MySQL-Replikation ist die gebräuchlichste und am weitesten verbreitete Lösung für Hochverfügbarkeit durch große Organisationen wie Github, Twitter und Facebook. Obwohl die Einrichtung einfach ist, gibt es Herausforderungen bei der Verwendung dieser Lösung von der Wartung, einschließlich Software-Upgrades, Datendrift oder Dateninkonsistenz über die Replikationsknoten hinweg, Topologieänderungen, Failover und Wiederherstellung. Als MySQL Version 5.6 veröffentlichte, brachte es eine Reihe bedeutender Verbesserungen, insbesondere für die Replikation, die globale Transaktions-IDs (GTIDs), Ereignisprüfsummen, Multithread-Slaves und absturzsichere Slaves/Master umfasst. Die Replikation wurde mit MySQL 5.7 und MySQL 8.0 sogar noch besser.
Die Replikation ermöglicht die Replikation von Daten von einem MySQL-Server (dem primären/Master) auf einen oder mehrere MySQL-Server (die Replik/Slaves). MySQL Replication ist sehr einfach einzurichten und wird verwendet, um Lese-Workloads zu skalieren, hohe Verfügbarkeit und geografische Redundanz bereitzustellen und Backups und Analysejobs auszulagern.
MySQL-Replikation in der Natur
Verschaffen wir uns einen kurzen Überblick darüber, wie die MySQL-Replikation in der Natur funktioniert. Die MySQL-Replikation ist breit gefächert und es gibt mehrere Möglichkeiten, sie zu konfigurieren und zu verwenden. Standardmäßig wird die asynchrone Replikation verwendet, die funktioniert, wenn die Transaktion in der lokalen Umgebung abgeschlossen wird. Es gibt keine Garantie dafür, dass ein Ereignis jemals einen Sklaven erreicht. Es ist eine lose gekoppelte Master-Slave-Beziehung, wobei:
-
Primary wartet nicht auf eine Replik.
-
Replica bestimmt, wie viel gelesen werden soll und ab welchem Punkt im Binärlog.
-
Replica kann beim Lesen oder Anwenden von Änderungen beliebig hinter dem Master zurückbleiben.
Wenn der primäre Server abstürzt, wurden Transaktionen, die er festgeschrieben hat, möglicherweise nicht an ein Replikat übertragen. Folglich kann ein Failover vom primären zum fortschrittlichsten Replikat in diesem Fall zu einem Failover zum gewünschten primären Server führen, dem tatsächlich Transaktionen im Vergleich zum vorherigen Server fehlen.
Asynchrone Replikation bietet eine geringere Schreiblatenz, da ein Schreibvorgang lokal von einem Master bestätigt wird, bevor er an Slaves geschrieben wird. Es eignet sich hervorragend für die Leseskalierung, da das Hinzufügen weiterer Replikate die Replikationslatenz nicht beeinflusst. Gute Anwendungsfälle für die asynchrone Replikation umfassen die Bereitstellung von Leserepliken für die Leseskalierung, Live-Sicherungskopien für die Notfallwiederherstellung und Analysen/Berichte.
Halbsynchrone MySQL-Replikation
MySQL unterstützt auch halbsynchrone Replikation, bei der der Master dem Client keine Transaktionen bestätigt, bis mindestens ein Slave die Änderung in sein Relay-Log kopiert und auf die Festplatte geschrieben hat. Um die halbsynchrone Replikation zu aktivieren, sind zusätzliche Schritte für die Plug-in-Installation erforderlich und müssen auf den designierten MySQL-Master- und -Slave-Knoten aktiviert werden.
