Vielleicht haben Sie im Zusammenhang mit der MySQL-Replikation schon von dem Begriff „Failover“ gehört. Vielleicht haben Sie sich gefragt, was es ist, als Sie Ihr Abenteuer mit Datenbanken beginnen. Vielleicht wissen Sie, was es ist, aber Sie sind sich nicht sicher, welche möglichen Probleme damit verbunden sind und wie sie gelöst werden können?
In diesem Blogbeitrag werden wir versuchen, Ihnen eine Einführung in die Failover-Behandlung in MySQL und MariaDB zu geben.
Wir werden diskutieren, was das Failover ist, warum es unvermeidlich ist, was der Unterschied zwischen Failover und Switchover ist. Wir werden den Failover-Prozess in der allgemeinsten Form besprechen. Wir werden auch ein wenig auf verschiedene Probleme eingehen, mit denen Sie sich in Bezug auf den Failover-Prozess befassen müssen.
Was bedeutet „Failover“?
Die MySQL-Replikation ist ein Kollektiv von Knoten, von denen jeder jeweils eine Rolle übernehmen kann. Es kann ein Master oder eine Replik werden. Es gibt zu einem bestimmten Zeitpunkt nur einen Master-Knoten. Dieser Knoten empfängt Schreibdatenverkehr und repliziert Schreibvorgänge an seine Replikate.
Wie Sie sich vorstellen können, ist der Master-Knoten als zentraler Einstiegspunkt für Daten in den Replikationscluster ziemlich wichtig. Was würde passieren, wenn es fehlschlägt und nicht mehr verfügbar ist?
Dies ist eine ziemlich ernste Bedingung für einen Replikationscluster. Es kann zu einem bestimmten Zeitpunkt keine Schreibvorgänge annehmen. Wie zu erwarten, muss eine der Repliken die Aufgaben des Masters übernehmen und mit der Annahme von Schreibvorgängen beginnen. Der Rest der Replikationstopologie muss möglicherweise ebenfalls geändert werden – verbleibende Replikate sollten ihren Master vom alten, ausgefallenen Knoten auf den neu gewählten ändern. Dieser Prozess des „Hochstufens“ eines Replikats zum Master, nachdem der alte Master ausgefallen ist, wird als „Failover“ bezeichnet.
Auf der anderen Seite findet eine „Umschaltung“ statt, wenn der Benutzer die Heraufstufung des Replikats auslöst. Ein neuer Master wird von einer Replik heraufgestuft, auf die der Benutzer zeigt, und der alte Master wird normalerweise zu einer Replik des neuen Masters.
Der wichtigste Unterschied zwischen „failover“ und „switchover“ ist der Zustand des alten Masters. Wenn ein Failover durchgeführt wird, ist der alte Master irgendwie nicht erreichbar. Es kann abgestürzt sein, es kann eine Netzwerkpartitionierung erlitten haben. Es kann zu einem bestimmten Zeitpunkt nicht verwendet werden und sein Status ist normalerweise unbekannt.
Auf der anderen Seite, wenn eine Umschaltung durchgeführt wird, lebt der alte Meister und ist gesund. Das hat schwerwiegende Folgen. Wenn ein Master nicht erreichbar ist, kann dies bedeuten, dass einige Daten noch nicht an die Slaves gesendet wurden (es sei denn, es wurde eine halbsynchrone Replikation verwendet). Einige der Daten wurden möglicherweise beschädigt oder teilweise gesendet.
Es gibt Mechanismen, um zu verhindern, dass solche Beschädigungen auf Slaves übertragen werden, aber der Punkt ist, dass einige der Daten während des Prozesses verloren gehen können. Andererseits ist bei einer Umschaltung der alte Master verfügbar und die Datenkonsistenz bleibt erhalten.
Failover-Prozess
Lassen Sie uns etwas Zeit damit verbringen, darüber zu diskutieren, wie genau der Failover-Prozess aussieht.
Master-Absturz erkannt
Zunächst einmal muss ein Master abstürzen, bevor das Failover durchgeführt wird. Sobald es nicht verfügbar ist, wird ein Failover ausgelöst. Bisher scheint es einfach, aber die Wahrheit ist, dass wir uns bereits auf rutschigem Boden befinden.
