Nicht möglich? Herausforderung angenommen. :)
WITH x(employee, department) AS (
VALUES
(1::int, 2::int)
,(3, 4)
,(5, 6)
-- ... more combinations
)
SELECT x.employee, x.department, count(i.employee) AS ct
FROM x
LEFT JOIN items i ON i.employee = x.employee
AND i.department = x.department
AND i.available
GROUP BY x.employee, x.department;
Dadurch erhalten Sie genau wonach du fragst. Wenn employee und department sind keine Ganzzahlen, werden in den passenden Typ umgewandelt.
Per Kommentar von @ypercube:count() muss sich in einer Nicht-Null-Spalte von items befinden , also erhalten wir 0 für nicht vorhandene Kriterien nicht 1 .
Ziehen Sie auch zusätzliche Kriterien in den LEFT JOIN Bedingung (i.available in diesem Fall), sodass Sie keine nicht vorhandenen Kriterien ausschließen.
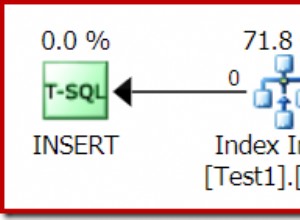
Leistung
Beantwortung zusätzlicher Fragen im Kommentar.
Dies sollte sehr gut funktionieren. Bei längeren Kriterienlisten (LEFT) JOIN ist wahrscheinlich die schnellste Methode.
Wenn Sie es so schnell wie möglich brauchen, stellen Sie sicher, dass Sie eine Multicolumn erstellen Index wie:
CREATE INDEX items_some_name_idx ON items (employee, department);
Wenn (employee, department) sollte der PRIMARY KEY sein oder Sie sollten einen UNIQUE haben Beschränkung auf die beiden Spalten, das würde auch funktionieren.