Semisynchron scheint eine gute und praktische Lösung für viele Fälle zu sein, in denen es auf hohe Verfügbarkeit und keinen Datenverlust ankommt. Sie sollten jedoch bedenken, dass sich halbsynchron aufgrund des zusätzlichen Roundtrips auf die Leistung auswirkt und keine starken Garantien gegen Datenverlust bietet. Wenn ein Commit erfolgreich zurückkehrt, ist bekannt, dass die Daten an mindestens zwei Stellen vorhanden sind (auf dem Master und mindestens einem Slave). Wenn der Master festschreibt, aber ein Absturz auftritt, während der Master auf eine Bestätigung von einem Slave wartet, ist es möglich, dass die Transaktion keinen Slave erreicht hat. Dies ist kein großes Problem, da der Commit in diesem Fall nicht an die Anwendung zurückgegeben wird. Es ist die Aufgabe der Anwendung, die Transaktion in Zukunft erneut zu versuchen. Beachten Sie unbedingt, dass der alte Master der Replikationskette nicht beitreten kann, wenn der Master ausfällt und ein Slave hochgestuft wurde. Dies kann unter Umständen zu Konflikten mit Daten auf den Slaves führen, z. B. wenn der Master abstürzte, nachdem der Slave das Binärlog-Ereignis erhalten hatte, aber bevor der Master die Bestätigung vom Slave erhielt). Daher besteht die einzig sichere Möglichkeit darin, die Daten auf dem alten Master zu verwerfen und sie mit den Daten des neu heraufgestuften Masters von Grund auf neu bereitzustellen.
Das Replikationsformat falsch verwenden
Seit MySQL 5.7.7 verwendet das standardmäßige binäre Protokollformat oder die binlog_format-Variable ROW, was vor 5.7.7 STATEMENT war. Die unterschiedlichen Replikationsformate entsprechen der Methode, die zum Aufzeichnen der Binärprotokollereignisse der Quelle verwendet wird. Die Replikation funktioniert, weil in das Binärprotokoll geschriebene Ereignisse aus der Quelle gelesen und dann auf dem Replikat verarbeitet werden. Die Ereignisse werden je nach Ereignistyp in verschiedenen Replikationsformaten im Binärprotokoll aufgezeichnet. Nicht sicher zu wissen, was man verwenden soll, kann ein Problem sein. MySQL hat drei Formate von Replikationsmethoden:STATEMENT, ROW und MIXED.
-
Das STATEMENT-basierte Replikationsformat (SBR) ist genau das, was es ist – ein Replikationsstrom jeder Anweisungsausführung auf dem Master, die auf dem Slave-Knoten wiedergegeben werden. Standardmäßig führt die herkömmliche (asynchrone) MySQL-Replikation die replizierten Transaktionen an den Slaves nicht parallel aus. Das bedeutet, dass die Reihenfolge der Anweisungen im Replikationsstrom möglicherweise nicht zu 100 % gleich ist. Außerdem kann die Wiedergabe einer Anweisung andere Ergebnisse liefern, wenn sie nicht gleichzeitig ausgeführt wird, als wenn sie von der Quelle ausgeführt wird. Dies führt zu einem inkonsistenten Zustand gegenüber dem Primärserver und seinen Replikaten. Dies war viele Jahre lang kein Problem, da nicht viele MySQL mit vielen gleichzeitigen Threads ausführten. Bei modernen Multi-CPU-Architekturen ist dies jedoch bei normaler täglicher Arbeitslast tatsächlich sehr wahrscheinlich geworden.
-
Das ROW-Replikationsformat bietet Lösungen, die dem SBR fehlen. Bei Verwendung des Protokollierungsformats für die zeilenbasierte Replikation (RBR) schreibt die Quelle Ereignisse in das Binärprotokoll, die angeben, wie einzelne Tabellenzeilen geändert werden. Die Replikation von der Quelle zum Replikat funktioniert, indem die Ereignisse, die die Änderungen an den Tabellenzeilen darstellen, in das Replikat kopiert werden. Dies bedeutet, dass mehr Daten generiert werden können, was sich auf den Speicherplatz im Replikat und den Netzwerkverkehr und die Festplatten-E/A auswirkt. Bedenken Sie, wenn eine Anweisung viele Zeilen ändert, sagen wir mit einer UPDATE-Anweisung, schreibt RBR mehr Daten in das Binärlog, selbst für Anweisungen, die zurückgesetzt werden. Das Ausführen von Point-in-Time-Snapshots kann ebenfalls mehr Zeit in Anspruch nehmen. Angesichts der Sperrzeiten, die zum Schreiben großer Datenmengen in das Binärlog erforderlich sind, können Parallelitätsprobleme auftreten.
-
Dann gibt es eine Methode zwischen diesen beiden; Replikation im gemischten Modus. Diese Art der Replikation repliziert immer Anweisungen, außer wenn die Abfrage die UUID()-Funktion, Trigger, gespeicherte Prozeduren, UDFs und einige andere Ausnahmen enthält. Der gemischte Modus löst das Problem der Datendrift nicht und sollte zusammen mit der anweisungsbasierten Replikation vermieden werden.
Planen Sie ein Multi-Master-Setup?
Zirkuläre Replikation (auch bekannt als Ringtopologie) ist ein bekanntes und gängiges Setup für die MySQL-Replikation. Es wird zum Ausführen eines Multi-Master-Setups verwendet (siehe Abbildung unten) und ist häufig erforderlich, wenn Sie eine Umgebung mit mehreren Rechenzentren haben. Da die Anwendung nicht darauf warten kann, dass der Master im anderen Rechenzentrum die Schreibvorgänge bestätigt, wird ein lokaler Master bevorzugt. Normalerweise wird der Autoinkrement-Offset verwendet, um Datenkollisionen zwischen den Mastern zu verhindern. Es ist eine allgemein akzeptierte Lösung, dass zwei Master auf diese Weise gegenseitig Schreibvorgänge ausführen.
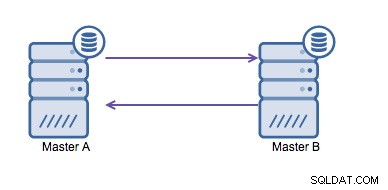
Wenn Sie jedoch in mehreren Rechenzentren in dieselbe Datenbank schreiben müssen , haben Sie am Ende mehrere Master, die ihre Daten ineinander schreiben müssen. Vor MySQL 5.7.6 gab es keine Methode, um eine Mesh-Replikation durchzuführen, daher wäre die Alternative, stattdessen eine Ringreplikation zu verwenden.
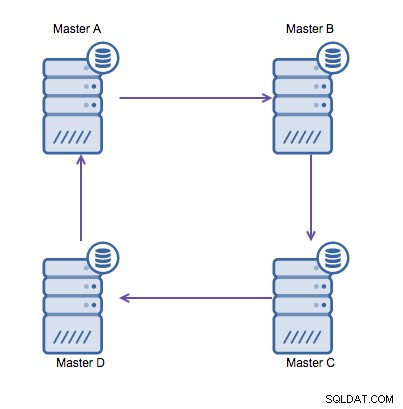
Ringreplikation in MySQL ist aus folgenden Gründen problematisch:Latenz, hohe Verfügbarkeit , und Datendrift. Das Schreiben einiger Daten auf Server A würde drei Sprünge dauern, um auf Server D zu landen (über Server B und C). Da die (herkömmliche) MySQL-Replikation Single-Threaded ist, kann jede lange laufende Abfrage in der Replikation den gesamten Ring blockieren. Auch wenn einer der Server ausfallen würde, würde der Ring unterbrochen, und derzeit kann keine Failover-Software Ringstrukturen reparieren. Dann kann es zu Datendrift kommen, wenn Daten auf Server A geschrieben und gleichzeitig auf Server C oder D geändert werden.
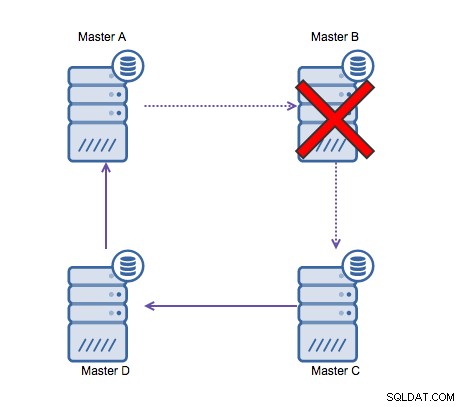
Im Allgemeinen passt die zirkuläre Replikation nicht gut zu MySQL und sollte es sein um jeden Preis vermeiden. Da es unter diesem Gesichtspunkt entwickelt wurde, wäre Galera Cluster eine gute Alternative für Schreibvorgänge in mehreren Rechenzentren.
Verzögern Ihrer Replikation mit großen Updates
Verschiedene Haushalts-Batch-Jobs führen oft verschiedene Aufgaben aus, die von der Bereinigung alter Daten bis zur Berechnung des Durchschnitts von „Gefällt mir“-Angaben aus einer anderen Quelle reichen. Dies bedeutet, dass ein Job in festgelegten Intervallen eine Menge Datenbankaktivitäten erzeugt und höchstwahrscheinlich viele Daten in die Datenbank zurückschreibt. Das bedeutet natürlich, dass die Aktivität innerhalb des Replikationsstroms gleichermaßen ansteigt.
Anweisungsbasierte Replikation repliziert genau die Abfragen, die in den Batch-Jobs verwendet werden. Wenn also die Abfrage eine halbe Stunde für die Verarbeitung auf dem Master benötigt, würde der Slave-Thread für mindestens die gleiche Zeit angehalten Zeit. Das bedeutet, dass keine anderen Daten repliziert werden können und die Slave-Knoten hinter dem Master zurückbleiben. Wenn dies den Schwellenwert Ihres Failover-Tools oder Proxys überschreitet, werden diese Slave-Knoten möglicherweise von den verfügbaren Servern im Cluster gelöscht. Wenn Sie die anweisungsbasierte Replikation verwenden, können Sie dies verhindern, indem Sie die Daten für Ihren Job in kleineren Stapeln verarbeiten.
Jetzt denken Sie vielleicht, dass die zeilenbasierte Replikation davon nicht betroffen ist, da sie die Zeileninformationen anstelle der Abfrage repliziert. Dies trifft teilweise zu, da die Replikation bei DDL-Änderungen auf ein anweisungsbasiertes Format zurückkehrt. Außerdem wirkt sich eine große Anzahl von CRUD-Vorgängen (Create, Read, Update, Delete) auf den Replikationsstrom aus. In den meisten Fällen handelt es sich immer noch um einen Single-Thread-Vorgang, und daher wartet jede Transaktion darauf, dass die vorherige über die Replikation wiederholt wird. Das bedeutet, dass bei hoher Gleichzeitigkeit auf dem Master der Slave aufgrund der Transaktionsüberlastung während der Replikation ins Stocken geraten kann.
Um dies zu umgehen, bieten sowohl MariaDB als auch MySQL parallele Replikation an. Die Implementierung kann je nach Anbieter und Version unterschiedlich sein. MySQL 5.6 bietet parallele Replikation, solange die Abfragen durch das Schema getrennt sind. MariaDB 10.0 und MySQL 5.7 können beide die parallele Replikation über Schemas hinweg handhaben, haben aber andere Grenzen. Das Ausführen von Abfragen über parallele Slave-Threads kann Ihren Replikationsstrom beschleunigen, wenn Sie viel schreiben. Andernfalls wäre es besser, bei der traditionellen Single-Thread-Replikation zu bleiben.
Umgang mit Ihrer Schemaänderung oder Ihren DDLs
Seit der Veröffentlichung von 5.7 hat sich die Verwaltung der Schemaänderung oder DDL-Änderung (Data Definition Language) in MySQL stark verbessert. Bis MySQL 8.0 sind die unterstützten DDL-Änderungsalgorithmen COPY und INPLACE.
-
COPY:Dieser Algorithmus erstellt eine neue temporäre Tabelle mit dem geänderten Schema. Sobald die Daten vollständig in die neue temporäre Tabelle migriert sind, wird die alte Tabelle ausgetauscht und gelöscht.
-
INPLACE:Dieser Algorithmus führt Operationen direkt an der ursprünglichen Tabelle durch und vermeidet das Kopieren und Neuerstellen der Tabelle, wann immer dies möglich ist.
-
SOFORT:Dieser Algorithmus wurde seit MySQL 8.0 eingeführt, hat aber immer noch Einschränkungen.
In MySQL 8.0 wurde der Algorithmus INSTANT eingeführt, der sofortige und direkte Tabellenänderungen für das Hinzufügen von Spalten vornimmt und gleichzeitiges DML mit verbesserter Reaktionsfähigkeit und Verfügbarkeit in ausgelasteten Produktionsumgebungen ermöglicht. Dies hilft, große Verzögerungen und Verzögerungen in der Replik zu vermeiden, die in der Anwendungsperspektive normalerweise große Probleme darstellten und dazu führten, dass veraltete Daten abgerufen wurden, da die Lesevorgänge im Slave aufgrund von Verzögerungen noch nicht aktualisiert wurden.
Obwohl dies eine vielversprechende Verbesserung ist, gibt es immer noch Einschränkungen, und manchmal ist es nicht möglich, diese INSTANT- und INPLACE-Algorithmen anzuwenden. Beispielsweise ist das Ändern des Datentyps einer Spalte für INSTANT- und INPLACE-Algorithmen auch eine übliche DBA-Aufgabe, insbesondere aus Sicht der Anwendungsentwicklung aufgrund von Datenänderungen. Diese Gelegenheiten sind unvermeidlich; Daher können Sie mit dem COPY-Algorithmus nicht fortfahren, da dies die Tabelle sperrt und Verzögerungen im Slave verursacht. Es wirkt sich während dieser Ausführung auch auf den Primär-/Master-Server aus, da eingehende Transaktionen angehäuft werden, die ebenfalls auf die betroffene Tabelle verweisen. Sie können auf einem ausgelasteten Server keine direkte ALTER- oder Schemaänderung durchführen, da dies mit Ausfallzeiten einhergeht oder möglicherweise Ihre Datenbank beschädigt, wenn Sie die Geduld verlieren, insbesondere wenn die Zieltabelle riesig ist.
Es stimmt, dass die Durchführung von Schemaänderungen in einer laufenden Produktionsumgebung immer eine herausfordernde Aufgabe ist. Eine häufig verwendete Problemumgehung besteht darin, die Schemaänderung zuerst auf die Slave-Knoten anzuwenden. Dies funktioniert gut für die anweisungsbasierte Replikation, aber dies kann nur bis zu einem gewissen Grad für die zeilenbasierte Replikation funktionieren. Bei der zeilenbasierten Replikation können am Ende der Tabelle zusätzliche Spalten vorhanden sein. Solange die ersten Spalten geschrieben werden können, ist dies in Ordnung. Wenden Sie zuerst die Änderung auf alle Slaves an, führen Sie dann ein Failover auf einen der Slaves durch und wenden Sie dann die Änderung auf den Master an und hängen Sie diesen als Slave an. Wenn Ihre Änderung das Einfügen einer Spalte in der Mitte oder das Entfernen einer Spalte beinhaltet, funktioniert dies mit der zeilenbasierten Replikation.
Es sind Tools verfügbar, die Online-Schemaänderungen zuverlässiger durchführen können. Percona Online Schema Change (bekannt als pt-osc) und gh-ost von Schlomi Noach werden häufig von DBAs verwendet. Diese Tools handhaben Schemaänderungen effektiv, indem sie die betroffenen Zeilen in Chunks gruppieren, und diese Chunks können entsprechend konfiguriert werden, je nachdem, wie viele Sie gruppieren möchten.
Wenn Sie mit pt-osc springen, erstellt dieses Tool eine Schattentabelle mit der neuen Tabellenstruktur, fügt neue Daten über Trigger ein und füllt Daten im Hintergrund auf. Sobald die neue Tabelle erstellt ist, wird einfach die alte gegen die neue Tabelle innerhalb einer Transaktion ausgetauscht. Dies funktioniert nicht in allen Fällen, insbesondere wenn Ihre vorhandene Tabelle bereits Trigger hat.
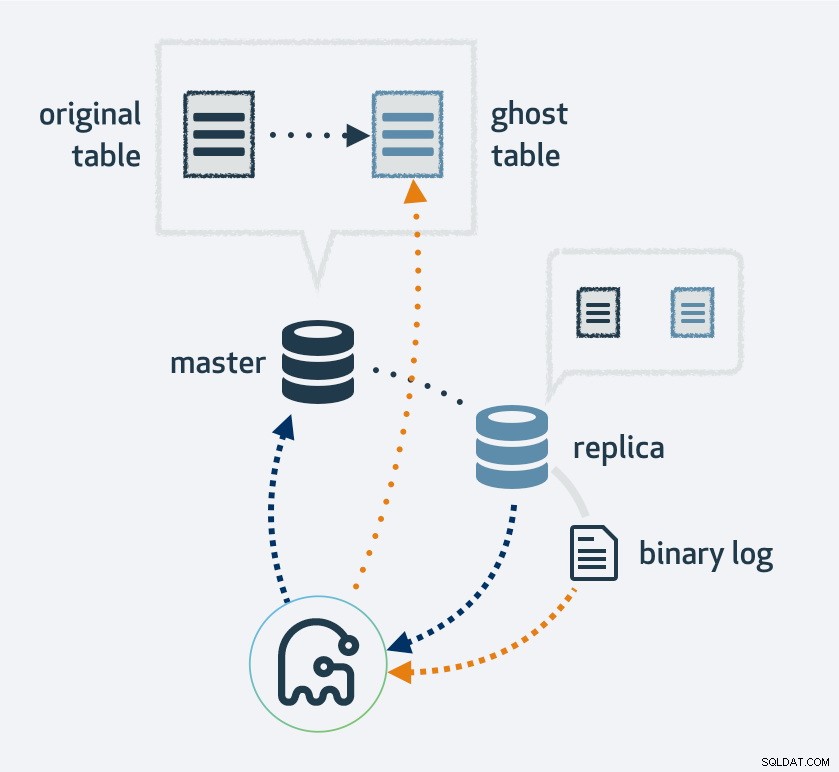
Bei Verwendung von gh-ost wird zunächst eine Kopie Ihres vorhandenen Tabellenlayouts erstellt. Ändern Sie die Tabelle in das neue Layout und binden Sie den Prozess dann als MySQL-Replikat ein. Es verwendet den Replikationsstream, um neue Zeilen zu finden, die in die ursprüngliche Tabelle eingefügt wurden, und füllt gleichzeitig die Tabelle auf. Sobald das Auffüllen abgeschlossen ist, wechseln die ursprüngliche und die neue Tabelle. Natürlich landen alle Operationen an der neuen Tabelle im Replikationsstrom; Daher findet die Migration auf jedem Replikat gleichzeitig statt.
Speichertabellen und Replikation
Wo wir gerade beim Thema DDLs sind, ein häufiges Problem ist die Erstellung von Speichertabellen. Speichertabellen sind nicht-persistente Tabellen, ihre Tabellenstruktur bleibt erhalten, aber sie verlieren ihre Daten nach einem Neustart von MySQL. Wenn Sie sowohl auf einem Master als auch auf einem Slave eine neue Speichertabelle erstellen, haben sie eine leere Tabelle, die einwandfrei funktioniert. Sobald einer von beiden neu gestartet wird, wird die Tabelle geleert und es treten Replikationsfehler auf.
Die zeilenbasierte Replikation bricht ab, sobald die Daten im Slave-Knoten andere Ergebnisse zurückgeben, und die anweisungsbasierte Replikation bricht ab, sobald sie versucht, bereits vorhandene Daten einzufügen. Bei Speichertabellen ist dies ein häufiger Replikationsbrecher. Die Lösung ist einfach:Erstellen Sie eine neue Kopie der Daten, ändern Sie die Engine auf InnoDB, und sie sollte jetzt replikationssicher sein.
Festlegen von read_only={True|1}
Dies ist natürlich ein möglicher Fall, wenn Sie eine Ringtopologie verwenden, und wir raten nach Möglichkeit von der Verwendung einer Ringtopologie ab. Wir haben bereits beschrieben, dass die Replikation unterbrochen werden kann, wenn nicht dieselben Daten in den Slave-Knoten vorhanden sind. Dies wird häufig dadurch verursacht, dass etwas (oder jemand) die Daten auf dem Slave-Knoten ändert, aber nicht auf dem Master-Knoten. Sobald die Daten des Master-Knotens geändert werden, werden diese auf den Slave repliziert, wo er die Änderung nicht anwenden kann, und dies führt dazu, dass die Replikation unterbrochen wird. Dies kann auch zu Datenkorruption auf Clusterebene führen, insbesondere wenn der Slave hochgestuft wurde oder aufgrund eines Absturzes ein Failover stattgefunden hat. Das kann eine Katastrophe sein.
Eine einfache Vorbeugung dafür ist sicherzustellen, dass read_only und super_read_only (nur auf> 5.6) auf ON oder 1 gesetzt sind. Sie haben vielleicht verstanden, wie sich diese beiden Variablen unterscheiden und wie es sich auswirkt, wenn Sie sie deaktivieren oder aktivieren Sie. Wenn super_read_only (seit MySQL 5.7.8) deaktiviert ist, kann der Root-Benutzer Änderungen am Ziel oder Replikat verhindern. Wenn also beide deaktiviert sind, kann niemand Änderungen an den Daten vornehmen, mit Ausnahme der Replikation. Die meisten Failover-Manager, wie z. B. ClusterControl, setzen dieses Flag automatisch, um zu verhindern, dass Benutzer während des Failovers auf den verwendeten Master schreiben. Einige von ihnen behalten dies sogar nach dem Failover bei.
GTID aktivieren
Bei der MySQL-Replikation ist es wichtig, den Slave von der richtigen Position in den Binärlogs zu starten. Das Erhalten dieser Position kann erfolgen, wenn Sie ein Backup erstellen (xtrabackup und mysqldump unterstützen dies) oder wenn Sie aufgehört haben, auf einem Knoten zu arbeiten, von dem Sie eine Kopie erstellen. Das Starten der Replikation mit dem Befehl CHANGE MASTER TO würde wie folgt aussehen:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',
MASTER_USER='replication_user',
MASTER_PASSWORD='password',
MASTER_LOG_FILE='master-bin.00001',
MASTER_LOG_POS=4;Die Replikation an der falschen Stelle zu starten, kann fatale Folgen haben:Daten können doppelt geschrieben oder nicht aktualisiert werden. Dies verursacht eine Datendrift zwischen dem Master- und dem Slave-Knoten.
Außerdem erfordert das Failover eines Masters auf einen Slave, die richtige Position zu finden und den Master auf den entsprechenden Host umzustellen. MySQL behält die Binärlogs und Positionen von seinem Master nicht bei, sondern erstellt stattdessen seine eigenen Binärlogs und Positionen. Dies könnte ein ernsthaftes Problem für die Neuausrichtung eines Slave-Knotens auf den neuen Master werden. Die genaue Position des Masters beim Failover muss auf dem neuen Master gefunden werden, und dann können alle Slaves neu ausgerichtet werden.
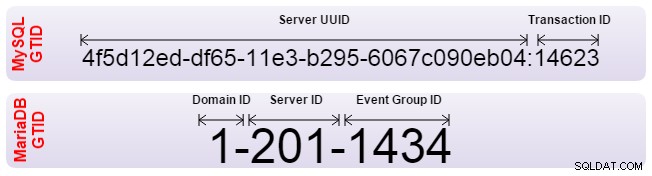
Sowohl Oracle MySQL als auch MariaDB haben den Global Transaction Identifier (GTID) implementiert dieses Problem lösen. GTIDs ermöglichen die automatische Ausrichtung von Slaves, und der Server findet selbst heraus, was die richtige Position ist. Allerdings haben beide die GTID unterschiedlich implementiert und sind daher nicht kompatibel. Wenn Sie eine Replikation von einem zum anderen einrichten müssen, sollte die Replikation mit herkömmlicher binärer Log-Positionierung eingerichtet werden. Außerdem sollte Ihre Failover-Software darauf hingewiesen werden, keine GTIDs zu verwenden.
Absturzsicherer Slave
Absturzsicher bedeutet, dass Sie selbst dann, wenn ein Slave-MySQL/OS abstürzt, den Slave wiederherstellen und die Replikation fortsetzen können, ohne MySQL-Datenbanken auf dem Slave wiederherzustellen. Damit der absturzsichere Slave funktioniert, müssen Sie nur die InnoDB-Speicher-Engine verwenden, und in 5.6 müssen Sie relay_log_info_repository=TABLE und relay_log_recovery=1 festlegen.
Fazit
Übung macht in der Tat den Meister, aber ohne angemessenes Training und Wissen über diese lebenswichtigen Techniken könnte es mühsam sein oder zu einer Katastrophe führen. Diese Praktiken werden allgemein von MySQL-Experten befolgt und von großen Branchen als Teil ihrer täglichen Routinearbeit bei der Verwaltung der MySQL-Replikation auf den Produktionsdatenbankservern übernommen.
Wenn Sie mehr über die MySQL-Replikation erfahren möchten, sehen Sie sich dieses Tutorial zur MySQL-Replikation für Hochverfügbarkeit an.
Folgen Sie uns für weitere Updates zu Datenbankverwaltungslösungen und Best Practices für Ihre Open-Source-basierten Datenbanken auf Twitter und LinkedIn und abonnieren Sie unseren Newsletter.