Dies ist der zweite Teil einer zweiteiligen Serie über repmgr von 2ndQuadrant, ein Open-Source-Hochverfügbarkeitstool für PostgreSQL.
Im ersten Teil richten wir einen PostgreSQL 12-Cluster mit drei Knoten zusammen mit einem „Witness“-Knoten ein. Der Cluster bestand aus einem Primärknoten und zwei Standby-Knoten. Der Cluster und der Witness-Knoten wurden in einer Amazon Web Service Virtual Private Cloud (VPC) gehostet. Die EC2-Server, die die Postgres-Instanzen hosten, wurden in Subnetze in verschiedenen Verfügbarkeitszonen (AZ) platziert, wie unten gezeigt:
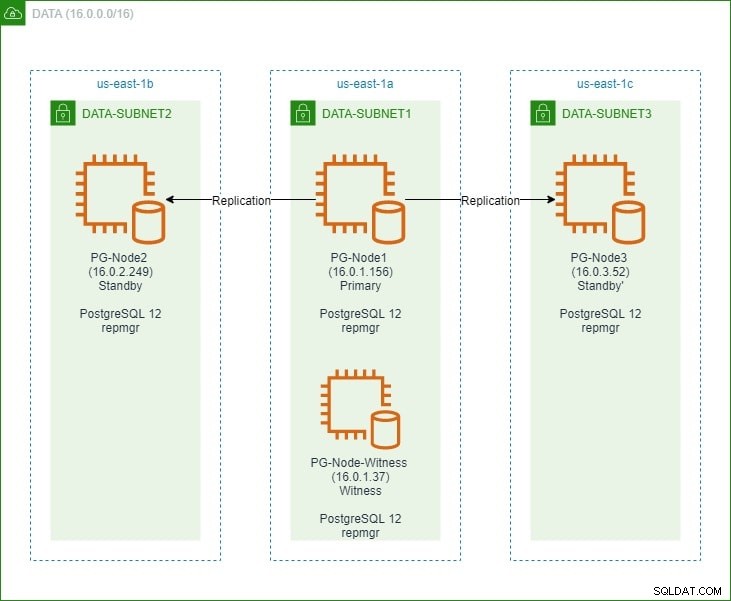
Wir werden ausführlich auf die Knotennamen und ihre IP-Adressen verweisen, daher hier noch einmal die Tabelle mit den Details der Knoten:
| Knotenname | IP-Adresse | Rolle | Apps laufen |
| PG-Knoten1 | 16.0.1.156 | Primär | PostgreSQL 12 und repmgr |
| PG-Knoten2 | 16.0.2.249 | Standby 1 | PostgreSQL 12 und repmgr |
| PG-Knoten3 | 16.0.3.52 | Standby 2 | PostgreSQL 12 und repmgr |
| PG-Node-Witness | 16.0.1.37 | Zeuge | PostgreSQL 12 und repmgr |
Wir haben repmgr auf den primären und Standby-Knoten installiert und dann den primären Knoten bei repmgr registriert. Wir haben dann beide Standby-Knoten vom Primärknoten geklont und gestartet. Beide Standby-Knoten wurden auch bei repmgr registriert. Der Befehl „repmgr cluster show“ zeigte uns, dass alles wie erwartet lief:

Aktuelles Problem
Das Einrichten der Streaming-Replikation mit repmgr ist sehr einfach. Als Nächstes müssen wir sicherstellen, dass der Cluster auch dann funktioniert, wenn der primäre Cluster nicht mehr verfügbar ist. Darauf werden wir in diesem Artikel eingehen.
Bei der PostgreSQL-Replikation kann ein primärer Server aus verschiedenen Gründen nicht mehr verfügbar sein. Zum Beispiel:
- Das Betriebssystem des primären Knotens kann abstürzen oder nicht mehr reagieren
- Der primäre Knoten kann seine Netzwerkverbindung verlieren
- Der PostgreSQL-Dienst im primären Knoten kann abstürzen, anhalten oder unerwartet nicht mehr verfügbar sein
- Der PostgreSQL-Dienst im primären Knoten kann absichtlich oder versehentlich gestoppt werden
Immer wenn ein primärer Server nicht verfügbar ist, gilt dies für einen Standby nicht sich automatisch in die Hauptrolle befördern. Ein Standby bedient weiterhin schreibgeschützte Abfragen – obwohl die Daten bis zur letzten LSN, die von der primären empfangen wurde, aktuell sind. Jeder Schreibversuch schlägt fehl.
Es gibt zwei Möglichkeiten, dies abzumildern:
- Der Standby-Modus erfolgt manuell auf eine primäre Rolle aufgewertet. Dies ist normalerweise bei einem geplanten Failover oder „Switchover“ der Fall
- Das Standby erfolgt automatisch in eine Hauptrolle befördert. Dies ist bei nicht nativen Tools der Fall, die die Replikation kontinuierlich überwachen und Wiederherstellungsmaßnahmen ergreifen, wenn die primäre nicht verfügbar ist. repmgr ist ein solches Tool.
Wir betrachten hier das zweite Szenario. Diese Situation bringt jedoch einige zusätzliche Herausforderungen mit sich:
- Wenn es mehr als einen Standby gibt, wie entscheidet das Tool (oder die Standbys), welches zum primären hochgestuft werden soll? Wie funktionieren das Quorum und der Beförderungsprozess?
- Wenn bei mehreren Standby-Knoten einer zum primären gemacht wird, wie beginnen dann die anderen Knoten, ihm als neuer primärer zu „folgen“?
- Was passiert, wenn die primäre funktioniert, aber aus irgendeinem Grund vorübergehend vom Netzwerk getrennt ist? Wenn einer der Standbys zum Primary befördert wird und der ursprüngliche Primary dann wieder online geht, wie kann eine „Split Brain“-Situation vermieden werden?
Antwort von remgr:Witness Node und der repmgr-Daemon
Um diese Fragen zu beantworten, verwendet repmgr einen sogenannten Zeugenknoten . Wenn der primäre Knoten nicht verfügbar ist, ist es die Aufgabe des Witness-Knotens, den Standbys dabei zu helfen, ein Quorum zu erreichen, wenn einer von ihnen zu einer primären Rolle befördert werden soll. Die Standbys erreichen dieses Quorum, indem sie feststellen, ob der primäre Knoten tatsächlich offline oder nur vorübergehend nicht verfügbar ist. Der Witness-Knoten sollte sich im selben Rechenzentrum/Netzwerksegment/Teilnetz wie der primäre Knoten befinden, darf jedoch NIEMALS auf demselben physischen Host wie der primäre Knoten ausgeführt werden.
Denken Sie daran, dass wir im ersten Teil dieser Serie einen Witness-Knoten in derselben Verfügbarkeitszone und demselben Subnetz wie den primären Knoten eingeführt haben. Wir haben es PG-Node-Witness genannt und dort eine PostgreSQL 12-Instanz installiert. In diesem Beitrag werden wir dort auch repmgr installieren, aber dazu später mehr.
Die zweite Komponente der Lösung ist der repmgr-Daemon (repmgrd) auf allen Knoten des Clusters und dem Zeugenknoten ausgeführt. Auch hier haben wir diesen Daemon nicht im ersten Teil dieser Serie gestartet, aber wir werden dies hier tun. Der Daemon ist Teil des repmgr-Pakets – wenn er aktiviert ist, wird er als regulärer Dienst ausgeführt und überwacht kontinuierlich den Zustand des Clusters. Es initiiert ein Failover, wenn ein Quorum erreicht wird, dass der primäre Server offline ist. Er kann nicht nur automatisch einen Standby heraufstufen, sondern auch andere Standbys in einem Multi-Node-Cluster erneut initiieren, um dem neuen Primärknoten zu folgen .
Der Quorum-Prozess
Wenn ein Standby erkennt, dass es den primären nicht sehen kann, konsultiert es andere Standbys. Alle Standbys, die im Cluster ausgeführt werden, erreichen ein Quorum, um mithilfe einer Reihe von Prüfungen einen neuen Primärserver auszuwählen:
- Jeder Standby fragt andere Standby nach der Zeit ab, zu der er den primären zuletzt „gesehen“ hat. Wenn die letzte replizierte LSN eines Standby oder der Zeitpunkt der letzten Kommunikation mit dem primären Knoten jünger ist als die letzte replizierte LSN des aktuellen Knotens oder der Zeitpunkt der letzten Kommunikation, unternimmt der Knoten nichts und wartet darauf, dass die Kommunikation mit dem primären Knoten wiederhergestellt wird
- Wenn keiner der Standby-Knoten den Primärknoten sehen kann, prüfen sie, ob der Witness-Knoten verfügbar ist. Wenn der Witness-Knoten ebenfalls nicht erreicht werden kann, gehen die Standbys davon aus, dass auf der Primärseite ein Netzwerkausfall vorliegt, und fahren nicht mit der Auswahl einer neuen Primärseite fort
- Wenn der Zeuge erreichbar ist, gehen die Standbys davon aus, dass die primäre ausgefallen ist, und wählen eine primäre aus
- Der Knoten, der als „bevorzugter“ Primärknoten konfiguriert wurde, wird dann heraufgestuft. Die Replikation jedes Standby-Servers wird neu initialisiert, um dem neuen Primärserver zu folgen.
Konfigurieren des Clusters für automatisches Failover
Wir werden jetzt den Cluster und den Witness-Knoten für automatisches Failover konfigurieren.
Schritt 1:Installieren und konfigurieren Sie repmgr in Witness
Wir haben bereits in unserem letzten Artikel gesehen, wie man das Paket repmgr installiert. Wir tun dies auch im Witness-Knoten:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Und dann:
# yum install repmgr12 -y
Als Nächstes fügen wir die folgenden Zeilen in die Datei postgresql.conf des Zeugenknotens ein:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
Wir fügen auch die folgenden Zeilen in der Datei pg_hba.conf im Witness-Knoten hinzu. Beachten Sie, wie wir den CIDR-Bereich des Clusters verwenden, anstatt einzelne IP-Adressen anzugeben.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trustpre> pre> pre> pre> pre> pre> pre> pre> prepmgr repmgr.
Hinweis
[Die hier beschriebenen Schritte dienen nur zu Demonstrationszwecken. Unser Beispiel hier verwendet extern erreichbare IPs für die Knoten. Die Verwendung von listen_address =„*“ zusammen mit dem Sicherheitsmechanismus „trust“ von pg_hba stellt daher ein Sicherheitsrisiko dar und sollte NICHT in Produktionsszenarien verwendet werden. In einem Produktionssystem befinden sich alle Knoten in einem oder mehreren privaten Subnetzen, die über private IPs von Jumphosts erreichbar sind.]
Nachdem die Änderungen an postgresql.conf und pg_hba.conf vorgenommen wurden, erstellen wir den repmgr-Benutzer und die repmgr-Datenbank im Zeugen und ändern den Standardsuchpfad des repmgr-Benutzers:
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Schließlich fügen wir die folgenden Zeilen zur Datei repmgr.conf hinzu, die sich unter /etc/repmgr/12/
befindetnode_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
Sobald die Konfigurationsparameter festgelegt sind, starten wir den PostgreSQL-Dienst im Witness-Knoten neu:
# systemctl restart postgresql-12.service
Um die Konnektivität zum Zeugenknoten repmgr zu testen, können wir diesen Befehl vom primären Knoten ausführen:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Als Nächstes registrieren wir den Witness-Knoten bei repmgr, indem wir den Befehl „repmgr Witness Register“ als postgres-Benutzer ausführen. Beachten Sie, wie wir die Adresse der primären verwenden Knoten und NICHT der Witness-Knoten im folgenden Befehl:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Dies liegt daran, dass der Befehl „repmgr Witness Register“ die Metadaten des Witness-Knotens zur repmgr-Datenbank des primären Knotens hinzufügt und bei Bedarf den Witness-Knoten initialisiert, indem die repmgr-Erweiterung installiert und die repmgr-Metadaten auf den Witness-Knoten kopiert werden.
