Einführung
Unabhängig von der Datenbanktechnologie ist eine Überwachungseinrichtung erforderlich, um Probleme zu erkennen und Maßnahmen zu ergreifen oder einfach um den aktuellen Status unserer Systeme zu kennen.
Zu diesem Zweck gibt es mehrere Tools, kostenpflichtige und kostenlose. In diesem Blog werden wir uns besonders auf eines konzentrieren:Nagios Core.
Was ist Nagios Core?
Nagios Core ist ein Open-Source-System zur Überwachung von Hosts, Netzwerken und Diensten. Es ermöglicht die Konfiguration von Warnungen und hat verschiedene Zustände für sie. Es ermöglicht die Implementierung von Plugins, die von der Community entwickelt wurden, oder erlaubt uns sogar, unsere eigenen Überwachungsskripte zu konfigurieren.
Wie installiere ich Nagios?
Die offizielle Dokumentation zeigt uns, wie man Nagios Core auf CentOS- oder Ubuntu-Systemen installiert.
Sehen wir uns ein Beispiel der notwendigen Schritte für die Installation auf CentOS 7 an.
Pakete erforderlich
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipLaden Sie Nagios Core, Nagios Plugins und NRPE herunter
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzNagios-Benutzer und -Gruppe hinzufügen
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheNagios-Installation
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgNagios-Plugin und NRPE-Installation
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginWir fügen die folgende Zeile am Ende unserer Datei /usr/local/nagios/etc/objects/command.cfg hinzu, um NRPE beim Überprüfen unserer Server zu verwenden:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios startet
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdWebzugriff
Wir erstellen den Benutzer für den Zugriff auf die Webschnittstelle und können die Site betreten.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Adresse/nagios/
 Nagios Web Access
Nagios Web Access Wie konfiguriere ich Nagios?
Nachdem wir unser Nagios installiert haben, können wir mit der Konfiguration fortfahren. Dazu müssen wir an den Ort gehen, der unserer Installation entspricht, in unserem Beispiel /usr/local/nagios/etc.
Es gibt mehrere verschiedene Konfigurationsdateien, die Sie erstellen oder bearbeiten müssen, bevor Sie mit der Überwachung beginnen.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: Die CGI-Konfigurationsdatei enthält eine Reihe von Anweisungen, die den Betrieb der CGIs beeinflussen. Es enthält auch einen Verweis auf die Hauptkonfigurationsdatei, damit die CGIs wissen, wie Sie Nagios konfiguriert haben und wo Ihre Objektdefinitionen gespeichert sind.
- htpasswd.users: Diese Datei enthält die Benutzer, die für den Zugriff auf die Nagios-Weboberfläche erstellt wurden.
- nagios.cfg: Die Hauptkonfigurationsdatei enthält eine Reihe von Direktiven, die beeinflussen, wie der Nagios Core-Daemon arbeitet.
- Objekte: Wenn Sie Nagios installieren, werden hier mehrere Beispiel-Objektkonfigurationsdateien abgelegt. Anhand dieser Beispieldateien können Sie sehen, wie die Objektvererbung funktioniert, und lernen, wie Sie Ihre eigenen Objektdefinitionen definieren. Objekte sind alle Elemente, die an der Überwachungs- und Benachrichtigungslogik beteiligt sind.
- resource.cfg: Dies wird verwendet, um eine optionale Ressourcendatei anzugeben, die Makrodefinitionen enthalten kann. Mit Makros können Sie in Ihren Befehlen auf Informationen von Hosts, Diensten und anderen Quellen verweisen.
Innerhalb von Objekten finden wir Vorlagen, die beim Erstellen neuer Objekte verwendet werden können. Zum Beispiel können wir sehen, dass es in unserer Datei /usr/local/nagios/etc/objects/templates.cfg eine Vorlage namens linux-server gibt, die verwendet wird, um unsere Server hinzuzufügen.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Mit dieser Vorlage erben unsere Hosts die Konfiguration, ohne sie einzeln auf jedem hinzugefügten Server angeben zu müssen.
