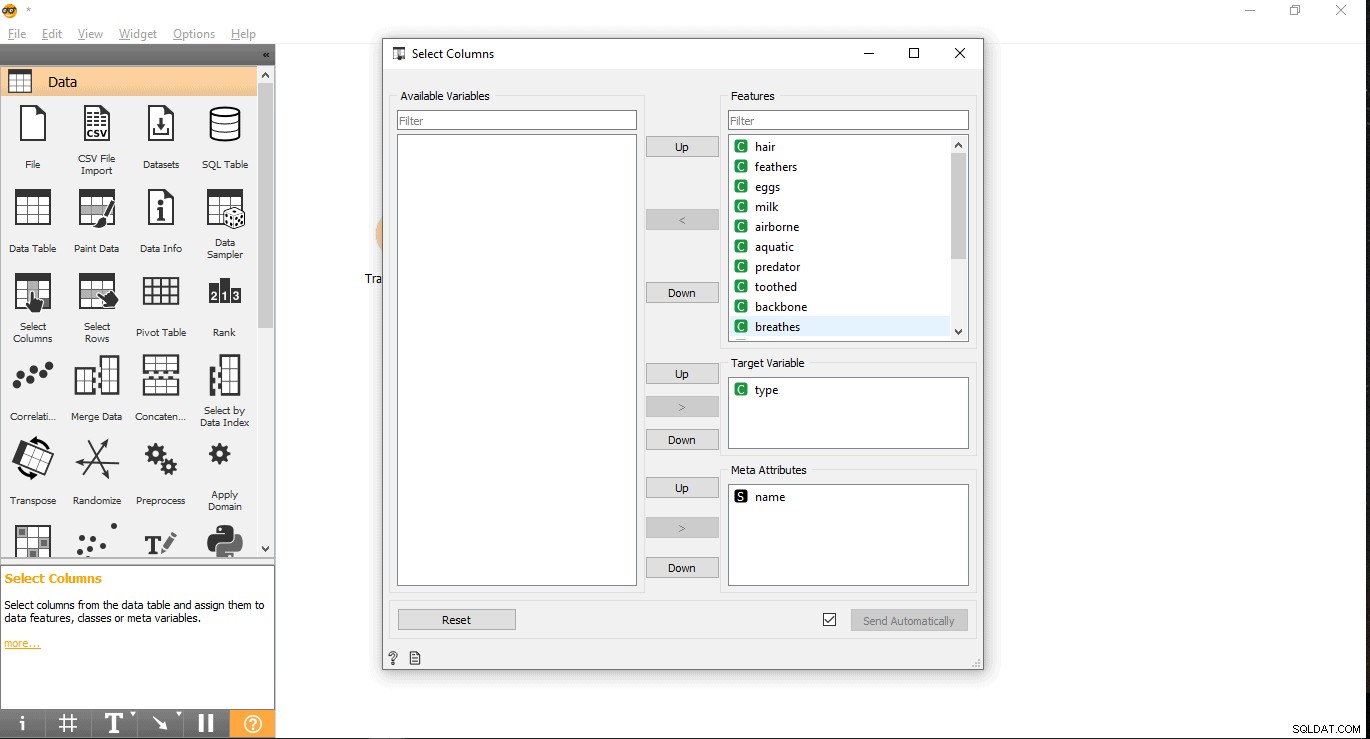
- Suchen Sie Ihre Zielspalte unter der Bezeichnung "Features". Hier wird Typ verwendet als Zielvariable, weil wir sehen müssen, welcher Art ein bestimmtes Tier ist.
- Ziehen Sie es unter Zielvariable und legen Sie es dort ab ein und schließen Sie das Pop-up.
