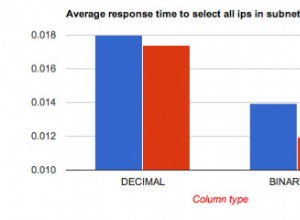
Wenn Ihr Fall so einfach ist, wie die Beispielwerte vermuten lassen, Antwort von @Giorgos dient gut.
Dies ist jedoch normalerweise nicht der Fall . Wenn die id Spalte ist eine serial , können Sie sich nicht darauf verlassen, dass eine Zeile mit einer früheren time hat auch eine kleinere id .
Außerdem time Werte (oder timestamp wie Sie wahrscheinlich haben) können leicht Duplikate sein, Sie müssen die Sortierreihenfolge eindeutig machen.
Angenommen, beides kann passieren, und Sie möchten die id ab der Zeile mit der frühesten time pro Zeitscheibe (eigentlich die kleinste id zum frühesten Zeitpunkt , es könnte Unentschieden geben), würde diese Abfrage die Situation richtig behandeln:
SELECT *
FROM (
SELECT DISTINCT ON (way, grp)
id, way, time AS time_from
, max(time) OVER (PARTITION BY way, grp) AS time_to
FROM (
SELECT *
, row_number() OVER (ORDER BY time, id) -- id as tie breaker
- row_number() OVER (PARTITION BY way ORDER BY time, id) AS grp
FROM table1
) t
ORDER BY way, grp, time, id
) sub
ORDER BY time_from, id;
-
ORDER BY time, ideindeutig sein. Angenommen, Zeit ist nicht unique, fügen Sie die (angenommene eindeutige)idhinzu um willkürliche Ergebnisse zu vermeiden - die sich zwischen Abfragen auf hinterhältige Weise ändern könnten. -
max(time) OVER (PARTITION BY way, grp):ohneORDER BY, der Fensterrahmen erstreckt sich über alle Zeilen der PARTITION, sodass wir das absolute Maximum pro Zeitscheibe erhalten. -
Die äußere Abfrageschicht ist nur notwendig, um die gewünschte Sortierreihenfolge im Ergebnis zu erzeugen, da wir an einen anderen
ORDER BYgebunden sind in der Unterabfragesubdurch Verwendung vonDISTINCT ON. Einzelheiten:
SQL-Fiddle Demonstrieren des Anwendungsfalls.
Wenn Sie die Leistung optimieren möchten, könnte eine plpgsql-Funktion in einem solchen Fall schneller sein. Eng verwandte Antwort:
Übrigens:Verwenden Sie nicht den grundlegenden Typnamen time als Bezeichner (auch ein reserviertes Wort in Standard-SQL ).