Wir haben auch vordefinierte Befehle, Kontakte und Zeiträume.
Die Befehle werden von Nagios für seine Prüfungen verwendet, und das fügen wir in die Konfigurationsdatei jedes Servers ein, um ihn zu überwachen. Beispiel:PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Wir haben die Möglichkeit, Kontakte oder Gruppen zu erstellen und festzulegen, welche Benachrichtigungen ich welche Person oder Gruppe erreichen möchte.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Für unsere Prüfungen und Benachrichtigungen können wir konfigurieren, zu welchen Stunden und an welchen Tagen wir sie erhalten möchten. Wenn wir einen Dienst haben, der nicht kritisch ist, möchten wir wahrscheinlich nicht im Morgengrauen aufwachen, daher wäre es gut, nur während der Arbeitszeit zu alarmieren, um dies zu vermeiden.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Sehen wir uns nun an, wie wir Warnungen zu unserem Nagios hinzufügen.
Wir werden unsere PostgreSQL-Server überwachen, also fügen wir sie zuerst als Hosts in unserem Objektverzeichnis hinzu. Wir werden 3 neue Dateien erstellen:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Dann müssen wir sie der Datei nagios.cfg hinzufügen und hier haben wir 2 Optionen.
Fügen Sie unsere Hosts (cfg-Dateien) nacheinander mit der cfg_file-Variablen (Standardoption) hinzu oder fügen Sie alle cfg-Dateien, die wir in einem Verzeichnis haben, mit der cfg_dir-Variablen hinzu.
Wir werden die Dateien nacheinander gemäß der Standardstrategie hinzufügen.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgDamit lassen wir unsere Hosts überwachen. Jetzt müssen wir nur noch hinzufügen, welche Dienste wir überwachen möchten. Dazu verwenden wir einige bereits definierte Prüfungen (check_ssh und check_ping) und fügen einige grundlegende Prüfungen des Betriebssystems wie unter anderem Auslastung und Speicherplatz mithilfe von NRPE hinzu.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterWas ist NRPE?
Nagios Remote Plugin Executor. Dieses Tool ermöglicht es uns, Nagios-Plug-ins so transparent wie möglich auf einem entfernten Host auszuführen.
Um es zu verwenden, müssen wir den Server in jedem Knoten installieren, den wir überwachen möchten, und unser Nagios verbindet sich als Client mit jedem von ihnen und führt die entsprechenden Plugins aus.
Wie installiere ich NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeDann editieren wir die Konfigurationsdatei /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>Und wir starten den NRPE-Dienst neu:
[example@sqldat.com ~]# systemctl restart nrpeWir können die Verbindung testen, indem wir Folgendes von unserem Nagios-Server ausführen:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Wie überwacht man PostgreSQL?
Bei der Überwachung von PostgreSQL müssen zwei Hauptbereiche berücksichtigt werden:Betriebssystem und Datenbanken.
Für das Betriebssystem hat NRPE einige grundlegende Prüfungen konfiguriert, wie unter anderem Speicherplatz und Auslastung. Diese Überprüfungen können auf folgende Weise sehr einfach aktiviert werden.
In unseren Knoten bearbeiten wir die Datei /usr/local/nagios/etc/nrpe.cfg und gehen zu den folgenden Zeilen:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200Die Namen in eckigen Klammern sind diejenigen, die wir in unserem Nagios-Server verwenden werden, um diese Prüfungen zu aktivieren.
In unserem Nagios bearbeiten wir die Dateien der 3 Knoten:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgWir fügen diese Überprüfungen hinzu, die wir zuvor gesehen haben, und belassen unsere Dateien wie folgt:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}Und wir starten den Nagios-Dienst neu:
[example@sqldat.com ~]# systemctl start nagiosWenn wir an dieser Stelle zum Abschnitt „Dienste“ in der Weboberfläche unseres Nagios gehen, sollten wir etwa Folgendes sehen:
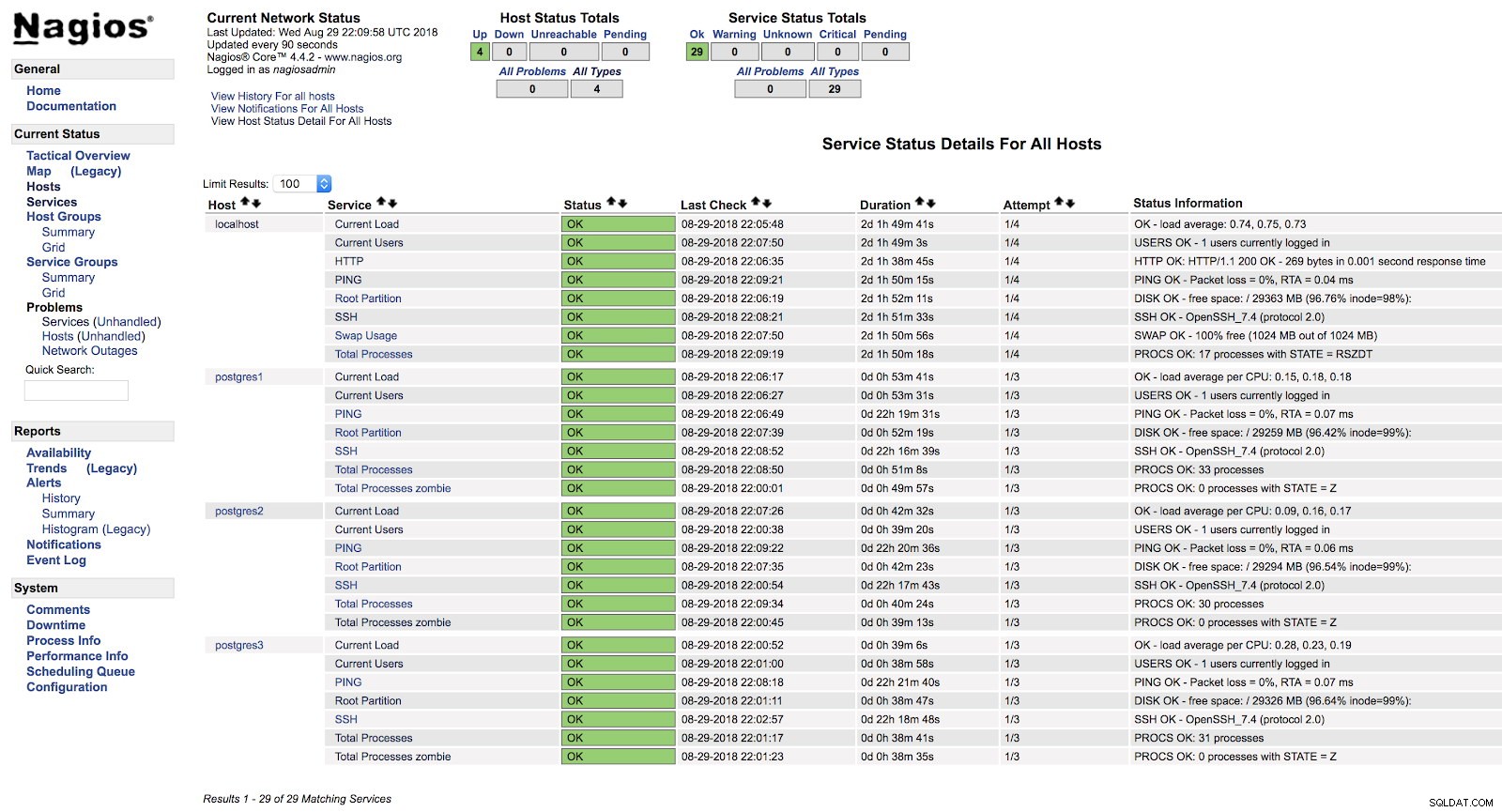 Nagios-Host-Warnungen
Nagios-Host-Warnungen Auf diese Weise decken wir die grundlegenden Überprüfungen unseres Servers auf Betriebssystemebene ab.