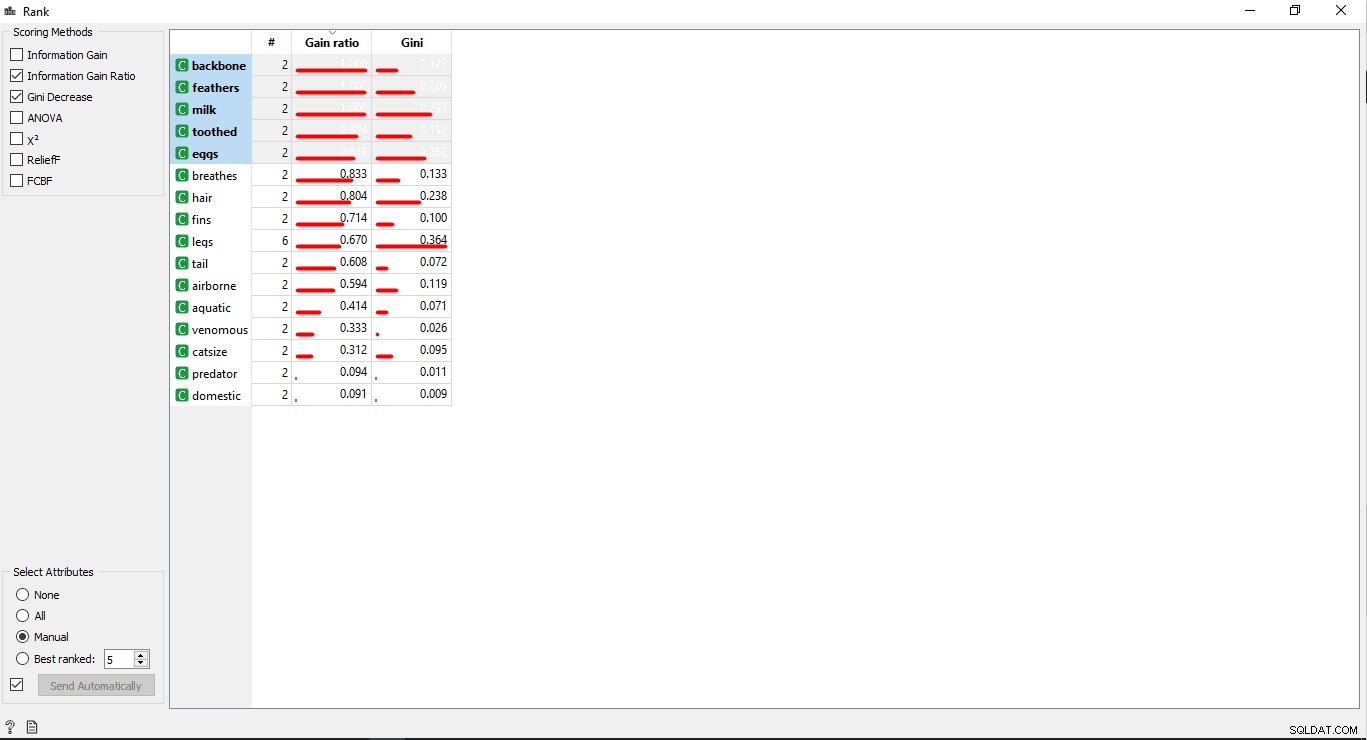
Schritt 6:Spaltenranking
Sie können die Trainingsvariablen/Spalten entsprechend ihrer Korrelation mit der Zielspalte ordnen oder bewerten.
