Das Verschieben Ihrer Daten in einen öffentlichen Cloud-Dienst ist eine große Entscheidung. Alle großen Cloud-Anbieter bieten Cloud-Datenbankdienste an, wobei Amazon RDS für MySQL wahrscheinlich am beliebtesten ist.
In diesem Blog werden wir uns genau ansehen, was es ist, wie es funktioniert, und seine Vor- und Nachteile vergleichen.
RDS (Relational Database Service) ist ein Angebot von Amazon Web Services. Kurz gesagt handelt es sich um eine Database as a Service, bei der Amazon Ihre Datenbank bereitstellt und betreibt. Es kümmert sich um Aufgaben wie Backup und Patchen der Datenbanksoftware sowie Hochverfügbarkeit. Einige Datenbanken werden von RDS unterstützt, wir interessieren uns hier jedoch hauptsächlich für MySQL - Amazon unterstützt MySQL und MariaDB. Es gibt auch Aurora, Amazons Klon von MySQL, der verbessert wurde, insbesondere im Bereich Replikation und Hochverfügbarkeit.
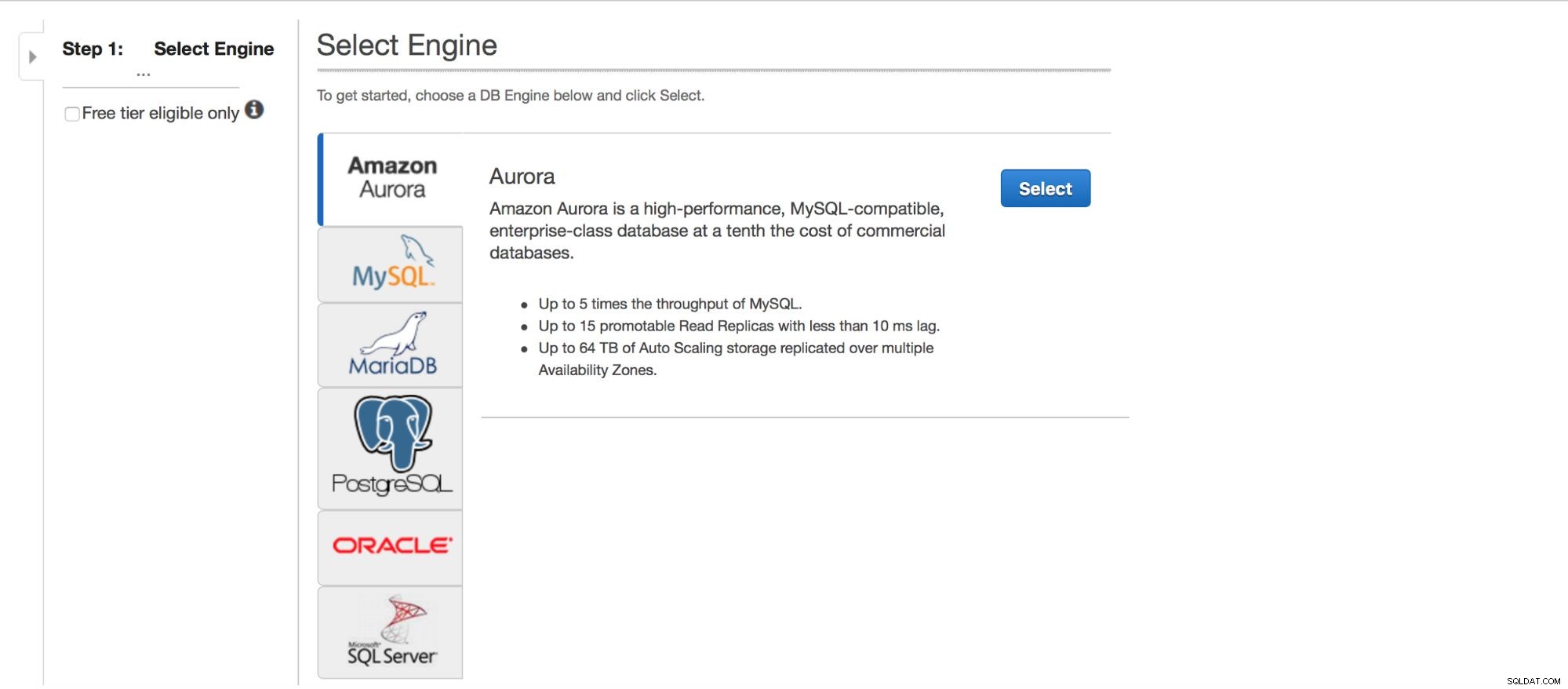
Bereitstellen von MySQL über RDS
Werfen wir einen Blick auf die Bereitstellung von MySQL über RDS. Wir haben MySQL ausgewählt und dann werden uns einige Bereitstellungsmuster zur Auswahl präsentiert.
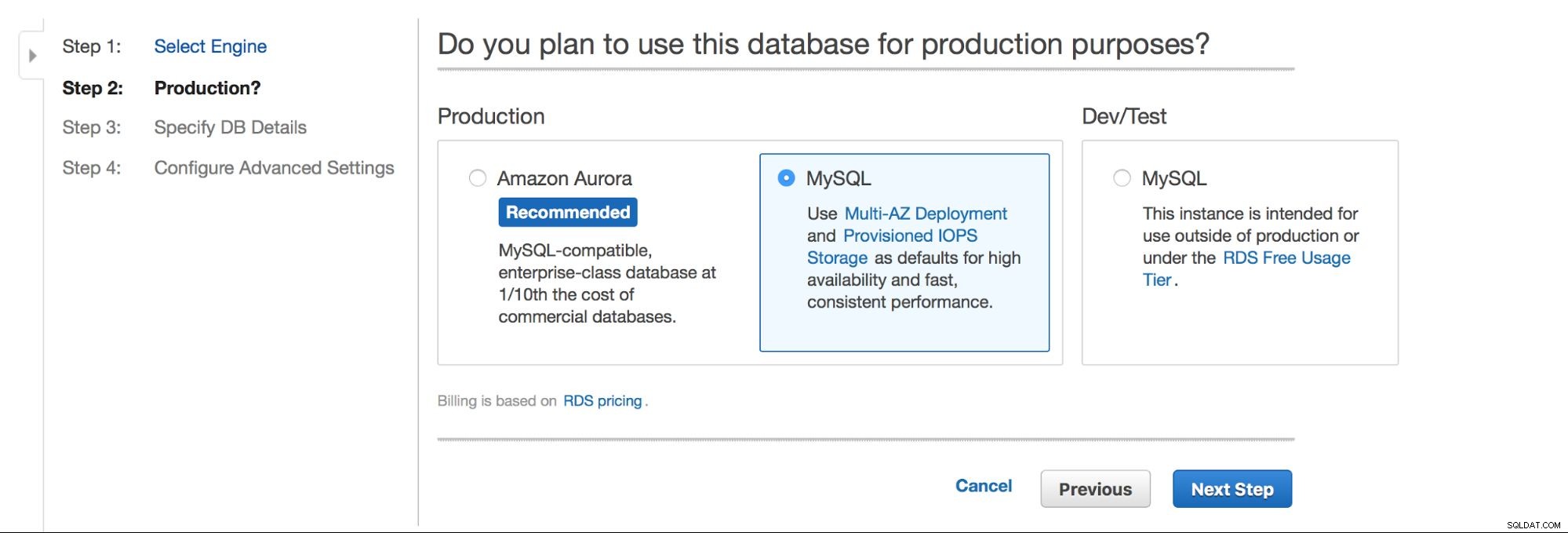
Die Hauptentscheidung ist – wollen wir eine hohe Verfügbarkeit haben oder nicht? Aurora wird auch beworben.
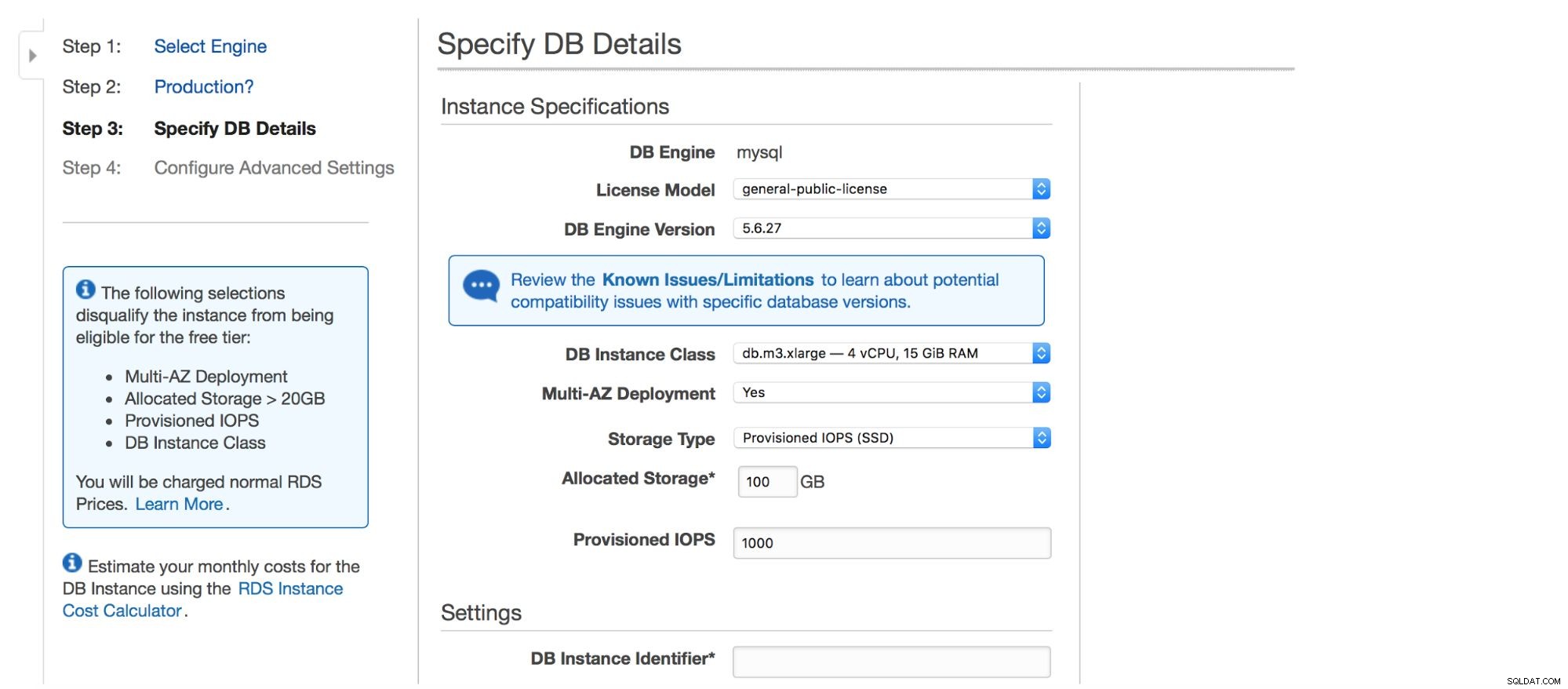
Das nächste Dialogfeld bietet uns einige Optionen zum Anpassen. Sie können eine von vielen MySQL-Versionen auswählen - mehrere 5.5-, 5.6- und 5.7-Versionen sind verfügbar. Datenbankinstanz – Sie können aus typischen Instanzgrößen wählen, die in einer bestimmten Region verfügbar sind.
Die nächste Option ist eine ziemlich wichtige Wahl – möchten Sie die Multi-AZ-Bereitstellung verwenden oder nicht? Hier dreht sich alles um Hochverfügbarkeit. Wenn Sie keine Multi-AZ-Bereitstellung verwenden möchten, wird eine einzelne Instanz installiert. Im Falle eines Ausfalls wird ein neuer hochgefahren und sein Datenvolumen wird darauf neu gemountet. Dieser Vorgang dauert einige Zeit, während der Ihre Datenbank nicht verfügbar ist. Natürlich können Sie diese Auswirkungen minimieren, indem Sie Sklaven verwenden und einen von ihnen fördern, aber es ist kein automatisierter Prozess. Wenn Sie eine automatisierte Hochverfügbarkeit wünschen, sollten Sie die Multi-AZ-Bereitstellung verwenden. Was passieren wird, ist, dass zwei Datenbankinstanzen erstellt werden. Einer ist für Sie sichtbar. Eine zweite Instanz in einer separaten Verfügbarkeitszone ist für den Benutzer nicht sichtbar. Er fungiert als Schattenkopie und ist bereit, den Datenverkehr zu übernehmen, sobald der aktive Knoten ausfällt. Es ist immer noch keine perfekte Lösung, da der Datenverkehr von der ausgefallenen Instanz auf die Schatteninstanz umgeleitet werden muss. In unseren Tests dauerte es ungefähr 45 Sekunden, um ein Failover durchzuführen, aber es hängt natürlich von der Instanzgröße, der E/A-Leistung usw. ab. Aber es ist viel besser als ein nicht automatisiertes Failover, bei dem nur Slaves beteiligt sind.
Schließlich haben wir Speichereinstellungen – Typ, Größe, PIOPS (falls zutreffend) und Datenbankeinstellungen – Kennung, Benutzer und Passwort.
Im nächsten Schritt warten noch ein paar Optionen auf Benutzereingaben.
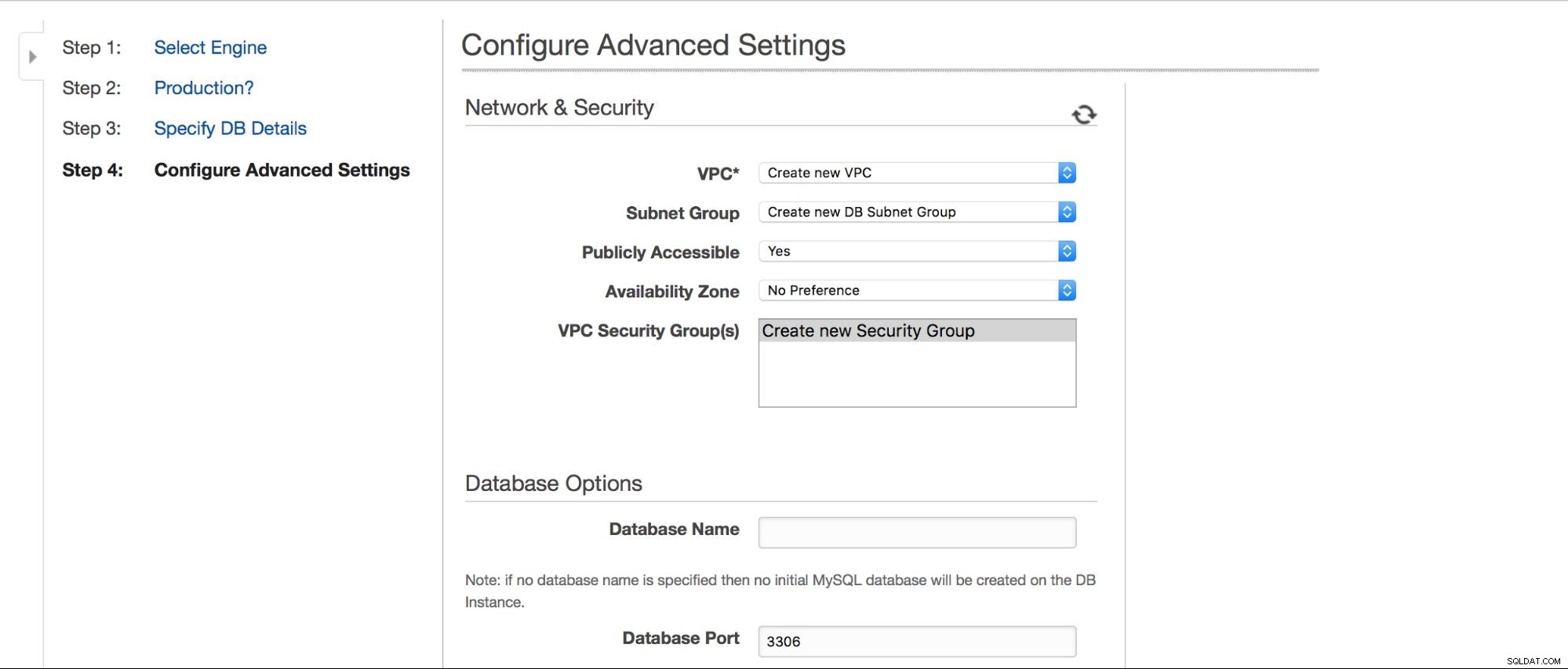
Wir können auswählen, wo die Instanz erstellt werden soll:VPC, Subnetz, ob es öffentlich verfügbar ist oder nicht (wie in - soll der RDS-Instanz eine öffentliche IP zugewiesen werden), Verfügbarkeitszone und VPC-Sicherheitsgruppe. Dann haben wir Datenbankoptionen:erstes zu erstellendes Schema, Port, Parameter- und Optionsgruppen, ob Metadaten-Tags in Snapshots enthalten sein sollen oder nicht, Verschlüsselungseinstellungen.