Zunächst einmal, wie wird die Master-Gesundheit getestet? Wird von einem Ort aus getestet oder werden die Tests verteilt? Versucht die Failover-Verwaltungssoftware nur, sich mit dem Master zu verbinden, oder implementiert sie erweiterte Überprüfungen, bevor der Ausfall des Masters erklärt wird?
Stellen wir uns folgende Topologie vor:
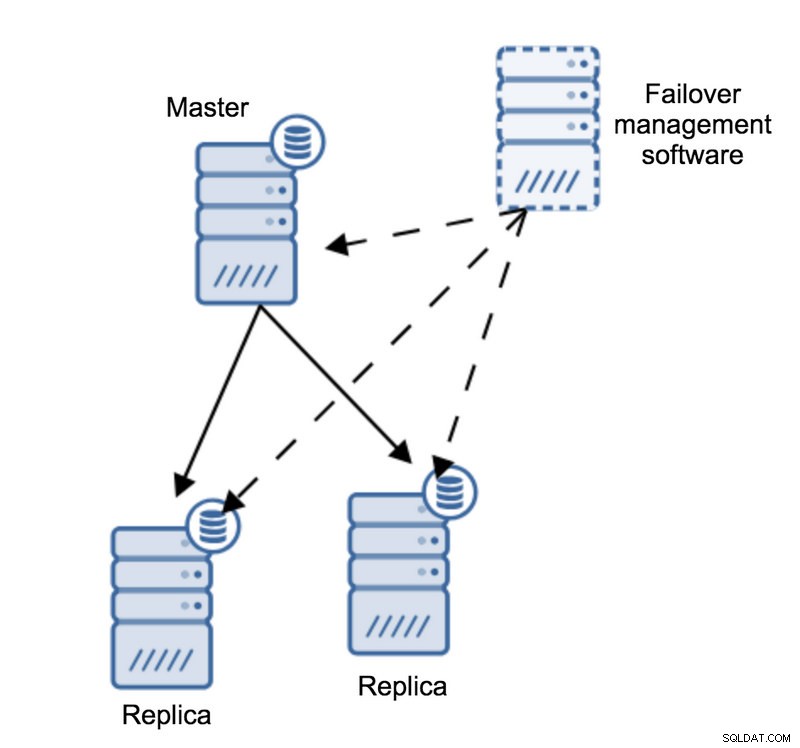
Wir haben einen Master und zwei Repliken. Wir haben auch eine Failover-Verwaltungssoftware, die sich auf einem externen Host befindet. Was würde passieren, wenn eine Netzwerkverbindung zwischen dem Host mit Failover-Software und dem Master ausfällt?
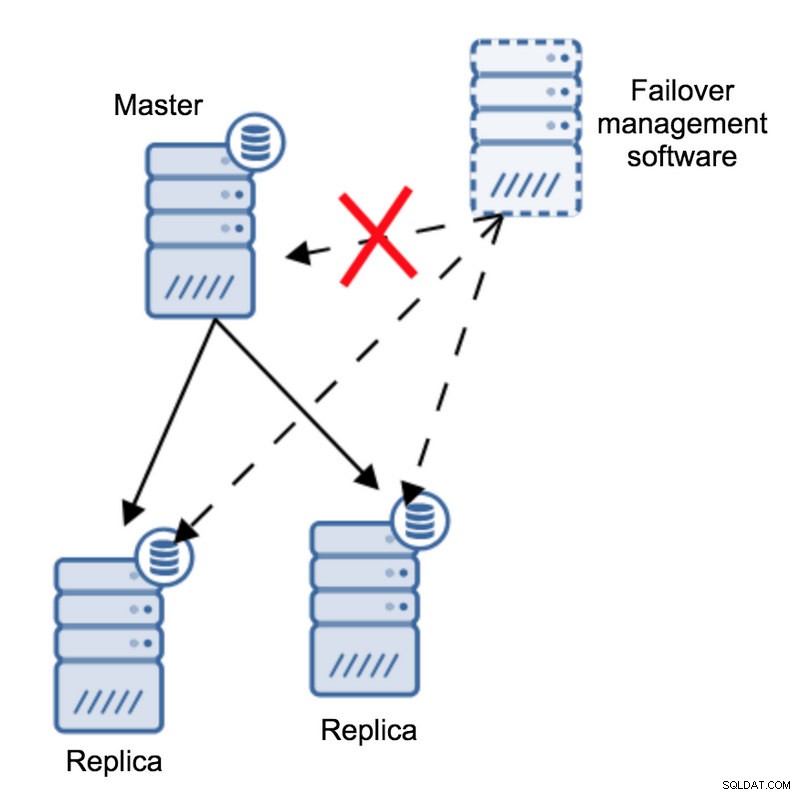
Laut der Failover-Verwaltungssoftware ist der Master abgestürzt – es besteht keine Verbindung zu ihm. Die Replikation selbst funktioniert jedoch einwandfrei. Was hier passieren sollte, ist, dass die Failover-Verwaltungssoftware versuchen würde, sich mit Replikaten zu verbinden und zu sehen, was deren Standpunkt ist.
