Wenn Sie mit einer Datenbank arbeiten müssen, mit der Sie nicht zu 100 % vertraut sind, können Sie von den Hunderten von verfügbaren Metriken überwältigt werden. Welche sind die wichtigsten? Was sollte ich überwachen und warum? Bei welchen Mustern in Metriken sollten einige Alarmglocken läuten? In diesem Blogbeitrag werden wir versuchen, Ihnen einige der wichtigsten Metriken vorzustellen, die Sie im Auge behalten sollten, während Sie MySQL oder MariaDB in der Produktion ausführen.
Com_* Statuszähler
Wir beginnen mit Com_*-Zählern – diese definieren die Anzahl und Art der Abfragen, die MySQL ausführt. Wir sprechen hier von Abfragetypen wie SELECT, INSERT, UPDATE und vielen mehr. Es ist sehr wichtig, diese im Auge zu behalten, da plötzliche Spitzen oder unerwartete Einbrüche darauf hindeuten können, dass etwas im System schief gelaufen ist.
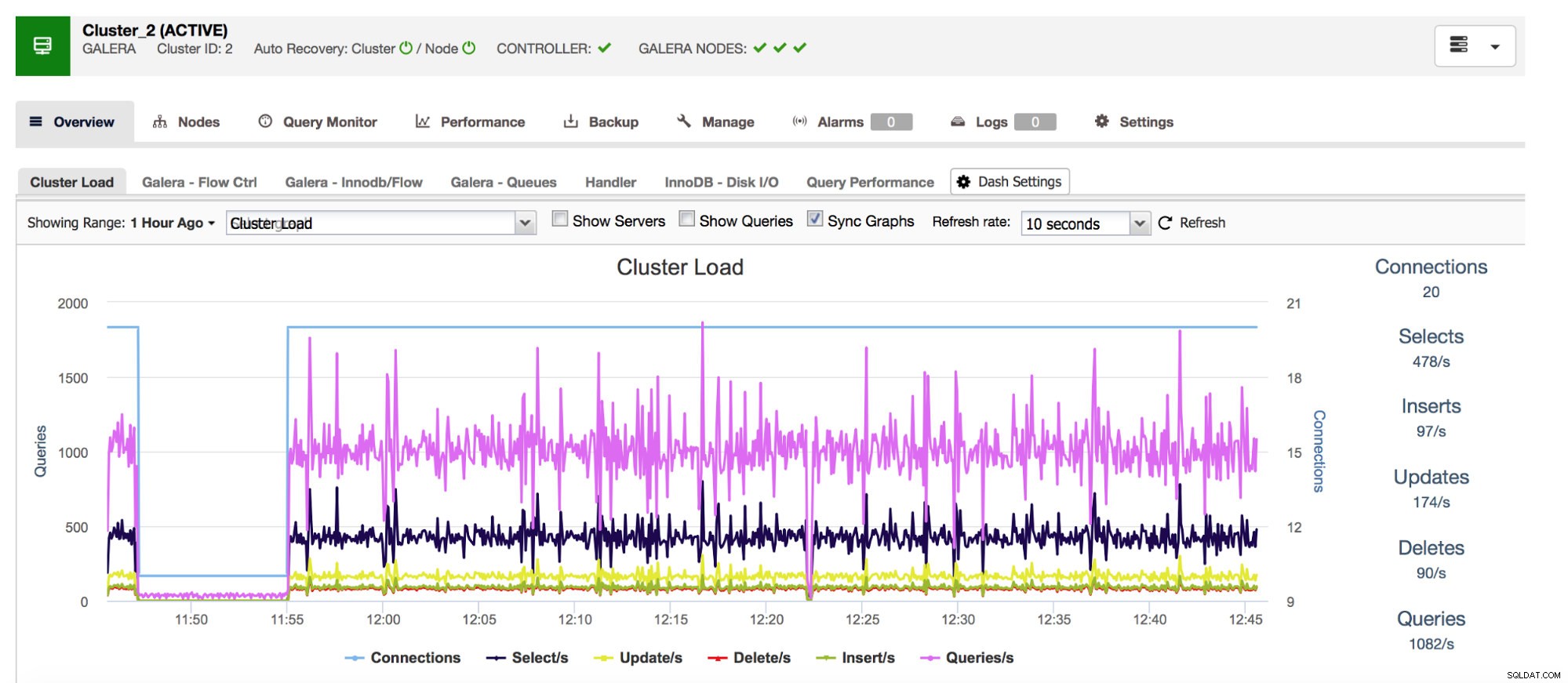
Unser allumfassendes Datenbankmanagementsystem ClusterControl zeigt Ihnen diese Daten zu den gängigsten Abfragetypen in der Rubrik „Übersicht“.