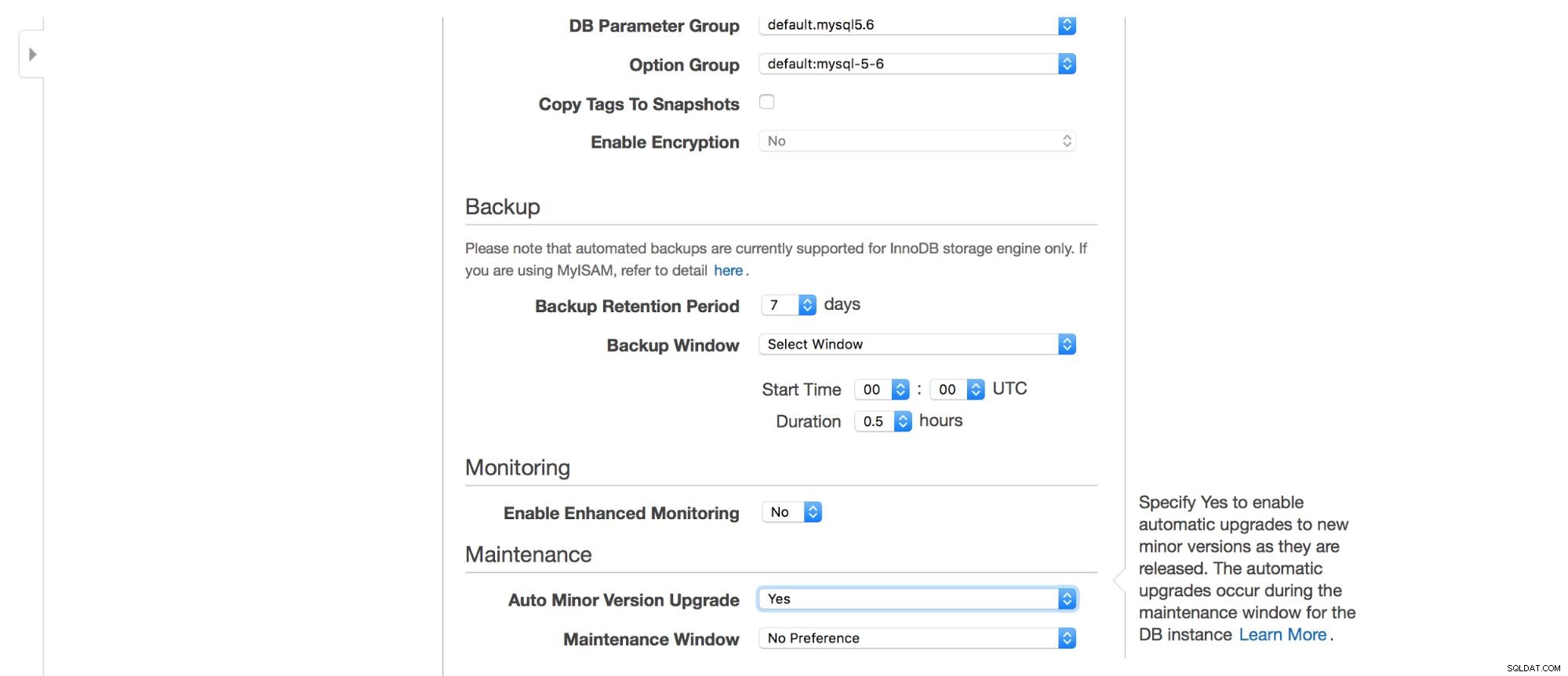
Als nächstes Backup-Optionen – wie lange möchten Sie Ihre Backups aufbewahren? Wann möchten Sie, dass sie genommen werden? Eine ähnliche Einrichtung bezieht sich auf Wartungsarbeiten – manchmal müssen Amazon-Administratoren Wartungsarbeiten an Ihrer RDS-Instanz durchführen – dies geschieht innerhalb eines vordefinierten Fensters, das Sie hier festlegen können. Bitte beachten Sie, dass es keine Option gibt, nicht mindestens 30 Minuten für das Wartungsfenster auszuwählen, deshalb ist es wirklich wichtig, eine Multi-AZ-Instanz in der Produktion zu haben. Die Wartung kann für einige Zeit zu einem Neustart des Knotens oder mangelnder Verfügbarkeit führen. Ohne Multi-AZ müssen Sie diese Ausfallzeit akzeptieren. Bei einer Multi-AZ-Bereitstellung findet ein Failover statt.
Schließlich haben wir Einstellungen in Bezug auf die zusätzliche Überwachung – wollen wir sie aktivieren oder nicht?
RDS verwalten
In diesem Kapitel sehen wir uns genauer an, wie man MySQL RDS verwaltet. Wir werden nicht alle verfügbaren Optionen durchgehen, aber wir möchten einige der Funktionen hervorheben, die Amazon zur Verfügung gestellt hat.
Schnappschüsse
MySQL RDS verwendet EBS-Volumes als Speicher, sodass EBS-Snapshots für verschiedene Zwecke verwendet werden können. Backups, Slaves – alles basierend auf Snapshots. Sie können Snapshots manuell erstellen oder bei Bedarf automatisch erstellen. Es ist wichtig zu bedenken, dass EBS-Snapshots im Allgemeinen (nicht nur auf RDS-Instances) I/O-Vorgängen etwas Overhead hinzufügen. Wenn Sie einen Snapshot erstellen möchten, müssen Sie damit rechnen, dass Ihre E/A-Leistung sinkt. Es sei denn, Sie verwenden eine Multi-AZ-Bereitstellung. In diesem Fall wird die „Schatteninstanz“ als Quelle für Snapshots verwendet und es sind keine Auswirkungen auf die Produktionsinstanz sichtbar.
Multiplenines DevOps-Leitfaden zur DatenbankverwaltungErfahren Sie, was Sie wissen müssen, um Ihre Open-Source-Datenbanken zu automatisieren und zu verwalten.Kostenlos herunterladenSicherungen
Backups basieren auf Snapshots. Wie oben erwähnt, können Sie Ihren Backup-Zeitplan und die Aufbewahrung definieren, wenn Sie eine neue Instanz erstellen. Natürlich können Sie diese Einstellungen später über die Option „Instanz ändern“ bearbeiten.
Sie können jederzeit einen Snapshot wiederherstellen – Sie müssen zum Snapshot-Bereich gehen, den Snapshot auswählen, den Sie wiederherstellen möchten, und Ihnen wird ein Dialogfeld ähnlich dem angezeigt, das Sie beim Erstellen einer neuen Instanz gesehen haben. Dies ist keine Überraschung, da Sie einen Snapshot nur in einer neuen Instanz wiederherstellen können – es gibt keine Möglichkeit, ihn auf einer der vorhandenen RDS-Instanzen wiederherzustellen. Es mag überraschen, aber selbst in einer Cloud-Umgebung kann es sinnvoll sein, Hardware (und bereits vorhandene Instanzen) wiederzuverwenden. In einer gemeinsam genutzten Umgebung kann die Leistung einer einzelnen virtuellen Instanz abweichen – vielleicht ziehen Sie es vor, bei dem Leistungsprofil zu bleiben, mit dem Sie bereits vertraut sind. Leider ist dies in RDS nicht möglich.
Eine weitere Option in RDS ist die Point-in-Time-Wiederherstellung – eine sehr wichtige Funktion, eine Voraussetzung für jeden, der sich gut um seine Daten kümmern muss. Hier sind die Dinge komplexer und weniger hell. Für den Anfang ist es wichtig zu bedenken, dass MySQL RDS binäre Protokolle vor dem Benutzer verbirgt. Sie können einige Einstellungen ändern und erstellte Binlogs auflisten, aber Sie haben keinen direkten Zugriff darauf. Um Vorgänge auszuführen, einschließlich der Verwendung für die Wiederherstellung, können Sie nur die UI oder CLI verwenden. Dies beschränkt Ihre Optionen auf das, was Amazon Ihnen erlaubt, und ermöglicht es Ihnen, Ihr Backup bis zur letzten „wiederherstellbaren Zeit“ wiederherzustellen, die zufällig in 5-Minuten-Intervallen berechnet wird. Wenn Ihre Daten also um 9:33 Uhr entfernt wurden, können Sie sie nur bis zum Stand um 9:30 Uhr wiederherstellen. Die Point-in-Time-Wiederherstellung funktioniert genauso wie die Wiederherstellung von Snapshots – es wird eine neue Instanz erstellt.
Scale-out, Replikation
MySQL RDS ermöglicht Scale-out durch Hinzufügen neuer Slaves. Wenn ein Slave erstellt wird, wird ein Snapshot des Masters erstellt und zum Erstellen eines neuen Hosts verwendet. Dieser Teil funktioniert ziemlich gut. Leider können Sie keine komplexere Replikationstopologie wie eine mit Zwischenmastern erstellen. Sie können kein Master-Master-Setup erstellen, wodurch alle HA in den Händen von Amazon (und Multi-AZ-Bereitstellungen) bleiben. Soweit wir wissen, gibt es keine Möglichkeit, GTID zu aktivieren (nicht, dass Sie davon profitieren könnten, da Sie keine Kontrolle über die Replikation haben, kein CHANGE MASTER in RDS), nur normale, altmodische Binlog-Positionen.
Das Fehlen von GTID macht es nicht möglich, Multithread-Replikation zu verwenden - während es möglich ist, eine Anzahl von Workern mithilfe von RDS-Parametergruppen festzulegen, ist dies ohne GTID unbrauchbar. Das Hauptproblem ist, dass es im Falle eines Absturzes keine Möglichkeit gibt, eine einzelne Binärlog-Position zu lokalisieren - einige Arbeiter könnten zurückgeblieben sein, andere könnten weiter fortgeschritten sein. Wenn Sie das zuletzt angewendete Ereignis verwenden, verlieren Sie Daten, die noch nicht von diesen „hinkenden“ Mitarbeitern angewendet wurden. Wenn Sie das älteste Ereignis verwenden, werden Sie höchstwahrscheinlich mit „Duplicate Key“-Fehlern enden, die durch Ereignisse verursacht werden, die von fortgeschritteneren Mitarbeitern angewendet werden. Natürlich gibt es eine Möglichkeit, dieses Problem zu lösen, aber es ist nicht trivial und zeitaufwändig - definitiv nicht etwas, das Sie einfach automatisieren könnten.
Benutzer, die auf MySQL RDS erstellt wurden, haben keine SUPER-Berechtigung, sodass Operationen, die in eigenständigem MySQL einfach sind, in RDS nicht trivial sind. Amazon hat sich entschieden, gespeicherte Prozeduren zu verwenden, um dem Benutzer die Durchführung einiger dieser Vorgänge zu ermöglichen. Soweit wir das beurteilen können, werden eine Reihe potenzieller Probleme behandelt, obwohl dies nicht immer der Fall war – wir erinnern uns, wann Sie nicht zum nächsten Binärlog auf dem Master wechseln konnten. Ein Master-Absturz + Binlog-Korruption könnte alle Slaves kaputt machen - dafür gibt es jetzt eine Prozedur:rds_next_master_log .
Ein Slave kann manuell zum Master befördert werden. Dies würde es Ihnen ermöglichen, eine Art HA auf dem Multi-AZ-Mechanismus zu erstellen (oder ihn zu umgehen), aber es wurde sinnlos durch die Tatsache, dass Sie keinen der vorhandenen Slaves an den neuen Master reslaven können. Denken Sie daran, dass Sie keine Kontrolle über die Replikation haben. Dies macht die ganze Übung sinnlos - es sei denn, Ihr Master kann Ihren gesamten Datenverkehr aufnehmen. Nachdem Sie einen neuen Master heraufgestuft haben, können Sie kein Failover darauf durchführen, da er keine Slaves zur Verarbeitung Ihrer Last hat. Das Hochfahren neuer Slaves wird einige Zeit in Anspruch nehmen, da zuerst EBS-Snapshots erstellt werden müssen, was Stunden dauern kann. Dann müssen Sie die Infrastruktur aufwärmen, bevor Sie sie belasten können.
Mangelndes SUPER-Privileg
Wie wir bereits erwähnt haben, gewährt RDS Benutzern keine SUPER-Berechtigungen, und dies wird für jemanden ärgerlich, der daran gewöhnt ist, es auf MySQL zu haben. Gehen Sie davon aus, dass Sie in den ersten Wochen lernen werden, wie oft Sie Dinge tun müssen, die Sie eher häufig tun - wie z. B. das Beenden von Abfragen oder das Bedienen des Leistungsschemas. In RDS müssen Sie sich an eine vordefinierte Liste gespeicherter Prozeduren halten und diese verwenden, anstatt Dinge direkt zu tun. Sie können sie alle mit der folgenden Abfrage auflisten:
SELECT specific_name FROM information_schema.routines;Wie bei der Replikation werden eine Reihe von Aufgaben abgedeckt, aber wenn Sie in eine Situation geraten, die noch nicht abgedeckt ist, haben Sie Pech.
