Die meisten OLTP-Arbeitslasten umfassen eine zufällige Festplatten-E/A-Nutzung. In dem Wissen, dass Festplatten (einschließlich SSD) langsamer sind als die Verwendung von RAM, verwenden Datenbanksysteme Caching, um die Leistung zu steigern. Beim Caching geht es darum, Daten im Arbeitsspeicher (RAM) für einen schnelleren Zugriff zu einem späteren Zeitpunkt zu speichern.
PostgreSQL nutzt auch das Caching seiner Daten in einem Bereich namens shared_buffers. In diesem Blog werden wir diese Funktion untersuchen, um Ihnen bei der Leistungssteigerung zu helfen.
Grundlagen des PostgreSQL-Cachings
Bevor wir uns eingehender mit dem Konzept des Cachings befassen, wollen wir die Grundlagen etwas auffrischen.
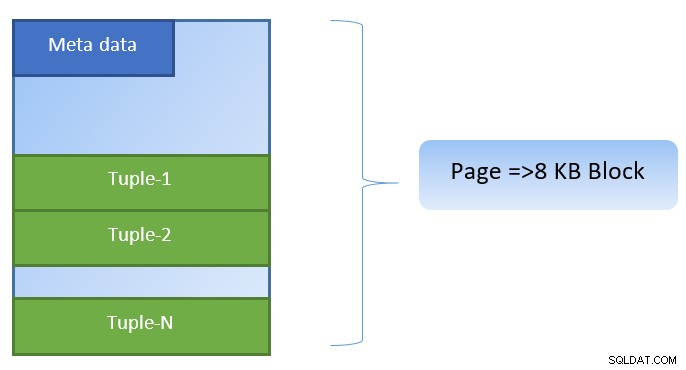
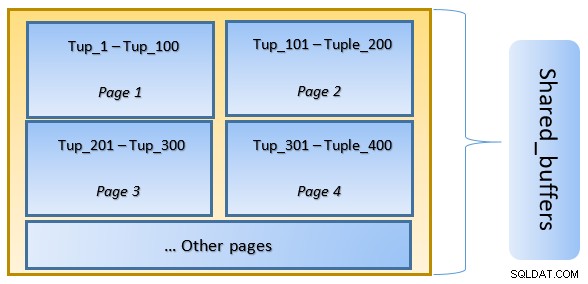
In PostgreSQL sind Daten in Form von Seiten mit einer Größe von 8 KB organisiert, und jede dieser Seiten kann mehrere Tupel enthalten (abhängig von der Größe des Tupels). Eine vereinfachte Darstellung könnte wie folgt aussehen:
PostgreSQL speichert Folgendes zur Beschleunigung des Datenzugriffs:
- Daten in Tabellen
- Indizes
- Abfrageausführungspläne
Während das Caching des Abfrageausführungsplans darauf ausgerichtet ist, CPU-Zyklen zu sparen; Caching für Tabellendaten und Indexdaten konzentriert sich darauf, kostspielige Festplatten-E/A-Operationen einzusparen.
Bei PostgreSQL können Benutzer definieren, wie viel Speicher sie reservieren möchten, um einen solchen Cache für Daten zu halten. Die relevante Einstellung ist shared_buffers in der Konfigurationsdatei postgresql.conf. Der endliche Wert von shared_buffers definiert, wie viele Seiten zu einem beliebigen Zeitpunkt zwischengespeichert werden können.
Während eine Abfrage ausgeführt wird, sucht PostgreSQL nach der Seite auf der Festplatte, die das relevante Tupel enthält, und schiebt es für den seitlichen Zugriff in den shared_buffers-Cache. Wenn das nächste Mal auf dasselbe Tupel (oder ein beliebiges Tupel auf derselben Seite) zugegriffen werden muss, kann PostgreSQL Festplatten-IO sparen, indem es es im Speicher liest.
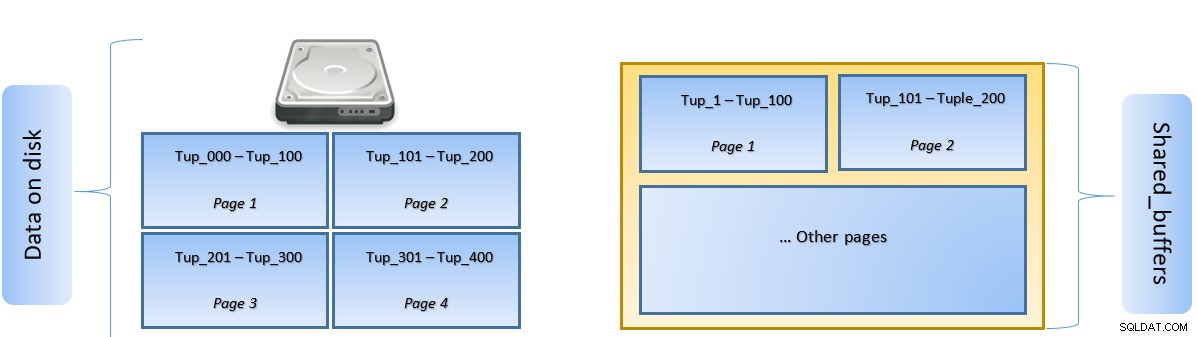
In der obigen Abbildung Seite-1 und Seite-2 einer bestimmten Tabelle wurden zwischengespeichert. Falls eine Benutzerabfrage auf Tupel zwischen Tuple-1 bis Tuple-200 zugreifen muss, kann PostgreSQL sie selbst aus dem RAM abrufen.