Die Ausgabe sieht folgendermaßen aus:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Schließlich überprüfen wir den Status des gesamten Setups von jedem Knoten aus:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Die Ausgabe sieht so aus:

Schritt 2:Ändern der sudoers-Datei
Wenn der Cluster und der Zeuge ausgeführt werden, fügen wir die folgenden Zeilen in die sudoers-Datei in jedem Knoten des Clusters und des Zeugenknotens ein:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Schritt 3:Konfigurieren der repmgrd-Parameter
Wir haben bereits vier Parameter in der Datei repmgr.conf in jedem Knoten hinzugefügt. Die hinzugefügten Parameter sind die grundlegenden Parameter, die für den repmgr-Betrieb benötigt werden. Um den repmgr-Daemon und das automatische Failover zu aktivieren, müssen eine Reihe anderer Parameter aktiviert/hinzugefügt werden. In den folgenden Unterabschnitten beschreiben wir jeden Parameter und den Wert, auf den sie in jedem Knoten gesetzt werden.
Failover
Der Failover-Parameter ist einer der obligatorischen Parameter für den repmgr-Daemon. Dieser Parameter teilt dem Daemon mit, ob er ein automatisches Failover initiieren soll, wenn eine Failover-Situation erkannt wird. Es kann einen von zwei Werten haben:„manuell“ oder „automatisch“. Wir werden dies in jedem Knoten auf automatisch setzen:
failover='automatic'
promote_command
Dies ist ein weiterer obligatorischer Parameter für den repmgr-Daemon. Dieser Parameter teilt dem repmgr-Daemon mit, welchen Befehl er ausführen soll, um eine Standby-Instanz hochzustufen. Der Wert dieses Parameters ist normalerweise der Befehl „repmgr standby promote“ oder der Pfad zu einem Shell-Skript, das den Befehl aufruft. Für unseren Anwendungsfall setzen wir dies in jedem Knoten auf Folgendes:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
follow_command
Dies ist der dritte obligatorische Parameter für den repmgr-Daemon. Dieser Parameter weist einen Standby-Knoten an, dem neuen Primärknoten zu folgen. Der repmgr-Daemon ersetzt zur Laufzeit den Platzhalter %n durch die Knoten-ID des neuen Primärknotens:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
Priorität
Der Prioritätsparameter verleiht der Berechtigung eines Knotens, ein Primärknoten zu werden, Gewicht. Wenn Sie diesen Parameter auf einen höheren Wert setzen, ist ein Knoten besser geeignet, der primäre Knoten zu werden. Wenn Sie diesen Wert für einen Knoten auf Null setzen, wird außerdem sichergestellt, dass der Knoten niemals als primär hochgestuft wird.
In unserem Anwendungsfall haben wir zwei Standbys:PG-Node2 und PG-Node3. Wir möchten PG-Knoten2 als neuen Primärknoten heraufstufen, wenn PG-Knoten1 offline geht, und PG-Knoten3 soll PG-Knoten2 als seinen neuen Primärknoten folgen. Wir setzen den Parameter in den beiden Standby-Knoten auf die folgenden Werte:
| Knotenname | Parametereinstellung |
| PG-Knoten2 | Priorität =60 |
| PG-Knoten3 | Priorität =40 |
monitor_interval_secs
Dieser Parameter teilt dem repmgr-Daemon mit, wie oft (in Sekunden) er die Verfügbarkeit des Upstream-Knotens überprüfen soll. In unserem Fall gibt es nur einen Upstream-Knoten:den Primärknoten. Der Standardwert ist 2 Sekunden, aber wir werden dies trotzdem explizit in jedem Knoten setzen:
monitor_interval_secs=2
connection_check_type
Der Parameter connection_check_type bestimmt das Protokoll, das der repmgr-Daemon verwendet, um den Upstream-Knoten zu erreichen. Dieser Parameter kann drei Werte annehmen:
- Ping :repmgr verwendet die PQPing()-Methode
- Verbindung :repmgr versucht, eine neue Verbindung zum Upstream-Knoten herzustellen
- Abfrage :repmgr versucht, eine SQL-Abfrage auf dem Upstream-Knoten unter Verwendung der bestehenden Verbindung auszuführen
Auch hier setzen wir diesen Parameter in jedem Knoten auf den Standardwert von ping:
connection_check_type='ping'
reconnect_attempts und reconnect_interval
Wenn der Primärknoten nicht mehr verfügbar ist, versucht der repmgr-Daemon in den Standby-Knoten, die Verbindung zum Primärknoten für die Zeit von reconnect_attempts wiederherzustellen. Der Standardwert für diesen Parameter ist 6. Zwischen jedem Wiederverbindungsversuch wird auf reconnect_interval Sekunden gewartet, die einen Standardwert von 10 haben. Zu Demonstrationszwecken verwenden wir ein kurzes Intervall und weniger Wiederverbindungsversuche. Wir setzen diesen Parameter in jedem Knoten:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
Wenn der Primärknoten in einem Cluster mit mehreren Knoten nicht mehr verfügbar ist, können sich die Standbys gegenseitig konsultieren, um ein Quorum für ein Failover aufzubauen. Dies geschieht, indem jeder Standby nach der Zeit gefragt wird, zu der er den Primary zuletzt gesehen hat. Wenn die letzte Kommunikation eines Knotens vor kurzem und nach dem Zeitpunkt stattgefunden hat, zu dem der lokale Knoten den primären Knoten gesehen hat, geht der lokale Knoten davon aus, dass der primäre Knoten noch verfügbar ist, und trifft keine Failover-Entscheidung.
Um dieses Konsensmodell zu ermöglichen, muss der Parameter primary_visibility_consensus in jedem Knoten auf „true“ gesetzt werden – einschließlich des Zeugen:
primary_visibility_consensus=true
standby_disconnect_on_failover
Wenn der Parameter standby_disconnect_on_failover in einem Standby-Knoten auf „true“ gesetzt ist, stellt der repmgr-Daemon sicher, dass sein WAL-Empfänger vom primären Knoten getrennt ist und keine WAL-Segmente empfängt. Er wartet auch darauf, dass die WAL-Empfänger anderer Standby-Knoten anhalten, bevor er eine Failover-Entscheidung trifft. Dieser Parameter sollte in jedem Knoten auf denselben Wert gesetzt werden. Wir setzen dies auf „true“.
standby_disconnect_on_failover=true
Wenn Sie diesen Parameter auf „true“ setzen, bedeutet dies, dass jeder Standby-Knoten aufgehört hat, Daten vom primären Knoten zu empfangen, während das Failover stattfindet. Der Prozess hat eine Verzögerung von 5 Sekunden plus die Zeit, die der WAL-Empfänger benötigt, um zu stoppen, bevor eine Failover-Entscheidung getroffen wird. Standardmäßig wartet der repmgr-Daemon 30 Sekunden, um zu bestätigen, dass alle gleichgeordneten Knoten keine WAL-Segmente mehr empfangen, bevor das Failover stattfindet.
repmgrd_service_start_command und repmgrd_service_stop_command
Diese beiden Parameter geben an, wie der repmgr-Daemon mit den Befehlen „repmgr daemon start“ und „repmgr daemon stop“ gestartet und gestoppt wird.
Grundsätzlich sind diese beiden Befehle Wrapper um Betriebssystembefehle zum Starten/Stoppen des Dienstes. Die beiden Parameterwerte ordnen diese Befehle ihren betriebssystemspezifischen Versionen zu. Wir setzen diese Parameter in jedem Knoten auf die folgenden Werte:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
Befehle zum Starten/Stoppen/Neustarten des PostgreSQL-Dienstes
Als Teil seines Betriebs muss der repmgr-Daemon häufig den PostgreSQL-Dienst stoppen, starten oder neu starten. Damit dies reibungslos geschieht, geben Sie am besten die entsprechenden Betriebssystembefehle als Parameterwerte in der Datei repmgr.conf an. Zu diesem Zweck setzen wir in jedem Knoten vier Parameter:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
Überwachungsverlauf
Durch Festlegen des Parameters monitoring_history auf „yes“ wird sichergestellt, dass repmgr seine Cluster-Überwachungsdaten speichert. Wir setzen dies in jedem Knoten auf „yes“:
monitoring_history=yes
log_status_interval
Wir legen den Parameter in jedem Knoten fest, um anzugeben, wie oft der repmgr-Daemon eine Statusmeldung protokolliert. In diesem Fall setzen wir dies auf alle 60 Sekunden:
log_status_interval=60
Schritt 4:Den repmgr-Daemon starten
Mit den jetzt im Cluster und im Witness-Knoten festgelegten Parametern führen wir einen Probelauf des Befehls zum Starten des repmgr-Daemons aus. Wir testen dies zuerst im primären Knoten und dann in den beiden Standby-Knoten, gefolgt vom Witness-Knoten. Der Befehl muss als Postgres-Benutzer ausgeführt werden:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Die Ausgabe sollte so aussehen:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
Als nächstes starten wir den Daemon in allen vier Knoten:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Die Ausgabe in jedem Knoten sollte zeigen, dass der Daemon gestartet wurde:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
Wir können das Startereignis des Dienstes auch von den primären oder Standby-Knoten aus überprüfen:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
Die Ausgabe sollte zeigen, dass der Daemon die Verbindungen überwacht:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Schließlich können wir die Daemon-Ausgabe aus dem Syslog in jedem der Standbys überprüfen:
# cat /var/log/messages | grep repmgr | less
Hier ist die Ausgabe von PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Die Überprüfung des Syslog im primären Knoten zeigt eine andere Art von Ausgabe:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Schritt 5:Simulieren einer fehlgeschlagenen Grundschule
Jetzt simulieren wir einen ausgefallenen Primärknoten, indem wir den Primärknoten (PG-Node1) stoppen. An der Shell-Eingabeaufforderung des Knotens führen wir den folgenden Befehl aus:
# systemctl stop postgresql-12.service
Der Failover-Prozess
Sobald der Prozess beendet ist, warten wir etwa ein oder zwei Minuten und überprüfen dann die Syslog-Datei von PG-Node2. Die folgenden Meldungen werden angezeigt. Zur Verdeutlichung und Einfachheit haben wir Nachrichtengruppen farbcodiert und Leerzeichen zwischen den Zeilen hinzugefügt:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
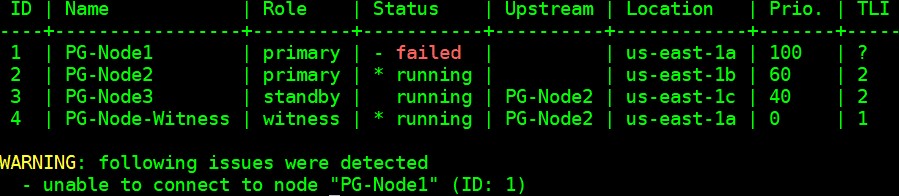
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Schlussfolgerung
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1