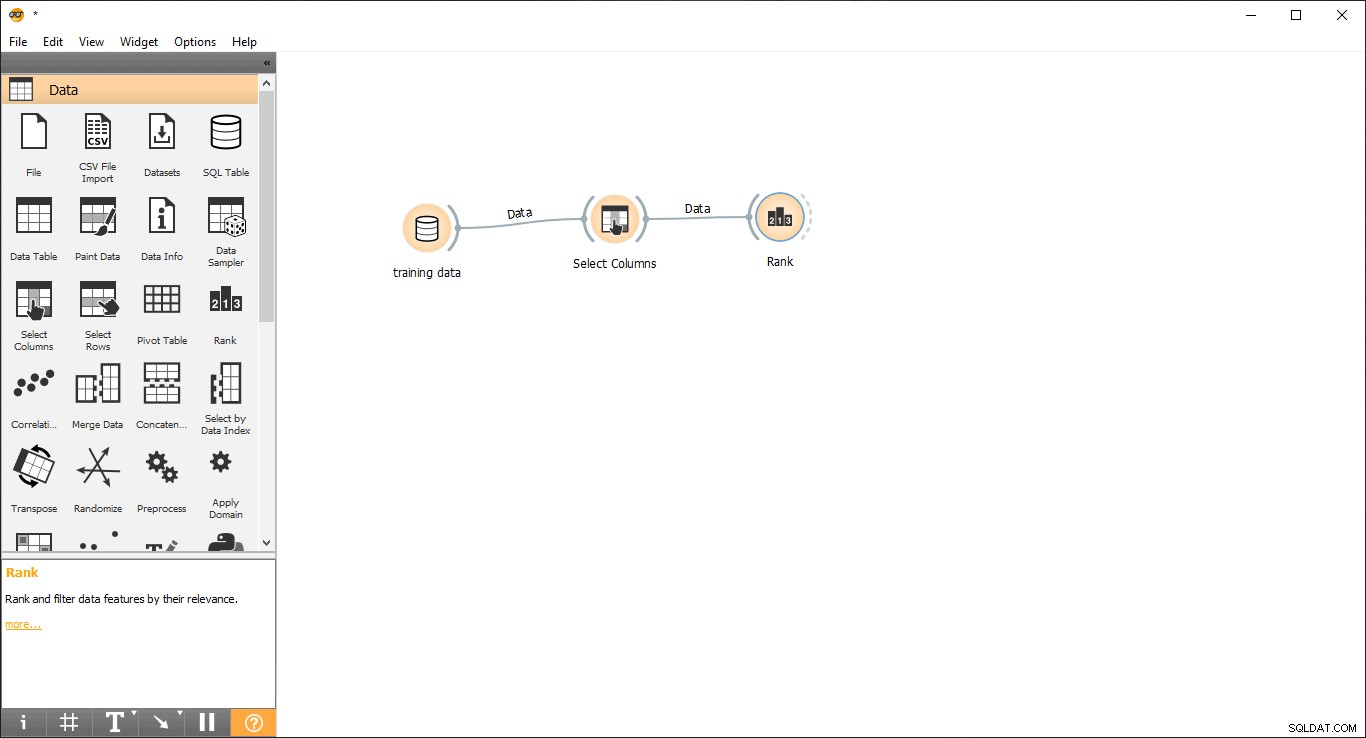
- Drag &Drop Rang Widget aus den Daten Menü.
- Zeichnen Sie eine Verbindungslinie von Spalten auswählen Widget zum Rang Widget .
- Doppelklicken Sie auf den Rang Widget, um die relevantesten Spalten in der Trainingsdatentabelle anzuzeigen. Standardmäßig werden die obersten 5 Spalten ausgewählt.
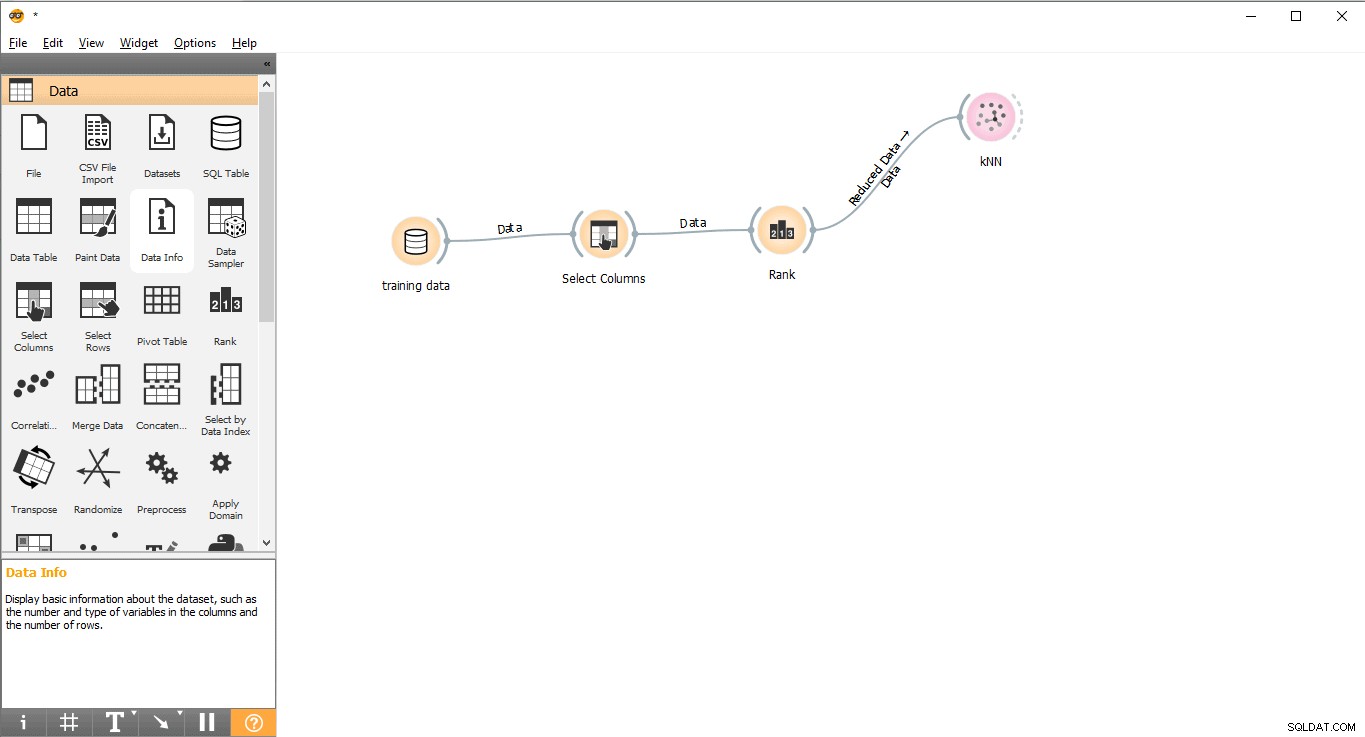
Schritt 7:Datentraining
In diesem Schritt wird das Machine Learning Model (KNN) mit dem Trainingsdatensatz trainiert. Bitte befolgen Sie die folgenden Schritte:
- Ziehen und legen Sie KNN ab Widget aus dem Modell Menü.
- Zeichnen Sie eine Verbindungslinie von Rang Widget an KNN Widget.
Schritt 8:Testdatensatz in PostgreSQL laden
