Da null =null wird zu false ausgewertet Sie müssen prüfen, ob zwei Felder beide null sind zusätzlich zur Gleichheitsprüfung:
UPDATE table_one SET table_one.x = table_two.y
FROM table_two
WHERE
(table_one.invoice_number = table_two.invoice_number
OR (table_one.invoice_number is null AND table_two.invoice_number is null))
AND
(table_one.submitted_by = table_two.submitted_by
OR (table_one.submitted_by is null AND table_two.submitted_by is null))
AND
-- etc
Sie können auch den Code
UPDATE table_one SET table_one.x = table_two.y
FROM table_two
WHERE
coalesce(table_one.invoice_number, '') = coalesce(table_two.invoice_number, '')
AND coalesce(table_one.submitted_by, '') = coalesce(table_two.submitted_by, '')
AND -- etc
Aber Sie müssen vorsichtig mit den Standardwerten sein (letztes Argument für coalesce ).
Der Datentyp sollte mit dem Spaltentyp übereinstimmen (damit Sie beispielsweise keine Daten mit Zahlen vergleichen) und der Standardwert sollte so sein, dass er nicht in den Daten erscheint
z coalesce(null, 1) =coalesce(1, 1) ist eine Situation, die Sie vermeiden möchten.
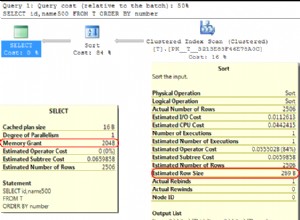
Update (in Bezug auf die Leistung):
Seq Scan auf table_two - Dies deutet darauf hin, dass Sie keine Indizes auf table_two haben .
Wenn Sie also eine Zeile in table_one aktualisieren dann um eine passende Zeile in table_two zu finden die Datenbank muss grundsätzlich alle Zeilen nacheinander durchsuchen, bis sie eine Übereinstimmung findet.
Die übereinstimmenden Zeilen könnten viel schneller gefunden werden, wenn die relevanten Spalten indiziert wären.
Auf der Rückseite, wenn table_one hat dann irgendwelche Indizes, die das Update verlangsamen.
Laut dieser Leistungsleitfaden
:
Ein weiterer Vorschlag aus demselben Leitfaden, der hilfreich sein könnte, ist:
Also zum Beispiel wenn table_one eine id Spalte könnten Sie so etwas hinzufügen wie
and table_one.id between x and y
zum wo Bedingung und führen Sie die Abfrage mehrmals aus, indem Sie die Werte von x ändern und y sodass alle Zeilen abgedeckt sind.
Sie sollten vorsichtig sein, wenn Sie ANALYZE verwenden Option mit EXPLAIN beim Umgang mit Anweisungen mit Nebeneffekten. Gemäß Dokumentation
: