Python ist heutzutage sehr beliebt. Da Python eine Allzweck-Programmiersprache ist, kann sie auch zum Ausführen des ETL-Prozesses (Extract, Transform, Load) verwendet werden. Es stehen verschiedene ETL-Module zur Verfügung, aber heute bleiben wir bei der Kombination aus Python und MySQL. Wir verwenden Python, um gespeicherte Prozeduren aufzurufen und SQL-Anweisungen vorzubereiten und auszuführen.
Wir werden zwei ähnliche, aber unterschiedliche Ansätze verwenden. Zuerst rufen wir gespeicherte Prozeduren auf, die die ganze Aufgabe erledigen, und danach analysieren wir, wie wir denselben Prozess ohne gespeicherte Prozeduren ausführen könnten, indem wir MySQL-Code in Python verwenden.
Bereit? Bevor wir uns vertiefen, werfen wir einen Blick auf das Datenmodell – oder Datenmodelle, da es in diesem Artikel zwei davon gibt.
Die Datenmodelle
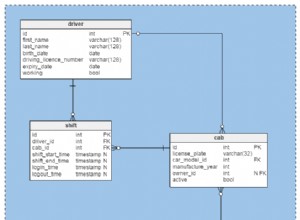
Wir benötigen zwei Datenmodelle, eines zum Speichern unserer Betriebsdaten und das andere zum Speichern unserer Berichtsdaten.
Das erste Modell ist im Bild oben dargestellt. Dieses Modell wird verwendet, um operative (Live-)Daten für ein abonnementbasiertes Geschäft zu speichern. Weitere Informationen zu diesem Modell finden Sie in unserem vorherigen Artikel Erstellen eines DWH, Teil 1:Ein Abonnement-Geschäftsdatenmodell.
Die Trennung von Betriebs- und Berichtsdaten ist normalerweise eine sehr kluge Entscheidung. Um diese Trennung zu erreichen, müssen wir ein Data Warehouse (DWH) erstellen. Das haben wir bereits getan; Sie können das Modell auf dem Bild oben sehen. Dieses Modell wird auch ausführlich im Beitrag Erstellen eines DWH, Teil 2:Ein Abonnement-Geschäftsdatenmodell beschrieben.
Schließlich müssen wir Daten aus der Live-Datenbank extrahieren, transformieren und in unser DWH laden. Wir haben dies bereits mit gespeicherten SQL-Prozeduren getan. Eine Beschreibung dessen, was wir erreichen möchten, sowie einige Codebeispiele finden Sie in Erstellen eines Data Warehouse, Teil 3:Ein Abonnement-Geschäftsdatenmodell.
Wenn Sie zusätzliche Informationen zu DWHs benötigen, empfehlen wir die Lektüre dieser Artikel:
- Das Sternenschema
- Das Snowflake-Schema
- Sternenschema vs. Schneeflockenschema.
Unsere Aufgabe heute ist es, die gespeicherten SQL-Prozeduren durch Python-Code zu ersetzen. Wir sind bereit, etwas Python-Magie zu machen. Beginnen wir damit, nur gespeicherte Prozeduren in Python zu verwenden.
Methode 1:ETL mit gespeicherten Prozeduren
Bevor wir mit der Beschreibung des Prozesses beginnen, ist es wichtig zu erwähnen, dass wir zwei Datenbanken auf unserem Server haben.
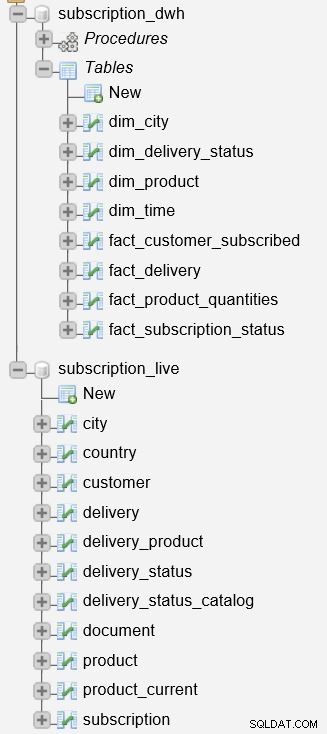
Der subscription_live Datenbank wird zum Speichern von Transaktions-/Live-Daten verwendet, während die subscription_dwh ist unsere Berichtsdatenbank (DWH).
Wir haben bereits die gespeicherten Prozeduren beschrieben, die zum Aktualisieren von Dimensions- und Faktentabellen verwendet werden. Sie lesen Daten aus subscription_live Datenbank, kombinieren Sie sie mit Daten in subscription_dwh Datenbank und fügen Sie neue Daten in subscription_dwh Datenbank. Diese beiden Verfahren sind:
p_update_dimensions– Aktualisiert die Dimensionstabellendim_timeunddim_city.p_update_facts– Aktualisiert zwei Faktentabellen,fact_customer_subscribedundfact_subscription_status.
Wenn Sie den vollständigen Code für diese Verfahren sehen möchten, lesen Sie Erstellen eines Data Warehouse, Teil 3:Ein Abonnement-Geschäftsdatenmodell.
Jetzt können wir ein einfaches Python-Skript schreiben, das eine Verbindung zum Server herstellt und den ETL-Prozess durchführt. Schauen wir uns zunächst das gesamte Skript an (etl_procedures.py ). Dann erklären wir die wichtigsten Teile.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Module importieren und mit der Datenbank verbinden
Python verwendet Module zum Speichern von Definitionen und Anweisungen. Sie können ein vorhandenes Modul verwenden oder Ihr eigenes schreiben. Die Verwendung vorhandener Module wird Ihr Leben vereinfachen, da Sie vorgefertigten Code verwenden, aber das Schreiben Ihres eigenen Moduls ist auch sehr nützlich. Wenn Sie den Python-Interpreter beenden und erneut ausführen, gehen zuvor definierte Funktionen und Variablen verloren. Natürlich möchten Sie nicht immer wieder denselben Code eingeben. Um dies zu vermeiden, könnten Sie Ihre Definitionen in einem Modul speichern und es in Python importieren.
Zurück zu etl_procedures.py . In unserem Programm beginnen wir mit dem Importieren von MySQL Connector:
# import MySQL connector import mysql.connector
MySQL Connector for Python wird als standardisierter Treiber verwendet, der eine Verbindung zu einem MySQL-Server/einer MySQL-Datenbank herstellt. Sie müssen es herunterladen und installieren, wenn Sie dies noch nicht getan haben. Neben der Verbindung zur Datenbank bietet es eine Reihe von Methoden und Eigenschaften für die Arbeit mit einer Datenbank. Wir werden einige davon verwenden, aber Sie können die vollständige Dokumentation hier einsehen.
Als nächstes müssen wir uns mit unserer Datenbank verbinden:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
Die erste Zeile stellt eine Verbindung zu einem Server her (in diesem Fall verbinde ich mich mit meinem lokalen Computer), wobei Ihre Anmeldeinformationen verwendet werden (ersetzen Sie
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Ich habe absichtlich nur eine Verbindung zu einem Server und nicht zu einer bestimmten Datenbank hergestellt, da ich zwei Datenbanken verwenden werde, die sich auf demselben Server befinden.
Der nächste Befehl – print – ist hier nur eine Benachrichtigung, dass wir erfolgreich verbunden wurden. Obwohl es keine Bedeutung für die Programmierung hat, könnte es zum Debuggen des Codes verwendet werden, wenn im Skript etwas schief gelaufen ist.
Die letzte Zeile in diesem Teil lautet:
cursor =connection.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Aufrufverfahren
Der vorherige Teil war allgemein gehalten und konnte für andere datenbankbezogene Aufgaben verwendet werden. Der folgende Teil des Codes ist speziell für ETL:Aufrufen unserer gespeicherten Prozeduren mit cursor.callproc Befehl. Es sieht so aus:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Aufrufverfahren sind ziemlich selbsterklärend. Nach jedem Aufruf wurde ein Druckbefehl hinzugefügt. Auch dies gibt uns nur eine Benachrichtigung, dass alles in Ordnung gelaufen ist.
Übernehmen und schließen
Der letzte Teil des Skripts schreibt die Datenbankänderungen fest und schließt alle verwendeten Objekte:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Aufrufverfahren sind ziemlich selbsterklärend. Nach jedem Aufruf wurde ein Druckbefehl hinzugefügt. Auch dies gibt uns nur eine Benachrichtigung, dass alles in Ordnung gelaufen ist.
Engagement ist hier unerlässlich; ohne sie werden keine Änderungen an der Datenbank vorgenommen, selbst wenn Sie eine Prozedur aufgerufen oder eine SQL-Anweisung ausgeführt haben.
Das Skript ausführen
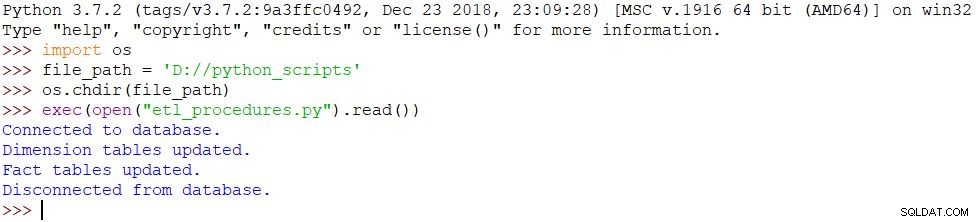
Als letztes müssen wir unser Skript ausführen. Dazu verwenden wir die folgenden Befehle in der Python-Shell:
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())Das Skript wird ausgeführt und alle Änderungen werden entsprechend in der Datenbank vorgenommen. Das Ergebnis ist im Bild unten zu sehen.
Methode 2:ETL mit Python und MySQL
Der oben vorgestellte Ansatz unterscheidet sich nicht wesentlich von dem Ansatz, Stored Procedures direkt in MySQL aufzurufen. Der einzige Unterschied besteht darin, dass wir jetzt ein Skript haben, das die ganze Arbeit für uns erledigt.
Wir könnten einen anderen Ansatz verwenden:Alles in das Python-Skript einfügen. Wir fügen Python-Anweisungen hinzu, bereiten aber auch SQL-Abfragen vor und führen sie in der Datenbank aus. Die Quelldatenbank (live) und die Zieldatenbank (DWH) sind die gleichen wie im Beispiel mit gespeicherten Prozeduren.
Bevor wir uns damit befassen, werfen wir einen Blick auf das vollständige Skript (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Module importieren und mit der Datenbank verbinden
Noch einmal müssen wir MySQL mit dem folgenden Code importieren:
import mysql.connector
Wir importieren auch das datetime-Modul, wie unten gezeigt. Wir brauchen dies für datumsbezogene Operationen in Python:
from datetime import date
Der Vorgang zum Herstellen einer Verbindung zur Datenbank ist derselbe wie im vorherigen Beispiel.
Aktualisieren der dim_time-Dimension
Zum Aktualisieren der dim_time Tabelle müssen wir überprüfen, ob der Wert (für gestern) bereits in der Tabelle enthalten ist. Dazu müssen wir die Datumsfunktionen von Python (anstelle von SQL) verwenden:
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
Die erste Codezeile gibt das gestrige Datum in der Datumsvariablen zurück, während die zweite Zeile diesen Wert als Zeichenfolge speichert. Wir benötigen dies als Zeichenfolge, da wir es mit einer anderen Zeichenfolge verketten, wenn wir die SQL-Abfrage erstellen.
Als Nächstes müssen wir testen, ob dieses Datum bereits in dim_time Tisch. Nachdem wir einen Cursor deklariert haben, bereiten wir die SQL-Abfrage vor. Um die Abfrage auszuführen, verwenden wir cursor.execute Befehl:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
Wir speichern das Abfrageergebnis im Ergebnis Variable. Das Ergebnis hat entweder 0 oder 1 Zeile, sodass wir die erste Spalte der ersten Zeile testen können. Es enthält entweder eine 0 oder eine 1. (Denken Sie daran, dass wir dasselbe Datum nur einmal in einer Dimensionstabelle haben können.)
Wenn das Datum noch nicht in der Tabelle enthalten ist, bereiten wir die Zeichenfolgen vor, die Teil der SQL-Abfrage sein werden:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Schließlich erstellen wir eine Abfrage und führen sie aus. Dadurch wird dim_time Tabelle, nachdem sie festgeschrieben wurde. Bitte beachten Sie, dass ich den vollständigen Pfad zur Tabelle verwendet habe, einschließlich des Datenbanknamens (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
Aktualisieren Sie die dim_city-Dimension
Aktualisieren von dim_city table ist sogar noch einfacher, weil wir vor dem Einfügen nichts testen müssen. Wir werden diesen Test tatsächlich in die SQL-Abfrage aufnehmen.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Hier bereiten wir die SQL-Abfrage vor und führen sie aus. Beachten Sie, dass ich wieder die vollständigen Pfade zu Tabellen verwendet habe, einschließlich der Namen beider Datenbanken (subscription_live und subscription_dwh ).
Aktualisierung der Faktentabellen
Als letztes müssen wir unsere Faktentabellen aktualisieren. Der Prozess ist fast derselbe wie beim Aktualisieren von Dimensionstabellen:Wir bereiten Abfragen vor und führen sie aus. Diese Abfragen sind viel komplexer, aber sie sind dieselben, die in den gespeicherten Prozeduren verwendet werden.
Wir haben eine Verbesserung gegenüber den gespeicherten Prozeduren hinzugefügt:das Löschen der vorhandenen Daten für dasselbe Datum in der Faktentabelle. Dadurch können wir ein Skript mehrmals für dasselbe Datum ausführen. Am Ende müssen wir die Transaktion festschreiben und alle Objekte und die Verbindung schließen.
Das Skript ausführen
Wir haben eine kleine Änderung in diesem Teil, die ein anderes Skript aufruft:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
Da wir dieselben Nachrichten verwendet haben und das Skript erfolgreich abgeschlossen wurde, ist das Ergebnis dasselbe:
Wie würden Sie Python in ETL verwenden?
Heute haben wir ein Beispiel für die Durchführung des ETL-Prozesses mit einem Python-Skript gesehen. Es gibt andere Möglichkeiten, dies zu tun, z. eine Reihe von Open-Source-Lösungen, die Python-Bibliotheken verwenden, um mit Datenbanken zu arbeiten und den ETL-Prozess durchzuführen. Im nächsten Artikel werden wir mit einem von ihnen spielen. In der Zwischenzeit können Sie gerne Ihre Erfahrungen mit Python und ETL teilen.