Handler_* Statuszähler
Eine Kategorie von Metriken, die Sie im Auge behalten sollten, sind Handler_*-Zähler in MySQL. Com_*-Zähler sagen Ihnen, welche Art von Abfragen Ihre MySQL-Instanz ausführt, aber ein SELECT kann sich völlig von einem anderen unterscheiden - SELECT könnte eine Primärschlüsselsuche sein, es kann auch ein Tabellenscan sein, wenn kein Index verwendet werden kann. Handler teilen Ihnen mit, wie MySQL auf gespeicherte Daten zugreift - dies ist sehr nützlich, um Leistungsprobleme zu untersuchen und zu beurteilen, ob es einen möglichen Gewinn bei der Überprüfung von Abfragen und zusätzlicher Indexierung gibt.
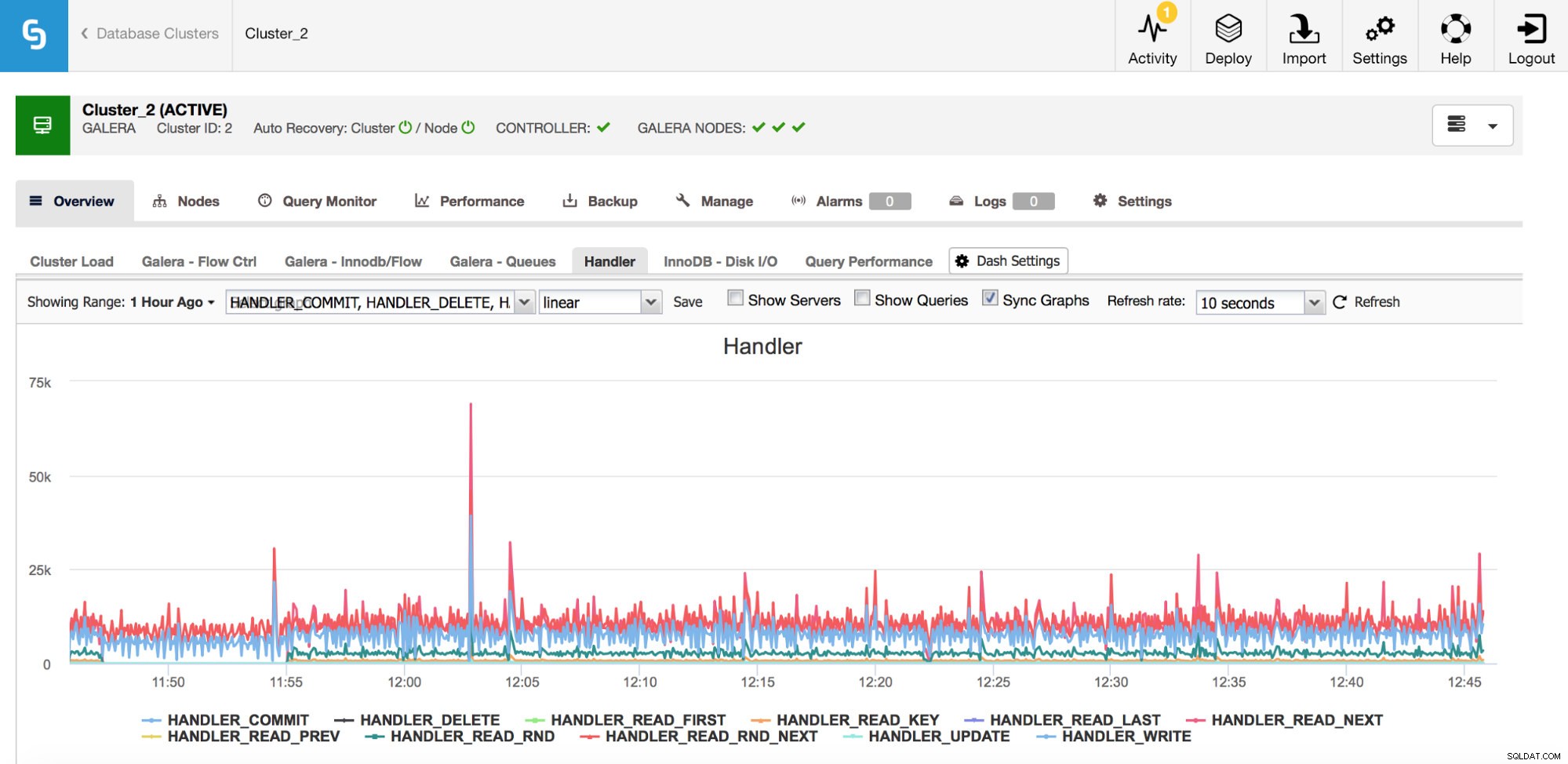
Wie Sie aus der obigen Grafik ersehen können, gibt es viele Metriken zu verfolgen (und ClusterControl stellt die wichtigsten grafisch dar) – wir werden hier nicht alle behandeln (Sie finden Beschreibungen in der MySQL-Dokumentation), aber wir möchten die hervorheben wichtigsten.
Handler_read_rnd_next – Immer wenn MySQL auf eine Zeile ohne Indexsuche in sequentieller Reihenfolge zugreift, wird dieser Zähler erhöht. Wenn in Ihrem Workload handler_read_rnd_next für einen hohen Prozentsatz des gesamten Datenverkehrs verantwortlich ist, bedeutet dies, dass Ihre Tabellen höchstwahrscheinlich einige zusätzliche Indizes verwenden könnten, da MySQL viele Tabellenscans durchführt.
Handler_read_next und handler_read_prev – diese beiden Zähler werden aktualisiert, wenn MySQL einen Index-Scan durchführt – vorwärts oder rückwärts. Handler_read_first und handler_read_last können etwas mehr Licht darauf werfen, welche Art von Index-Scans das sind - wenn wir von einem vollständigen Index-Scan (vorwärts oder rückwärts) sprechen, werden diese beiden Zähler aktualisiert.
Handler_read_key - dieser Zähler hingegen sagt Ihnen, wenn sein Wert hoch ist, dass Ihre Tabellen gut indiziert sind, da auf viele der Zeilen über eine Indexsuche zugegriffen wurde.
Replikationsverzögerung
Wenn Sie mit der MySQL-Replikation arbeiten, ist die Replikationsverzögerung eine Metrik, die Sie unbedingt überwachen möchten. Replikationsverzögerung ist unvermeidlich und Sie müssen damit umgehen, aber um damit fertig zu werden, müssen Sie verstehen, warum es passiert. Dafür ist der erste Schritt, zu wissen, _wann_ es aufgetaucht ist.
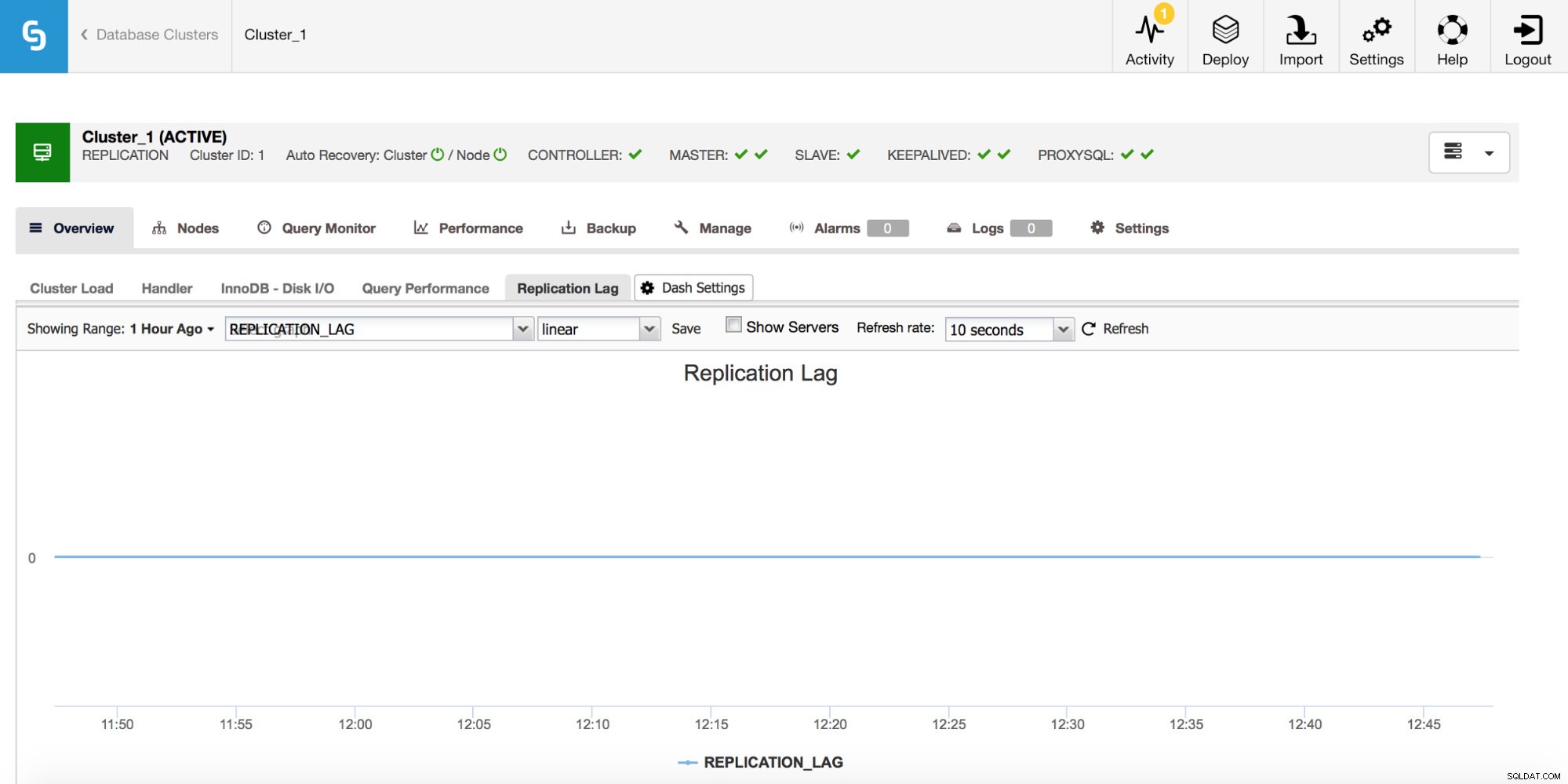
Wann immer Sie eine Spitze der Replikationsverzögerung sehen, sollten Sie andere Diagramme überprüfen, um weitere Hinweise zu erhalten – warum ist dies passiert? Was könnte es verursacht haben? Die Gründe können unterschiedlich sein – lange, schwere DMLs, eine deutliche Zunahme der Anzahl von DMLs, die in kurzer Zeit ausgeführt werden, CPU- oder E/A-Beschränkungen.
InnoDB-I/O
Es gibt eine Reihe wichtiger Metriken, die in Bezug auf die E/A überwacht werden müssen.
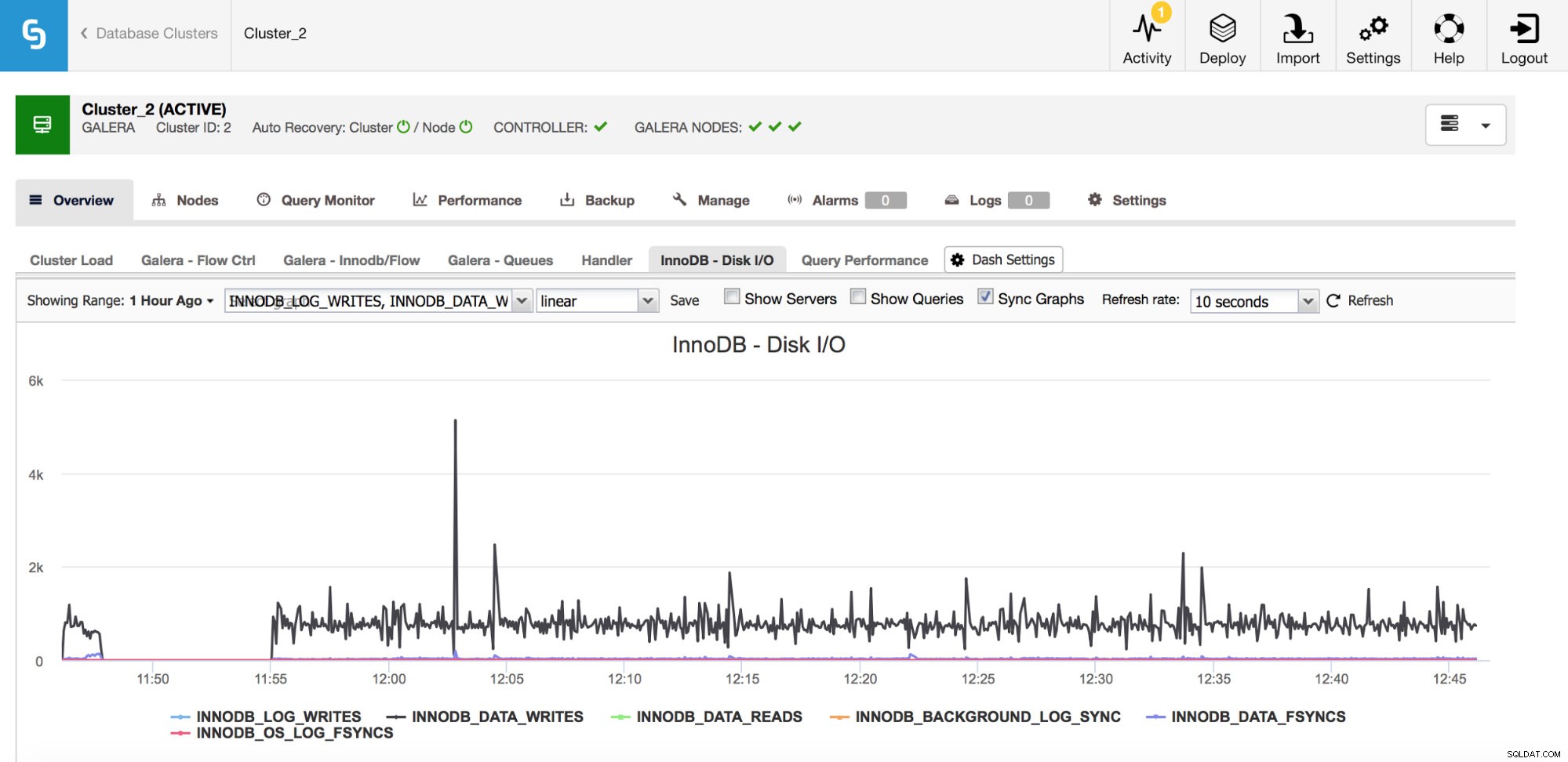
In der obigen Grafik sehen Sie einige Metriken, die Ihnen sagen, welche Art von I/O InnoDB ausführt – Datenschreib- und -lesevorgänge, Redo-Log-Schreibvorgänge, fsyncs. Diese Metriken helfen Ihnen beispielsweise bei der Entscheidung, ob die Replikationsverzögerung durch eine I/O-Spitze oder vielleicht aus einem anderen Grund verursacht wurde. Es ist auch wichtig, diese Metriken im Auge zu behalten und sie mit Ihren Hardwarebeschränkungen zu vergleichen. Wenn Sie sich den Hardwarebeschränkungen Ihrer Festplatten nähern, ist es vielleicht an der Zeit, dies zu untersuchen, bevor es schwerwiegendere Auswirkungen auf Ihre Datenbankleistung hat. P> Multiplenines DevOps-Leitfaden zur DatenbankverwaltungErfahren Sie, was Sie wissen müssen, um Ihre Open-Source-Datenbanken zu automatisieren und zu verwalten.Kostenlos herunterladen
Galera-Metriken – Flusskontrolle und Warteschlangen
Wenn Sie zufällig Galera Cluster verwenden (egal welche Variante Sie verwenden), gibt es ein paar weitere Metriken, die Sie genau überwachen sollten, diese sind etwas miteinander verbunden. Die erste davon sind Metriken, die sich auf die Flusskontrolle beziehen.
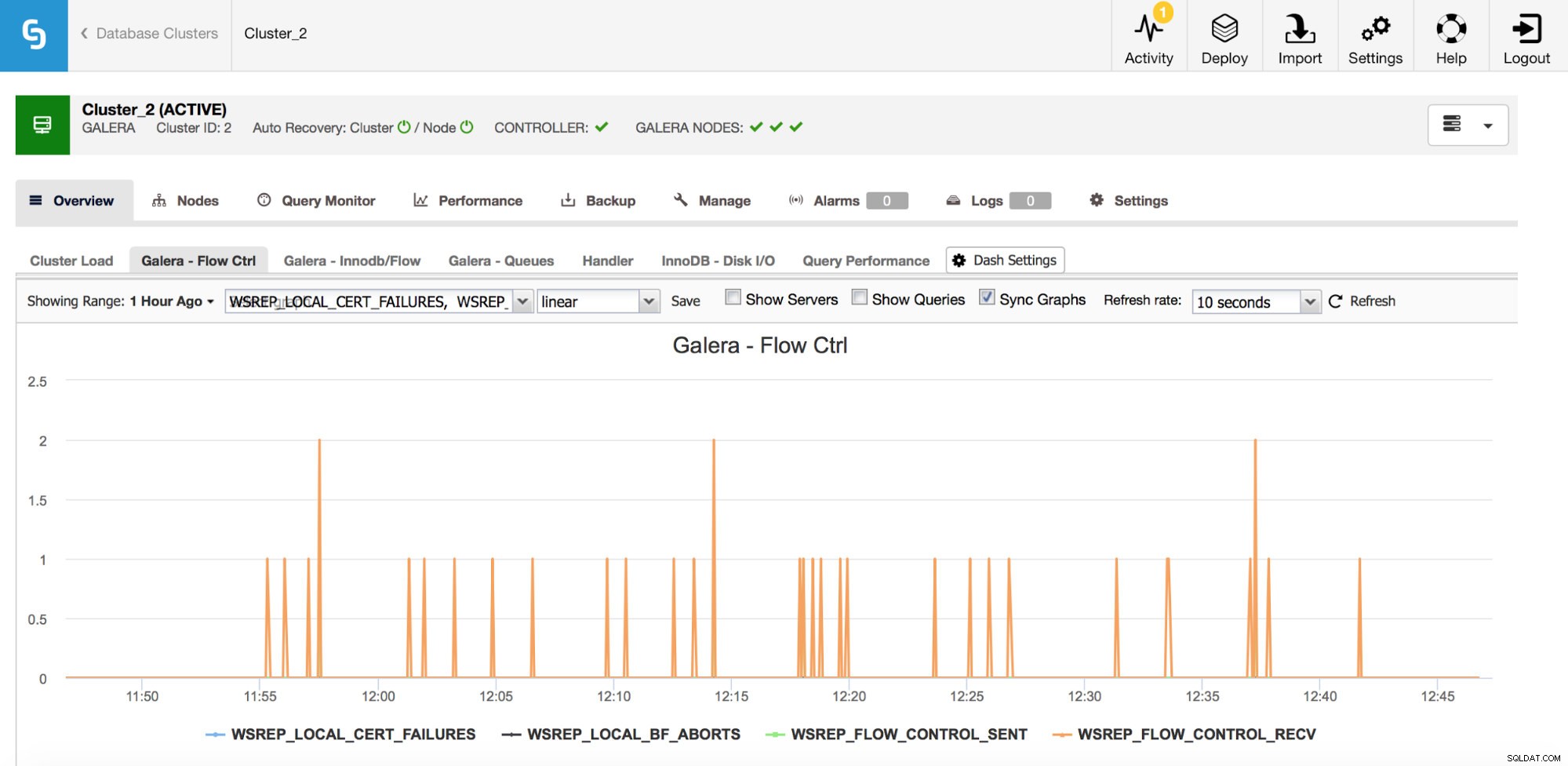
Die Flusssteuerung in Galera ist ein Mittel, um den Cluster synchron zu halten. Immer wenn ein Knoten ins Stocken gerät und nicht mit dem Rest des Clusters mithalten kann, beginnt er, Nachrichten zur Flusssteuerung zu senden, in denen er die verbleibenden Cluster-Knoten auffordert, langsamer zu werden. Dadurch kann es aufholen. Dadurch wird die Leistung des Clusters verringert, daher ist es wichtig, feststellen zu können, welcher Knoten wann mit dem Senden von Flusssteuerungsnachrichten begonnen hat. Dies kann einige der von Benutzern erlebten Verlangsamungen erklären oder das Zeitfenster und den Host für weitere Untersuchungen einschränken.
Die zweite zu überwachende Metrik betrifft die Sende- und Empfangswarteschlangen in Galera.
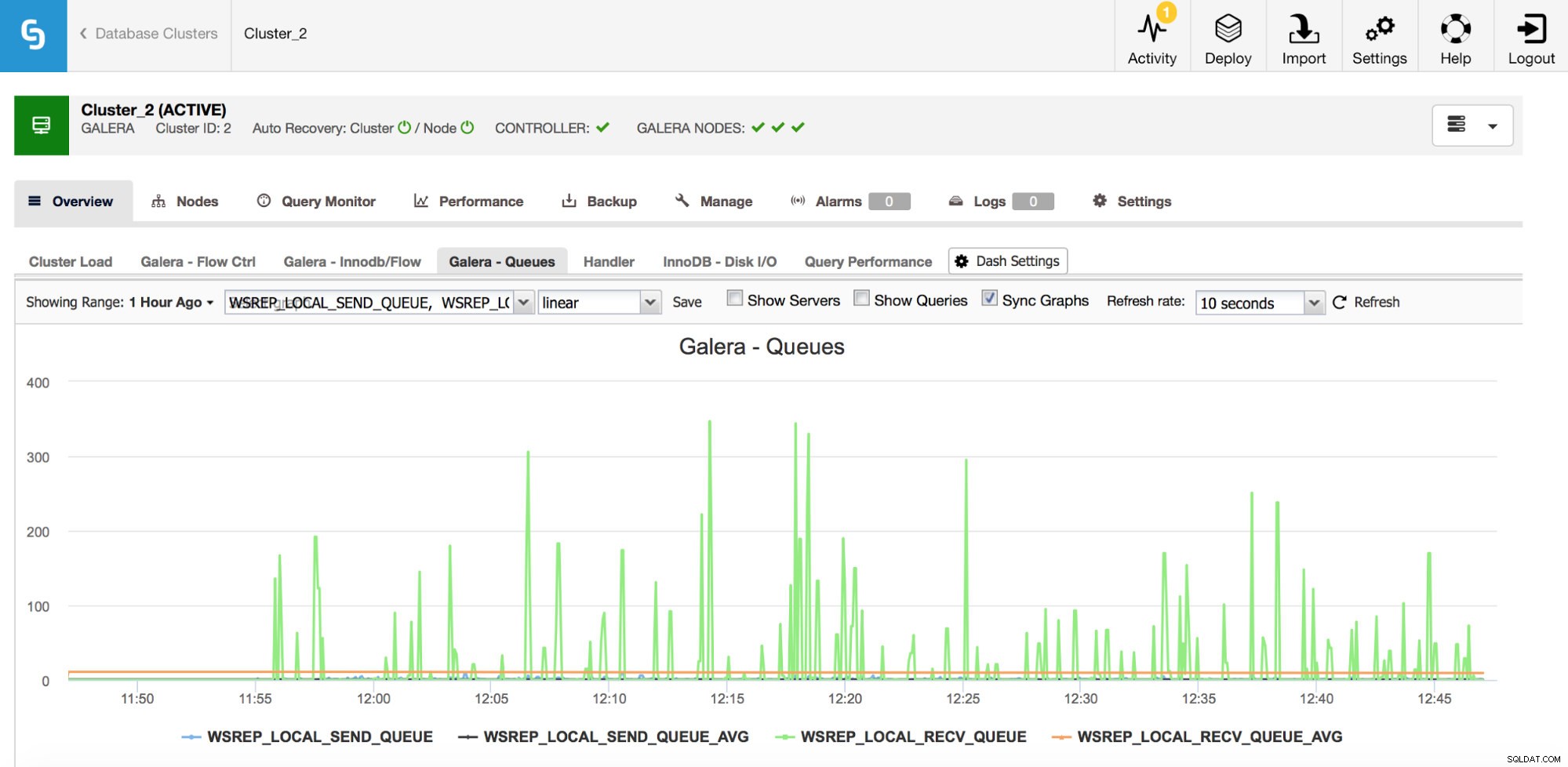
Galera-Knoten können Writesets (Transaktionen) zwischenspeichern, wenn sie nicht alle sofort anwenden können. Bei Bedarf können sie auch Schreibsätze zwischenspeichern, die an andere Knoten gesendet werden sollen (wenn ein bestimmter Knoten Schreibvorgänge von der Anwendung erhält). Beide Fälle sind Symptome einer Verlangsamung, die höchstwahrscheinlich dazu führen wird, dass Nachrichten zur Flusssteuerung gesendet werden, und einige Untersuchungen erfordern – warum ist es passiert, auf welchem Knoten, zu welcher Zeit?
Dies ist natürlich nur die Spitze des Eisbergs, wenn wir alle Metriken berücksichtigen, die MySQL zur Verfügung stellt - dennoch können Sie nichts falsch machen, wenn Sie sich zusätzlich zu den regulären Betriebssystem-/Hardware-Metriken wie CPU die hier behandelten ansehen , Arbeitsspeicher, Festplattenauslastung und Zustand der Dienste.