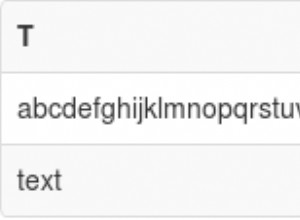
Spaltennamen sind Bezeichner, und die blutigen Details der Syntax für Bezeichner sind beschrieben unter:
https://www.postgresql .org/docs/current/static/sql-syntax-lexical.html#SQL-SYNTAX-IDENTIFIERS
TL;DR :Verwenden Sie das U&"..." Syntax, um nicht druckbare Zeichen über ihre Unicode-Codepunkte in Bezeichner einzufügen, und es gibt keine Möglichkeit, CR,LF zu vereinheitlichen mit LF allein.
So verweisen Sie auf die Spalte in einer einzelnen Zeile
Wir dürfen Unicode-Escape-Sequenzen in Bezeichnern verwenden, daher funktioniert Folgendes laut Dokumentation:
select U&"first\000asecond" from Two;
wenn es sich nur um ein Zeilenumbruchzeichen zwischen den beiden Wörtern handelt.
Was passiert mit den Abfragen in der ersten Tabelle
Die Tabelle wird erstellt mit:
CREATE TABLE One("first\nsecond" text);
Da der Backslash hier keine besondere Bedeutung hat, enthält diese Spalte keinen Zeilenumbruch. Sie enthält first gefolgt von \ gefolgt von n gefolgt von second .Also:
SELECT "first\nsecond" from One;
funktioniert, weil es dasselbe ist wie in CREATE TABLE
wohingegen
SELECT "first
second" from One;
schlägt fehl, weil es in diesem SELECT einen Zeilenumbruch gibt, wo der tatsächliche Spaltenname in der Tabelle einen umgekehrten Schrägstrich gefolgt von einem n hat .
Was passiert mit den Abfragen in der zweiten Tabelle
Das ist das Gegenteil von „Eins“.
CREATE TABLE Two("first
second" text);
Der Zeilenumbruch wird wörtlich übernommen und ist Teil der Spalte. Also
SELECT "first
second" from Two;
funktioniert, weil der Zeilenumbruch genau wie in der CREATE TABLE vorhanden ist, mit einem eingebetteten Zeilenumbruch, während
SELECT "first\nsecond" from Two;
schlägt fehl, weil wie zuvor \n bedeutet in diesem Zusammenhang keinen Zeilenumbruch.
Carriage Return gefolgt von Newline oder irgendetwas Seltsameren
Wie in den Kommentaren und Ihrer Bearbeitung erwähnt, könnte dies stattdessen Wagenrücklauf und Zeilenumbruch sein, in diesem Fall sollte Folgendes ausreichen:
select U&"first\000d\000asecond" from Two;
obwohl ich in meinem Test die Eingabetaste in der Mitte einer Spalte mit psql gedrückt habe unter Unix und Windows hat denselben Effekt:ein einzelner Zeilenumbruch im Namen der Spalte.
Um zu überprüfen, welche genauen Zeichen in einem Spaltennamen gelandet sind, können wir sie im Hexadezimalformat untersuchen.
Bei Anwendung auf Ihr Tabellenerstellungsbeispiel aus psql unter Unix:
CREATE TABLE Two("first
second" text);
select convert_to(column_name::text,'UTF-8')
from information_schema.columns
where table_schema='public'
and table_name='two';
Das Ergebnis ist:
convert_to
----------------------------
\x66697273740a7365636f6e64
Für komplexere Fälle (z. B. Nicht-ASCII-Zeichen mit mehreren Bytes in UTF-8) kann eine erweiterte Abfrage für leicht lesbare Codepunkte hilfreich sein:
select c,lpad(to_hex(ascii(c)),4,'0') from (
select regexp_split_to_table(column_name::text,'') as c
from information_schema.columns
where table_schema='public'
and table_name='two'
) as g;
c | lpad
---+------
f | 0066
i | 0069
r | 0072
s | 0073
t | 0074
+| 000a
|
s | 0073
e | 0065
c | 0063
o | 006f
n | 006e
d | 0064