Wir haben viele weitere Prüfungen, die wir hinzufügen können, und wir können sogar unsere eigenen Prüfungen erstellen (ein Beispiel sehen wir später).
Lassen Sie uns nun sehen, wie Sie unsere PostgreSQL-Datenbank-Engine mit zwei der wichtigsten Plugins überwachen, die für diese Aufgabe entwickelt wurden.
Check_postgres
Eines der beliebtesten Plugins zum Überprüfen von PostgreSQL ist check_postgres von Bucardo.
Sehen wir uns an, wie man es installiert und wie man es mit unserer PostgreSQL-Datenbank verwendet.
Pakete erforderlich
[example@sqldat.com ~]# yum install perl-develInstallation
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksDieser letzte Befehl erstellt die Links, um alle Funktionen dieser Prüfung zu verwenden, wie unter anderem check_postgres_connection, check_postgres_last_vacuum oder check_postgres_replication_slots.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Wir fügen unserer NRPE-Konfigurationsdatei (/usr/local/nagios/etc/nrpe.cfg) die Zeile hinzu, um die Prüfung auszuführen, die wir verwenden möchten:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100In unserem Beispiel haben wir 4 grundlegende Prüfungen für PostgreSQL hinzugefügt. Wir werden Sperren, Bloat, Verbindungen und Backends überwachen.