Beschweren sie sich über eine fehlerhafte Replikation oder replizieren sie fröhlich?
Die Dinge können noch komplexer werden. Was wäre, wenn wir einen Proxy (oder eine Reihe von Proxys) hinzufügen würden? Es wird verwendet, um den Datenverkehr weiterzuleiten – Schreibvorgänge an den Master und Lesevorgänge an Replikate. Was ist, wenn ein Proxy nicht auf den Master zugreifen kann? Was ist, wenn keiner der Proxys auf den Master zugreifen kann?
Das bedeutet, dass die Anwendung unter diesen Bedingungen nicht funktionieren kann. Soll das Failover (eigentlich wäre es eher ein Switchover, da der Master technisch am Leben ist) ausgelöst werden?
Technisch gesehen ist der Master am Leben, kann aber von der Anwendung nicht verwendet werden. Hier muss die Geschäftslogik eingreifen und eine Entscheidung getroffen werden.
Verhindern, dass der alte Meister ausgeführt wird
Egal wie und warum, wenn es eine Entscheidung gibt, eine der Repliken zu einem neuen Master zu machen, muss der alte Master gestoppt werden und sollte im Idealfall nicht wieder starten können.
Wie dies erreicht werden kann, hängt von den Details der jeweiligen Umgebung ab; Daher wird dieser Teil des Failover-Prozesses üblicherweise durch externe Skripte verstärkt, die über verschiedene Hooks in den Failover-Prozess integriert werden.
Diese Skripte können so gestaltet werden, dass sie Tools verwenden, die in der jeweiligen Umgebung verfügbar sind, um den alten Master zu stoppen. Es kann ein CLI- oder API-Aufruf sein, der eine VM stoppt; es kann sich um Shell-Code handeln, der Befehle über eine Art „Lights-Out-Management“-Gerät ausführt; Es kann ein Skript sein, das SNMP-Traps an die Power Distribution Unit sendet, die die Steckdosen deaktivieren, die der alte Master verwendet (ohne Strom können wir sicher sein, dass er nicht wieder startet).
Wenn eine Failover-Verwaltungssoftware Teil eines komplexeren Produkts ist, das auch die Wiederherstellung von Knoten übernimmt (wie dies bei ClusterControl der Fall ist), kann der alte Master als von den Wiederherstellungsroutinen ausgeschlossen markiert werden.
Sie fragen sich vielleicht, warum es so wichtig ist, zu verhindern, dass der alte Master wieder verfügbar wird?
Das Hauptproblem besteht darin, dass in Replikationskonfigurationen nur ein Knoten für Schreibvorgänge verwendet werden kann. Typischerweise stellen Sie dies sicher, indem Sie eine read_only (und super_read_only, falls zutreffend) Variable auf allen Replikaten aktivieren und sie nur auf dem Master deaktiviert lassen.
Sobald ein neuer Master heraufgestuft wurde, ist read_only deaktiviert. Das Problem ist, dass wir, wenn der alte Master nicht verfügbar ist, ihn nicht zurück auf read_only=1 schalten können. Wenn MySQL oder ein Host abgestürzt ist, ist dies kein großes Problem, da es gute Praktiken ist, my.cnf mit dieser Einstellung zu konfigurieren, damit MySQL nach dem Start immer im Nur-Lese-Modus startet.
Das Problem zeigt sich, wenn es sich nicht um einen Absturz, sondern um ein Netzwerkproblem handelt. Der alte Master läuft immer noch mit read_only deaktiviert, er ist nur nicht verfügbar. Wenn Netzwerke konvergieren, erhalten Sie am Ende zwei beschreibbare Knoten. Dies kann ein Problem sein oder auch nicht. Einige der Proxys verwenden die read_only-Einstellung als Indikator dafür, ob ein Knoten ein Master oder ein Replikat ist. Wenn zu einem bestimmten Zeitpunkt zwei Master auftauchen, kann dies zu einem großen Problem führen, da Daten auf beide Hosts geschrieben werden, Replikate jedoch nur die Hälfte des Schreibverkehrs erhalten (der Teil, der den neuen Master trifft).
Manchmal geht es um fest codierte Einstellungen in einigen Skripten, die so konfiguriert sind, dass sie nur eine Verbindung zu einem bestimmten Host herstellen. Normalerweise würden sie scheitern und jemand würde bemerken, dass der Meister gewechselt hat.
Wenn der alte Master verfügbar ist, verbinden sie sich gerne damit, und es kommt zu Datenabweichungen. Wie Sie sehen können, ist das Sicherstellen, dass der alte Master nicht startet, ein Punkt mit ziemlich hoher Priorität.
Entscheiden Sie sich für einen Meisterkandidaten
Der alte Meister ist am Boden und wird nicht aus seinem Grab zurückkehren, jetzt ist es an der Zeit zu entscheiden, welchen Wirt wir als neuen Meister verwenden sollen. Normalerweise gibt es mehr als eine Replik zur Auswahl, also muss eine Entscheidung getroffen werden. Es gibt viele Gründe, warum ein Replikat einem anderen vorgezogen werden kann, daher müssen Kontrollen durchgeführt werden.
Weiße und schwarze Listen
Zunächst einmal kann ein Team, das Datenbanken verwaltet, seine Gründe haben, bei der Entscheidung über einen Master-Kandidaten eine Replik einer anderen vorzuziehen. Vielleicht verwendet es schwächere Hardware oder hat einen bestimmten Job, der ihm zugewiesen ist (dieses Replikat führt Backups aus, analytische Abfragen, Entwickler haben Zugriff darauf und führen benutzerdefinierte, handgemachte Abfragen aus). Vielleicht handelt es sich um eine Testreplik, bei der eine neue Version Abnahmetests unterzogen wird, bevor mit dem Upgrade fortgefahren wird. Die meisten Failover-Verwaltungsprogramme unterstützen White- und Blacklists, die verwendet werden können, um genau zu definieren, welche Replikate als Masterkandidaten verwendet werden sollen und welche nicht.
Halbsynchrone Replikation
Eine Replikationskonfiguration kann eine Mischung aus asynchronen und halbsynchronen Replikaten sein. Es gibt einen großen Unterschied zwischen ihnen – die halbsynchrone Replikation enthält garantiert alle Ereignisse des Masters. Ein asynchrones Replikat hat möglicherweise nicht alle Daten empfangen, sodass ein Failover zu einem Datenverlust führen kann. Wir würden eher sehen, dass halbsynchrone Replikate beworben werden.
Replikationsverzögerung
Auch wenn ein halbsynchrones Replikat alle Ereignisse enthält, befinden sich diese Ereignisse möglicherweise immer noch nur in Relay-Protokollen. Bei starkem Datenverkehr können alle Replikate, egal ob halbsynchron oder asynchron, Verzögerungen aufweisen.
Das Problem mit der Replikationsverzögerung besteht darin, dass Sie beim Heraufstufen einer Replik die Replikationseinstellungen zurücksetzen sollten, damit sie nicht versucht, eine Verbindung zum alten Master herzustellen. Dadurch werden auch alle Relay-Logs entfernt, auch wenn sie noch nicht angewendet wurden - was zu Datenverlust führt.
Auch wenn Sie die Replikationseinstellungen nicht zurücksetzen, können Sie immer noch keinen neuen Master für Verbindungen öffnen, wenn er nicht alle Ereignisse aus seinem Relay-Protokoll übernommen hat. Andernfalls riskieren Sie, dass die neuen Abfragen Transaktionen aus dem Relay-Log beeinflussen und alle möglichen Probleme auslösen (z. B. kann eine Anwendung einige Zeilen entfernen, auf die Transaktionen aus dem Relay-Log zugreifen).
Wenn man all dies berücksichtigt, besteht die einzig sichere Option darin, auf die Anwendung des Relaisprotokolls zu warten. Dennoch kann es eine Weile dauern, wenn die Replik stark verzögert war. Es müssen Entscheidungen darüber getroffen werden, welche Replik einen besseren Master abgeben würde – asynchron, aber mit geringer Verzögerung, oder halbsynchron, aber mit Verzögerung, deren Anwendung eine beträchtliche Zeit in Anspruch nehmen würde.
Fehlerhafte Transaktionen
Auch wenn Replikate nicht beschrieben werden sollten, kann es dennoch passieren, dass jemand (oder etwas) darauf geschrieben hat.
In der Vergangenheit war dies möglicherweise nur ein einzelner Transaktionsweg, aber es kann immer noch schwerwiegende Auswirkungen auf die Fähigkeit haben, ein Failover durchzuführen. Das Problem hängt eng mit der Global Transaction ID (GTID) zusammen, einer Funktion, die jeder Transaktion, die auf einem bestimmten MySQL-Knoten ausgeführt wird, eine eindeutige ID zuweist.
Heutzutage ist es ein ziemlich beliebtes Setup, da es ein hohes Maß an Flexibilität bietet und eine bessere Leistung ermöglicht (mit Multithread-Replikaten).
Das Problem ist, dass die GTID-Replikation beim erneuten Slaven an einen neuen Master erfordert, dass alle Ereignisse von diesem Master (die nicht auf dem Replikat ausgeführt wurden) auf das Replikat repliziert werden.
Betrachten wir das folgende Szenario:Irgendwann in der Vergangenheit wurde auf einer Replik geschrieben. Es ist lange her und dieses Ereignis wurde aus den Binärprotokollen der Replik gelöscht. Irgendwann ist ein Master ausgefallen und das Replikat wurde zum neuen Master ernannt. Alle verbleibenden Nachbildungen werden vom neuen Meister abgeführt. Sie werden nach Transaktionen fragen, die auf dem neuen Master ausgeführt werden. Es antwortet mit einer Liste von GTIDs, die vom alten Master stammten, und der einzelnen GTID, die sich auf diesen alten Schreibvorgang bezieht. GTIDs des alten Masters sind kein Problem, da alle verbleibenden Replikate zumindest die meisten davon enthalten (wenn nicht alle) und alle fehlenden Ereignisse aktuell genug sein sollten, um in den Binärprotokollen des neuen Masters verfügbar zu sein.
Im schlimmsten Fall werden einige fehlende Ereignisse aus den Binärprotokollen gelesen und auf Replikate übertragen. Das Problem liegt bei diesem alten Schreibvorgang - er ist nur auf einem neuen Master aufgetreten, während er noch ein Replikat war, und existiert daher nicht auf den verbleibenden Hosts. Es ist ein altes Ereignis, daher gibt es keine Möglichkeit, es aus Binärprotokollen abzurufen. Infolgedessen wird keine der Repliken in der Lage sein, sich vom neuen Meister abzusklaven. Die einzige Lösung besteht hier darin, eine manuelle Maßnahme zu ergreifen und allen Replikaten ein leeres Ereignis mit dieser problematischen GTID einzufügen. Dies bedeutet auch, dass die Replikate je nach Vorfall möglicherweise nicht mit dem neuen Master synchron sind.
Wie Sie sehen können, ist es sehr wichtig, fehlerhafte Transaktionen zu verfolgen und festzustellen, ob es sicher ist, eine bestimmte Replik zu einem neuen Master zu machen. Wenn es fehlerhafte Transaktionen enthält, ist es möglicherweise nicht die beste Option.
Failover-Behandlung für die Anwendung
Es ist wichtig zu bedenken, dass der Hauptschalter, ob erzwungen oder nicht, Auswirkungen auf die gesamte Topologie hat. Schreibvorgänge müssen auf einen neuen Knoten umgeleitet werden. Dies kann auf verschiedene Weise erfolgen, und es ist wichtig sicherzustellen, dass diese Änderung für die Anwendung so transparent wie möglich ist. In diesem Abschnitt sehen wir uns einige Beispiele an, wie das Failover für die Anwendung transparent gemacht werden kann.
DNS
Eine der Möglichkeiten, wie eine Anwendung auf einen Master verwiesen werden kann, ist die Verwendung von DNS-Einträgen. Mit niedriger TTL ist es möglich, die IP-Adresse zu ändern, auf die ein DNS-Eintrag wie „master.dc1.example.com“ zeigt. Eine solche Änderung kann durch externe Skripte erfolgen, die während des Failover-Prozesses ausgeführt werden.
Diensterkennung
Tools wie Consul oder etc.d können auch verwendet werden, um den Verkehr an einen richtigen Ort zu leiten. Solche Tools können Informationen darüber enthalten, dass die IP des aktuellen Masters auf einen bestimmten Wert eingestellt ist. Einige von ihnen bieten auch die Möglichkeit, Hostnamen-Lookups zu verwenden, um auf eine korrekte IP zu verweisen. Auch hier müssen Einträge in Service-Discovery-Tools gepflegt werden, und eine Möglichkeit, dies zu tun, besteht darin, diese Änderungen während des Failover-Prozesses vorzunehmen, indem Hooks verwendet werden, die in verschiedenen Phasen des Failover ausgeführt werden.
Proxy
Proxys können auch als Quelle der Wahrheit über die Topologie verwendet werden. Ganz allgemein gesagt, unabhängig davon, wie sie die Topologie ermitteln (es kann entweder ein automatischer Prozess sein oder der Proxy muss neu konfiguriert werden, wenn sich die Topologie ändert), sollten sie den aktuellen Status der Replikationskette enthalten, da dies sonst nicht möglich wäre Abfragen korrekt weiterleiten.
Der Ansatz, einen Proxy als Quelle der Wahrheit zu verwenden, kann in Verbindung mit dem Ansatz, Proxys auf Anwendungshosts zusammenzufassen, ziemlich üblich sein. Die Zusammenlegung von Proxy- und Webservern bietet zahlreiche Vorteile:schnelle und sichere Kommunikation über Unix-Socket, Beibehaltung einer Caching-Schicht (da einige der Proxys, wie ProxySQL, auch das Caching übernehmen können) in der Nähe der Anwendung. In einem solchen Fall ist es für die Anwendung sinnvoll, sich einfach mit dem Proxy zu verbinden und davon auszugehen, dass Abfragen korrekt weitergeleitet werden.
Failover in ClusterControl
ClusterControl wendet bewährte Verfahren der Branche an, um sicherzustellen, dass der Failover-Prozess korrekt durchgeführt wird. Es stellt auch sicher, dass der Prozess sicher ist – Standardeinstellungen sollen das Failover abbrechen, wenn mögliche Probleme erkannt werden. Diese Einstellungen können vom Benutzer außer Kraft gesetzt werden, wenn er Failover gegenüber Datensicherheit priorisieren möchte.
Sobald ein Master-Ausfall von ClusterControl erkannt wurde, wird ein Failover-Prozess initiiert und sofort ein erster Failover-Hook ausgeführt:

Als nächstes wird die Master-Verfügbarkeit getestet.

ClusterControl führt umfangreiche Tests durch, um sicherzustellen, dass der Master tatsächlich nicht verfügbar ist. Dieses Verhalten ist standardmäßig aktiviert und wird von der folgenden Variablen verwaltet:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Als nächster Schritt stellt ClusterControl sicher, dass der alte Master ausgefallen ist, und falls nicht, wird ClusterControl nicht versuchen, ihn wiederherzustellen:

Im nächsten Schritt muss bestimmt werden, welcher Host als Masterkandidat verwendet werden kann. ClusterControl prüft, ob eine Whitelist oder eine Blacklist definiert ist.
Sie können dies tun, indem Sie die folgenden Variablen in der cmon-Konfigurationsdatei verwenden:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Es ist auch möglich, ClusterControl so zu konfigurieren, dass nach Unterschieden in binären Protokollfiltern über alle Replikate hinweg gesucht wird. Dies kann mit der Variablen replication_check_binlog_filtration_bf_failover erfolgen. Standardmäßig sind diese Überprüfungen deaktiviert. ClusterControl überprüft auch, dass keine fehlerhaften Transaktionen vorhanden sind, die Probleme verursachen könnten.

Sie können ClusterControl auch bitten, Replikate automatisch neu zu erstellen, die nicht vom neuen Master repliziert werden können, indem Sie die folgende Einstellung in der cmon-Konfigurationsdatei verwenden:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
Danach wird ein zweites Skript ausgeführt:Es ist in der Einstellung replication_pre_failover_script definiert. Als nächstes durchläuft ein Kandidat einen Vorbereitungsprozess.


ClusterControl wartet darauf, dass Redo-Protokolle angewendet werden (um sicherzustellen, dass der Datenverlust minimal ist). Es prüft auch, ob andere Transaktionen auf verbleibenden Replikaten verfügbar sind, die nicht auf den Masterkandidaten angewendet wurden. Beide Verhaltensweisen können vom Benutzer gesteuert werden, indem die folgenden Einstellungen in der cmon-Konfigurationsdatei verwendet werden:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Wie Sie sehen können, können Sie ein Failover erzwingen, obwohl nicht alle Redo-Log-Ereignisse angewendet wurden – der Benutzer kann entscheiden, was die höhere Priorität hat – Datenkonsistenz oder Failover-Geschwindigkeit.


Schließlich wird der Master gewählt und das letzte Skript ausgeführt (ein Skript, das als replication_post_failover_script.
definiert werden kannWenn Sie ClusterControl noch nicht ausprobiert haben, empfehle ich Ihnen, es herunterzuladen (es ist kostenlos) und es auszuprobieren.
Master-Erkennung in ClusterControl
ClusterControl gibt Ihnen die Möglichkeit, einen vollständigen Hochverfügbarkeits-Stack bereitzustellen, einschließlich Datenbank- und Proxy-Ebenen. Die Master-Entdeckung ist immer eines der Probleme, mit denen man sich befassen muss.
Wie funktioniert es in ClusterControl?
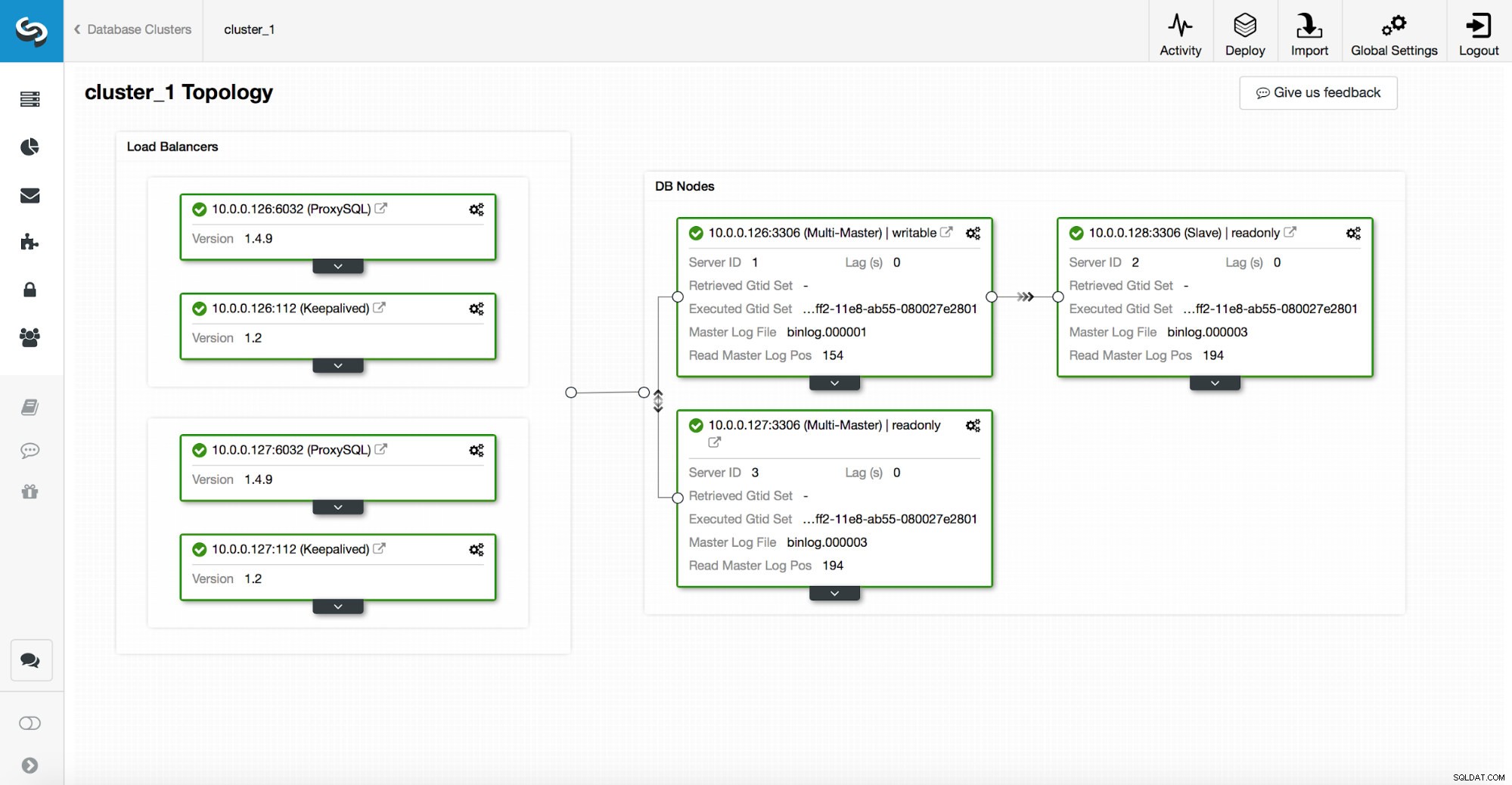
Ein Hochverfügbarkeitsstapel, der über ClusterControl bereitgestellt wird, besteht aus drei Teilen:
- Datenbankschicht
- Proxy-Schicht, die HAProxy oder ProxySQL sein kann
- Keepalived Layer, der bei Verwendung von Virtual IP eine hohe Verfügbarkeit des Proxy-Layers sicherstellt
Proxys verlassen sich auf Read_only-Variablen auf den Knoten.
Wie Sie im obigen Screenshot sehen können, ist nur ein Knoten in der Topologie als „beschreibbar“ markiert. Dies ist der Master und dies ist der einzige Knoten, der Schreibvorgänge erhält.
Ein Proxy (in diesem Beispiel ProxySQL) überwacht diese Variable und konfiguriert sich automatisch neu.
Auf der anderen Seite dieser Gleichung kümmert sich ClusterControl um Topologieänderungen:Failover und Umschaltungen. Es werden notwendige Änderungen am Read_only-Wert vorgenommen, um den Zustand der Topologie nach der Änderung widerzuspiegeln. Wenn ein neuer Master heraufgestuft wird, wird er zum einzigen beschreibbaren Knoten. Wenn nach dem Failover ein Master gewählt wird, ist read_only deaktiviert.
Auf der Proxy-Schicht wird Keepalived bereitgestellt. Es stellt einen VIP bereit und überwacht den Status der zugrunde liegenden Proxy-Knoten. VIP zeigt zu einem bestimmten Zeitpunkt auf einen Proxy-Knoten. Wenn dieser Knoten ausfällt, wird die virtuelle IP an einen anderen Knoten umgeleitet, wodurch sichergestellt wird, dass der an VIP gerichtete Datenverkehr einen fehlerfreien Proxy-Knoten erreicht.
Zusammenfassend stellt eine Anwendung über eine virtuelle IP-Adresse eine Verbindung zur Datenbank her. Diese IP zeigt auf einen der Proxys. Proxys leiten den Datenverkehr entsprechend der Topologiestruktur um. Informationen zur Topologie werden aus dem Read_only-Zustand abgeleitet. Diese Variable wird von ClusterControl verwaltet und auf der Grundlage der vom Benutzer angeforderten oder von ClusterControl automatisch durchgeführten Topologieänderungen gesetzt.