Ein separates Testdataset wird erstellt, um Vorhersagen durchzuführen. Bitte befolgen Sie die Schritte zum Laden des Testdatensatzes in die PostgreSQL-Tabelle.
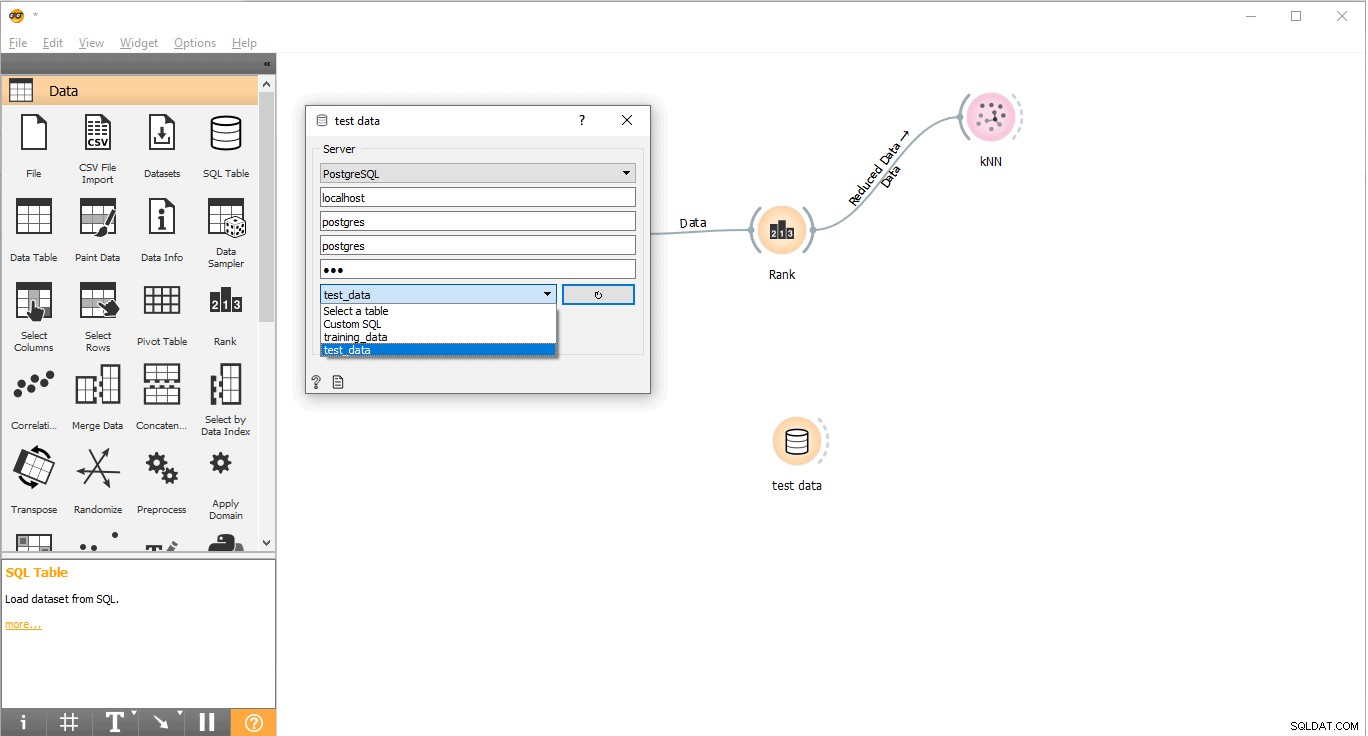
- Erstellen Sie eine Tabelle, um unsere Testdaten zu speichern . Hier heißt es test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Testdaten über KOPIEREN in die Testtabelle einfügen Anfrage. Vor dem Ausführen von COPY stellen Sie bitte sicher, dass PostgreSQL über die erforderlichen Leseberechtigungen für die Datendatei verfügt, andernfalls schlägt der COPY-Vorgang fehl.
HINWEIS: Bitte stellen Sie sicher, dass Sie einen Tabulator eingeben Leerzeichen zwischen einfachen Anführungszeichen nach dem Trennzeichen Stichwort. In den Typ wird absichtlich ein Fragezeichen gesetzt Spalte des Testdatensatzes, da wir mit unserem maschinellen Lernmodell die Art eines bestimmten Tieres herausfinden müssen.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Unten finden Sie den Screenshot des Testdatensatzes

Schritt 9:Testdaten von PostgreSQL in Orange importieren
Bitte befolgen Sie die folgenden Schritte, um die Vorhersagen zu übernehmen.
- Ziehen Sie SQL-Tabellen per Drag-and-Drop Widget aus den Daten Speisekarte.
- Widget umbenennen (optional)
- Klicken Sie mit der rechten Maustaste auf die SQL-Tabelle Widget.
- Wählen Sie Umbenennen .
- Verbinden Sie sich mit PostgreSQL, um Testdaten zu laden.
- Doppelklicken Sie auf Daten testen Widget.
- Verbinden Sie es mit Testdaten Tabelle aus PostgreSQL.
Jetzt können wir Vorhersagen treffen.