In der Datei, die unserer Datenbank auf dem Nagios-Server entspricht (/usr/local/nagios/etc/objects/postgres1.cfg), fügen wir die folgenden Einträge hinzu:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}Und nach dem Neustart beider Dienste (NRPE und Nagios) auf beiden Servern können wir unsere konfigurierten Warnungen sehen.
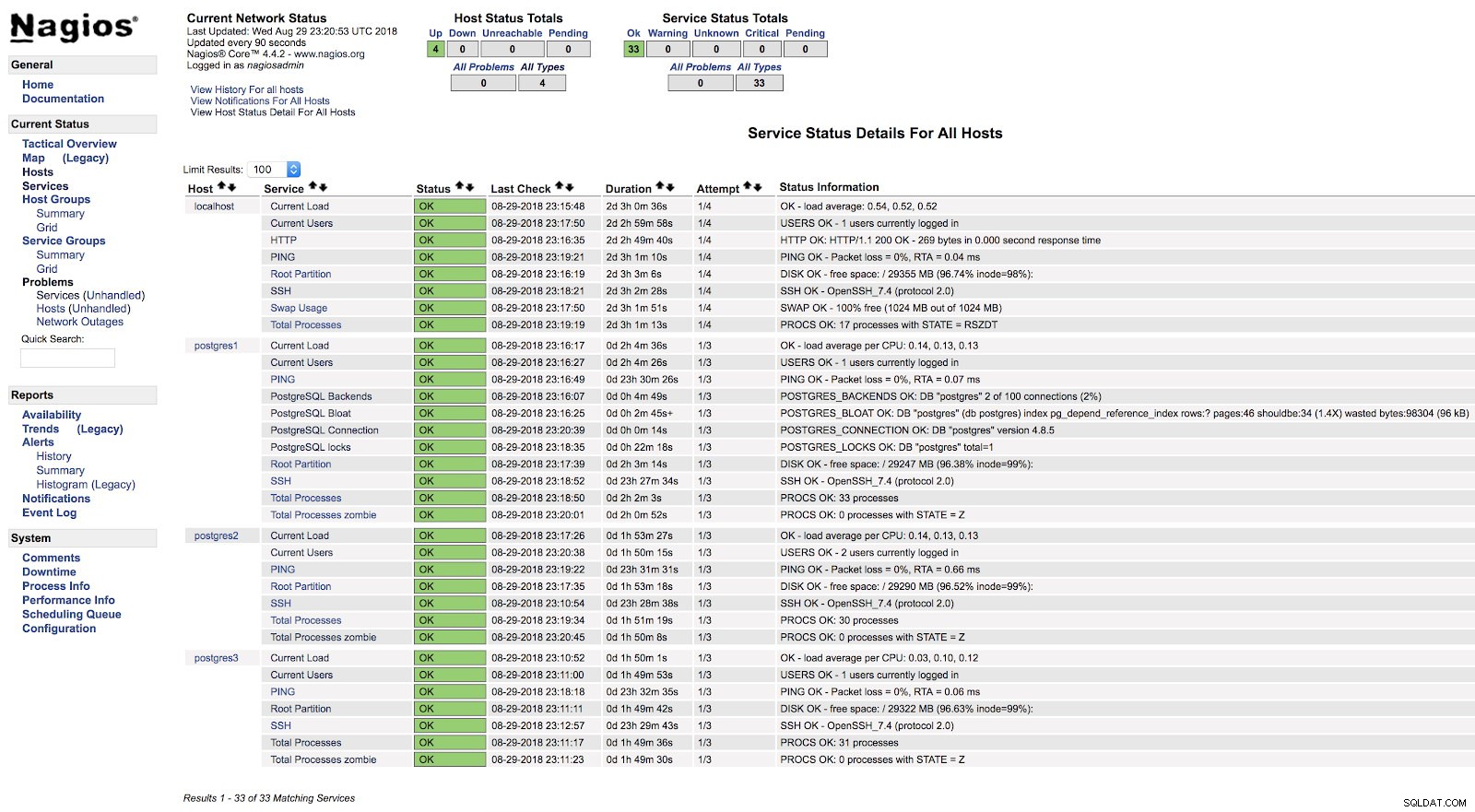 Nagios check_postgres-Warnungen
Nagios check_postgres-Warnungen In der offiziellen Dokumentation des check_postgres-Plug-Ins finden Sie Informationen darüber, was Sie sonst noch überwachen sollten und wie es geht.
Check_pgactivity
Jetzt ist check_pgactivity an der Reihe, das auch für die Überwachung unserer PostgreSQL-Datenbank beliebt ist.
Installation
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityWir fügen unserer NRPE-Konfigurationsdatei (/usr/local/nagios/etc/nrpe.cfg) die Zeile hinzu, um die Prüfung auszuführen, die wir verwenden möchten:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10In unserem Beispiel werden wir 4 grundlegende Prüfungen für PostgreSQL hinzufügen. Wir überwachen Backends, Verbindungen, ungültige Indizes und Sperren.
In der Datei, die unserer Datenbank auf dem Nagios-Server entspricht (/usr/local/nagios/etc/objects/postgres2.cfg), fügen wir die folgenden Einträge hinzu:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}Und nach dem Neustart beider Dienste (NRPE und Nagios) auf beiden Servern können wir unsere konfigurierten Warnungen sehen.