Interoperabilität und Hybrid-Cloud-Setups
Dies ist ein weiterer Bereich, in dem es RDS an Flexibilität mangelt. Nehmen wir an, Sie möchten ein gemischtes Cloud-/On-Premises-Setup aufbauen – Sie haben eine RDS-Infrastruktur und möchten ein paar Slaves vor Ort erstellen. Das Hauptproblem, mit dem Sie konfrontiert werden, besteht darin, dass es keine Möglichkeit gibt, Daten aus RDS zu verschieben, außer einen logischen Dump zu erstellen. Sie können Snapshots von RDS-Daten erstellen, haben aber keinen Zugriff darauf und können sie nicht von AWS entfernen. Sie haben auch keinen physischen Zugriff auf die Instanz, um xtrabackup, rsync oder sogar cp zu verwenden. Die einzige Möglichkeit für Sie ist die Verwendung von mysqldump, mydumper oder ähnlichen Tools. Dies erhöht die Komplexität (Zeichensatz- und Sortierungseinstellungen können Probleme verursachen) und ist zeitaufwändig (das Sichern und Laden von Daten mit logischen Sicherungswerkzeugen dauert lange).
Es ist möglich, die Replikation zwischen RDS und einer externen Instanz einzurichten (auf beide Arten, sodass die Migration von Daten in RDS ebenfalls möglich ist), aber es kann ein sehr zeitaufwändiger Prozess sein.
Wenn Sie andererseits in einer RDS-Umgebung bleiben und Ihre Infrastruktur über den Atlantik oder von der Ost- zur Westküste der USA erstrecken möchten, können Sie dies mit RDS tun – Sie können einfach eine Region auswählen, wenn Sie einen neuen Slave erstellen.
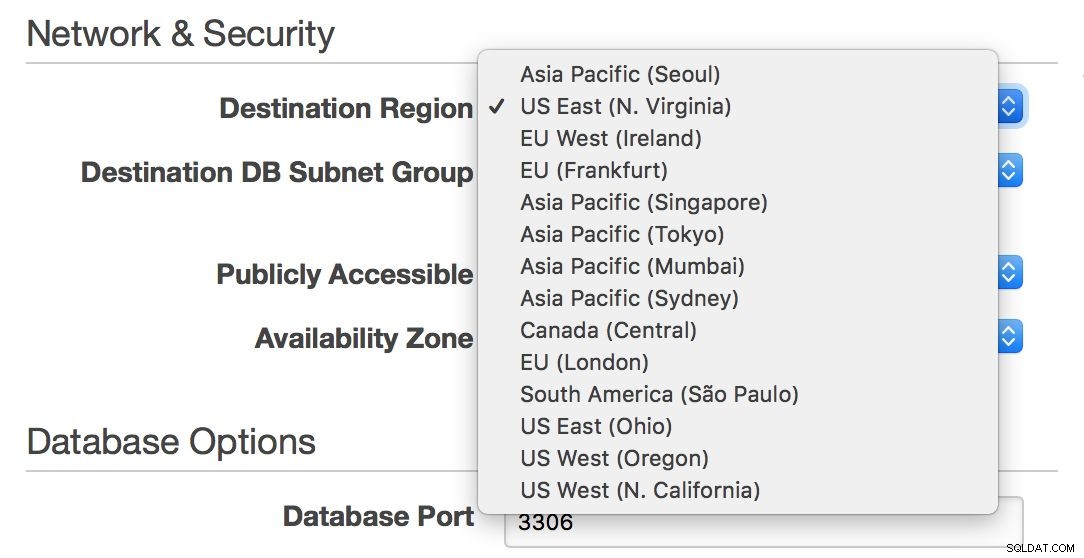
Wenn Sie Ihren Master von einer Region in die andere verschieben möchten, ist dies leider praktisch nicht ohne Ausfallzeit möglich – es sei denn, Ihr einzelner Knoten kann Ihren gesamten Datenverkehr bewältigen.
Sicherheit
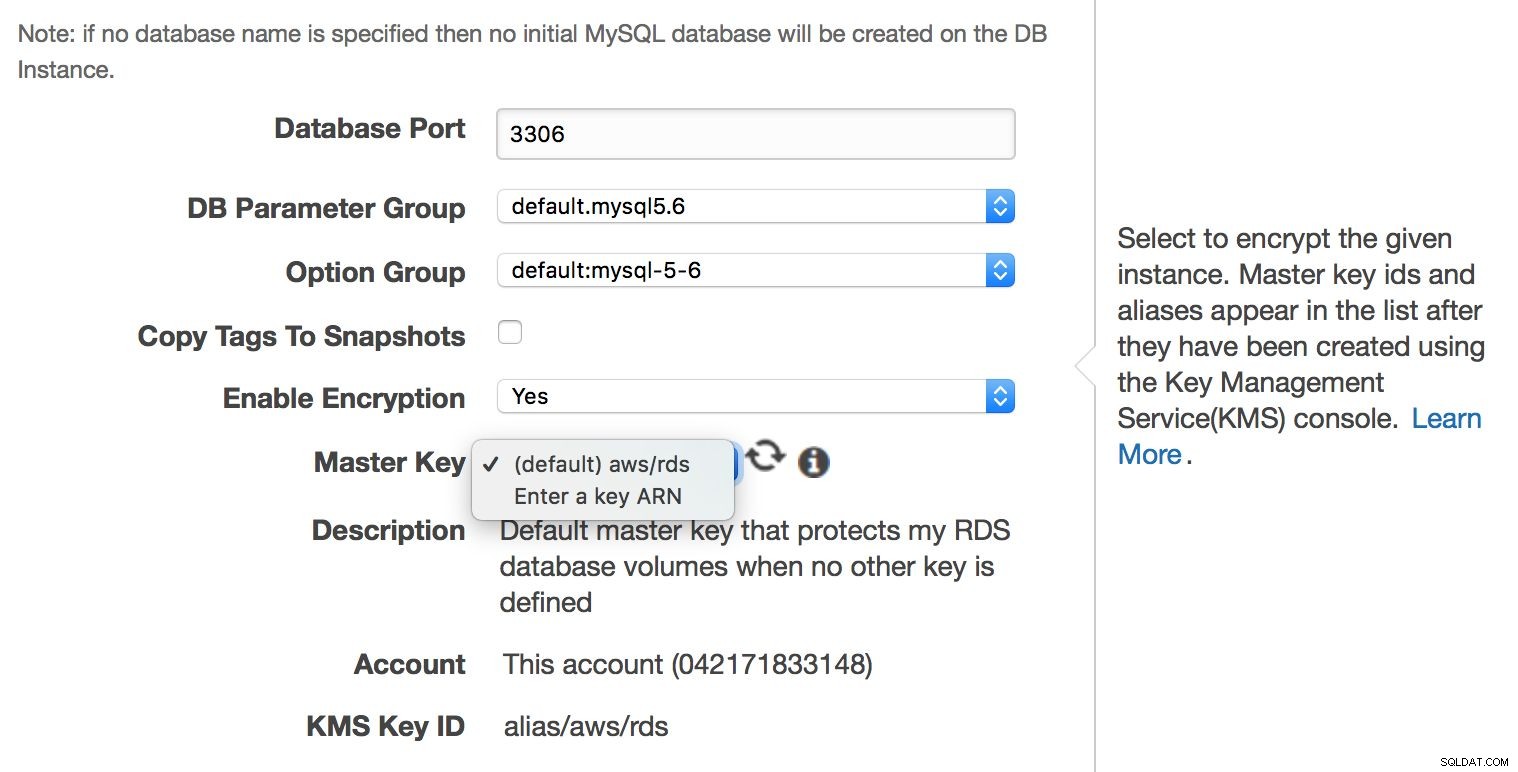
Obwohl MySQL RDS ein Managed Service ist, wird nicht jeder Sicherheitsaspekt von den Ingenieuren von Amazon betreut. Amazon nennt es „Shared Responsibility Model“. Kurz gesagt, Amazon kümmert sich um die Sicherheit der Netzwerk- und Speicherschicht (damit Daten sicher übertragen werden) und des Betriebssystems (Patches, Sicherheitsfixes). Andererseits muss sich der Benutzer um den Rest des Sicherheitsmodells kümmern. Stellen Sie sicher, dass der Datenverkehr zu und von der RDS-Instanz innerhalb der VPC begrenzt ist, stellen Sie sicher, dass die Authentifizierung auf Datenbankebene richtig erfolgt (keine passwortlosen MySQL-Benutzerkonten), überprüfen Sie, ob die API-Sicherheit gewährleistet ist (AMIs sind korrekt und mit minimal