Teil 1 - Verknüpfungen und Vereinigungen
Diese Antwort umfasst:
- Teil 1
- Zwei oder mehr Tabellen mit einem Inner Join verbinden (Siehe den Wikipedia-Eintrag für weitere Informationen)
- So verwenden Sie eine Union-Abfrage
- Left and Right Outer Joins (diese stackOverflow-Antwort eignet sich hervorragend, um Arten von Joins zu beschreiben)
- Abfragen überschneiden (und wie man sie reproduziert, wenn Ihre Datenbank sie nicht unterstützt) - dies ist eine Funktion von SQL-Server (siehe info ) und Teil des Grund, warum ich das ganze geschrieben habe an erster Stelle.
- Teil 2
- Unterabfragen - was sie sind, wo sie eingesetzt werden können und worauf zu achten ist
- Cartesian schließt sich AKA an - Oh, das Elend!
Es gibt eine Reihe von Möglichkeiten, Daten aus mehreren Tabellen in einer Datenbank abzurufen. In dieser Antwort werde ich die ANSI-92-Join-Syntax verwenden. Dies kann sich von einer Reihe anderer Tutorials unterscheiden, die die ältere ANSI-89-Syntax verwenden (und wenn Sie an 89 gewöhnt sind, scheint dies viel weniger intuitiv zu sein - aber ich kann nur sagen, probieren Sie es aus), da es viel leichter verständlich, wenn die Abfragen komplexer werden. Warum verwenden? Gibt es einen Leistungsgewinn? Die kurze Antwort ist nein, aber es ist einfacher zu lesen, wenn man sich daran gewöhnt hat. Mit dieser Syntax ist es einfacher, Abfragen zu lesen, die von anderen Leuten geschrieben wurden.
Ich werde auch das Konzept eines kleinen Autohofs verwenden, der über eine Datenbank verfügt, um zu verfolgen, welche Autos verfügbar sind. Der Besitzer hat Sie als seinen IT-Computer-Mann eingestellt und erwartet, dass Sie ihm die Daten, die er verlangt, im Handumdrehen liefern können.
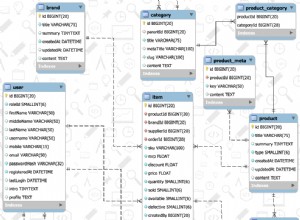
Ich habe eine Reihe von Nachschlagetabellen erstellt, die von der Abschlusstabelle verwendet werden. Dies gibt uns ein vernünftiges Modell, nach dem wir arbeiten können. Zu Beginn werde ich meine Abfragen gegen eine Beispieldatenbank ausführen, die die folgende Struktur hat. Ich werde versuchen, an häufige Fehler zu denken, die am Anfang gemacht werden, und erklären, was dabei schief geht – und natürlich zeigen, wie man sie korrigiert.
Die erste Tabelle ist einfach eine Farbliste, damit wir wissen, welche Farben wir auf dem Autohof haben.
mysql> create table colors(id int(3) not null auto_increment primary key,
-> color varchar(15), paint varchar(10));
Query OK, 0 rows affected (0.01 sec)
mysql> show columns from colors;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(3) | NO | PRI | NULL | auto_increment |
| color | varchar(15) | YES | | NULL | |
| paint | varchar(10) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
3 rows in set (0.01 sec)
mysql> insert into colors (color, paint) values ('Red', 'Metallic'),
-> ('Green', 'Gloss'), ('Blue', 'Metallic'),
-> ('White' 'Gloss'), ('Black' 'Gloss');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from colors;
+----+-------+----------+
| id | color | paint |
+----+-------+----------+
| 1 | Red | Metallic |
| 2 | Green | Gloss |
| 3 | Blue | Metallic |
| 4 | White | Gloss |
| 5 | Black | Gloss |
+----+-------+----------+
5 rows in set (0.00 sec)
Die Markentabelle identifiziert die verschiedenen Marken der Autos, die Caryard möglicherweise verkaufen könnte.
mysql> create table brands (id int(3) not null auto_increment primary key,
-> brand varchar(15));
Query OK, 0 rows affected (0.01 sec)
mysql> show columns from brands;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(3) | NO | PRI | NULL | auto_increment |
| brand | varchar(15) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.01 sec)
mysql> insert into brands (brand) values ('Ford'), ('Toyota'),
-> ('Nissan'), ('Smart'), ('BMW');
Query OK, 5 rows affected (0.00 sec)
Records: 5 Duplicates: 0 Warnings: 0
mysql> select * from brands;
+----+--------+
| id | brand |
+----+--------+
| 1 | Ford |
| 2 | Toyota |
| 3 | Nissan |
| 4 | Smart |
| 5 | BMW |
+----+--------+
5 rows in set (0.00 sec)
Die Modelltabelle wird verschiedene Autotypen abdecken, es wird einfacher sein, verschiedene Autotypen anstelle von tatsächlichen Automodellen zu verwenden.
mysql> create table models (id int(3) not null auto_increment primary key,
-> model varchar(15));
Query OK, 0 rows affected (0.01 sec)
mysql> show columns from models;
+-------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+----------------+
| id | int(3) | NO | PRI | NULL | auto_increment |
| model | varchar(15) | YES | | NULL | |
+-------+-------------+------+-----+---------+----------------+
2 rows in set (0.00 sec)
mysql> insert into models (model) values ('Sports'), ('Sedan'), ('4WD'), ('Luxury');
Query OK, 4 rows affected (0.00 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> select * from models;
+----+--------+
| id | model |
+----+--------+
| 1 | Sports |
| 2 | Sedan |
| 3 | 4WD |
| 4 | Luxury |
+----+--------+
4 rows in set (0.00 sec)
Und schließlich, um all diese anderen Tische zusammenzubinden, der Tisch, der alles zusammenhält. Das ID-Feld ist eigentlich die eindeutige Chargennummer, die zur Identifizierung von Autos verwendet wird.
mysql> create table cars (id int(3) not null auto_increment primary key,
-> color int(3), brand int(3), model int(3));
Query OK, 0 rows affected (0.01 sec)
mysql> show columns from cars;
+-------+--------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------+------+-----+---------+----------------+
| id | int(3) | NO | PRI | NULL | auto_increment |
| color | int(3) | YES | | NULL | |
| brand | int(3) | YES | | NULL | |
| model | int(3) | YES | | NULL | |
+-------+--------+------+-----+---------+----------------+
4 rows in set (0.00 sec)
mysql> insert into cars (color, brand, model) values (1,2,1), (3,1,2), (5,3,1),
-> (4,4,2), (2,2,3), (3,5,4), (4,1,3), (2,2,1), (5,2,3), (4,5,1);
Query OK, 10 rows affected (0.00 sec)
Records: 10 Duplicates: 0 Warnings: 0
mysql> select * from cars;
+----+-------+-------+-------+
| id | color | brand | model |
+----+-------+-------+-------+
| 1 | 1 | 2 | 1 |
| 2 | 3 | 1 | 2 |
| 3 | 5 | 3 | 1 |
| 4 | 4 | 4 | 2 |
| 5 | 2 | 2 | 3 |
| 6 | 3 | 5 | 4 |
| 7 | 4 | 1 | 3 |
| 8 | 2 | 2 | 1 |
| 9 | 5 | 2 | 3 |
| 10 | 4 | 5 | 1 |
+----+-------+-------+-------+
10 rows in set (0.00 sec)
Dies wird uns (hoffentlich) genügend Daten liefern, um die Beispiele unten für verschiedene Arten von Joins abzudecken, und auch genügend Daten liefern, damit sie sich lohnen.
Also, um ins Detail zu gehen, will der Chef Die IDs aller Sportwagen wissen, die er hat .
Dies ist ein einfacher Zwei-Tabellen-Join. Wir haben eine Tabelle, die das Modell und die Tabelle mit dem verfügbaren Bestand darin identifiziert. Wie Sie sehen können, sind die Daten im model Spalte der cars Tabelle bezieht sich auf die models Spalte der cars Tisch haben wir. Jetzt wissen wir, dass die Modelltabelle die ID 1 hat für Sports Schreiben wir also den Join.
select
ID,
model
from
cars
join models
on model=ID
Diese Abfrage sieht also gut aus, oder? Wir haben die beiden Tabellen identifiziert und enthalten die Informationen, die wir benötigen, und verwenden einen Join, der korrekt identifiziert, welche Spalten verknüpft werden sollen.
ERROR 1052 (23000): Column 'ID' in field list is ambiguous
Oh nein! Ein Fehler in unserer ersten Abfrage! Ja, und es ist eine Pflaume. Sie sehen, die Abfrage hat tatsächlich die richtigen Spalten, aber einige davon existieren in beiden Tabellen, sodass die Datenbank verwirrt darüber ist, welche tatsächliche Spalte wir meinen und wo. Es gibt zwei Lösungen, um dies zu lösen. Die erste ist nett und einfach, wir können tableName.columnName verwenden um der Datenbank genau mitzuteilen, was wir meinen, so:
select
cars.ID,
models.model
from
cars
join models
on cars.model=models.ID
+----+--------+
| ID | model |
+----+--------+
| 1 | Sports |
| 3 | Sports |
| 8 | Sports |
| 10 | Sports |
| 2 | Sedan |
| 4 | Sedan |
| 5 | 4WD |
| 7 | 4WD |
| 9 | 4WD |
| 6 | Luxury |
+----+--------+
10 rows in set (0.00 sec)
Die andere wird wahrscheinlich häufiger verwendet und heißt Tabellen-Aliasing. Die Tabellen in diesem Beispiel haben nette und kurze einfache Namen, aber etwas wie KPI_DAILY_SALES_BY_DEPARTMENT eingeben würde wahrscheinlich schnell alt werden, also ist es eine einfache Möglichkeit, die Tabelle wie folgt zu benennen:
select
a.ID,
b.model
from
cars a
join models b
on a.model=b.ID
Nun zurück zur Anfrage. Wie Sie sehen können, haben wir die Informationen, die wir brauchen, aber wir haben auch Informationen, nach denen nicht gefragt wurde, also müssen wir eine Where-Klausel in die Erklärung aufnehmen, um nur die Sportwagen zu bekommen, wie es verlangt wurde. Da ich die Tabellen-Alias-Methode bevorzuge, anstatt die Tabellennamen immer wieder zu verwenden, bleibe ich ab diesem Punkt dabei.
Natürlich müssen wir unserer Abfrage eine where-Klausel hinzufügen. Wir können Sportwagen entweder durch ID=1 identifizieren oder model='Sports' . Da die ID und der Primärschlüssel indiziert sind (und weniger Tipparbeit erforderlich sind), können wir dies in unserer Abfrage verwenden.
select
a.ID,
b.model
from
cars a
join models b
on a.model=b.ID
where
b.ID=1
+----+--------+
| ID | model |
+----+--------+
| 1 | Sports |
| 3 | Sports |
| 8 | Sports |
| 10 | Sports |
+----+--------+
4 rows in set (0.00 sec)
Bingo! Der Chef freut sich. Da er ein Chef ist und niemals mit dem zufrieden ist, was er verlangt, schaut er sich die Informationen an und sagt dann Ich möchte auch die Farben .
Okay, wir haben einen großen Teil unserer Abfrage bereits geschrieben, aber wir müssen eine dritte Tabelle verwenden, die Farben enthält. Nun unsere Hauptinformationstabelle cars speichert die Farb-ID des Autos und verknüpft diese mit der Farb-ID-Spalte. So können wir, ähnlich wie im Original, einen dritten Tisch beitreten:
select
a.ID,
b.model
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
where
b.ID=1
+----+--------+
| ID | model |
+----+--------+
| 1 | Sports |
| 3 | Sports |
| 8 | Sports |
| 10 | Sports |
+----+--------+
4 rows in set (0.00 sec)
Verdammt, obwohl die Tabelle korrekt verknüpft und die zugehörigen Spalten verknüpft waren, haben wir vergessen, die eigentlichen Informationen einzufügen aus der neuen Tabelle, die wir gerade verlinkt haben.
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
where
b.ID=1
+----+--------+-------+
| ID | model | color |
+----+--------+-------+
| 1 | Sports | Red |
| 8 | Sports | Green |
| 10 | Sports | White |
| 3 | Sports | Black |
+----+--------+-------+
4 rows in set (0.00 sec)
Richtig, das ist für einen Moment der Chef von unserem Rücken. Nun, um einige davon etwas ausführlicher zu erklären. Wie Sie sehen können, ist der from -Klausel in unserer Anweisung verknüpft unsere Haupttabelle (ich verwende oft eher eine Tabelle, die Informationen enthält, als eine Nachschlage- oder Dimensionstabelle. Die Abfrage würde genauso gut funktionieren, wenn die Tabellen alle vertauscht wären, aber weniger Sinn ergeben, wenn wir auf diese Abfrage zurückkommen um es in ein paar Monaten zu lesen, daher ist es oft am besten, zu versuchen, eine Abfrage zu schreiben, die schön und leicht verständlich ist - gestalten Sie sie intuitiv, verwenden Sie schöne Einzüge, damit alles so klar wie möglich ist Fahren Sie fort, andere zu unterrichten, und versuchen Sie, diese Merkmale in ihre Abfragen einzubringen – insbesondere, wenn Sie Fehler beheben werden.
Es ist durchaus möglich, immer mehr Tabellen auf diese Weise zu verknüpfen.
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
where
b.ID=1
Während ich vergessen habe, eine Tabelle einzufügen, in der wir mehr als eine Spalte in join verbinden möchten Erklärung, hier ist ein Beispiel. Wenn die models Tabelle hatte markenspezifische Modelle und hatte daher auch eine Spalte namens brand die auf die brands zurückverwiesen Tabelle auf der ID Feld, könnte dies wie folgt erfolgen:
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
and b.brand=d.ID
where
b.ID=1
Wie Sie sehen, verknüpft die obige Abfrage nicht nur die verknüpften Tabellen mit den wichtigsten cars Tabelle, sondern gibt auch Verknüpfungen zwischen den bereits verknüpften Tabellen an. Wenn dies nicht getan wurde, wird das Ergebnis als kartesischer Join bezeichnet - was dba für schlecht spricht. Bei einer kartesischen Verknüpfung werden Zeilen zurückgegeben, da die Informationen der Datenbank nicht mitteilen, wie die Ergebnisse begrenzt werden sollen, sodass die Abfrage all zurückgibt die Zeilen, die den Kriterien entsprechen.
Um also ein Beispiel für einen kartesischen Join zu geben, führen wir die folgende Abfrage aus:
select
a.ID,
b.model
from
cars a
join models b
+----+--------+
| ID | model |
+----+--------+
| 1 | Sports |
| 1 | Sedan |
| 1 | 4WD |
| 1 | Luxury |
| 2 | Sports |
| 2 | Sedan |
| 2 | 4WD |
| 2 | Luxury |
| 3 | Sports |
| 3 | Sedan |
| 3 | 4WD |
| 3 | Luxury |
| 4 | Sports |
| 4 | Sedan |
| 4 | 4WD |
| 4 | Luxury |
| 5 | Sports |
| 5 | Sedan |
| 5 | 4WD |
| 5 | Luxury |
| 6 | Sports |
| 6 | Sedan |
| 6 | 4WD |
| 6 | Luxury |
| 7 | Sports |
| 7 | Sedan |
| 7 | 4WD |
| 7 | Luxury |
| 8 | Sports |
| 8 | Sedan |
| 8 | 4WD |
| 8 | Luxury |
| 9 | Sports |
| 9 | Sedan |
| 9 | 4WD |
| 9 | Luxury |
| 10 | Sports |
| 10 | Sedan |
| 10 | 4WD |
| 10 | Luxury |
+----+--------+
40 rows in set (0.00 sec)
Guter Gott, das ist hässlich. Was die Datenbank betrifft, ist es jedoch genau wonach gefragt wurde. In der Abfrage haben wir nach der ID gefragt von cars und das model von models . Allerdings, weil wir wie nicht angegeben haben um die Tabellen zu verbinden, hat die Datenbank alle abgeglichen Zeile aus der ersten Tabelle mit every Zeile aus der zweiten Tabelle.
Okay, der Boss ist zurück und will wieder mehr Informationen. Ich möchte die gleiche Liste, aber auch Allradantriebe darin aufnehmen .
Dies gibt uns jedoch eine gute Entschuldigung dafür, zwei verschiedene Wege zu betrachten, um dies zu erreichen. Wir könnten der where-Klausel eine weitere Bedingung wie diese hinzufügen:
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
where
b.ID=1
or b.ID=3
Während das obige perfekt funktionieren wird, sehen wir es anders an, dies ist eine großartige Entschuldigung, um zu zeigen, wie eine union funktioniert Abfrage funktioniert.
Wir wissen, dass das Folgende alle Sportwagen zurückgeben wird:
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
where
b.ID=1
Und das Folgende würde alle 4WDs zurückgeben:
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
where
b.ID=3
Also durch Hinzufügen eines union all -Klausel dazwischen, werden die Ergebnisse der zweiten Abfrage an die Ergebnisse der ersten Abfrage angehängt.
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
where
b.ID=1
union all
select
a.ID,
b.model,
c.color
from
cars a
join models b
on a.model=b.ID
join colors c
on a.color=c.ID
join brands d
on a.brand=d.ID
where
b.ID=3
+----+--------+-------+
| ID | model | color |
+----+--------+-------+
| 1 | Sports | Red |
| 8 | Sports | Green |
| 10 | Sports | White |
| 3 | Sports | Black |
| 5 | 4WD | Green |
| 7 | 4WD | White |
| 9 | 4WD | Black |
+----+--------+-------+
7 rows in set (0.00 sec)
Wie Sie sehen können, werden die Ergebnisse der ersten Abfrage zuerst zurückgegeben, gefolgt von den Ergebnissen der zweiten Abfrage.
In diesem Beispiel wäre es natürlich viel einfacher gewesen, einfach die erste Abfrage zu verwenden, aber union Abfragen können für bestimmte Fälle großartig sein. Sie sind eine großartige Möglichkeit, bestimmte Ergebnisse aus Tabellen aus Tabellen zurückzugeben, die nicht einfach zusammengefügt werden können - oder übrigens vollständig unzusammenhängende Tabellen. Es gibt jedoch ein paar Regeln zu beachten.
- Die Spaltentypen aus der ersten Abfrage müssen mit den Spaltentypen aus jeder anderen Abfrage darunter übereinstimmen.
- Die Namen der Spalten aus der ersten Abfrage werden verwendet, um den gesamten Ergebnissatz zu identifizieren.
- Die Anzahl der Spalten in jeder Abfrage muss gleich sein.
Jetzt fragen Sie sich vielleicht was die
Der Unterschied besteht zwischen der Verwendung von union und union all . Eine union Abfrage wird Duplikate entfernen, während eine union all wird nicht. Dies bedeutet jedoch, dass es bei der Verwendung von union zu einem kleinen Leistungseinbruch kommt über union all aber die Ergebnisse könnten es wert sein - ich werde jedoch nicht über solche Dinge spekulieren.
In diesem Sinne könnte es sich lohnen, hier einige zusätzliche Anmerkungen zu machen.