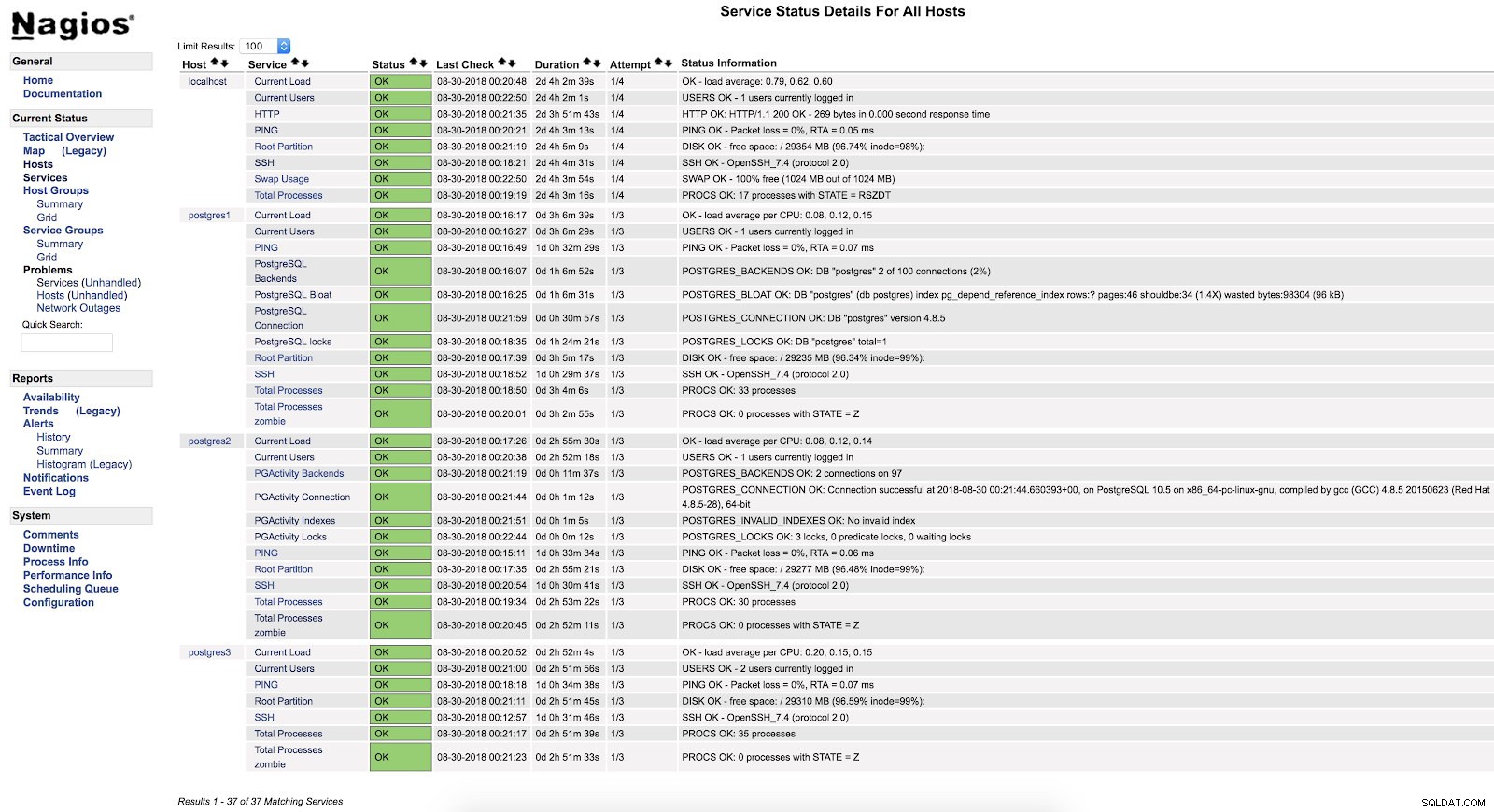 Nagios check_pgactivity Alerts
Nagios check_pgactivity Alerts Fehlerprotokoll prüfen
Eine der wichtigsten Überprüfungen, oder die allerwichtigste, ist die Überprüfung unseres Fehlerprotokolls.
Hier finden wir verschiedene Arten von Fehlern wie FATAL oder Deadlock, und es ist ein guter Ausgangspunkt, um jedes Problem zu analysieren, das wir in unserer Datenbank haben.
Um unser Fehlerprotokoll zu überprüfen, werden wir unser eigenes Überwachungsskript erstellen und es in unser Nagios integrieren (dies ist nur ein Beispiel, dieses Skript wird einfach sein und viel Raum für Verbesserungen haben).
Skript
Wir werden die Datei /usr/local/nagios/libexec/check_postgres_log.sh auf unserem PostgreSQL3-Server erstellen.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiDas Wichtigste an dem Skript ist, die jedem Zustand entsprechenden Ausgaben korrekt zu erstellen. Diese Ausgaben werden von Nagios gelesen und jede Zahl entspricht einem Zustand:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNIn unserem Beispiel verwenden wir nur 2 Zustände, OK und CRITICAL, da wir nur wissen möchten, ob es in der aktuellen Stunde Fehler des Typs FATAL in unserem Fehlerprotokoll gibt.
Der Text, den wir vor unserem Exit verwenden, wird von der Weboberfläche unseres Nagios angezeigt, daher sollte es so klar wie möglich sein, dies als Leitfaden für das Problem zu verwenden.
Sobald wir unser Überwachungsskript fertiggestellt haben, werden wir ihm Ausführungsberechtigungen erteilen, es dem Benutzer nagios zuweisen und es zu unserem Datenbankserver NRPE sowie zu unserem Nagios hinzufügen:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Starten Sie NRPE und Nagios neu. Dann können wir unseren Check in der Nagios-Oberfläche sehen:
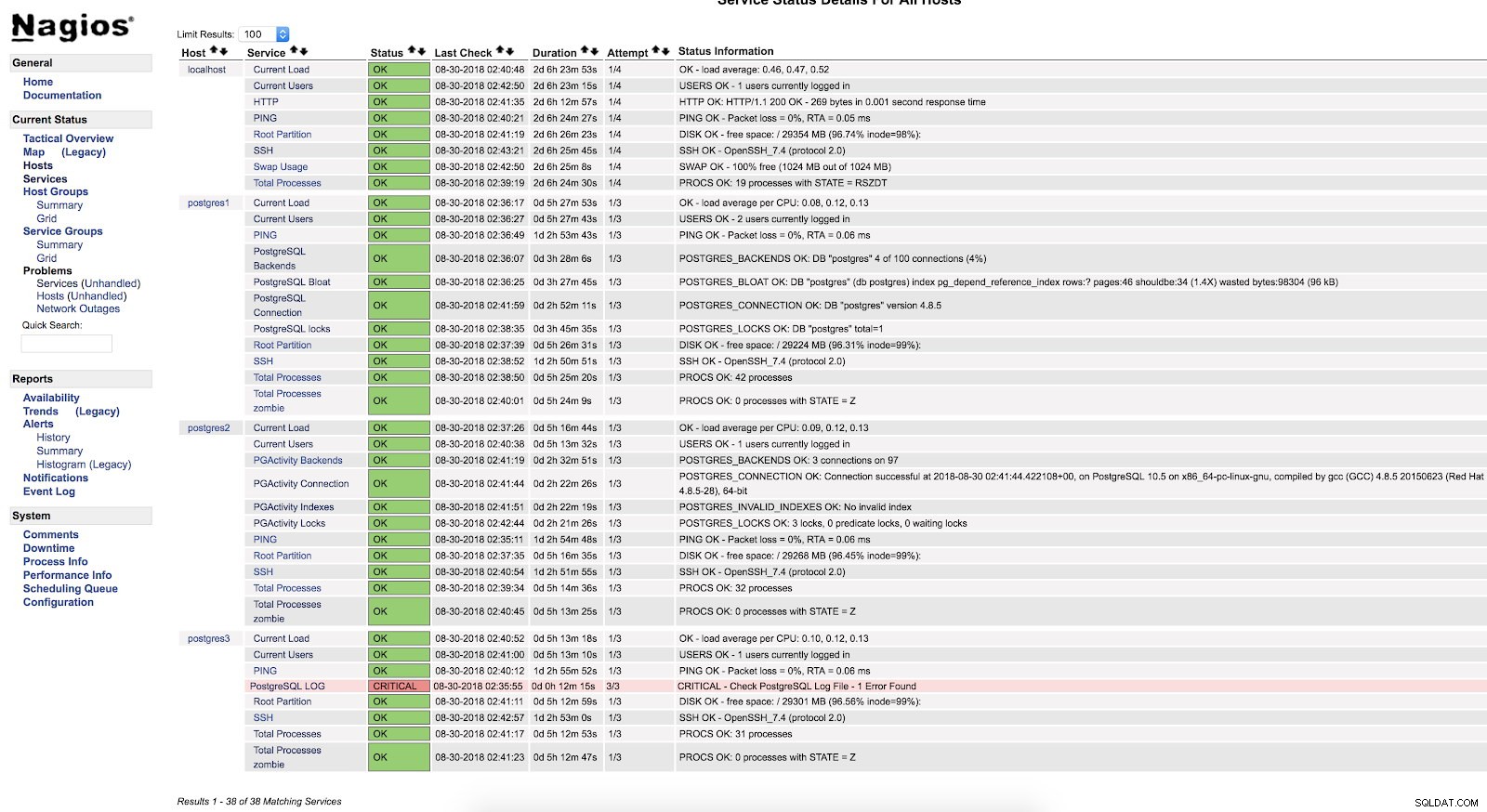 Nagios-Skriptwarnungen
Nagios-Skriptwarnungen Wie wir sehen können, befindet es sich in einem kritischen Zustand. Wenn wir also zum Protokoll gehen, können wir Folgendes sehen:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Für weitere Informationen darüber, was wir in unserer PostgreSQL-Datenbank überwachen können, empfehle ich Ihnen, unsere Leistungs- und Überwachungsblogs oder dieses Webinar zur Postgres-Leistung zu lesen.
Sicherheit und Leistung
Bei der Konfiguration einer Überwachung, entweder mit Plugins oder unserem eigenen Skript, müssen wir auf zwei sehr wichtige Dinge achten - Sicherheit und Leistung.