erforderlichen Berechtigungen eingestellt). Der Benutzer sollte sich auch um die Firewall-Einstellungen (Sicherheitsgruppen) kümmern, um die Gefährdung von RDS und der VPC, in der es sich befindet, gegenüber externen Netzwerken zu minimieren. Es liegt auch in der Verantwortung des Benutzers, die Verschlüsselung von ruhenden Daten zu implementieren – entweder auf Anwendungsebene oder auf Datenbankebene, indem er überhaupt eine verschlüsselte RDS-Instanz erstellt.
Die Verschlüsselung auf Datenbankebene kann nur bei der Instanzerstellung aktiviert werden, Sie können keine vorhandene, bereits laufende Datenbank verschlüsseln.
RDS-Einschränkungen
Wenn Sie RDS verwenden möchten oder bereits verwenden, müssen Sie sich der Einschränkungen bewusst sein, die mit MySQL RDS einhergehen.
Fehlende SUPER-Berechtigung kann, wie bereits erwähnt, sehr nervig sein. Während gespeicherte Prozeduren eine Reihe von Vorgängen erledigen, ist dies eine Lernkurve, da Sie lernen müssen, Dinge auf andere Weise zu tun. Das Fehlen der SUPER-Berechtigung kann auch zu Problemen bei der Verwendung externer Überwachungs- und Trending-Tools führen - es gibt immer noch einige Tools, die diese Berechtigung für einen Teil ihrer Funktionalität benötigen.
Der fehlende direkte Zugriff auf das MySQL-Datenverzeichnis und die Protokolle erschwert die Durchführung von Aktionen was sie betrifft. Hin und wieder kommt es vor, dass ein DBA Binärprotokolle analysieren oder Fehler, langsame Abfragen oder allgemeine Protokolle auswerten muss. Es ist zwar möglich, auf diese Protokolle auf RDS zuzugreifen, aber es ist umständlicher, als alles zu tun, was Sie brauchen, indem Sie sich bei der Shell auf dem MySQL-Host anmelden. Das lokale Herunterladen dauert auch einige Zeit und fügt bei allem, was Sie tun, zusätzliche Latenz hinzu.
Mangelnde Kontrolle über die Replikationstopologie, hohe Verfügbarkeit nur in Multi-AZ-Bereitstellungen. Da Sie keine Kontrolle über die Replikation haben, können Sie keinen Hochverfügbarkeitsmechanismus in Ihre Datenbankschicht implementieren. Es spielt keine Rolle, dass Sie mehrere Slaves haben, Sie können einige von ihnen nicht als Master-Kandidaten verwenden, denn selbst wenn Sie einen Slave zu einem Master befördern, gibt es keine Möglichkeit, die verbleibenden Slaves von diesem neuen Master zu versklaven. Dies zwingt Benutzer dazu, Multi-AZ-Bereitstellungen zu verwenden und die Kosten zu erhöhen (die „Schatteninstanz“ ist nicht kostenlos, der Benutzer muss dafür bezahlen).