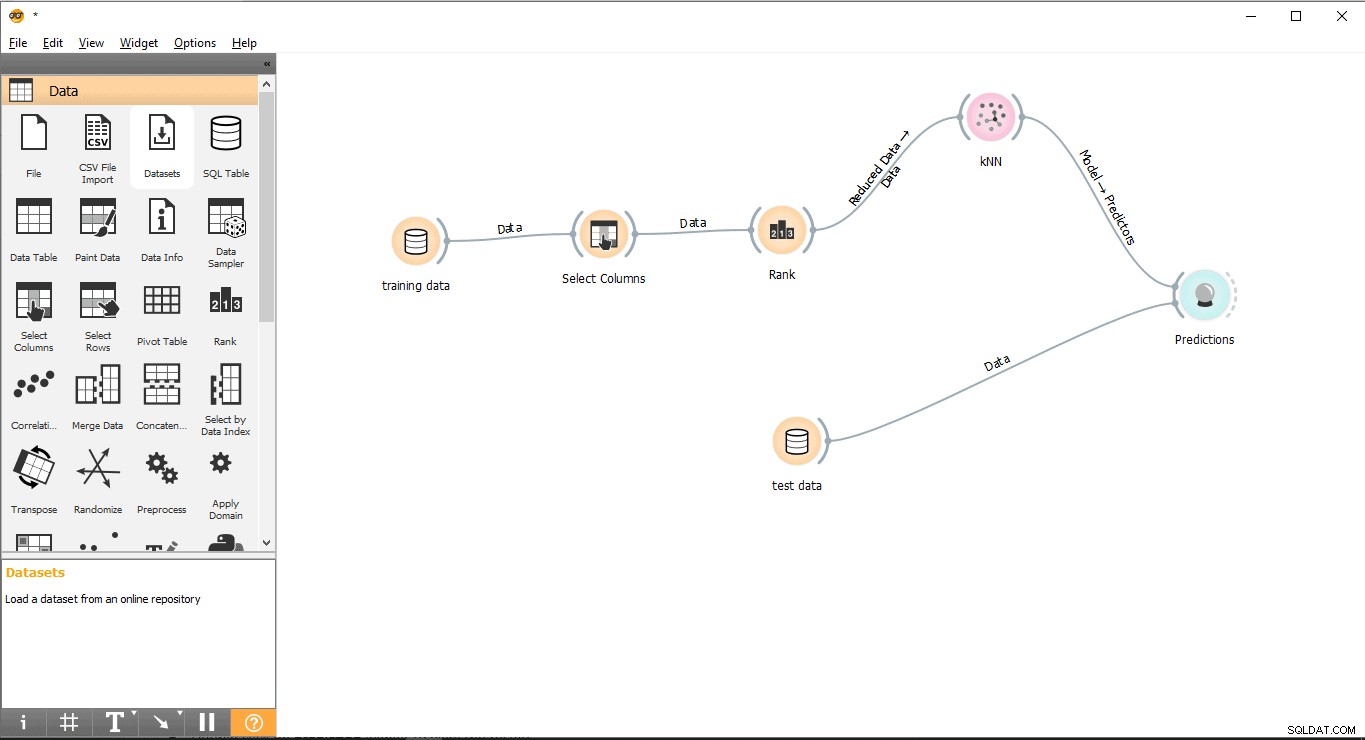
Schritt 10:Vorhersagen
Vorhersage Widget versucht, die Testdaten basierend auf den Trainingsdaten von KNN vorherzusagen .
- Drag-and-Drop Vorhersage Widget aus dem Auswerten Menü.
- Zeichnen Sie eine Verbindungslinie aus Testdaten Widget zu Vorhersage Widget.
- Zeichne eine Verbindungslinie von KNN Widget zu Vorhersage Widget.
Schritt 11:Ergebnisse
Doppelklicken Sie auf Vorhersage Widget, um die Ergebnisse anzuzeigen.
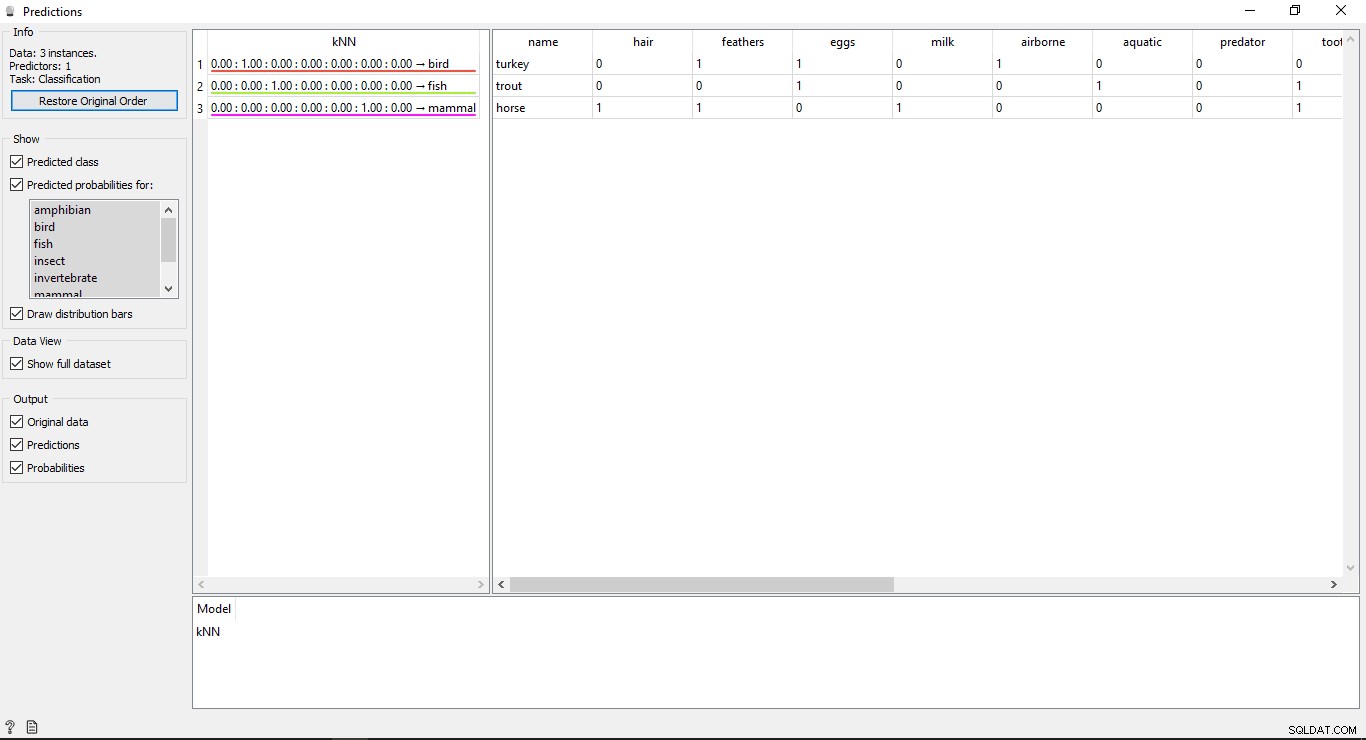
Ergebnisse verstehen
Sie sehen 2 Haupttabellen im Vorhersagefenster. Die Tabelle auf der linken Seite zeigt die vorhergesagten Ergebnisse, während die Tabelle auf der rechten Seite die ursprünglichen Testdaten zeigt, die für Vorhersagen bereitgestellt wurden.
Da die KNN -Modell wurde zum Trainieren von Daten verwendet, sodass Sie eine Spalte mit dem Namen KNN sehen das die Ergebnisse auflistet.
Wie wir wissen:
- Pferd ist ein Säugetier
- Forelle ist ein Fisch
- Türkei ist ein Vogel
Damit kann KNN alle Typen korrekt bestimmen.
Vorhersagegenauigkeit