Wenn wir die erforderlichen Berechtigungen für die Überwachung zuweisen, müssen wir so restriktiv wie möglich vorgehen, den Zugriff nur lokal oder von unserem Überwachungsserver aus beschränken, sichere Schlüssel verwenden, den Datenverkehr verschlüsseln und die Verbindung auf das für die Überwachung erforderliche Minimum zulassen.
In Bezug auf die Leistung ist eine Überwachung erforderlich, aber es ist auch erforderlich, sie für unsere Systeme sicher zu verwenden.
Wir müssen darauf achten, keinen unangemessen hohen Festplattenzugriff zu generieren oder Abfragen auszuführen, die sich negativ auf die Leistung unserer Datenbank auswirken.
Wenn wir viele Transaktionen pro Sekunde haben, die Gigabyte an Protokollen generieren, und wir ständig nach Fehlern suchen, ist es wahrscheinlich nicht das Beste für unsere Datenbank. Daher müssen wir ein Gleichgewicht zwischen dem, was wir überwachen, wie oft und den Auswirkungen auf die Leistung halten.
Schlussfolgerung
Es gibt mehrere Möglichkeiten, die Überwachung zu implementieren oder zu konfigurieren. Wir können es so komplex oder so einfach machen, wie wir wollen. Das Ziel dieses Blogs war es, Sie in die Überwachung von PostgreSQL mit einem der am häufigsten verwendeten Open-Source-Tools einzuführen. Wir haben auch gesehen, dass die Konfiguration sehr flexibel ist und auf unterschiedliche Bedürfnisse zugeschnitten werden kann.
Und vergessen Sie nicht, dass wir uns immer auf die Community verlassen können, deshalb hinterlasse ich einige Links, die eine große Hilfe sein könnten.
Support-Forum:https://support.nagios.com/forum/
Bekannte Probleme:https://github.com/NagiosEnterprises/nagioscore/issues
Nagios-Plugins:https://exchange.nagios.org/directory/Plugins
Nagios-Plugin für ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol