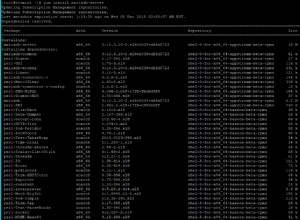
tl;dr Sie müssen einen Index für item_id hinzufügen . Die „schwarze Magie“ der Postgres-Indizierung wird in 11 behandelt. Indizes
.
Sie haben einen zusammengesetzten Index für (topic_id, item_id) und Spaltenreihenfolge ist wichtig. Postgres kann dies verwenden, um Abfragen zu topic_id zu indizieren , fragt sowohl nach topic_id und item_id , aber nicht (oder weniger effizient) item_id allein.
Von 11.3. Mehrspaltige Indizes ...
-- indexed
select *
from topics_items
where topic_id = ?
-- also indexed
select *
from topics_items
where topic_id = ?
and item_id = ?
-- probably not indexed
select *
from topics_items
where item_id = ?
Das liegt daran, dass ein zusammengesetzter Index wie (topic_id, item_id) speichert zuerst die Themen-ID, dann eine Element-ID, die ebenfalls diese Themen-ID hat. Um in diesem Index effizient nach einer Element-ID zu suchen, muss Postgres die Suche zunächst mit einer Themen-ID eingrenzen.
Postgres kann einen Index umkehren, wenn er der Meinung ist, dass sich der Aufwand lohnt. Wenn es eine kleine Anzahl möglicher Themen-IDs und eine große Anzahl möglicher Index-IDs gibt, wird in jeder Themen-ID nach der Index-ID gesucht.
Angenommen, Sie haben 10 mögliche Themen-IDs und 1000 mögliche Element-IDs und Ihren Index (topic_id, index_id) . Das ist so, als hätten Sie 10 klar gekennzeichnete Themen-ID-Buckets mit jeweils 1000 klar gekennzeichneten Element-ID-Buckets darin. Um zu den Element-ID-Buckets zu gelangen, muss in jedem Themen-ID-Bucket nachgesehen werden. Verwenden Sie diesen Index für where item_id = 23 Postgres muss jeden der 10 Themen-ID-Buckets nach allen Buckets mit der Element-ID 23 durchsuchen.
Aber wenn Sie 1000 mögliche Themen-IDs und 10 mögliche Element-IDs haben, müsste Postgres 1000 Themen-IDs-Buckets durchsuchen. Höchstwahrscheinlich wird stattdessen ein vollständiger Tabellenscan durchgeführt. In diesem Fall sollten Sie Ihren Index umkehren und ihn zu (item_id, topic_id) machen .
Dies hängt stark von guten Tabellenstatistiken ab, was bedeutet, dass die Selbstbereinigung ordnungsgemäß funktioniert.
Sie können also mit einem einzigen Index für zwei Spalten davonkommen, wenn eine Spalte weitaus weniger Variabilität aufweist als eine andere.
Postgres kann auch mehrere Indizes verwenden, wenn es glaubt, dass es die Abfrage zum Laufen bringt schneller
. Zum Beispiel, wenn Sie einen Index zu topic_id hatten und einen Index auf item_id , es kann Verwenden Sie beide Indizes und kombinieren Sie die Ergebnisse. Zum Beispiel where topic_id = 23 or item_id = 42 könnte den topic_id-Index verwenden, um nach der Themen-ID 23 zu suchen, und den item_id-Index, um nach der Element-ID 42 zu suchen, und dann die Ergebnisse kombinieren.
Dies ist im Allgemeinen langsamer als ein zusammengesetztes (topic_id, item_id) Index. Es kann auch langsamer sein als die Verwendung eines einzelnen Indexes, seien Sie also nicht überrascht, wenn Postgres beschließt, nicht mehrere Indizes zu verwenden.
Im Allgemeinen haben Sie bei B-Baum-Indizes drei mögliche Kombinationen, wenn Sie zwei Spalten haben.
- a + b
- ein
- b
Und Sie brauchen zwei Indizes.
- (a, b) -- a und a + b
- (b) -- b
(a, b) deckt beide Suchen nach a und a + b ab. (b) deckt die Suche nach b ab .
Wenn Sie drei Spalten haben, haben Sie sieben mögliche Kombinationen.
- a + b + c
- a + b
- a + c
- ein
- b + c
- b
- c
Aber Sie brauchen nur drei Indizes.
- (a, b, c) -- a, a + b, a + b + c
- (b, c) -- b, b + c
- (c, a) -- c, c + a
Wahrscheinlich möchten Sie jedoch vermeiden, einen Index für drei Spalten zu haben. Es ist oft langsamer . Was Sie eigentlich wollen, ist dies.
- (a, b)
- (b, c)
- (c, a)
Das Lesen aus einem Index ist langsamer als das Lesen aus der Tabelle. Sie möchten, dass Ihre Indizes die Anzahl der Zeilen reduzieren, die gelesen werden müssen, aber Sie möchten nicht, dass Postgres mehr Index-Scans durchführen muss als nötig.