Wenn die Abfrage jedoch auf die Tupel 250 bis 350 zugreifen muss, muss sie Festplatten-E/A für Seite 3 und Seite 4 ausführen. Jeder weitere Zugriff für Tupel 201 bis 400 wird aus dem Cache und abgerufen Festplatten-E/A wird nicht benötigt – wodurch die Abfrage schneller wird.
Auf hoher Ebene folgt PostgreSQL dem LRU-Algorithmus (zuletzt verwendet). Identifizieren Sie die Seiten, die aus dem Cache entfernt werden müssen. Mit anderen Worten, eine Seite, auf die nur einmal zugegriffen wird, hat höhere Chancen auf Räumung (im Vergleich zu einer Seite, auf die mehrmals zugegriffen wird), falls eine neue Seite von PostgreSQL in den Cache geholt werden muss.
PostgreSQL-Caching in Aktion
Lassen Sie uns ein Beispiel ausführen und sehen, wie sich der Cache auf die Leistung auswirkt.
Starten Sie PostgreSQL, wobei shared_buffer standardmäßig auf 128 MB eingestellt bleibt
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startVerbinden Sie sich mit dem Server und erstellen Sie eine Dummy-Tabelle tblDummy und einen Index auf c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Dummy-Daten mit 200.000 Tupeln füllen, sodass es 10.000 eindeutige p_id und für jede p_id 200 c_id gibt
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Starten Sie den Server neu, um den Cache zu leeren. Führen Sie nun eine Abfrage aus und überprüfen Sie die Zeit, die für die Ausführung derselben benötigt wird
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msÜberprüfe dann die von der Platte gelesenen Blöcke
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0Im obigen Beispiel wurden 1000 Blöcke von der Festplatte gelesen, um Zähltupel zu finden, bei denen c_id =1. Es dauerte 160 ms, da Festplatten-E/A beteiligt war, um diese Datensätze von der Festplatte abzurufen.
Die Ausführung ist schneller, wenn dieselbe Abfrage erneut ausgeführt wird, da sich zu diesem Zeitpunkt alle Blöcke noch im Cache des PostgreSQL-Servers befinden
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msund Blöcke, die von der Festplatte vs. aus dem Cache gelesen werden
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Aus obigem ist ersichtlich, dass, da alle Blöcke aus dem Cache gelesen wurden, keine Festplatten-E/A erforderlich war. Dadurch ergaben sich auch die Ergebnisse schneller.
Festlegen der Größe des PostgreSQL-Cache
Die Größe des Caches muss in einer Produktionsumgebung entsprechend der verfügbaren RAM-Menge sowie den auszuführenden Abfragen angepasst werden.
Als Beispiel – shared_buffer von 128 MB reicht möglicherweise nicht aus, um alle Daten zwischenzuspeichern, wenn die Abfrage mehr Tupel abrufen sollte:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Ändern Sie den shared_buffer auf 1024 MB, um den heap_blks_hit zu erhöhen.
Tatsächlich kann unter Berücksichtigung der Abfragen (basierend auf c_id) im Falle einer Reorganisation der Daten auch mit einem kleineren shared_buffer eine bessere Cache-Trefferquote erreicht werden.
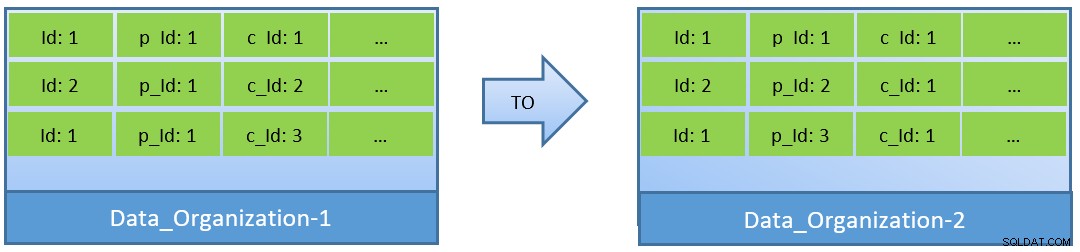
In Data_Organization-1 benötigt PostgreSQL 1000 Blocklesevorgänge (und Cacheverbrauch). ) zum Finden von c_id=1. Andererseits benötigt PostgreSQL für Data_Organisation-2 für dieselbe Abfrage nur 104 Blöcke.
Weniger Blöcke, die für die gleiche Abfrage erforderlich sind, verbrauchen schließlich weniger Cache und sorgen auch für eine optimierte Ausführungszeit der Abfrage.
Fazit
Während der shared_buffer auf PostgreSQL-Prozessebene verwaltet wird, wird der Cache auf Kernelebene auch zur Identifizierung optimierter Abfrageausführungspläne berücksichtigt. Ich werde dieses Thema in einer späteren Blogserie aufgreifen.