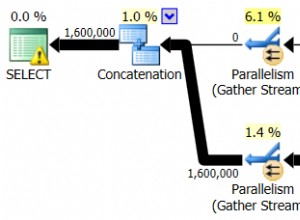
Frage 1 selbst beantworten:Es scheint, dass das Problem mehr mit Postgresql (oder eher Datenbanken im Allgemeinen) zu tun hatte. Unter Berücksichtigung der in diesem Artikel gemachten Punkte:https://use-the- index-luke.com/sql/dml/insert Folgendes habe ich gefunden:
1) Das Entfernen aller Indizes aus der Zieltabelle führte dazu, dass die Abfrage in 9 Sekunden ausgeführt wurde. Der Neuaufbau der Indizes (in postgresql) dauerte weitere 12 Sekunden, also immer noch weit unter den anderen Zeiten.
2) Wenn nur ein Primärschlüssel vorhanden ist, reduziert das Einfügen von Zeilen in der Reihenfolge der Primärschlüsselspalten die benötigte Zeit auf etwa ein Drittel. Dies ist sinnvoll, da nur wenig oder gar kein Mischen der Indexzeilen erforderlich sein sollte. Ich habe auch überprüft, dass dies der Grund ist, warum mein kartesischer Join in Postgresql überhaupt schneller war (dh die Zeilen wurden rein zufällig nach dem Index geordnet), indem ich dieselben Zeilen in eine temporäre Tabelle (ungeordnet) platzierte und daraus einfügte hat tatsächlich viel länger gedauert.
3) Ich habe ähnliche Experimente auf unseren MySQL-Systemen durchgeführt und beim Entfernen von Indizes die gleiche Erhöhung der Einfügegeschwindigkeit festgestellt. Bei mysql hingegen schien der Neuaufbau der verbrauchten Indizes Zeit zu gewinnen.
Ich hoffe, das hilft allen anderen, die bei einer Suche auf diese Frage stoßen.
Ich frage mich immer noch, ob es möglich ist, den Schritt zum Schreiben in CSV in Python (Q2 oben) zu entfernen, da ich glaube, dass ich dann etwas in Python schreiben könnte, das schneller als reines Postgresql wäre.
Danke Giles