- Wenn wir die Ergebnisse ordnen möchten, können wir einen
order byverwenden aber Sie können den Alias nicht mehr verwenden. Anhängen einerorder by a.IDin der Abfrage oben würde zu einem Fehler führen - was die Ergebnisse betrifft, heißt die SpalteIDstatta.ID- obwohl in beiden Abfragen derselbe Alias verwendet wurde. - Wir können nur eine
order byhaben -Anweisung, und es muss die letzte Anweisung sein.
Für die nächsten Beispiele füge ich unseren Tabellen ein paar zusätzliche Zeilen hinzu.
Ich habe Holden hinzugefügt zur Markentabelle hinzugefügt. Ich habe auch eine Zeile in cars hinzugefügt das hat die color Wert von 12 - die keine Referenz in der Farbtabelle hat.
Okay, der Chef ist wieder da und bellt Anfragen heraus - *Ich möchte eine Zählung jeder Marke, die wir führen, und der Anzahl der Autos darin!` - Typisch, wir kommen gerade zu einem interessanten Abschnitt unserer Diskussion und der Chef will mehr Arbeit .
Richtig, also müssen wir als Erstes eine vollständige Liste möglicher Marken erstellen.
select
a.brand
from
brands a
+--------+
| brand |
+--------+
| Ford |
| Toyota |
| Nissan |
| Smart |
| BMW |
| Holden |
+--------+
6 rows in set (0.00 sec)
Wenn wir dies nun mit unserer Autos-Tabelle verbinden, erhalten wir das folgende Ergebnis:
select
a.brand
from
brands a
join cars b
on a.ID=b.brand
group by
a.brand
+--------+
| brand |
+--------+
| BMW |
| Ford |
| Nissan |
| Smart |
| Toyota |
+--------+
5 rows in set (0.00 sec)
Was natürlich ein Problem ist – wir sehen keine Erwähnung des schönen Holden Marke, die ich hinzugefügt habe.
Dies liegt daran, dass ein Join nach übereinstimmenden Zeilen in beiden sucht Tische. Da es keine Daten in Autos gibt, die vom Typ Holden sind es wird nicht zurückgegeben. Hier können wir einen outer verwenden beitreten. Dies gibt alle zurück die Ergebnisse aus einer Tabelle, unabhängig davon, ob sie in der anderen Tabelle übereinstimmen oder nicht:
select
a.brand
from
brands a
left outer join cars b
on a.ID=b.brand
group by
a.brand
+--------+
| brand |
+--------+
| BMW |
| Ford |
| Holden |
| Nissan |
| Smart |
| Toyota |
+--------+
6 rows in set (0.00 sec)
Jetzt, wo wir das haben, können wir eine schöne Aggregatfunktion hinzufügen, um eine Zählung zu erhalten und den Boss für einen Moment von unserem Rücken zu nehmen.
select
a.brand,
count(b.id) as countOfBrand
from
brands a
left outer join cars b
on a.ID=b.brand
group by
a.brand
+--------+--------------+
| brand | countOfBrand |
+--------+--------------+
| BMW | 2 |
| Ford | 2 |
| Holden | 0 |
| Nissan | 1 |
| Smart | 1 |
| Toyota | 5 |
+--------+--------------+
6 rows in set (0.00 sec)
Und damit schleicht der Chef davon.
Nun, um dies etwas detaillierter zu erklären, Outer Joins können left sein oder right Typ. Links oder Rechts definieren, welche Tabelle vollständig ist inbegriffen. Ein left outer join enthält alle Zeilen aus der Tabelle auf der linken Seite, während (Sie haben es erraten) ein right outer join ist bringt alle Ergebnisse aus der rechten Tabelle in die Ergebnisse.
Einige Datenbanken erlauben einen full outer join was Ergebnisse (ob übereinstimmend oder nicht) von beiden zurückbringt Tabellen, aber dies wird nicht in allen Datenbanken unterstützt.
Nun, ich nehme an, dass Sie sich zu diesem Zeitpunkt wahrscheinlich fragen, ob Sie Join-Typen in einer Abfrage zusammenführen können oder nicht - und die Antwort ist ja, das können Sie absolut.
select
b.brand,
c.color,
count(a.id) as countOfBrand
from
cars a
right outer join brands b
on b.ID=a.brand
join colors c
on a.color=c.ID
group by
a.brand,
c.color
+--------+-------+--------------+
| brand | color | countOfBrand |
+--------+-------+--------------+
| Ford | Blue | 1 |
| Ford | White | 1 |
| Toyota | Black | 1 |
| Toyota | Green | 2 |
| Toyota | Red | 1 |
| Nissan | Black | 1 |
| Smart | White | 1 |
| BMW | Blue | 1 |
| BMW | White | 1 |
+--------+-------+--------------+
9 rows in set (0.00 sec)
Warum sind das nicht die erwarteten Ergebnisse? Dies liegt daran, dass wir zwar die äußere Verknüpfung von Autos zu Marken ausgewählt haben, diese jedoch nicht in der Verknüpfung zu Farben angegeben wurde - sodass diese bestimmte Verknüpfung nur Ergebnisse zurückgibt, die in beiden Tabellen übereinstimmen.
Hier ist die Abfrage, die funktionieren würde, um die erwarteten Ergebnisse zu erhalten:
select
a.brand,
c.color,
count(b.id) as countOfBrand
from
brands a
left outer join cars b
on a.ID=b.brand
left outer join colors c
on b.color=c.ID
group by
a.brand,
c.color
+--------+-------+--------------+
| brand | color | countOfBrand |
+--------+-------+--------------+
| BMW | Blue | 1 |
| BMW | White | 1 |
| Ford | Blue | 1 |
| Ford | White | 1 |
| Holden | NULL | 0 |
| Nissan | Black | 1 |
| Smart | White | 1 |
| Toyota | NULL | 1 |
| Toyota | Black | 1 |
| Toyota | Green | 2 |
| Toyota | Red | 1 |
+--------+-------+--------------+
11 rows in set (0.00 sec)
Wie wir sehen können, haben wir zwei Outer Joins in der Abfrage und die Ergebnisse kommen wie erwartet an.
Wie sieht es nun mit den anderen Arten von Joins aus, die Sie fragen? Was ist mit Kreuzungen?
Nun, nicht alle Datenbanken unterstützen den intersection aber so ziemlich alle Datenbanken erlauben es Ihnen, eine Schnittmenge durch einen Join (oder zumindest eine gut strukturierte where-Anweisung) zu erstellen.
Eine Schnittmenge ist eine Art von Join, ähnlich einer union wie oben beschrieben - aber der Unterschied ist, dass es nur gibt Datenzeilen zurück, die zwischen den verschiedenen einzelnen Abfragen, die durch die Vereinigung verbunden sind, identisch sind (und ich meine identisch). Es werden nur Zeilen zurückgegeben, die in jeder Hinsicht identisch sind.
Ein einfaches Beispiel wäre wie folgt:
select
*
from
colors
where
ID>2
intersect
select
*
from
colors
where
id<4
Während eine normale union würde alle Zeilen der Tabelle zurückgeben (die erste Abfrage, die irgendetwas über ID>2 zurückgibt und das zweite alles mit ID<4 ), was zu einem vollständigen Satz führen würde, würde eine Intersect-Abfrage nur die Zeile zurückgeben, die id=3 entspricht da es beide Kriterien erfüllt.
Nun, falls Ihre Datenbank kein intersect unterstützt Abfrage kann das obige einfach mit der folgenden Abfrage erreicht werden:
select
a.ID,
a.color,
a.paint
from
colors a
join colors b
on a.ID=b.ID
where
a.ID>2
and b.ID<4
+----+-------+----------+
| ID | color | paint |
+----+-------+----------+
| 3 | Blue | Metallic |
+----+-------+----------+
1 row in set (0.00 sec)
Wenn Sie eine Überschneidung zwischen zwei verschiedenen Tabellen mit einer Datenbank durchführen möchten, die von Natur aus keine Überschneidungsabfrage unterstützt, müssen Sie für jede Spalte einen Join erstellen der Tabellen.