Eingeschränkte Verfügbarkeit durch geplante Ausfallzeiten. Beim Bereitstellen einer RDS-Instanz müssen Sie ein wöchentliches Zeitfenster von 30 Minuten auswählen, in dem Wartungsvorgänge auf Ihrer RDS-Instanz ausgeführt werden können. Dies ist einerseits verständlich, da RDS ein Database as a Service ist, sodass Hardware- und Software-Upgrades Ihrer RDS-Instanzen von AWS-Ingenieuren verwaltet werden. Auf der anderen Seite verringert sich dadurch Ihre Verfügbarkeit, da Sie den Ausfall Ihrer Stammdatenbank für die Dauer des Wartungszeitraums nicht verhindern können. Auch in diesem Fall erhöht die Verwendung des Multi-AZ-Setups die Verfügbarkeit, da Änderungen zuerst auf der Schatteninstanz vorgenommen werden und dann ein Failover ausgeführt wird. Das Failover selbst ist jedoch nicht transparent, sodass Sie auf die eine oder andere Weise Betriebszeit verlieren. Dies zwingt Sie dazu, Ihre App unter Berücksichtigung unerwarteter MySQL-Master-Ausfälle zu entwerfen. Nicht, dass es ein schlechtes Designmuster wäre – Datenbanken können jederzeit abstürzen und Ihre Anwendung sollte so aufgebaut sein, dass sie selbst den schlimmsten Szenarien standhält. Es ist nur so, dass Sie mit RDS nur begrenzte Möglichkeiten für Hochverfügbarkeit haben.
Eingeschränkte Optionen für die Hochverfügbarkeitsimplementierung. Angesichts der mangelnden Flexibilität bei der Verwaltung der Replikationstopologie ist die Multi-AZ-Bereitstellung die einzige praktikable Hochverfügbarkeitsmethode. Diese Methode ist gut, aber es gibt Tools für die MySQL-Replikation, die die Ausfallzeit noch weiter minimieren würden. Beispielsweise können MHA oder ClusterControl bei Verwendung in Verbindung mit ProxySQL (unter bestimmten Bedingungen, wie z. B. dem Fehlen lang laufender Transaktionen) einen transparenten Failover-Prozess für die Anwendung bereitstellen. Während Sie RDS verwenden, können Sie diese Methode nicht verwenden.
Reduzierter Einblick in die Leistung Ihrer Datenbank. Während Sie Metriken von MySQL selbst erhalten können, reicht es manchmal einfach nicht aus, eine vollständige 10.000-Fuß-Ansicht der Situation zu erhalten. Irgendwann müssen sich die meisten Nutzer mit wirklich seltsamen Problemen auseinandersetzen, die durch fehlerhafte Hardware oder fehlerhafte Infrastruktur verursacht werden - verlorene Netzwerkpakete, abrupt beendete Verbindungen oder unerwartet hohe CPU-Auslastung. Wenn Sie Zugriff auf Ihren MySQL-Host haben, können Sie viele Tools nutzen, die Ihnen helfen, den Zustand eines Linux-Servers zu diagnostizieren. Bei der Verwendung von RDS sind Sie auf die Metriken beschränkt, die in Cloudwatch, dem Überwachungs- und Trending-Tool von Amazon, verfügbar sind. Für eine detailliertere Diagnose müssen Sie sich an den Support wenden und ihn bitten, das Problem zu überprüfen und zu beheben. Dies kann schnell gehen, aber es kann auch ein sehr langer Prozess mit viel Hin- und Her-E-Mail-Kommunikation sein.
Vendor-Lock-in, verursacht durch einen komplexen und zeitaufwändigen Prozess, Daten aus dem MySQL-RDS herauszuholen. RDS gewährt keinen Zugriff auf das MySQL-Datenverzeichnis, daher gibt es keine Möglichkeit, branchenübliche Tools wie xtrabackup zu verwenden, um Daten binär zu verschieben. Andererseits ist das RDS unter der Haube ein von Amazon gepflegtes MySQL, es ist schwer zu sagen, ob es zu 100% mit dem Upstream kompatibel ist oder nicht. RDS ist nur auf AWS verfügbar, sodass Sie keine hybride Einrichtung durchführen können.
Zusammenfassung
MySQL RDS hat sowohl Stärken als auch Schwächen. Dies ist ein sehr gutes Tool für diejenigen, die sich auf die Anwendung konzentrieren möchten, ohne sich um den Betrieb der Datenbank kümmern zu müssen. Sie stellen eine Datenbank bereit und beginnen mit der Ausgabe von Abfragen. Es ist nicht erforderlich, Backup-Skripte zu erstellen oder eine Überwachungslösung einzurichten, da dies bereits von AWS-Ingenieuren erledigt wird – Sie müssen es nur verwenden.
Es gibt auch eine dunkle Seite von MySQL RDS. Fehlende Optionen, um komplexere Setups und Skalierungen zu erstellen, die über das Hinzufügen weiterer Slaves hinausgehen. Mangelnde Unterstützung für eine bessere Hochverfügbarkeit als bei Multi-AZ-Bereitstellungen vorgeschlagen. Umständlicher Zugriff auf MySQL-Protokolle. Fehlender direkter Zugriff auf das MySQL-Datenverzeichnis und fehlende Unterstützung für physische Sicherungen, wodurch es schwierig wird, die Daten aus der RDS-Instanz zu verschieben.
Zusammenfassend lässt sich sagen, dass RDS für Sie gut funktionieren kann, wenn Sie die Benutzerfreundlichkeit der detaillierten Kontrolle der Datenbank vorziehen. Sie müssen bedenken, dass Sie irgendwann in der Zukunft aus MySQL RDS herauswachsen könnten. Wir sprechen hier nicht unbedingt nur von Leistung. Es geht mehr um den Bedarf Ihres Unternehmens an einer komplexeren Replikationstopologie oder um einen besseren Einblick in den Datenbankbetrieb, um schnell auf verschiedene Probleme reagieren zu können, die von Zeit zu Zeit auftreten. Wenn Ihr Datensatz bereits an Größe zugenommen hat, kann es in diesem Fall schwierig sein, aus dem RDS herauszukommen. Bevor Sie eine Entscheidung treffen, Ihre Daten in RDS zu verschieben, müssen Informationsmanager die Anforderungen und Einschränkungen ihrer Organisation in bestimmten Bereichen berücksichtigen.
In den nächsten Blogbeiträgen zeigen wir Ihnen, wie Sie Ihre Daten aus dem RDS an einen anderen Ort verschieben. Wir werden sowohl die Migration zu EC2 als auch zur lokalen Infrastruktur besprechen.