Wenn Sie die Tabelle auf der linken Seite in der Ausgabe des Vorhersage-Widgets sehen, enthält sie einige Zahlen vor dem vorhergesagten Typ, z. B. 1,00. 0,00 Diese Zahlen zeigen die Genauigkeit des vorhergesagten Typs.
Wir haben 7 Tierarten im Trainingsdatensatz verwendet, daher zeigt es eine Gesamtzahl von 7 Spalten mit Genauigkeitswerten, wobei jede Spalte 1 Tierart darstellt. Sie können überprüfen, welche Spalte welche Art von Tier darstellt, indem Sie sich die Liste ansehen, die auf der linken Seite Ihres Bildschirms unter Vorhergesagte Wahrscheinlichkeiten für verfügbar ist Etikette. Wenn Sie sich die erste Zeile ansehen, in der Türkei steht ist ein Vogel . Wir können sehen, dass seine Genauigkeit 1,00 beträgt (100 % aus 2. Spalte). Dasselbe gilt für andere Beispiele Forelle ist ein Fisch und seine Genauigkeit beträgt 1,00 (100 % aus 3. Spalte).
In diesem Artikel haben wir den Algorithmus der k-nächsten Nachbarn (KNN) verwendet, um das Modell des maschinellen Lernens zu implementieren. Im nächsten Blog werden wir die Support Vector Machine verwenden (SVM)-Modell.
Bei Fragen oder Kommentaren wenden Sie sich bitte über das Kontaktformular hier an uns.



